
卷积神经网络
整体结构
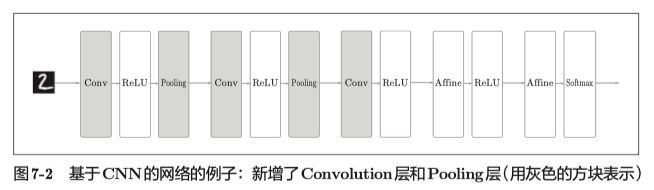
卷积层
卷积操作的本质特性包括稀疏交互和参数共享。
稀疏交互:
定义:在卷积神经网络中,卷积核尺度远小于输入的维度,这样每个输出神经元仅与前一层特定局部区域内的神经元存在连接权重(即产生交互),我们称这种特性为稀疏交互。
意义:通常图像、文本、语音等现实世界中的数据都具有局部的特征结构,我们可以先学习局部的特征,再将局部的特征组合起来形成更复杂和抽象的特征。
参数共享:
定义:在同一个模型的不同模块中使用相同的参数。
意义:1、使卷积层具有平移不变性;
2、只需要学习一组参数集合,大大减少了模型参数。
卷积运算:
将各个位置上卷积核的元素和输入放入对应元素相乘,然后再求和。

填充:
定义:向输入数据的周围填入固定的数据(比如0等);
作用:主要是为了调整输出的大小;
意义:如果不进行填充操作,每次进行卷积运算都会缩小空间,那么某个时刻输出的大小就有可能变为1,导致无法再进行卷积运算。
步幅/步长:
定义:应用卷积核的位置间隔;
作用:调整输出的大小。
计算输出特征图的大小:
假设输入大小为(H, W),卷积核大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S。此时,输出大小可通过下面的公式计算得到
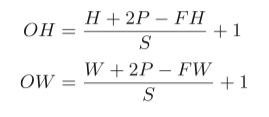
三维数据的卷积运算:
通道方向上有多个特征图时,会按通道进行输入数据和卷积核的卷积运算,然后将结果相加,得到最终输出。
在三维数据的卷积运算中,卷积核的通道数要与输入数据的通道数相同。

池化层
池化操作的本质是降采样。
特点:没有要学习的参数,通道数不发生变化。
作用:
1、降维
可以减小特征图的尺寸;
2、平移不变性
对微小位置的变化具有鲁棒性,输入数据发生微小偏差时,池化仍会返回相同的结果。
常见池化操作:
1、max pooling
取窗口内特征的最大值。
能更好地提取纹理信息。
2、mean pooling
求窗口中元素的均值。
对背景的保留效果更好。
卷积层和池化层的实现
卷积层实现
1、Conv2d 计算卷积一般不是直接一个一个计算的,这样效率太低;
2、通常用im2col把输入reshape成一个矩阵,把卷积核reshape成另一个矩阵,然后一次矩阵乘法就能得到整个卷积的结果;
3、在CNN中数据会保存成4维数组,所以最后再将2维输出数据转换为合适的形状。

池化层实现
1、池化层的实现和卷积层相同,都是用im2col展开输入数据;
2、池化的应用区域按通道单独展开;
3、展开之后,只需要对展开的矩阵求各行的最大值,然后再转换为合适的形状即可。

感受野
CNN每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
CNN训练时一个常见的错误是使用太大的卷积核。通常可以通过将两个3×3内核堆叠在一起来获得与9×9内核相同的效果,参数更少,计算量更少。
卷积用于文本分类
为什么可以用于文本分类?
1、卷积神经网络的核心思想是捕捉局部特征;
2、对于文本来说,局部特征就是由若干 单词组成的滑动窗口,类似于N-gram;
3、卷积神经网络的优势在于能够自动地对Ngram特征进行组合和筛选,获得不同抽象层次的语义信息。
怎么做?


tensorflow 接口
以下为tf.layers包下的方法。对比tf.nn.conv2d包下的卷积方法,tf.layers.conv2d是tf更高一级的API。
一维卷积
一维卷积一般用于处理文本数据,输入一般是文本经过embedding的二维数据。
def conv1d(inputs, # 输入tensor, 维度(batch_size, seq_length, embedding_dim) filters, # 卷积核数 kernel_size, # 卷积核大小,卷积核本身应该是二维的,这里只需要指定一维,第二维长度与词向量长度一致 strides=1, # 步长 padding='valid', data_format='channels_last', dilation_rate=1, activation=None, # 激活函数 use_bias=True, # 使用偏置 kernel_initializer=None, bias_initializer=init_ops.zeros_initializer(), kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, trainable=True, name=None, reuse=None)
padding必须是"VALID"或"SAME":
(1)如果设置为"VALID",卷积层不使用零填充,并且可能会忽略输入图像底部和右侧的某些行和列;
(2)如果设置为"SAME",则卷积层在必要时使用零填充。输出神经元的数量等于输入神经元的数量除以该步幅,向上取整。
data_format:表示输入中维度的顺序.支持channels_last(默认)和channels_first;
(1)channels_last对应于具有形状(batch, height, width, channels)的输入,
(2)channels_first对应于具有形状(batch, channels, height, width)的输入.
二维卷积
def conv2d(inputs, # 输入tensor, 维度(batch_size, seq_length, embedding_dim, channels) filters, kernel_size, strides=(1, 1), padding='valid', data_format='channels_last', dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer=None, bias_initializer=init_ops.zeros_initializer(), kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, trainable=True, name=None, reuse=None)
最大池化
def max_pooling2d(inputs, # 输入tensor,秩必须为4 pool_size, # 2个整数的元组/列表:(pool_height,pool_width),用于指定池窗口的大小.可以是单个整数,以指定所有空间维度的相同值. strides, # 2个整数的元组/列表,用于指定池操作的步幅.可以是单个整数,以指定所有空间维度的相同值. padding='valid', data_format='channels_last', name=None)
平均池化
def average_pooling2d(inputs, pool_size, strides, padding='valid', data_format='channels_last', name=None)
实例
Mnist
import tensorflow as tf import numpy as np height = 28 width = 28 channels = 1 n_inputs = height * width conv1_fmaps = 32 conv1_ksize = 3 conv1_stride = 1 conv1_pad = "SAME" conv2_fmaps = 64 conv2_ksize = 3 conv2_stride = 2 conv2_pad = "SAME" pool3_fmaps = conv2_fmaps n_fc1 = 64 n_outputs = 10 with tf.name_scope("inputs"): X = tf.placeholder(tf.float32, shape=[None, n_inputs], name="X") X_reshaped = tf.reshape(X, shape=[-1, height, width, channels]) y = tf.placeholder(tf.int32, shape=[None], name="y") print("X ", X.shape) print("X_reshaped ", X_reshaped.shape) print("y ", y.shape) conv1 = tf.layers.conv2d(X_reshaped, filters=conv1_fmaps, kernel_size=conv1_ksize, strides=conv1_stride, padding=conv1_pad, activation=tf.nn.relu, name="conv1") conv2 = tf.layers.conv2d(conv1, filters=conv2_fmaps, kernel_size=conv2_ksize, strides=conv2_stride, padding=conv2_pad, activation=tf.nn.relu, name="conv2") print("conv1 ", conv1.shape) print("conv2 ", conv2.shape) with tf.name_scope("pool3"): pool3 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="VALID") pool3_flat = tf.reshape(pool3, shape=[-1, pool3_fmaps * 7 * 7]) tf.layers.conv1d print("pool3 ", pool3.shape) print("pool3_flat ", pool3_flat.shape) with tf.name_scope("fc1"): fc1 = tf.layers.dense(pool3_flat, n_fc1, activation=tf.nn.relu, name="fc1") print("fc1 ", fc1.shape) with tf.name_scope("output"): logits = tf.layers.dense(fc1, n_outputs, name="output") Y_proba = tf.nn.softmax(logits, name="Y_proba") with tf.name_scope("train"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y) loss = tf.reduce_mean(xentropy) optimizer = tf.train.AdamOptimizer() training_op = optimizer.minimize(loss) with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) with tf.name_scope("init_and_save"): init = tf.global_variables_initializer() saver = tf.train.Saver() (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0 X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0 y_train = y_train.astype(np.int32) y_test = y_test.astype(np.int32) X_valid, X_train = X_train[:5000], X_train[5000:] y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size): rnd_idx = np.random.permutation(len(X)) n_batches = len(X) // batch_size for batch_idx in np.array_split(rnd_idx, n_batches): X_batch, y_batch = X[batch_idx], y[batch_idx] yield X_batch, y_batch n_epochs = 10 batch_size = 100 with tf.Session() as sess: init.run() for epoch in range(n_epochs): for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size): sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch}) acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test}) print(epoch, "Last batch accuracy:", acc_batch, "Test accuracy:", acc_test) save_path = saver.save(sess, "./model_dir/my_mnist_model")
textCNN
# 模型部分 def my_model(features, labels, mode, params): print(labels.shape) sentence = features['sentence'] # Get word embeddings for each token in the sentenceimport tensorflow as tf embeddings = tf.get_variable(name="embeddings", dtype=tf.float32, shape=[params["vocab_size"], FLAGS.embedding_size]) sentence = tf.nn.embedding_lookup(embeddings, sentence) # shape:(batch, sentence_len, embedding_size) # add a channel dim, required by the conv2d and max_pooling2d method sentence = tf.expand_dims(sentence, -1) # shape:(batch, sentence_len/height, embedding_size/width, channels=1) pooled_outputs = [] for filter_size in params["filter_sizes"]: conv = tf.layers.conv2d( sentence, filters=FLAGS.num_filters, kernel_size=[filter_size, FLAGS.embedding_size], strides=(1, 1), padding="VALID", activation=tf.nn.relu) pool = tf.layers.max_pooling2d( conv, pool_size=[FLAGS.sentence_max_len - filter_size + 1, 1], strides=(1, 1), padding="VALID") pooled_outputs.append(pool) h_pool = tf.concat(pooled_outputs, 3) # shape: (batch, 1, len(filter_size) * embedding_size, 1) h_pool_flat = tf.reshape(h_pool, [-1, FLAGS.num_filters * len(params["filter_sizes"])]) # shape: (batch, len(filter_size) * embedding_size) if 'dropout_rate' in params and params['dropout_rate'] > 0.0: h_pool_flat = tf.layers.dropout(h_pool_flat, params['dropout_rate'], training=(mode == tf.estimator.ModeKeys.TRAIN)) logits = tf.layers.dense(h_pool_flat, FLAGS.num_classes, activation=None) y_pred_cls = tf.argmax(tf.nn.softmax(logits), -1) # 预测类别,返回最大值的索引 correct_pred = tf.equal(tf.argmax(labels, -1), y_pred_cls) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) tf.summary.scalar("accuracy", accuracy) optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate']) def _train_op_fn(loss): return optimizer.minimize(loss, global_step=tf.train.get_global_step()) my_head = tf.contrib.estimator.multi_class_head(n_classes=FLAGS.num_classes) return my_head.create_estimator_spec( features=features, mode=mode, labels=labels, logits=logits, train_op_fn=_train_op_fn )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号