



prometheus简单介绍
在生产环境中,线上常常可能会有突发事件,服务挂死,cpu过高,磁盘空间不够。。。作为一个合格的程序员,我们应该未雨绸缪,防范于未然。
所以我们需要搭建一个服务器的监控系统,为我们的服务看家护院。
一.我们的需求
监控主机(cpu、内存、磁盘等)、web服务、基础组件(mysql、rocketmq、mongodb)的健康状况,如果持续一段时间不健康(比如cpu使用率持续大于90%,磁盘占用率超过80%等)会产生告警,通知对应的人和群(已发邮件、微信或者钉钉等形式)。
二、我们的设计
需求也有了,下面就是实现方法设计。
假设我们有两台虚拟机需要监控192.168.1.100,192.168.1.101,应用部署图如下。
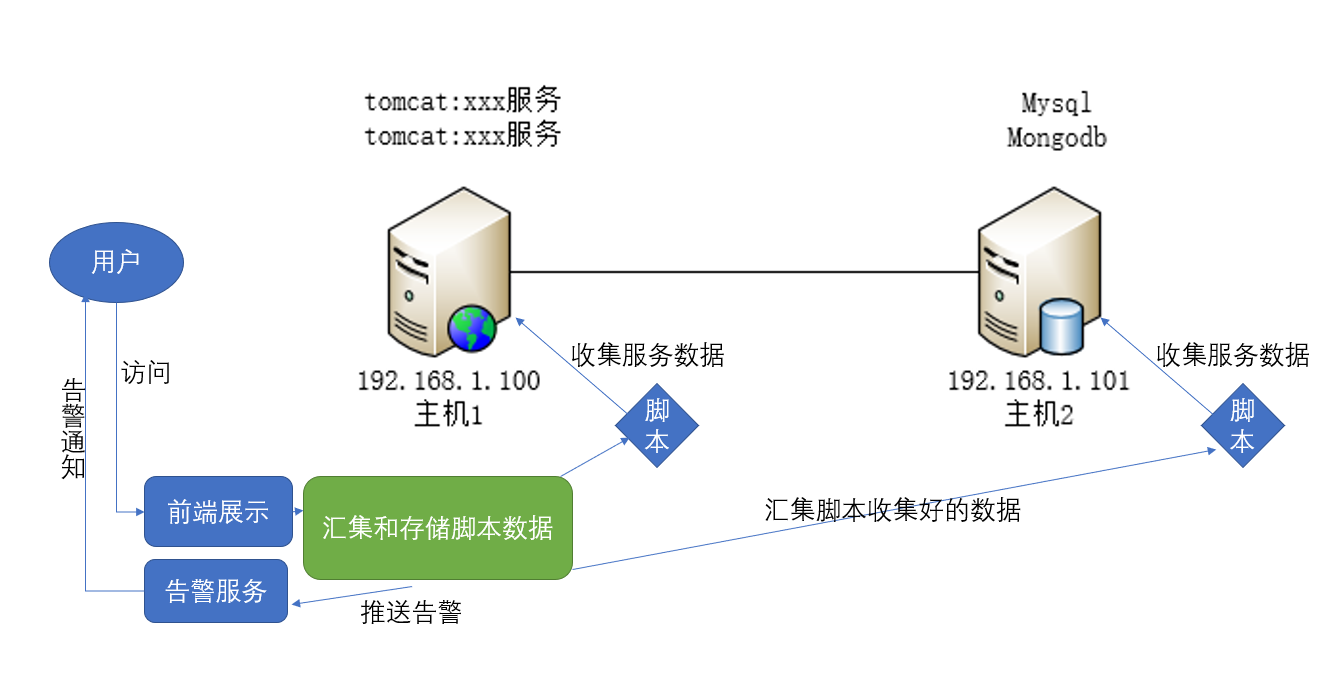
一般情况下,我们是写shell脚本定时监控web服务和虚拟机的状况。
更进一步,我们再写一个服务定时将脚本收集的数据存起来。
更更进一步,我们将这些数据用图形界面展示出来,方便更好的分析。
更更更进一步,我们在汇集存储监控数据的时候,对超出健康值的数据做出告警,推给告警服务,告警服务再对我们发出通知,我们就能及时发现问题了。
这样我们的监控系统初步设计完了。
三、prometheus引入
前面我们设计了最最简单的监控系统了。我们将收集监控数据的服务叫做exporter,将汇集和存储脚本数据、产生告警的服务叫prometheus,将前端展示服务叫grafana,将接受告警、通知告警的服务叫做Alertmanager。自己写脚本和服务太麻烦了,其实有已经造好的轮子,我们只要使用就行了,那么我们就自然而然地引入prometheus等组件。
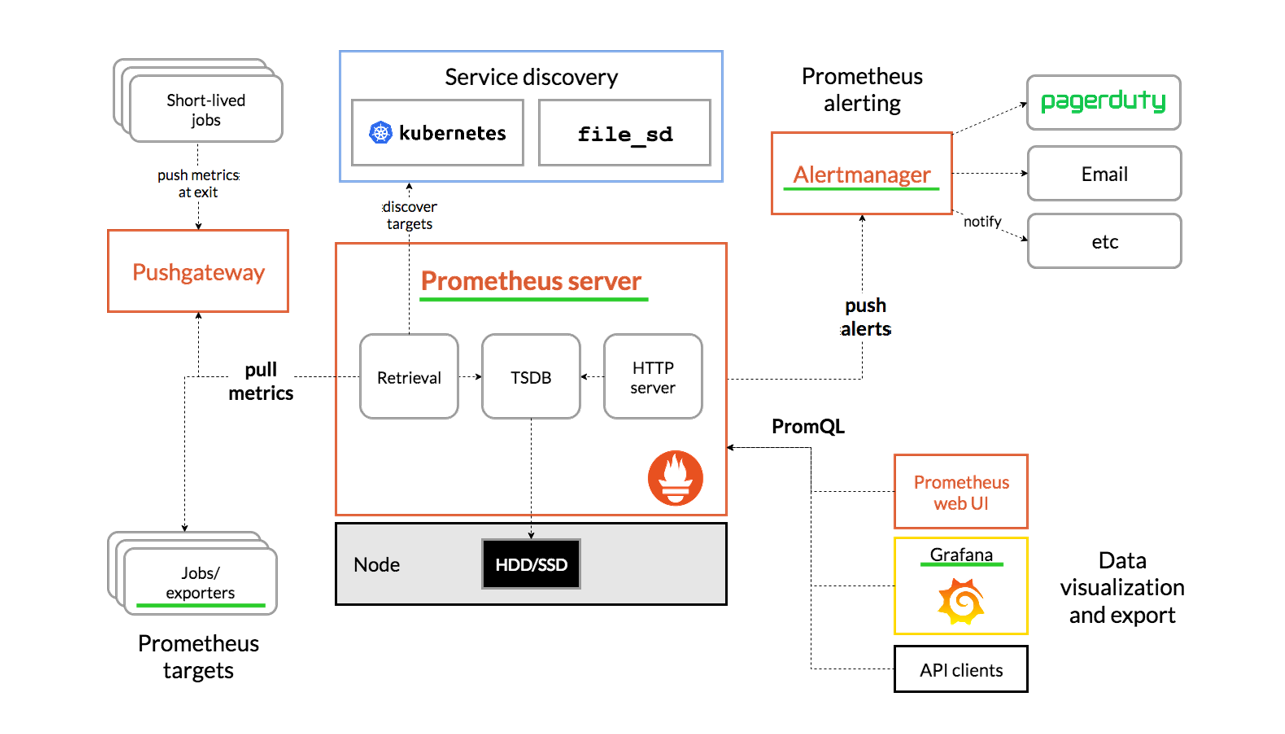
那么,现在绿线上的服务的大致功能,我们就简单了解大概了。
至于Pushgateway和Service discovery是更加的完善了监控系统的功能。
Pushgateway:支持临时性Job主动推送指标的中间网关。比如就是有个服务器10.10.10.12,我们的prometheus访问不到它,但它可以访问的到我们的服务器地址,我们就可以搭建Pushgateway,让它把监控数据发过来给Pushgateway,我们的prometheus再去拉取Pushgateway的数据就行了。
Service discovery:通过服务发现或者静态配置来发现目标服务对象。就是更好的动态加载配置文件。
四、部署拓扑图
综上我们就知道,我们大概在哪台服务部署什么组件,如下图所示:
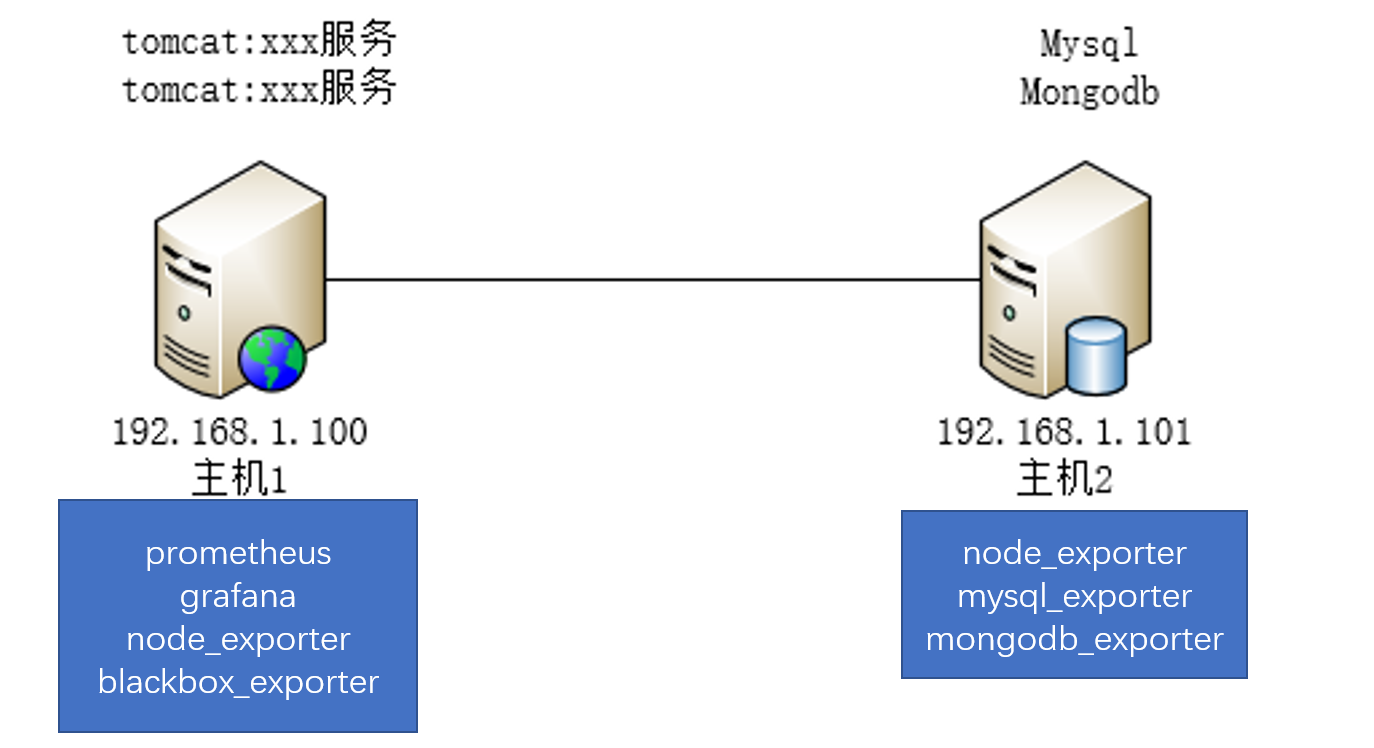
其中node_exporter:收集系统监控数据的第三方组件(也就是我们前面说的脚本),收集cpu、内存、磁盘等信息;
blackbox_exporter:允许通过HTTP,HTTPS,DNS,TCP和ICMP对端点进行黑盒探测。我们可以用来监控web服务,定时去探测一些暴露的接口,来判断服务的健康情况;
mysql_exporter:收集mysql的信息;
mongodb_exporter:收集mongodb的信息。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号