【算法】深度优先算法DFS
参考:https://blog.csdn.net/qq_38737992/article/details/95635940
一、算法理解
深度优先搜索算法(Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节 点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这 一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点 并重复以上过程,整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
在树的遍历中,我们可以用 DFS 进行 前序遍历,中序遍历和后序遍历。在这三个遍历顺序中有一个共同的特性: 除非我们到达最深的结点,否则我们永远不会回溯。这也是 DFS 和 BFS 之间最大的区别,BFS永远不会深入探 索,除非它已经在当前层级访问了所有结点。
DFS最直观的例子就是走迷宫。假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走 着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是 一种深度优先搜索策略。
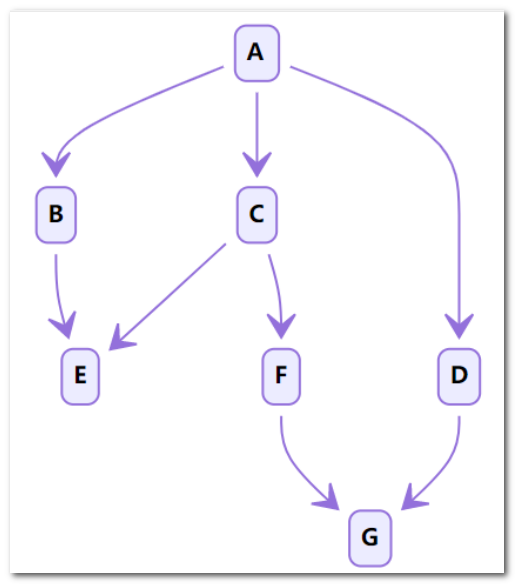
在上面的例子中,我们从根结点 A 开始。首先,我们选择结点 B 的路径,直到我们到达结点 E ,我们无法更进 一步深入。然后我们回溯到 A 并选择第二条路径到结点 C 。从 C 开始,我们尝试第一条路径到 E 但是 E 已 被访问过。所以我们回到 C 并尝试从另一条路径到 F 。最后,我们找到了 G 。
总的来说,在我们到达最深的结点之后,我们只会回溯并尝试另一条路径。 因此,你在 DFS 中找到的第一条路径并不总是最短的路径。例如,在上面的例子中,我们成功找出了路径 A-> C-> F-> G 并停止了 DFS。但这不是从 A 到 G 的最短路径。
**有两种实现 DFS 的方法。一种方法是进行递归,另一种是使用栈。 **
- 【递归模板】
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(Node cur, Node target, Set<Node> visited) {
return true if cur is target;
for (next : each neighbor of cur) {
if (next is not in visited) {
add next to visted;
return true if DFS(next, target, visited) == true;
}
}
return false;
}
换成二叉树的迭代方式就是:
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(Node cur, Node target, Set<Node> visited) {
//当前节点要做的业务逻辑;
DFS(leftNode, target, visited);
DFS(rightNode, target, visited)
return false;
}
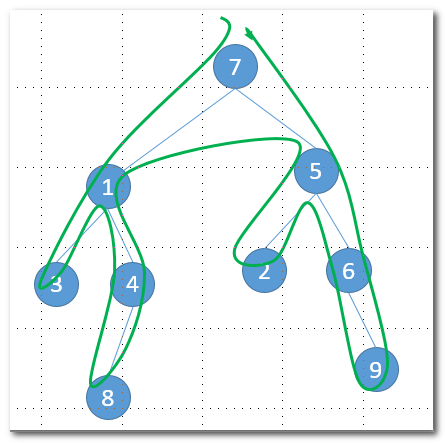
通过图的方式表达,其调用和返回路径如下:
- 【栈模板】(者是BFS的思路呀?)
boolean DFS(Node root, Node target) {
Set<Node> visited;
Stack<Node> s;
add root to s;
while (s is not empty) {
Node cur = the top element in s;
return true if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in visited) {
add next to s;
add next to visited;
}
}
remove cur from s;
}
return false;
}
当我们递归地实现 DFS 时,似乎不需要使用任何栈。但实际上,我们使用的是由系统提供的隐式栈,也称为调用 栈。显然使用递归更容易实现,但是递归存在一个很大的缺点是如果递归深度太高,可能会出现栈溢出。因此如果:
- 图比较小,可以用递归快速实现;
- 递归实现不了时,就要考虑用栈了。
回溯搜索是深度优先搜索(DFS)的一种。对于某一个搜索树来说(搜索树是起记录路径和状态判断的作用),回溯和DFS,其主要的区别是,回溯法在求解过程中不保留完整的树结构,而深度优先搜索则记下完整的搜索树。回溯就是通过不同的尝试来生成问题的解,有点类似于穷举,但是和穷举不同的是回溯会“剪枝”。为了减少存储空间,在深度优先搜索中,用标志的方法记录访问过的状态,这种处理方法使得深度优先搜索法与回溯法没什么区别了。
DFS采用递归方式的基本模式:
void dfs(int step) {
// 判断边界;
// 尝试每一种可能;
int len = 0;//define your own length
for (int i = 1; i <= len; ++i) {
//继续下一步
dfs(step + 1);
}
// 返回;
}
二、适用场景
DFS是图上的比较基本的搜索算法,简单粗暴,没有什么优化,所以仅适用于状态空间不大,或者说图不大的搜索。DFS和BFS往往能解决相同的问题:
- BFS是地毯式层层推进,偏向于找最短路径;
- DFS是走迷宫,用的是回溯思想,找到就结束,找不到就回溯,偏向于拓扑排序、判断连通性。
三、使用案例
1)钥匙与房间
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙 能使你进入下一个房间。
在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i]/[j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i]/[j] = v 可以打开编号为 v 的房间。
最初,除 0 号房间外的其余所有房间都被锁住。 你可以自由地在房间之间来回走动。 如果能进入每个房间返回 true,否则返回 false。
示例1:
输入: [[1],[2],[3],[]]
输出: true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。
示例2:
输入:[[1,3],[3,0,1],[2],[0]]
输出:false
解释:我们不能进入 2 号房间。
提示:
1 <= rooms.length <= 1000
0 <= rooms[i].length <= 1000
所有房间中的钥匙数量总计不超过 3000。
房间可以看成节点,钥匙可以看成是连接节点的边,题目可以转化为从0节点开始,是否能达到所有的节点。有向图的搜索,并且需要遍历图的每个节点,那么我们可以考虑用BFS或者DFS这种简单粗暴的算法。
这个题目用BFS和DFS都能实现,这里套用上面给出的栈模板来解决这个问题(也是官方题解)(这个样例代码是BFS的思路):
boolean canVisitAllRooms(List<List<Integer>> rooms) {
boolean[] seen = new boolean[rooms.size()];
seen[0] = true;
Stack<Integer> stack = new Stack();
stack.push(0);
// At the beginning, we have a todo list "stack" of keys to use.
// 'seen' represents at some point we have entered this room.
while (!stack.isEmpty()) { // While we have keys...
int node = stack.pop(); // Get the next key 'node'
for (int nei : rooms.get(node)) { // For every key in room # 'node'...
if (!seen[nei]) { // ...that hasn't been used yet
seen[nei] = true; // mark that we've entered the room
stack.push(nei); // add the key to the todo list
}
}
}
for (boolean v : seen) { // if any room hasn't been visited, return false
if (!v) {
return false;
}
}
return true;
}
2)!!!得分最高的路径 (并查集,DFS,优先队列+BFS均可)
给你一个 R 行 C 列的整数矩阵 A。矩阵上的路径从 [0,0] 开始,在 [R-1,C-1] 结束。
路径沿四个基本方向(上、下、左、右)展开,从一个已访问单元格移动到任一相邻的未访问单元格。路径的得分是该路径上的最小 值。例如,路径 8 → 4 → 5 → 9 的值为 4 。
找出所有路径中得分 最高 的那条路径,返回其 得分。
示例 1:
输入:[[5,4,5],[1,2,6],[7,4,6]]
输出:4
解释: 得分最高的路径用黄色突出显示。
示例 2:
输入:[[2,2,1,2,2,2],[1,2,2,2,1,2]]
输出:2
示例 3:
输入:[[3,4,6,3,4],[0,2,1,1,7],[8,8,3,2,7],[3,2,4,9,8],[4,1,2,0,0],[4,6,5,4,3]]
输出:3
提示:
1 <= R, C <= 100
0 <= A[i]/[j] <= 10^9
【使用深度优先算法解题】:
- 每查到下个节点,都会把从root到当前阶段路径上的最好值记录下来。
root
|--上
|--上
|--上 .....一个分支上,查到第,再逐层回溯,查找下个方向的查询方式。
|--下
|--左
|--右
|--下
|--左
|--右
|--下
|--左
|--右
class Solution {
private int rowLen;
private int colLen;
private static final int[][] DIRECTIONS = new int[][]{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
private int max;
public int maximumMinimumPath(int[][] A) {
rowLen = A.length;
if (rowLen != 0) {
colLen = A[0].length;
}
max = Integer.MIN_VALUE;
boolean[][] visited = new boolean[rowLen][colLen];
visited[0][0] = true;
backtrack(A, 0, 0, A[0][0], visited);
return max;
}
//score表示当前路径检索路径的最小值
private void backtrack(int[][] A, int row, int col, int score, boolean[][] visited) {
// 遇到终点,则返回
if (row == rowLen - 1 && col == colLen - 1) {
max = Math.max(max, score);
return;
}
for (int[] dir : DIRECTIONS) {
int newRow = row + dir[0];
int newCol = col + dir[1];
if (newRow >= 0 && newRow < rowLen && newCol >= 0 && newCol < colLen && !visited[newRow][newCol]) {
visited[newRow][newCol] = true;
int ns = A[newRow][newCol];
backtrack(A, newRow, newCol, Math.min(score, A[newRow][newCol]), visited);
visited[newRow][newCol] = false;
}
}
return;
}
}
如果采用广度优先(BFS)算法:
- 每个入栈Node,记录路径查找到当前Node后,路径上的最小值。
- 采用优先队列,优先出队记录的“最小值” 最大的路径。
class Solution {
class Point {
int x;
int y;
int pointValue;
int currentMinValue;
Point(int x, int y, int pointValue) {
this.x = x;
this.y = y;
this.pointValue = pointValue;
}
}
public int maximumMinimumPath(int[][] A) {
//优先队列,同时记录达到这个节点的最小值,到达该节点的路径中的最小值越大越优先,
PriorityQueue<Point> priorityQueue = new PriorityQueue<>((p1, p2) -> p2.currentMinValue - p1.currentMinValue);
int rows = A.length;
int cols = A[0].length;
boolean[][] visited = new boolean[rows][cols];
Point startPoint = new Point(0, 0, A[0][0]);
startPoint.currentMinValue = A[0][0];
priorityQueue.add(startPoint);
int[][] directors = new int[][]{{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
while (!priorityQueue.isEmpty()) {
Point currentPoint = priorityQueue.poll();
if (currentPoint.x == rows - 1 && currentPoint.y == cols - 1) {
return currentPoint.currentMinValue;
}
visited[currentPoint.x][currentPoint.y] = true;
for (int i = 0; i < directors.length; i++) {
int nextX = currentPoint.x + directors[i][0];
int nextY = currentPoint.y + directors[i][1];
//在范围内,且没有访问过,加入队列
if (nextX >= 0 && nextX < rows && nextY >= 0 && nextY < cols && !visited[nextX][nextY]) {
int nextPointValue = A[nextX][nextY];
Point nextPoint = new Point(nextX, nextY, nextPointValue);
//目前的最小值与当前节点比较
nextPoint.currentMinValue = Math.min(currentPoint.currentMinValue, nextPoint.pointValue);
priorityQueue.offer(nextPoint);
}
}
}
return -1;
}
}
3)打家劫舍
在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
示例 1:
输入: [3,2,3,null,3,null,1]
3
/
2 3
\ \
3 1
输出: 7
解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.
示例 2:
输入: [3,4,5,1,3,null,1]
3
/
4 5
/ \ \
1 3 1
输出: 9
解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9.
代码参考:
class Solution {
Map<TreeNode, Integer> memo = new HashMap<>();
public int rob(TreeNode root) {
if (root == null) {
return 0;
}
if (memo.containsKey(root)) {
return memo.get(root);
}
// 抢当前这家店,当前店铺抢到的金额加上抢劫下下家店铺的金额总合;
int robCurrentMoney = root.val;
// 去打劫左子树的下下个商店
robCurrentMoney += root.left != null ? rob(root.left.left) : 0;
robCurrentMoney += root.left != null ? rob(root.left.right) : 0;
// 去打劫右子树的下下个商店
robCurrentMoney += root.right != null ? rob(root.right.left) : 0;
robCurrentMoney += root.right != null ? rob(root.right.right) : 0;
// 不抢当前这家店,抢劫下家商店
int robNextMoney = rob(root.left) + rob(root.right);
int answer = Math.max(robCurrentMoney, robNextMoney);
//缓存已计算过的点
memo.put(root, answer);
return answer;
}
}
4) 路径总和
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/
4 8
/ /
11 13 4
/ \ /
7 2 5 1
返回:
[
[5,4,11,2],
[5,8,4,5]
]
【思路分析】:
list dfs(node, 已知和, 已知道list,retMap<Integer, List>) {
if(node == null) {
if(已知和 = 目标和) {
Integer v = retMap.size();
retMap.add(v+1, list);
}
}
list2 x= new list (list);
lsit2.add(node);
new已知和 = 已知和 + node.val;
def(node.left, new已知和, list2,retMap);
def(node.right, new已知和, list2,retMap);
}
别人代码参考:(与上面思路几乎一致)
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> res = new ArrayList<>();
helper(root, sum, res, new ArrayList<Integer>());
return res;
}
private void helper(TreeNode root, int sum, List<List<Integer>> res, ArrayList<Integer> tmp) {
if (root == null) {
return;
}
int leftSum = sum - root.val;
tmp.add(root.val);
if (root.left == null && root.right == null && leftSum == 0) {
res.add(new ArrayList<>(tmp));
//思考为什么不能在此处return直接返回?----当前路径查找完毕,最后一个节点要从tmp中干掉,回溯到上一步
}
helper(root.left, leftSum, res, tmp);
helper(root.right, leftSum, res, tmp);
tmp.remove(tmp.size() - 1);
}
推荐的做法,多点返回时,主要还原现场
public List<List<Integer>> pathSum(TreeNode root, int sum) {
List<List<Integer>> res = new ArrayList<>();
helper(root, sum, res, new ArrayList<Integer>());
return res;
}
private void helper(TreeNode root, int sum, List<List<Integer>> res, ArrayList<Integer> tmp) {
if (root == null) {
return;
}
int remainer = sum - root.val;
tmp.add(root.val);
if (root.left == null && root.right == null && remainer == 0) {
res.add(new ArrayList<>(tmp));
//注意此处增加返回时要把选择项环原
tmp.remove(tmp.size() - 1);
return;
}
helper(root.left, remainer, res, tmp);
helper(root.right, remainer, res, tmp);
tmp.remove(tmp.size() - 1);
}
5)单词拆分(#139)
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
- 拆分时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。
注意你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
【源码参考】:(采用DFS)
思路:
- 把句子进行匹配单词,如果匹配上,计算计算本单词后内容是否满足拆分要求。
- 采用递归DFS,为了提高效率,采用cacche记录结果。用Index为索引,记录从本index往后的句子是否满足要求。
public boolean wordBreak(String s, List<String> wordDict) {
// 0表示当前index开始字符串穿未计算,1表示能按照字典拆分,-1表示不能按照字典拆分
// 刚好匹配完,最后一个StartIndex是字段的下一个位置:s.length()
int[] cache = new int[s.length() + 1];
return dfsCanBreak(s, 0, wordDict, cache);
}
public boolean dfsCanBreak(String s, int startIndex, List<String> wordDict, int[] cache) {
if (startIndex == s.length()) {
return true;
}
if (cache[startIndex] == 1) {
return true;
} else if (cache[startIndex] == -1) {
return false;
}
for (int i = 0; i < wordDict.size(); i++) {
String word = wordDict.get(i);
if (s.substring(startIndex).startsWith(word)) {
int newStart = startIndex + word.length();
if (dfsCanBreak(s, newStart, wordDict, cache)) {
cache[newStart] = 1;
return true;
} else {
cache[newStart] = -1;
}
}
}
return false;
}
【源码参考】:(采用BFS)
思路:
把句子按照单词的分割点Index作为节点压栈、出栈:
- 初始start = 0;
- 往后匹配words,如果匹配上多个单词,把每种匹配的结尾都一种可能入栈,作为下次搜索的起点。
- 到匹配单词结尾刚好到语句结束,返回true。
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> wordDictSet = new HashSet(wordDict);
Queue<Integer> queue = new LinkedList<>();
int[] visited = new int[s.length()];
queue.add(0);
while (!queue.isEmpty()) {
int start = queue.remove();
if (visited[start] == 0) {
for (int end = start + 1; end <= s.length(); end++) {
if (wordDictSet.contains(s.substring(start, end))) {
queue.add(end);
if (end == s.length()) {
return true;
}
}
}
visited[start] = 1;
}
}
return false;
}
6)重新安排行程
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从JFK出发。
【说明】:
如果存在多种有效的行程,你可以按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前所有的机场都用三个大写字母表示(机场代码)。
假定所有机票至少存在一种合理的行程。
示例 1:
输入: [["MUC", "LHR"],
["JFK", "MUC"],
["SFO", "SJC"],
["LHR", "SFO"]]
输出: ["JFK", "MUC", "LHR", "SFO", "SJC"]
示例 2:
输入:
[["JFK","SFO"],
["JFK","ATL"],
["SFO","ATL"],
["ATL","JFK"],
["ATL","SFO"]]
输出: ["JFK","ATL","JFK","SFO","ATL","SFO"]
解释: 另一种有效的行程是 ["JFK","SFO","ATL","JFK","ATL","SFO"]。但是它自然排序更大更靠后。
【思路】:
- 按照关系,组成Map,key是起点,Value是可达的List(List按照字符排序)
- 图构建好了之后就是去dfs,按照题目要求从"JFK"开始,找下一个地点:
- 当发现某个from没有在map里或者某个from对应的优先队列为空,这就代表它没有了下一个节点,放到最后结果的list集合里。
- 当from对应的队列长度>0,那么就依次去dfs队列里面的地点,全部dfs完之后记得list.add上from,因为它终要回到这里。
class Solution {
static Map<String, PriorityQueue<String>> map = new HashMap<String, PriorityQueue<String>>();
static List<String> list = new ArrayList<String>();
public static List<String> findItinerary(String[][] tickets) {
map.clear();
list.clear();
for (String[] strings : tickets) {
if (map.containsKey(strings[0])){
map.get(strings[0]).add(strings[1]);
}else{
PriorityQueue<String> pqt = new PriorityQueue<String>();
pqt.add(strings[1]);
map.put(strings[0],pqt);
}
}
dfs("JFK");
Collections.reverse(list);
return list;
}
public static void dfs(String s){
if (map.containsKey(s) == false){
list.add(s);
return;
}
PriorityQueue<String> pq = map.get(s);
if (pq.size() == 0){
list.add(s);
return;
}else{
while(pq.size() != 0){
dfs(pq.poll());
}
list.add(s);
}
}
}
四、其他非DFS
1)孤独像素I
给定一幅黑白像素组成的图像, 计算黑色孤独像素的数量。
图像由一个由‘B’和‘W’组成二维字符数组表示, ‘B’和‘W’分别代表黑色像素和白色像素。
黑色孤独像素指的是在同一行和同一列不存在其他黑色像素的黑色像素。
示例:
输入:
[['W', 'W', 'B'],
['W', 'B', 'W'],
['B', 'W', 'W']]
输出: 3
解析: 全部三个'B'都是黑色孤独像素。
注意: 输入二维数组行和列的范围是 [1,500]。
【思路1】:并查集
同一行,同一列的B都加入到一个集合。
- 逐行遍历,Union都是B的节点。
- 逐列遍历,Union都是B的节点。
- 最终,在行集合、列集合中findRoot是-1的节点,都是孤立节点。
【思路2】:暴力解法
- 逐行遍历,B个数大于1个的排除。队里记录行只有一个B的单元。
- 按照队里中记录的单元,逐列遍历,B个数大于1,排除。
网上解法:https://cloud.tencent.com/developer/article/1659702?from=article.detail.1659701
- 先记录每行、每列各有多少黑色
- 共需遍历2次矩阵
class Solution {
int findLonelyPixel(vector<vector<char>>& picture) {
int m = picture.size(), n = picture[0].size(), i, j;
vector<int> r(m,0), c(n,0);
//对每行,每列的黑色进行计数
for(i = 0; i < m; ++i)
for(j = 0; j < n; ++j)
if(picture[i][j]=='B')
r[i]++, c[j]++;
int lonely = 0;
for(i = 0; i < m; ++i)
for(j = 0; j < n; ++j)
if(picture[i][j]=='B' && r[i]==1 && c[j]==1)
lonely++;
return lonely;
}
};
2)孤独像素II (采用两次遍历方式)
给定一幅由黑色像素和白色像素组成的图像,与一个正整数N,找到位于某行 R 和某列 C 中且符合下列规则的黑色像素的数量。
- 行R和列C都恰好包括N个黑色像素。
- 列C中所有黑色像素所在的行必须和行R完全相同。
图像由一个由‘B’和‘W’组成二维字符数组表示, ‘B’和‘W’分别代表黑色像素和白色像素。
示例:
输入:
[['W', 'B', 'W', 'B', 'B', 'W'],
['W', 'B', 'W', 'B', 'B', 'W'],
['W', 'B', 'W', 'B', 'B', 'W'],
['W', 'W', 'B', 'W', 'B', 'W']]
N = 3
输出: 6
【解题思路】:
要求:
- [R]/[C]为B,且 [R]行 B个数 和 [C]列 B个数安全一致,都为N。
- [R]行 B的 colIndex 与 [C]列 B的rowIndex完全一致。
思路:
- 新建ArrayList
[] row,记录每行的B的colIndex。 - 新建ArrayList
[] col,记录每列的B的rowIndex。 - 遍历二维数组。刷新1 2数组数据结构
- 二次遍历二威数组,看B所在行、列的 row[i] 和 col[j]是否完全相同(个数+序列中Index)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号