

从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
参考:https://blog.csdn.net/v_july_v/article/details/8203674
1.3、K值的选择
除了上述1.2节如何定义邻居的问题之外,还有一个选择多少个邻居,即K值定义为多大的问题。不要小看了这个K值选择问题,因为它对K近邻算法的结果会产生重大影响。如李航博士的一书「统计学习方法」上所说:
如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的累,模型过于简单,忽略了训练实例中大量有用信息。
近似误差:可以理解为对现有训练集的训练误差。
估计误差:可以理解为对测试集的测试误差。
2.2、KD树的构建
kd树构建的伪代码如下图所示(伪代码来自《图像局部不变特性特征与描述》王永明 王贵锦 编著):

再举一个简单直观的实例来介绍k-d树构建算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如下图所示。为了能有效的找到最近邻,k-d树采用分而治之的思想,即将整个空间划分为几个小部分,首先,粗黑线将空间一分为二,然后在两个子空间中,细黑直线又将整个空间划分为四部分,最后虚黑直线将这四部分进一步划分。
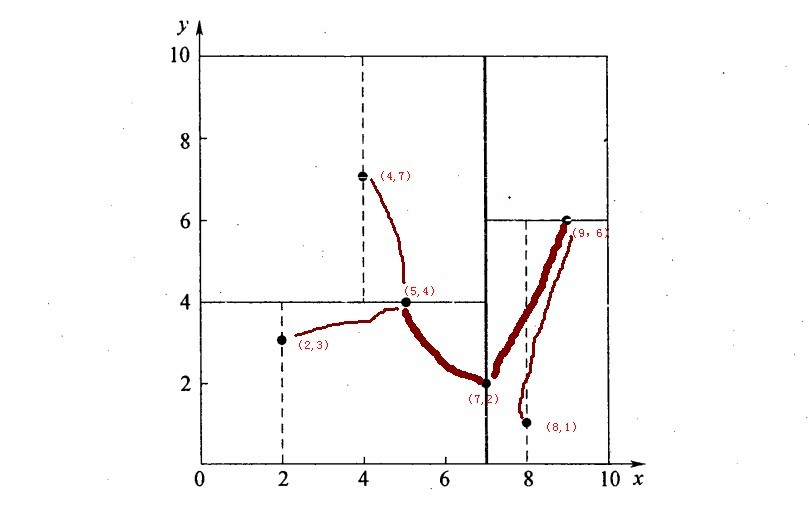
6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
1.确定:split域=x。具体是:6个数据点在x,y维度上的数据方差分别为39,28.63,所以在x轴上方差更大,故split域值为x;
2.确定:Node-data = (7,2)。具体是:根据x维上的数值将数据排序(2,4,5,7,8,9),6个数据的中值(所谓中值,即中间大小的值)为7,所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7;
注:这一步里面x轴上的中值为6,所以说第一个切分点选择6和7都行的。
3.确定:左子空间和右子空间。具体是:分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
如上算法所述,kd树的构建是一个递归过程,我们对左子空间和右子空间内的数据重复根节点的过程就可以得到一级子节点(5,4)和(9,6),同时将空间和数据集进一步细分,如此往复直到空间中只包含一个数据点,或者说直到空间无法划分为止,或者说每个点都被划分了。
与此同时,经过对上面所示的空间划分之后,我们可以看出,点(7,2)可以为根结点,从根结点出发的两条红粗斜线指向的(5,4)和(9,6)则为根结点的左右子结点,而(2,3),(4,7)则为(5,4)的左右孩子(通过两条细红斜线相连),最后,(8,1)为(9,6)的左孩子(通过细红斜线相连)。如此,便形成了下面这样一棵k-d树:
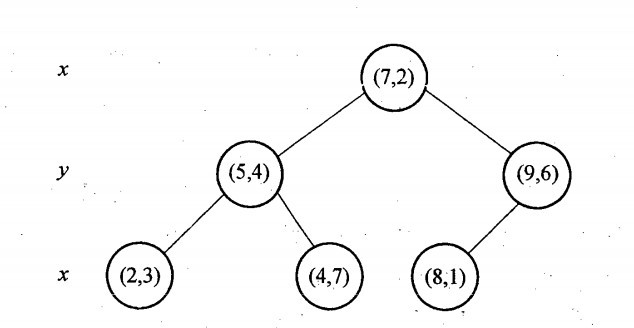
k-d树的数据结构

————————————————
版权声明:本文为CSDN博主「v_JULY_v」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/v_july_v/article/details/8203674
下面描述Kd树的搜索过程:
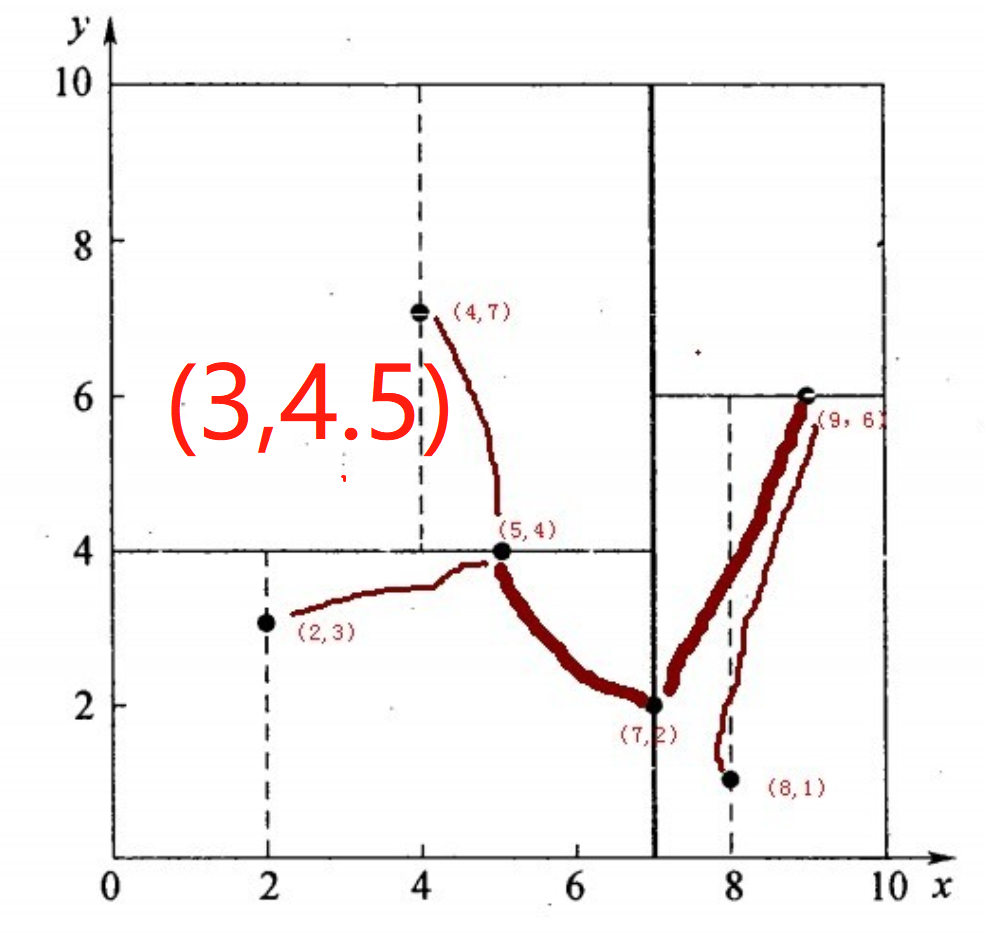
假如有个点是(3,4.5),现在要找到这个点的最临近点,整体思路是先看这个点位于哪个划分区域,然后找到距离这个点最近的子节点,再回溯到根节点就完成了寻找最邻近点的过程。具体步骤如下:
第一步:先找到点(3,4.5)所在的划分区域。
从根节点(7,2)开始,先比较横坐标:3<7,所以往左边找。找到叶子节点(5,4).然后比较纵坐标:4.5>4,找到叶子节点(4,7).点(3,4.5)就位于叶子节点(4,7)所划分的子区域内,此时,把叶子节点(4,7)(这个点叫做当前最近点)存储为(3,4.5)的最临近点。
第二步:回溯(就是从子节点往父节点递归)。
以(3,4.5)为圆心,以(3,4.5)与叶子节点(4,7)的连线为半径(r=2.69)画圆。此圆与(4,7)的父节点(5,4)所在的超平面相交,这说明(4,7)的兄弟节点里面有可能存在比距离(4,7)更小的距离(这个超平面的另一办子区域可能还有比距离2.69更小的点存在)。(5,4)的子节点有(4,7)和(2,3),(4,7)的兄弟节点有(2,3),(3,4.5)和(2,3)的距离是1.8,1.8<2.68,此时把最近邻点更新为(2,3)(这个叫做当前最近点的更新),以(3,4.5)为圆心,以(3,4.5)与叶子节点(2,3)的连线为半径(r=1.8)画圆。这个圆与(2,3)的父节点(5,4)虽然也相交,但是(2,3)的兄弟节点(4,7)已经遍历过了,所以不更新当前最近点了。
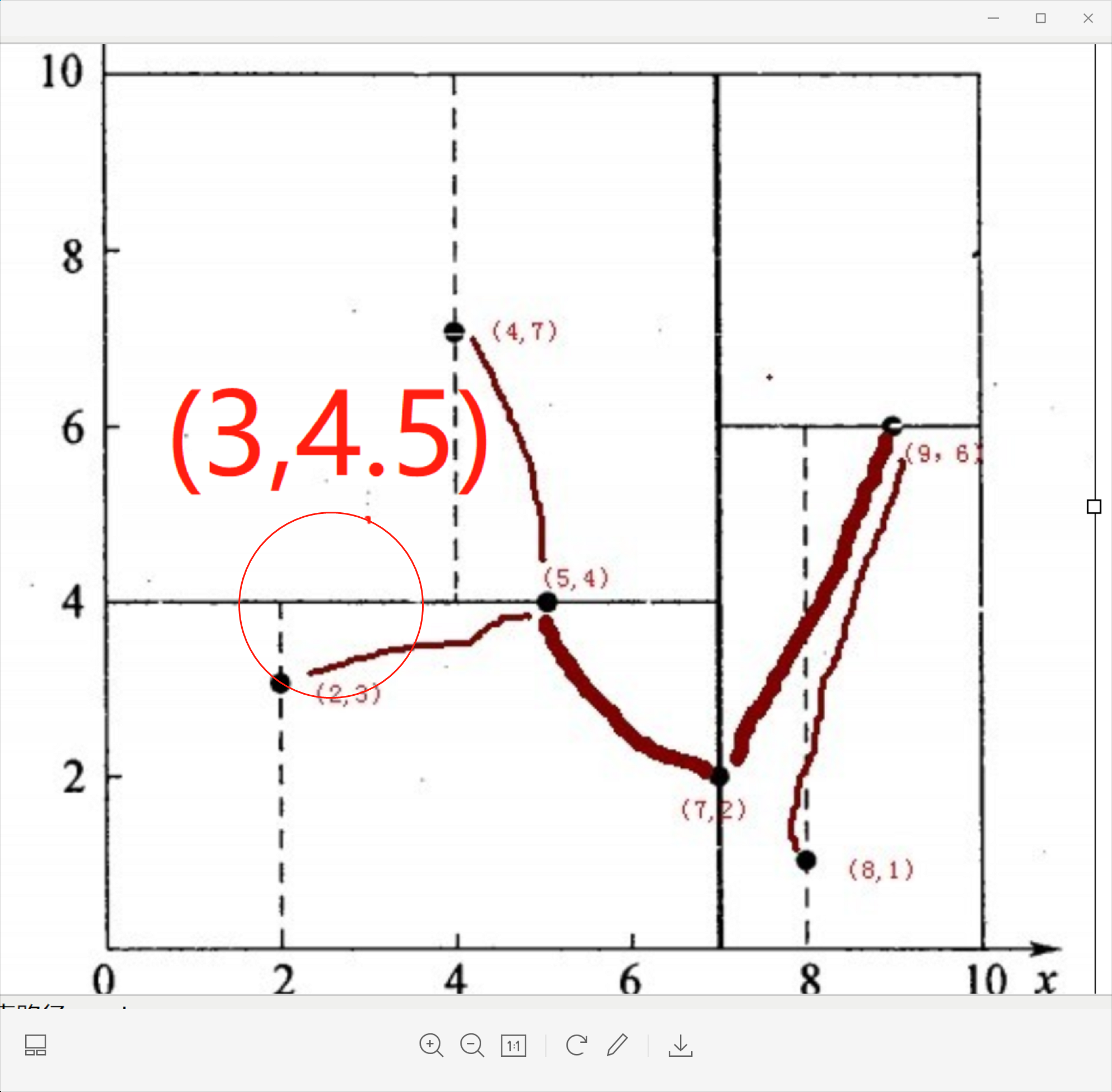
第三步:继续回溯到叶子节点(2,3)的父节点(5,4),计算的距离是2.06,不更新。应该是不用计算(2,3)的父节点(5,4)的,因为查询点(3,4.5)距离叶子节点(2,3)的距离一定是小于它距离叶子节点(2,3)的父节点的。
第四步:继续回溯(5,4)的父节点(7,2),(7,2)所确定的超平面和第三步画的圆是不相交的,所以不可能有更近的点了,搜索结束,即回溯过程结束。此时,当前最近点就是(2,3)。
k-d树是每个节点都为k维点的二叉树。所有非叶子节点可以视作用一个超平面把空间分割成两个半空间。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。选择超平面的方法如下:每个节点都与k维中垂直于超平面的那一维有关。因此,如果选择按照x轴划分,所有x值小于指定值的节点都会出现在左子树,所有x值大于指定值的节点都会出现在右子树。这样,超平面可以用该x值来确定,其法线为x轴的单位向量。
创建:
有很多种方法可以选择轴垂直分割面( axis-aligned splitting planes ),所以有很多种创建k-d树的方法。 最典型的方法如下:
随着树的深度轮流选择轴当作分割面。(例如:在三维空间中根节点是 x 轴垂直分割面,其子节点皆为 y 轴垂直分割面,其孙节点皆为 z 轴垂直分割面,其曾孙节点则皆为 x 轴垂直分割面,依此类推。)
点由垂直分割面之轴座标的中位数区分并放入子树
这个方法产生一个平衡的k-d树。每个叶节点的高度都十分接近。然而,平衡的树不一定对每个应用都是最佳的。
ball tree
对于一些分布不均匀的数据集,KD 树算法搜索效率并不好,为了优化就产生了球树这种算法。同样的,暂时先不用具体深入了解这种算法。
1. 原理:
为了改进KDtree的二叉树树形结构,并且沿着笛卡尔坐标进行划分的低效率,ball
tree将在一系列嵌套的超球体上分割数据。也就是说:使用超球面而不是超矩形划分区域。虽然在构建数据结构的花费上大过于KDtree,但是在高维甚至很高维的数据上都表现的很高效。
球树递归地将数据划分为由质心C和半径r定义的节点,使得节点中的每个点都位于由r和C定义的超球内。通过使用三角不等式来减少邻居搜索的候选点数量的。
为了解决 KD 树在高维上效率低下的问题, ball 树 数据结构就被研发出来了. 其中 KD 树沿迪卡尔轴(即坐标轴)分割数据, ball 树在沿着一系列的 hyper-spheres 来分割数据. 通过这种方法构建的树要比 KD 树消耗更多的时间, 但是这种数据结构对于高结构化的数据是非常有效的, 即使在高维度上也是一样.
ball 树将数据递归地划分为由质心 C和半径r定义的节点,使得节点中的每个点位于由r和C
定义的 hyper-sphere 内. 通过使用 triangle inequality(三角不等式) 减少近邻搜索的候选点数:|x+y|<=|x|+|y|通过这种设置, 测试点和质心之间的单一距离计算足以确定距节点内所有点的距离的下限和上限. 由于 ball 树节点的球形几何, 它在高维度上的性能超出 KD-tree, 尽管实际的性能高度依赖于训练数据的结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号