MySQL数据库基本知识
一、数据库表的相关操作
1、什么是SQL语言
SQL是用于访问和处理数据的标准的计算机语言
SQL语句不区分大小写,但是字符串区分,语句必须以分号结尾
空白和换行没有限制,但是不能破坏语法
注释有两种:#或/*xxxxxxxxxxxx*/
(1)创建逻辑库
SHOW DATABASES; 查看所有逻辑库
CREATE DATABASE demo; 创建demo逻辑库
DROP DATABASE demo; 删除demo逻辑库
(2)创建数据表
创建数据表
CREATE TABLE 数据库(
列名1 数据类型[约束] [COMMENT 注释],
列名1 数据类型[约束] [COMMENT 注释],
......
)[COMMENT = 注释];
# 创建一个逻辑库并且使用它
CREATE DATABASE test; USE test;
CREATE TABLE student( id INT UNSIGNED PRIMARY KEY, name VARCHAR(20) NOT NULL, sex CHAR(1) NOT NULL, birthday DATE NOT NULL, tel CHAR(11) NOT NULL, remark VARCHAR(200) ); INSERT INTO student VALUES(1,"李强","男","1995-09-18","12345678912","体育生")
(3)数据表的其他操作
SHOW tables; //打印出逻辑空间数据表的名字
DESC student; //查看数据表内的字段
SHOW CREATE TABLE student; //打印创建数据表时的SQL语句
DROP TABLE student; //删除数据表
2、不同的数据类型
(1)数字
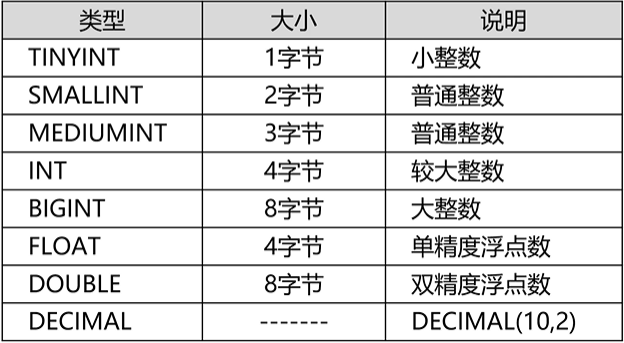
注意:
float double 会存在丢失精度
decimal 的数据类型是数字串(10,2) 10表示一共有几个字符,2表示精确到小数点后面几位【优先使用decimal保存精确的浮点数】
(2)字符串
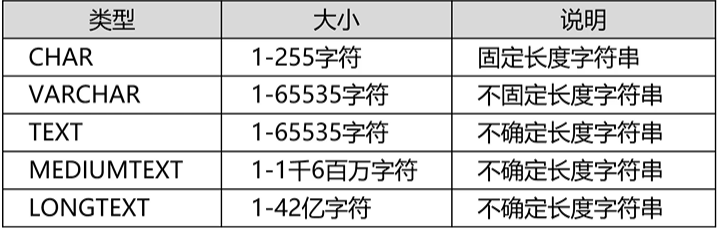
(3)日期类型
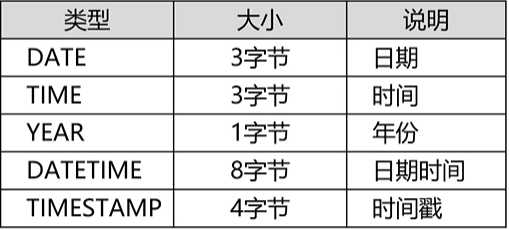
3、修改数据表结构
(1)添加字段
ALTER TABLE 表名
ADD 列1 数据类型[约束] [COMMENT 注释],
ADD 列2 数据类型[约束] [COMMENT 注释],
......;
(2)修改字段类型和约束
ALTER Table 表名称
MODIFY 列1 数据类型[约束] [COMMENT 注释],
MODIFY 列1 数据类型[约束] [COMMENT 注释],
......;
(3)修改字段的名称
ALTER TABLE 表名称
CHANGE 列1 新列名1 数据类型[约束] [COMMENT 注释],
CHANGE 列1 新列名1 数据类型[约束] [COMMENT 注释],
......;
(4)删除字段
ALTER TABLE 表名称
DROP 列1,
DROP 列2,
......;
4、数据库表字段约束
(1)数据库的范式
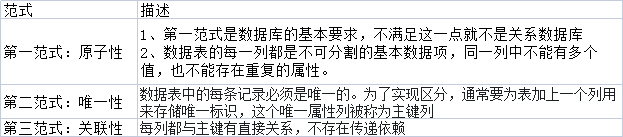
(2)字段约束
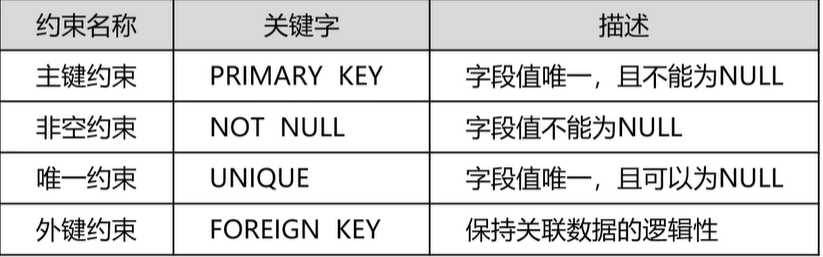
主键约束: a、主键约束要求字段的值在全表必须唯一,而且不能为NULL值 b、建议主键一定要使用数字类型,因为数字的检索速度会非常快 c、如果主键是数字类型,还可以设置自动生成自动增长
create table t_teacher( id int primary key auto_increment, ..... );
非空约束: a、非空约束要求字段的值不能为null值 b、null值为没有值,而不是“”空字符串
create table t_teacher( id int primary key auto_increment, name varchar(200) not null, married boolean note null default false ..... );
default 表示默认值 数据库中没有boolean数据类型,会转化成tinyint型,True用1表示,False用0表示
唯一约束: 唯一约束要求字段值如果不为null,那么在全表必须唯一
create table t_teacher( ..... tel char(11) not null unique ..... );
外键约束: 外键约束用来保证关联数据的逻辑关系 外键约束的定义是写在子表上的
create table t_dept( deptno int unsigned primary key, dname varchar(20) not null unique, tel char(4) unique ); create table t_temp( empno int unsigned primary key, ename varchar(20) not null, sex enum('男','女') not null, deptno int unsigned, hiredate date not null, foreign key (deptno) references t_dept(deptno) );
enum枚举值,选择枚举内容填写 建表时先建主表,后建从表 删数据时,先删从表,在删主表 外键约束的闭环问题: 如果形成外键闭环,我们将无法删除任何一张表的记录
5、数据库的索引机制
(1)创建索引
CREATE TABLE 表名称(
……,
INDEX [索引名称] (字段),
……
);
(2)添加索引
CREATE INDEX 索引名称 ON 表名称(字段);
ALTER TALBE 表名称 ADD INDEX [索引名](字段)
(3)查看数据表的所有索引:
SHOW INDEX FROM 表名称;
(4)删除索引:
DROP INDEX 索引名称 ON 表名;
(5)举例
CREATE TABLE t_message( id INT UNSIGNED PRIMARY KEY , content VARCHAR(200) NOT NULL, type ENUM("公告","通报","个人通知") NOT NULL, create_time TIMESTAMP NOT NULL, INDEX idx_type (type) ); DROP INDEX idx_type ON t_message; CREATE INDEX idx_type ON t_message(type); SHOW INDEX FROM t_message; DROP INDEX idx_type ON t_message; ALTER TABLE t_message ADD INDEX idx_type(type);
二、数据库的基本查询
1、数据表的基本查询
(1)记录查询
- 基本的查询语句是由SELECT和FROM关键字组成的
SELECT * FROM t_emp; SELECT empno,ename,sal FROM t_emp;
- SELECT 语句屏蔽了物理层的操作,用户不必关心数据的真实存储,交由数据库高效的查找数据
- 使用列别名:通常情况下,SELECT 子句中使用了表达式,那么这列的名字就默认为表达式,因此需要一种对列名重命名的机制
SELECT empno, sal*12 AS "income" FROM t_emp;
- 查询语句的子句执行顺序:1. 词法分析与优化(读取SQL语句)2.FROM 选择数据来源 3. SELECT 选择输出内容 (FROM 优先级高于SELECT)
2、如何让数据分页显示
- 如果结果集的记录很多,则可以使用LIMIT关键字限定结果集数量
语法:SELECT ...... FROM ...... LIMIT 起始位置,偏移量;
例如:
SELECT empno, ename FROM t_emp LIMIT 0,20;
- 数据分页的简写用法
如果LIMIT子句只有一个参数,它表示的是偏移值,起始值默认为0,以下两条查询语句是相等的
SELECT empno,ename FROM t_emp LIMIT 10; SELECT empno,ename FROM t_emp LIMIT 0,10;
- 执行顺序
FROM -> SELECT -> LIMIT
3、如何对查询结果集进行排序
- 如果没有设置,查询语句不会对结果进行排序。也就是说,如果想让结果集按照某种排序排列,就必须使用ORDER BY子句
SELECT ...... FROM ...... ORDER BY 列名[ASC|DESC];
【ASC 代表升序(默认),DESC代表降序,默认使用升序】
- 如果排序列是数字类型,数据库就按照数字大小排列,如果是日期类型就按照日期大小排序,如果是字符串就按照字符集序号排序
- 注意:默认情况下,如果两条数据排序字段内容相同,那么排序是什么样子?-----------按照主键大小排序
- 多个排序字段:使用ORDER BY规定首要排序条件和次要排序条件。数据库会先按照首要排序条件排序,如果遇到首要排序内容相同的记录,那么就会启用次要排序条件接着排序
SELECT empno, ename, sal, hiredate FROM t_emp ORDER BY sal DESC, hiredate ASC;
-
排序+分页
ORDER BY 子句书写的时候放在LIMIT子句的前面
FROM -> SELECT -> ORDER BY -> LIMIT
4、如果去除结果集中的重复记录
如果我们需要去除重复的记录,可以使用DISTINCT关键字来实现
语法: SELECT DISTINCT 字段 FROM ……;
例子:
SELECT DISTINCT job FROM t_emp;
- 注意事项
使用DISITINCT的SELECT子句中只能查询一列数据,如果查询多列,去除重复记录就会失效。
SELECT DISTINCT job,ename FROM t_emp; # 错误
DISTINCT关键字只能在SELECT子句中使用一次,而且必须写在第一个字段的前面
SELECT DISTINCT job, DISTINCT ename FROM t_emp; # 错误 SELECT ename,DISTINCT job FROM t_emp; # 错误
5、条件查询语句
(1)WHEREE子句实现数据的筛选
SELECT ...... FROM ...... WHERE 条件[AND| OR] 条件 ......;
SELECT empno,ename,sal FROM t_emp WHERE deptno=10 AND sal >= 2000;
SELECT empno,ename,sal FROM t_emp WHERE (deptno=10 OR deptno=20) AND sal >= 2000;
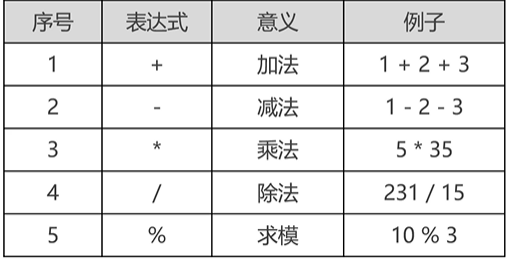
(2)四类运算符
- 算数运算符
ifnull语句
SELECT 10*null; 若结果为0可用ifnull语句
如果想让null值参与运算:SELECT 10*IFNULL(字段名,0);## 遇到null值就用0代替计算两日期差DateDiff语句
DATEDIFF(日期1,日期2)
NOW语句
用NOW()可以获取当前日期与时间
SELECT empno,ename,sal,hiredate FROM t_emp WHERE deptno=10 AND (sal+IFNULL(comm,0))*12>=15000 AND DATEDIFF(NOW(),hiredate)/365>=20;
- 比较运算符
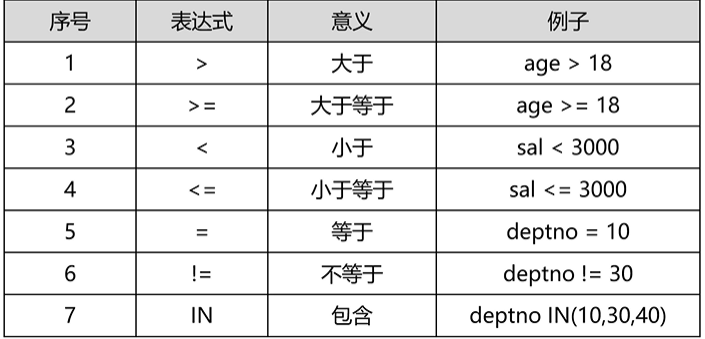

注:LIKE 模糊查询 如ename LIKE "A%"(名字以A开头),%A 名字以A结尾 ,%A% 名字中含有A,_A第 第二个字母为A
举例1:
SELECT empno,ename,sal,hiredate FROM t_emp WHERE deptno IN(10,20,30)AND job!="SALEMAN" AND hiredate<"1985-01-01";
举例2:
SELECT ename, comm,sal FROM t_emp WHERE comm IS NOT NULL AND sal BETWEEN 2000 AND 3000 AND ename LIKE "%A%";
举例3:
SELECT ename, comm,sal FROM t_emp WHERE comm IS NOT NULL AND sal BETWEEN 1000 AND 3000 AND ename REGEXP "^[\\u4e00-\\u9fa5]{2,4}$";
- 逻辑运算符
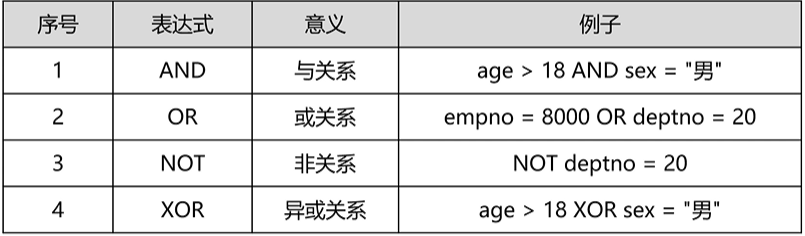
注意:
逻辑运算符的特殊:XOR异或关系 例如:age > 18 XOR sex = '男' # 多个条件判断结果相同,结果为FALSE;判断结果不同,结果为TRUE
SELECT ename,deptno FROM t_emp WHERE NOT deptno IN(10,20) XOR sal>=1000;
- 按位运算符

6、WHERE子句中条件执行的顺序
- 筛选的过程,where条件排序 1 有索引的条件放在前面,2 查询数据多的 3 普通查询条件
-
执行顺序:
from->where->select->order by-> limit
选择则数据来源(数据表):from
有条件查询的语法和运算符:where
显示结果集:select子句中的列别名和去除重复记录
数据摆列语法:order by
数据分页的语法:limit
三、数据库的高级查询
(1)聚合函数的使用【聚合函数不能出现在where子句里】
聚合函数在数据的查询分析中,应用十分广泛。聚合函数可以对数据求和、求最大值和最小值、求平均值等等。
- SUM函数
SUM函数用于求和,只能用于数字类型,字符类型的统计结果为0,日期类型统计结果是毫秒数相加
SELECT SUM(sal) FROM t_temp;
- MAX函数
MAX函数用于获取非空值得最大值。
SELECT MAX(comm) FROM t_emp;
- MIN函数
MIN函数用于获取非空值得最小值。
SELECT MIN(comm) FROM t_emp;
- AVG函数
AVG函数用于获取非空值得平均值,非数字数据统计结果为0
SELECT AVG(sal+IFNULL(comm)) FROM t_emp;
- COUNT函数
COUNT(*)用于获得包含空值的所有记录,COUNT(列名)用于获得包含非空值的记录数。
SELECT COUNT(*) FROM t_emp; SELECT COUNT(comm) FROM t_emp;
(2)分组查询的应用
- 分组:
默认情况下汇总函数是对全表范围内的数据做统计
GROUP BY子句的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对每个小区域分别进行数据汇总处理
SELECT deptno,AVG(sal) FROM t_emp GROUP BY deptno;
- 逐级分组
· 数据库支持多列分组条件,执行时候逐级分组
SELECT deptno,job,AVG(sal) FROM t_emp GROUP BY deptno,job;
对SELECT子句的要求
· 查询语句中如果含有GROUP BY子句,那么SELECT子句中的内容就必须要遵守规定:SELECT子句中可以包含聚合函数,或者GROUP BY子句的分组列,其余内容不可以出现在SELECT子句中
SELECT deptno,COUNT(*),AVG(sal) FROM t_emp GROUP BY deptno; 正确 SELECT deptno,COUNT(*),AVG(sal),sal FROM t_emp GROUP BY deptno; 错误
- 对分组结果集再次做汇总计算
SELECT deptno,COUNT(*),AVG(sal),MAX(sal),MIN(sal) FROM t_emp GROUP BY deptno WITH ROLLUP;
WITH ROLLUP可以对分组结果集再次做汇总计算,也就是都多个结果做聚合函数的总计算,非聚合函数为NULL值
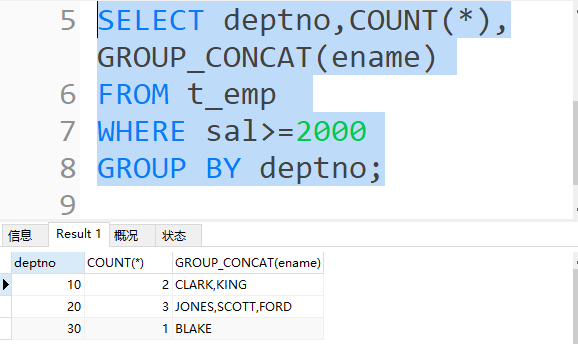
- GROUP_CONCAT函数
· GROUP_CONCAT函数可以把分组查询的某个字段拼接成一个字符串
SELECT deptno,GROUP_CONCAT(ename) FROM t_emp GROUP BY deptno;
- 各种子句的执行顺序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
(3)HAVING子句
- HAVING 子句不能独立存在,必须依赖于GROUP BY 语句
-
WHERE 对普通条件作判断,HAVING 对聚合函数作判断
- HAVING子句的特殊用法:按照数字1分组,MySQL会依据SELECT子句中的列进行分组,HAVING 子句也可以正常使用【GROUP BY 1 等于 GROUP BY SELECT的第一个数据】
select deptno from t_emp where hiredate>='1982-01-01' group by deptno having count(*)>=2; select deptno,count(*) from t_emp group by 1(1指的是select中第一个字段) #不建议 select deptno,count(*) from t_emp group by 1 having deptno in (10,20) #建议 select deptno,count(*) from t_emp where deptno in (10,20)group by 1
(4)表的连接
- 从多张表中提取数据:
从多张表中提取数据,必须指定关联的条件。如果不定义关联条件就会出现无条件连接,两张表的数据会交叉连接,产生笛卡尔积。
不定义关联条件:
select empno,ename,dname from t_emp join t_dept; # 错误
定义关联条件:
select e.empno,e.ename,d.dname from t_emp e join t_dept d on e.deptno = d.deptno;
- 表连接的分类
表连接分为两种:内连接和外连接
内连接是结果集中只保留符合连接条件的记录
外连接是不管符不符合连接条件,记录都要保留在结果集中
(5)表的内连接
- 内连接是最常见的一种表连接,用于查询多张关系表符合连接条件的记录
select ..... from 表1
[inner] join 表2 on 条件
[inner] join 表3 on 条件
.....
- 内连接的多种语法形式
SELECT ...... FROM 表1 JOIN 表2 ON 连接条件;
SELECT ...... FROM 表1 JOIN 表2 WHERE 连接条件;
SELECT ...... FROM 表1 ,表2 WHERE 连接条件;
SELECT e.empno,e.ename,d.dname FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno; SELECT e.empno,e.ename,d.dname FROM t_emp e JOIN t_dept d WHERE e.deptno=d.deptno; SELECT e.empno,e.ename,d.dname FROM t_emp e,t_dept d WHERE e.deptno=d.deptno;
- 练习
#1、查询每个员工的工号、姓名、部门名称、底薪、职位、工资等级 #内连接的数据表不一定必须有同名字段,只要字段之间符合逻辑关系就可以 SELECT e.empno,e.ename,d.dname,e.sal,e.job,s.grade FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal; #2、查询与SCOTT相同部门的员工 #第一个比第二个慢 SELECT ename FROM t_emp WHERE deptno=(SELECT deptno FROM t_emp WHERE ename="SCOTT") AND ename!="SCOTT"; #相同数据表也可以做表连接 SELECT e2.ename FROM t_emp e1 JOIN t_emp e2 ON e1.deptno=e2.deptno WHEREre e1.ename='SCOTT' AND e2.ename!='SCOTT'; #3、查询底薪超过公司平均底薪的员工 SELECT ename FROM t_emp WHERE sal>(SELECT AVG(sal) FROM t_emp); #错误表连接 SELECT e2.deptno,e2.ename,e2.sal FROM t_emp e1 JOIN t_emp e2 ON e2.sal>AVG(e1.sal); #正确表连接 SELECT e.deptno,e.ename,e.sal FROM t_emp e JOIN (SELECT AVG(sal) AS avg FROM t_emp) t ON e.sal>t.avg; #4、查询RESEARCH部门的人数、最高底薪、最低底薪、平均底薪、平均工龄 SELECT COUNT(*),MAX(e.sal),MIN(e.sal),AVG(e.sal),FLOOR(AVG(DATEDIFF(NOW(),e.hiredate)/365)) FROM t_emp e JOIN t_dept d ON e.deptno=d.deptno WHERE d.dname="RESEARCH"; #FLOOR()函数会将小数舍去;CELL()函数会将小数进位。 #5、查询每种职业的最高工资、最低工资、平均工资、最高工资等级和最低工资等级 SELECT e.job,MAX(e.sal+IFNULL(e.comm,0)),MIN(e.sal+IFNULL(e.comm,0)),AVG(e.sal+IFNULL(e.comm,0)),MAX(S.grade),MIN(S.grade) FROM t_emp e JOIN t_salgrade s ON (e.sal+IFNULL(e.comm,0)) BETWEEN s.losal AND s.hisal GROUP BY e.job; #6、查询每个底薪超过部门平均底薪的员工信息 SELECT e.empno,e.ename,e.sal FROM t_emp e JOIN (SELECT deptno,AVG(sal) AS avg FROM t_emp GROUP BY deptno) t ON e.deptno=t.deptno AND e.sal>t.avg;
(6)表的外连接
- 外连接与内连接的区别在于,除了符合条件的记录之外,结果集中还会保留不符合条件的记录。
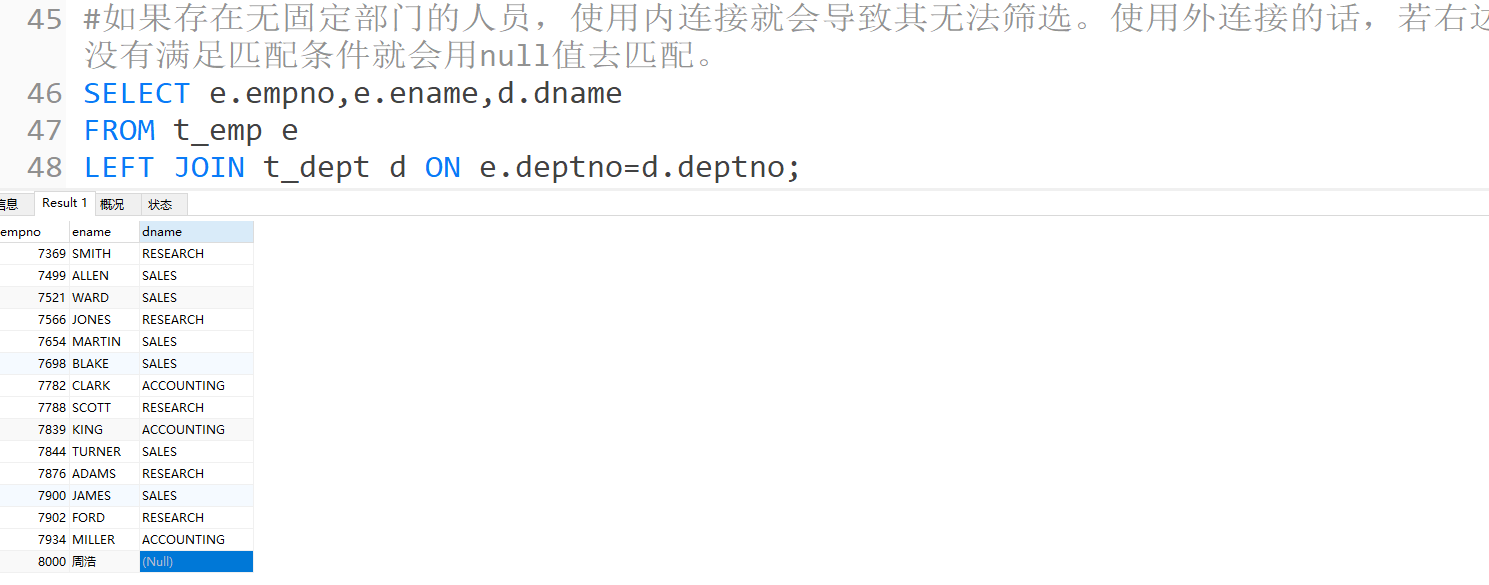
- 左连接和右连接:
左外连接就是保留左表所有的记录,与右表做连接。如果右表有符合条件的记录就与左表连接。如果右表没有符合条件的记录,就用null与左表连接。右外连接也是如此。
#查询每个部门的名称和部门的人数 SELECT d.dname, count(e.deptno) FROM t_dept d LEFT JOIN t_emp e ON e.deptno=d.deptno GROUP BY d.deptno; #查询每个部门的名称和部门的人数。如果没有部门的员工,部门名称用null替代 #union关键字可以将多个查询语句的结果集进行合并 (SELECT d.dname, count(e.deptno) FROM t_dept d LEFT JOIN t_emp e on e.deptno=d.deptno GROUP BY d.deptno) UNION (SELECT d.dname, count(*) FROM t_dept d RIGHT JOIN t_emp e ON e.deptno=d.deptno GROUP BY d.deptno) #查询每名员工的编号、姓名、部门、月薪、工资等级、工龄、上司编号、上司姓名、上司部门 SELECT e.empno,e.ename,d.dname,e.sal+IFNULL(e.comm,0),s.grade,FLOOR(DATEDIFF(NOW(),e.hiredate)/365),t.empno AS mgrno,t.ename AS mgrname,t.dname AS mgrdname FROM t_emp e LEFT JOIN t_dept d ON e.deptno=d.deptno LEFT JOIN t_salgrade s ON e.sal BETWEEN s.losal AND s.hisal LEFT JOIN (SELECT e1.empno,e1.ename,d1.dname FROM t_emp e1 JOIN t_dept d1 ON e1.deptno=d1.deptno) t ON e.mgr=t.empno;
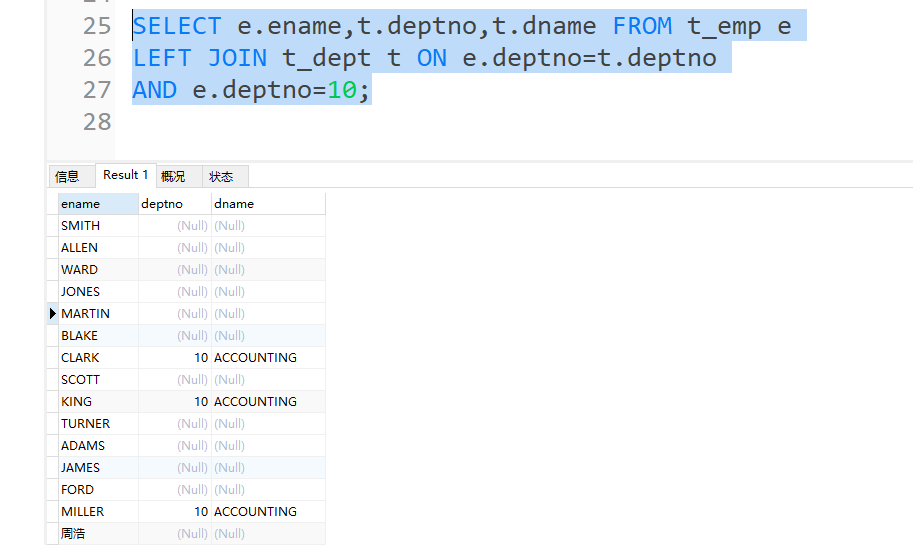
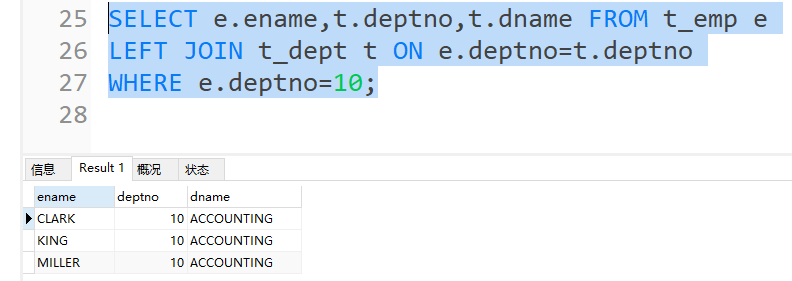
- 外连接的注意事项
内连接只保留条件的记录,所以查询条件写在on子句和where子句中的效果是相同的。但是外连接里,条件写在where子句里,不符合条件的记录是会被过滤掉的,而不是保留下来
(7)子查询的语法规则
- 子查询: 子查询是一种查询中嵌套查询的语句。
- 子查询的分类: 子查询可以写在三个地方:where子句、from子句、select子句,但是只有from子句子查询是最可取的。
- where子查询: 这种子查询最简单,最简单理解,但是却是效率最低的子查询
- from子查询: 这种子查询只会执行一次,所以查询效率很高
- select子查询: 这种子查询每输出一条记录的时候都要执行一次,查询效率很低
(8)单行和多行子查询语法规则
- 1.单行子查询的结果集只要一条记录,多行子查询结果集有多行记录
- 多行子查询只能出现在where子句和from子句中
- where子句中,可以使用in、all、any、exists关键字来处理多行表达式结果集的条件判断 all关键字:必须大于、小于或等于......子查询中所有的值 any关键字:只要大于、小于或等于......子查询中任意一值即可 exists关键字:把原来在子查询之外的条件判断,写到了子查询里面 exists语法:select ...... from 表名 where [not] exists(子查询);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号