Logstash 配置介绍
简介:
logstash是一个数据分析软件,主要目的是分析log日志。整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。
首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
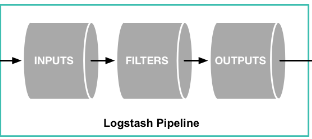
从input读取事件源,(经过filter解析和处理之后),从output输出到目标存储库(elasticsearch或其他)。
它组要组成部分是数据输入,数据源过滤,数据输出三部分。
logstash pipeline 包含两个必须的元素:input和output,和一个可选元素:filter。
数据源input使用详解:
input 及输入是指日志数据传输到Logstash中。其中常见的配置如下:
file:从文件系统中读取一个文件,很像UNIX命令 “tail -0a”syslog:监听514端口,按照RFC3164标准解析日志数据
redis:从redis服务器读取数据,支持channel(发布订阅)和list模式。redis一般在Logstash消费集群中作为"broker"角色,保存events队列共Logstash消费。
beats: 略lumberjack:使用
lumberjack协议来接收数据,目前已经改为 logstash-forwarder。
file:
input{
file{
#path属性接受的参数是一个数组,其含义是标明需要读取的文件位置
path => [‘pathA’,‘pathB’]
#type官方解释是字符串解释
type => nginx...
#表示多就去path路径下查看是够有新的文件产生。默认是15秒检查一次。
discover_interval => 15
#排除那些文件,也就是不去读取那些文件
exclude => [‘fileName1’,‘fileNmae2’]
#被监听的文件多久没更新后断开连接不在监听,默认是一个小时。
close_older => 3600
#在每次检查文件列 表的时候, 如果一个文件的最后 修改时间 超过这个值, 就忽略这个文件。 默认一天。
ignore_older => 86400
#logstash 每隔多 久检查一次被监听文件状态( 是否有更新) , 默认是 1 秒。
stat_interval => 1
#sincedb记录数据上一次的读取位置的一个index
sincedb_path => ’$HOME/. sincedb‘
#logstash 从什么 位置开始读取文件数据, 默认是结束位置 也可以设置为:beginning 从头开始
start_position => ‘beginning’
#注意:这里需要提醒大家的是,如果你需要每次都从同开始读取文件的话,关设置start_position => beginning是没有用的,你可以选择sincedb_path 定义为 /dev/null
}
}
例子:
input {
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
}
}
filter {
}
output {
stdout {}
}
注意:
文件的路径名需要时绝对路径
支持globs写法
如果想要监听多个目标文件可以改成数组
syslog:
syslog { # 系统日志方式
type => "system-syslog" # 定义类型
port => 10514 # 定义监听端口
}
beats(filebeats):
FileBeat 隶属于 Beats。目前 Beats 包括四种工具。
Packetbeat 搜集网络数据流量
Topbeat 搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据
Filebeat 搜集文件数据Winlogbeat 搜集
Windows 事件日志数据
工作原理 :在需要收集日志的所有服务上部署 filebeat(不推荐使用 logstash 来收集日志,因为 logstash 相对来说极为耗费系统内存),logstash 用于监控并过滤收集日志,日志收集在一起交给全文搜索服务 ElasticSearch ,可以用 ElasticSearch 进行自定义搜索通过 Kibana 来结合自定义搜索进行页面展示。
beats { # filebeats方式
port => 5044
}
以上文件来源file,syslog,beats 只能选择其中一种
数据库过滤filter:
Fillters 在Logstash处理链中担任中间处理组件。他们经常被组合起来实现一些特定的行为来,处理匹配特定规则的事件流。常见的filters如下
grok:解析无规则的文字并转化为有结构的格式。Grok 是目前最好的方式来将无结构的数据转换为有结构可查询的数据。有120多种匹配规则,会有一种满足你的需要。
mutate:mutate filter 允许改变输入的文档,你可以从命名,删除,移动或者修改字段在处理事件的过程中。drop:丢弃一部分events不进行处理,例如:debug events。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
它的主要作用就是把数据解析成规则的json键值对格式便于输出到其他组件中使用。
输出配置output:
outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。一些常用的outputs包括:
elasticsearch:如果你计划将高效的保存数据,并且能够方便和简单的进行查询.
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。http://graphite.wikidot.com/。
statsd:statsd是一个统计服务,比如技术和时间统计,通过udp通讯,聚合一个或者多个后台服务,如果你已经开始使用
statsd,该选项对你应该很有用。
默认情况下将过滤扣的数据输出到elasticsearch,当我们不需要输出到ES时需要特别声明输出的方式是哪一种,同时支持配置多个输出源
output {
elasticsearch {
hosts => ["192.168.137.25:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号