
爬虫常用技巧
今天跟大家分享几个
我在爬虫中用到的技巧

技巧一
爬取人家网站的时候频率不要太高,
有事没事睡一会,睡久了没效率
睡短了,被反爬了,那就尴尬了....
随机数更具有欺骗性
所以睡多久,random决定!
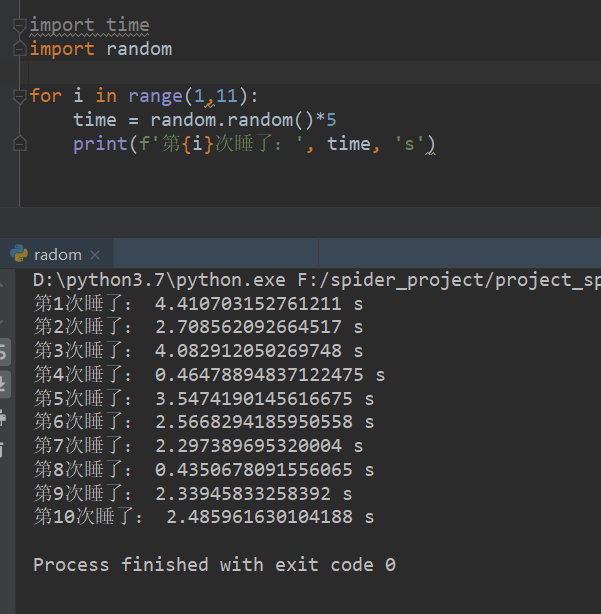
所以可以试着在爬虫代码加入这句代码
让子弹飞一会
time.sleep(random.random()*5)
技巧二
User-Agent中文名为用户代理,简称 UA,
它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU
类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
简单来说就是模拟浏览器去访问页面,
这样才不会被网站反爬到。
但是哪里去搞user-agnet呢?
随机数更具有欺骗性
所以哪里搞?我来决定!
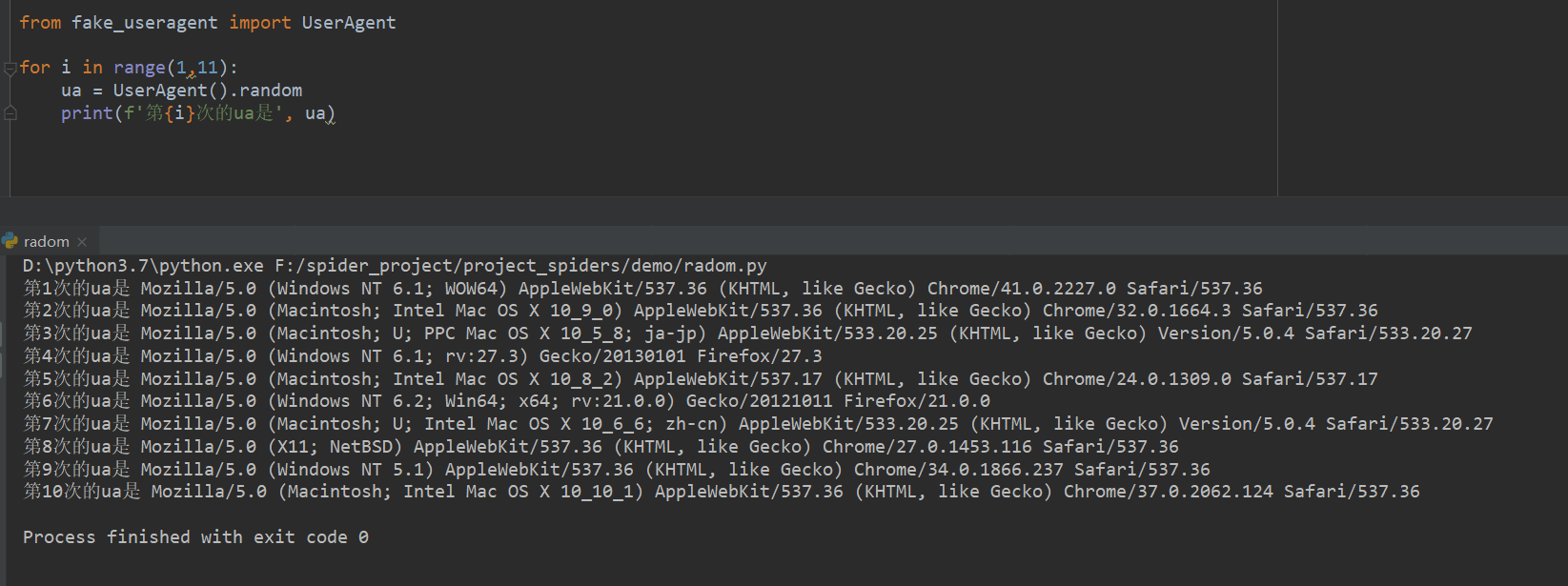
够用不?老板
所以可以试着在爬虫代码加入这句代码
让ua更具有欺骗性
headers= {'User-Agent':str(UserAgent().random)}
技巧三
让你事半功倍的浏览器插件
插件使用之前:

插件使用之后:

技巧Ⅳ
巧用pprint
这跟上面那个效果差不多,只不过刚才那个是在浏览器中查看的
而这个我们是在pycharm中查看的
来看效果吧
print()打印,不知道你感觉如何,我一脸懵逼
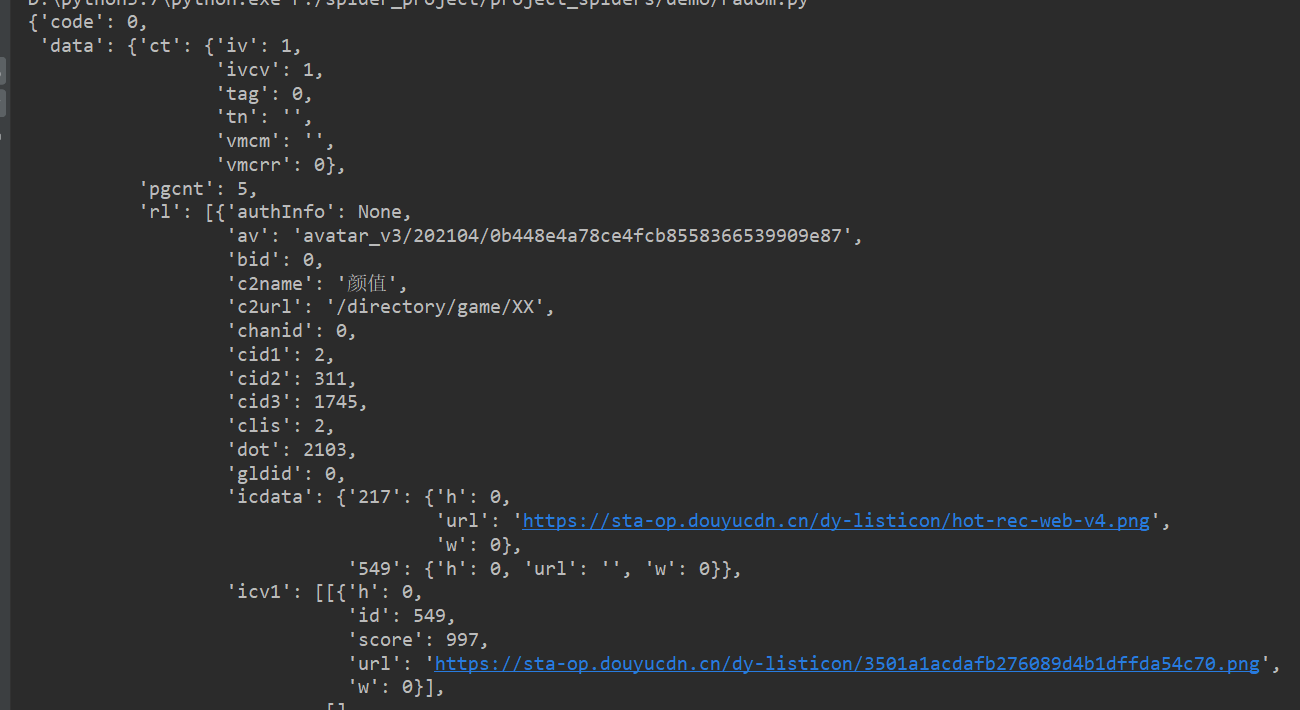
import requests
url = 'https://www.douyu.com/gapi/rknc/directory/yzRec/1'
resp = requests.get(url).json()
print(resp)
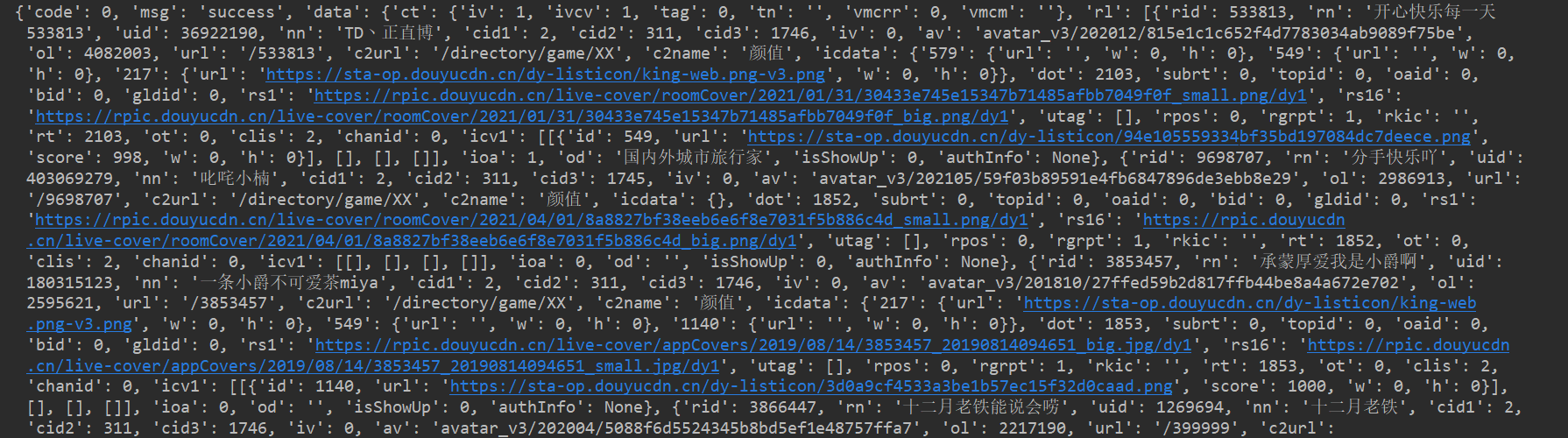
pprint()打印,这种结构看起来如何呢?
技巧Ⅴ
对于页面解析最强大的当然是正则表达式,这个对于不同网站不同的使用者都不一样,
就不用过多的说明,附两个比较好的网址:
正则表达式入门:
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
正则表达式在线测试:
http://tool.oschina.net/regex/
其次就是解析库了,常用的有两个lxml和BeautifulSoup,对于这两个的使用介
绍两个比较好的网站:
lxml:http://my.oschina.net/jhao104/blog/639448
BeautifulSoup:http://cuiqingcai.com/1319.html
对于这两个库,我的评价是,都是HTML/XML的处理库,
Beautifulsoup纯python实现,效率低,但是功能实用,
比如能用通过结果搜索获得某个HTML节点的源码;
lxml C语言编码,高效,支持Xpath。
技巧Ⅵ
在一些网站服务中,除了对 user-agent 的身份信息进行检测、
也对客户端的 ip 地址做了限制,
如果是同一个客户端访问此网站服务器的次数过多就会将其识别为爬虫,
因而,限制其客户端 ip 的访问。这样的限制给我们的爬虫带来了麻烦,所以使用代理 ip 在爬虫中是非常有必要的。
这里我给大家提供一下两个网站供参考
66代理:http://www.66ip.cn/6.html
快代理:https://www.kuaidaili.com/free/
大家可以将这些ip使用爬虫下载到本地,然后检查每一个ip的状态码判断其是否可用。
这样每次使用爬虫下载文件的时候。
只需使用random随机使用一个就可以。
技巧Ⅶ
验证码我们在很多网站会遇到,如果请求量大了之后就会遇到验证码的情况。
最让人诟病的12306,其实也是一定程度上的防止非正当请求的产生。
对于验证码,可以通过OCR来识别图片,Github上面有很多大神分享的代码可以用,可以去看看。
简单的OCR识别验证码:
from PIL import Image
import tesserocr
#tesserocr识别图片的2种方法
img = Image.open("code.jpg")
verify_code1 = tesserocr.image_to_text(img)
#print(verify_code1)
verify_code2 = tesserocr.file_to_text("code.jpg")
技巧Ⅷ
headers这应该是最常见的,最基本的反爬虫手段,主要是初步判断你是否是真实的浏览器在操作。
遇到这类反爬机制,可以直接在自己写的爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中。
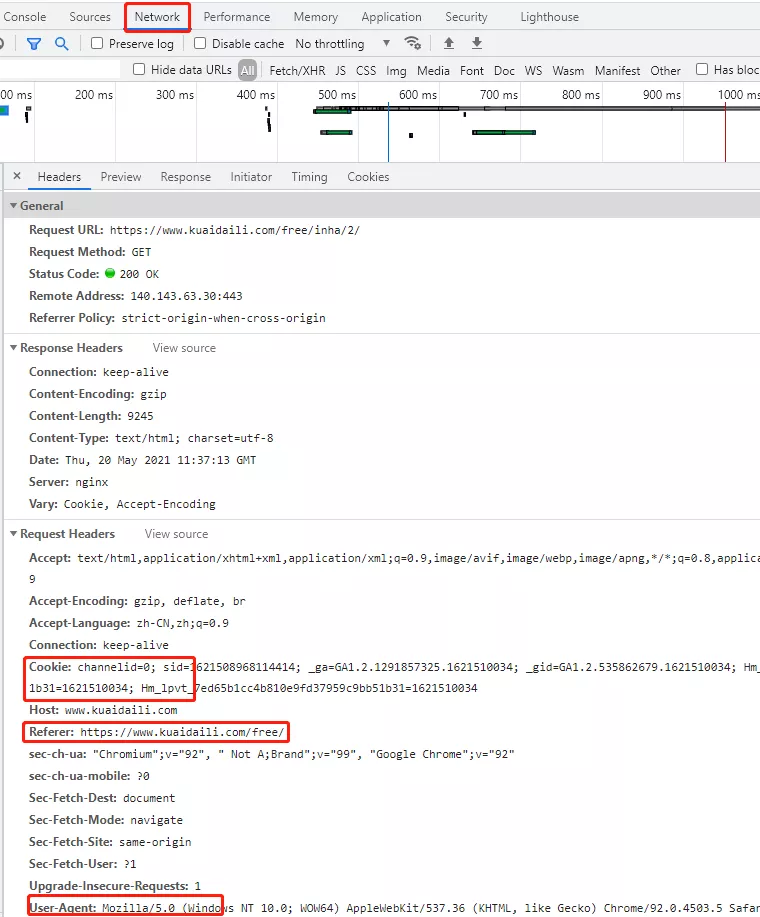
以edge浏览器为例,浏览器中打开页面;
第一步:点击上图中“网络”标签,然后刷新或载入页面
第二步:在右侧“标头”下方的“请求标头”中的所有信息都是headers内容,添加到请求中即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号