day03-面向对象高级3-内部类&枚举&泛型
1,内部类
回顾:之前学了类的四个成员,分别是成员变量,成员方法,代码块,构造器, 现在这是第五个成员,内部类;前三个作了解,第四个重点学习。
内部类的应用场景🎄
场景:当一个类的内部,包含了一个完整的事物,且这个事物没有必要单独设计时,就可以把这个事物设计成内部类。
比如:发动机中的引擎部分,就可以设计为内部类
public class Car{
// 内部类
public class Engine{
}
}
1,成员内部类(了解)
就是类中的一个普通的成员,类似前面的成员变量和方法。
public class Outer {
// 成员内部类
public class Inner {
}
}
创建对象格式:
外部类名.内部类名 对象名 = new 外部类(...).new 内部类(...);
Outer.Inner in = new Outer().new Inner();
2,静态内部类(了解)
静态内部类:有static修饰的内部类,属于外部类自己持有。
public class Outer{
// 静态内部类
public static class Inner{
}
}
创建对象的格式:
外部类名.内部类名 对象名 = new 外部类.内部类(…);
Outer.Inner in = new Outer.Inner();
3,局部内部类(了解)
局部内部类是定义在在方法中、代码块中、构造器等执行体中。
public class Test {
public static void main(String[] args) {
}
public static void go(){
class A{
}
abstract class B{
}
interface C{
}
}
}
从上面的代码中可以发现,在方法内中定义的内部类,如果要使用,就需要去new 或者是先实现这个接口,或继承这个抽象类,然后在调用其中的方法,这种方法很鸡肋,所以就有了匿名内部类的技术,能够节省很多对于业务代码没有用的代码,如下:
4,匿名内部类🔺
就是一种特殊的局部内部类;所谓匿名:指的是程序员不需要为这个类声明名字
new 类或接口(参数值…) {
类体(一般是方法重写);
};
new Animal(){
@Override
public void cry() {
}
};
观察可以得到,这里是直接new接口或者抽象类,或者父类,然后重写或者实现其中的业务代码;
而后面的大括号就代表着当前的对象,只是因为匿名,所以没有名字(自己看是没有名字,其实底层还是有的);因为大括号就相当于这个对象,所以可以在大括号之后直接调用内部类中实现的方法。即如下:
new Animal(){
@Override
public void cry() {
System.out.print("hello")
}
}.cry();
当然后面代表对象,就可以用其父类或者接口来接收这个对象;以便于后面多次的使用这个对象
Animal animal = new Animal(){
@Override
public void cry() {
System.out.print("hello")
}
};
animal.cry();
现在就探究刚才java内部是否为匿名内部类赋予名字
当在主方法中new两个内部类的时候,默认的名字如下:

命名方式: 当前类名$第几个内部类
特点:匿名内部类本质就是一个没有名字的子类,并会立即创建出这个子类的对象。
作用:用于更方便的创建一个子类对象。
应用场景:
通常作为一个参数传输给方法,案例代码如下:
public class Test {
public static void main(String[] args) {
// 目标:认识匿名内部类,并掌握其作用。
Swimming s1 = new Swimming() {
@Override
public void swim() {
System.out.println(“狗🏊飞快~~~”);
}
};
go(s1);
go(new Swimming() {
@Override
public void swim() {
System.out.println(“猫🏊也还行~~~");
}
});
}
public static void go(Swimming s){
System.out.println("开始============");
s.swim();
}
}
2,枚举
1,枚举入门
枚举是一种特殊的类。
枚举的格式:
修饰符 enum 枚举类名{
名称1 , 名称2, ... ;
其他成员…
}
注意:
-
枚举类中的第一行,只能写一些合法的标识符(名称),多个名称用逗号隔开。
-
这些名称,本质是常量,每个常量都会记住枚举类的一个对象。
2,枚举类的特点
public enum A{
X , Y , Z;
}
反编译得到的结果如下:
Compiled from “A.java"
public final class A extends java.lang.Enum<A> {
public static final A X = new A();
public static final A Y = new A();
public static final A Z = new A();
public static A[] values();
public static A valueOf(java.lang.String);
}
-
枚举类的第一行只能罗列一些名称,这些名称都是常量,并且每个常量记住的都是枚举类的一个对象。
-
枚举类的构造器都是私有的(写不写都只能是私有的),因此,枚举类对外不能创建对象。
-
枚举都是最终类,不可以被继承。
-
枚举类中,从第二行开始,可以定义类的其他各种成员。
-
编译器为枚举类新增了几个方法,并且枚举类都是继承:java.lang.Enum类的,从enum类也会继承到一些方法。
public static A[] values(); 返回当前枚举类中的对象数组
public static A valueOf(java.lang.String); 判断是不是这个枚举类中的对象
回顾一下单例设计模式的要求:
- 构造器私有化
- 定义一个私有的类变量记住类的一个对象
- 定义一个类方法,返回对象
在枚举中就很容易实现单例模式中的饿汉式: 因为枚举类直接满足,实现代码如下:无敌
// 枚举类
public enum MySystem {
MAIN_MENU;
}
// 测试类
class Test{
public static void main(String[] args) {
MySystem mainMenu1 = MySystem.MAIN_MENU;
MySystem mainMenu2 = MySystem.MAIN_MENU;
System.out.println(mainMenu1 == mainMenu2);
}
}
因为生成的对象是final的所以必然相同;
3,枚举的应用场景
通过需求来学习:这个时候就可以使用枚举,防止有其他不符合的数据引入,比如周八,但是当我们使用了枚举类作为参数的时候,使用者只能使用枚举中规定的数据。这样就避免了这个错误
* 一周有七天, 请编写方法实现, 接受调用者传入的星期选项, 做不同的操作
* 周一: 爬山
* 周二: 游泳
* 周三: 跑步
* 周四: 健身房
* 周五: 蹦极
* 周六: 方特游玩
* 周日: 在家休息
* Monday、Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday
定义一个枚举类:
public enum Week {
Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday;
}
定义一个判断的方法:根据不同的时间去做不同的事情
class WeekTest{
public String getHandle(Week week){
String str = "";
switch (week){
case Monday -> str = "爬山";
case Tuesday -> str = "游泳";
case Wednesday -> str = "跑步";
case Thursday -> str = "健身房";
case Friday -> str = "蹦极";
case Saturday -> str = "方特游玩";
case Sunday -> str = "在家休息";
}
return str;
}
}
测试类:
class MainTest{
public static void main(String[] args) {
System.out.println(new WeekTest().getHandle(Week.Friday));
}
}
通过上面的代码枚举的好处,就很容易体现出了,能够按照自己定义的内容去作为参数,传值,同样,也符合java面向对象的思想。
总结:
-
如果使用常量来表示一组信息,并作为参数传输的缺点是参数值不受约束,无法从语法层次对参数值进行限制
-
如果使用枚举表示一组信息,并作为参数传输的优势是代码可读性好,且可以对参数值进行约束,限制方法的调用者必须从给定的枚举对象中选择使用!
3,泛型
1,泛型入门
所谓泛型指的是,在定义类、接口、方法时,同时声明了一个或者多个类型变量(如:
2,自定义泛型
格式如下:
//这里的<T,W>其实指的就是类型变量,可以是一个,也可以是多个。
public class 类名<T,W>{
}
//定义一个泛型类,用来表示一个容器
//容器中存储的数据,它的类型用<E>先代替用着,等调用者来确认<E>的具体类型。
public class MyArrayList<E>{
private Object[] array = new Object[10];
//定一个索引,方便对数组进行操作
private int index;
//添加元素
public void add(E e){
array[index]=e;
index++;
}
//获取元素
public E get(int index){
return (E)array[index];
}
}
3,泛型接口的格式
//这里的类型变量,一般是一个字母,比如<E>
public interface 接口名<类型变量>{
}
4,泛型方法的格式
public <泛型变量,泛型变量> 返回值类型 方法名(形参列表){
}
5,泛型限定
泛型限定的意思是对泛型的数据类型进行范围的限制。有如下的三种格式
- 表示任意类型
- 表示指定类型或者指定类型的子类
- 表示指定类型或者指定类型的父类
示例代码如下:
假设有Car作为父类,BENZ,BWM两个类作为Car的子类,代码如下
class Car{}
class BENZ extends Car{}
class BWN extends Car{}
public class Test{
public static void main(String[] args){
//1.集合中的元素不管是什么类型,test1方法都能接收
ArrayList<BWM> list1 = new ArrayList<>();
ArrayList<Benz> list2 = new ArrayList<>();
ArrayList<String> list3 = new ArrayList<>();
test1(list1);
test1(list2);
test1(list3);
//2.集合中的元素只能是Car或者Car的子类类型,才能被test2方法接收
ArrayList<Car> list4 = new ArrayList<>();
ArrayList<BWM> list5 = new ArrayList<>();
test2(list4);
test2(list5);
//2.集合中的元素只能是Car或者Car的父类类型,才能被test3方法接收
ArrayList<Car> list6 = new ArrayList<>();
ArrayList<Object> list7 = new ArrayList<>();
test3(list6);
test3(list7);
}
public static void test1(ArrayList<?> list){
}
// 定义了上限
public static void test2(ArrayList<? extends Car> list){
}
// 定义了下限
public static void test3(ArrayList<? super Car> list){
}
}
6,泛型擦除
也就是说泛型只能编译阶段有效,一旦编译成字节码,字节码中是不包含泛型的。而且泛型只支持引用数据类型,不支持基本数据类型。
把下面的代码的字节码进行反编译
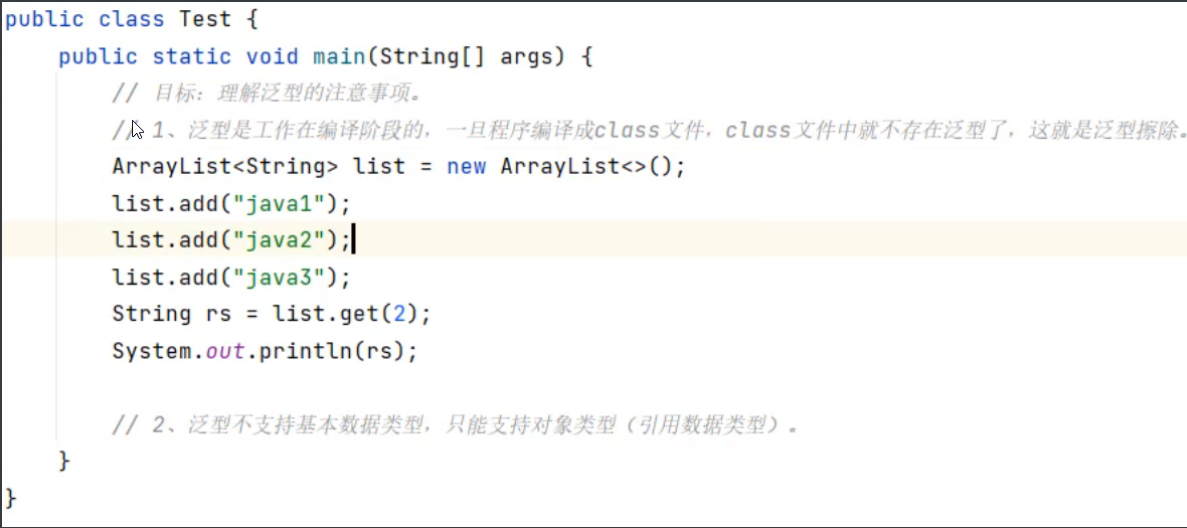
下面是反编译之后的代码:
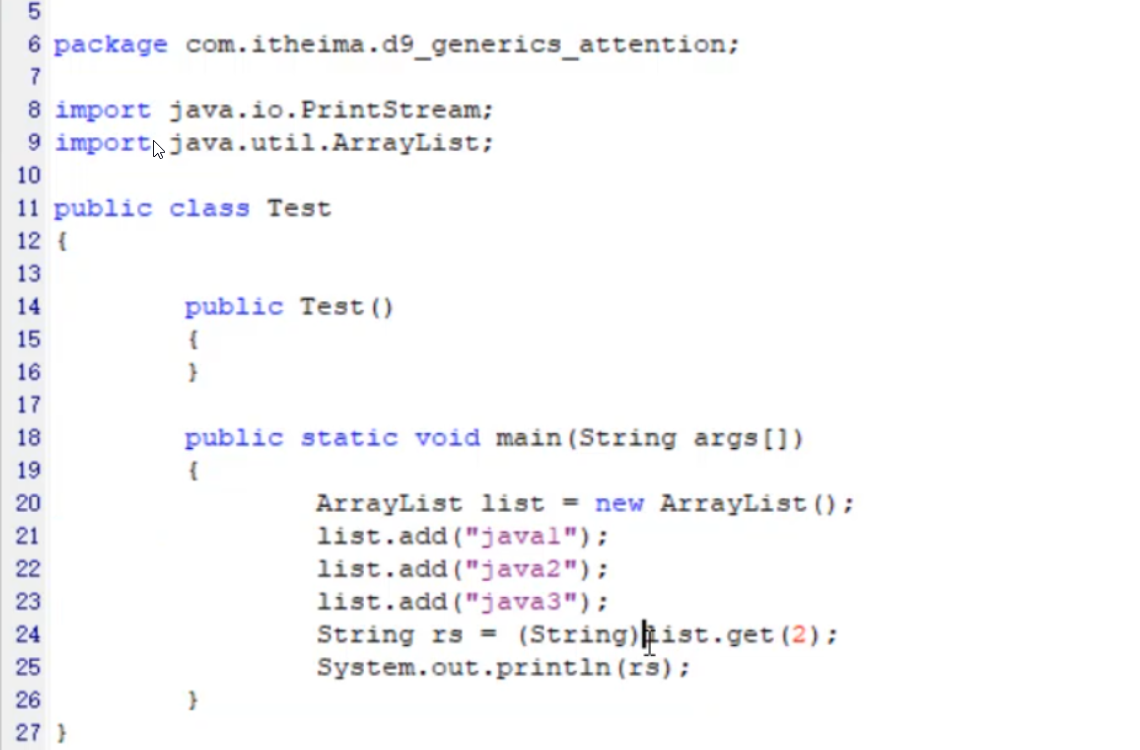
4,常用API
1,Object类
Object类是Java中所有类的祖宗类,因此,Java中所有类的对象都可以直接使用Object类中提供的一些方法。
这里暂且先介绍三个Object中的方法
1.1 toString方法
public String toString()
调用toString()方法可以返回对象的字符串表示形式。
默认的格式是:“包名.类名@哈希值16进制”
也就是如果不重写toString方法的默认返回的是 包名.类名@哈希值16进制,在toString的 方法解释中,有这样一句话

所以我们一般都会重写这个方法,以便于输出我们自己类中的属性内容
1.2 equals(Object o)方法
public boolean equals(Object o)
判断此对象与参数对象是否"相等"
----------------------------------------------------------------------------------
public boolean equals(Object obj) {
return (this == obj);
}
这里的底层使用的是 == 这个比较运算符,如果是基本数据类型,比较的就是其值,如果是引用数据类型那么比较的就是其地址;但是我们一般想比较引用数据类型的内容,并不是其地址值,所以我们就需要重写equals()方法来达到我们的目的;
示例代码如下:
public class Student{
private String name;
private int age;
public Student(String name, int age){
this.name=name;
this.age=age;
}
@Override
public String toString(){
return "Student{name=‘"+name+"’, age="+age+"}";
}
//重写equals方法,按照对象的属性值进行比较
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
}
1.3 clone() 方法
clone()方法,克隆。意思就是某一个对象调用这个方法,这个方法会复制一个一模一样的新对象,并返回。
注意这里并不是,简单的地址的引用:下面的表示是错误的,需要正确的理解其含义
Object o = new Object();
// 这只是对对象地址的引用,并不是clone ,因为clone是复制出一个一模一样的新的对象
Object o1 = o;
方法如下:
public Object clone()
克隆当前对象,返回一个新对象
想要调用clone()方法,必须让被克隆的类实现Cloneable接口。如我们准备克隆User类的对象,代码如下
public class User implements Cloneable{
private String id; //编号
private String username; //用户名
private String password; //密码
private double[] scores; //分数
public User() {
}
public User(String id, String username, String password, double[] scores) {
this.id = id;
this.username = username;
this.password = password;
this.scores = scores;
}
//...get和set...方法省略
@Override
public String toString() {
return "User{" +
"id='" + id + '\'' +
", username='" + username + '\'' +
", password='" + password + '\'' +
", scores=" + Arrays.toString(scores) +
'}';
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
接着,写一个测试类,克隆User类的对象。并观察打印的结果
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
User u1 = new User("1","zhangsan","wo666",new double[]{99.0,99.5});
//调用方法克隆得到一个新对象
User u2 = (User) u1.clone();
System.out.println(u1);
System.out.println(u2);
}
}
结果如下:这样子就完成了拷贝
User{id='1', username='zhangsan', password='wo666', scores=[99.0, 99.5]}
User{id='1', username='zhangsan', password='wo666', scores=[99.0, 99.5]}
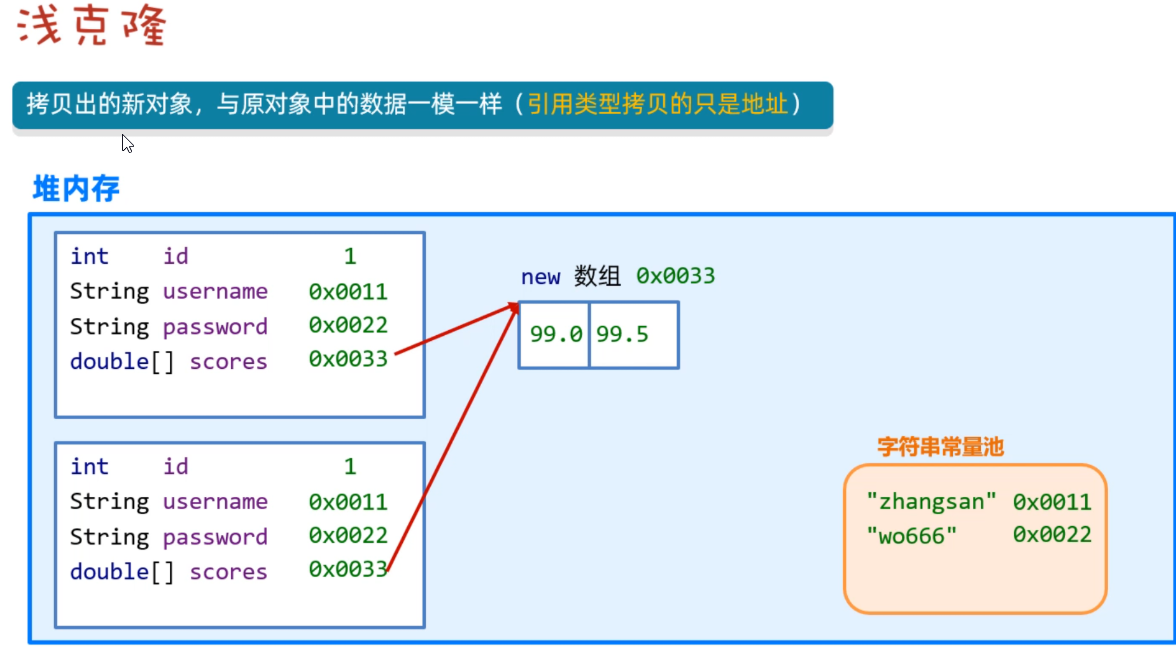
但是对于其中的引用数据类型,会发现clone的不是新的一个对象,而是原来对象的一个引用,可以做个小测试验证,这里的scores数组,就是一个引用类型,下面我们就通过在clone之后,用之前的对象去修改其中的内容的时候,看成龙之后的数据是否会被修改;
测试类中添加这一句:u1.getScores()[1] = 1000;
System.out.println(u1);
u1.getScores()[1] = 1000;
System.out.println(u2);
结果如下:
User{id='1', username='zhangsan', password='wo666', scores=[99.0, 99.5]}
User{id='1', username='zhangsan', password='wo666', scores=[99.0, 1000.0]}
发现被修改了,通过下图来理解其中的原因
还有一种拷贝方式,称之为深拷贝,拷贝原理如下图所示
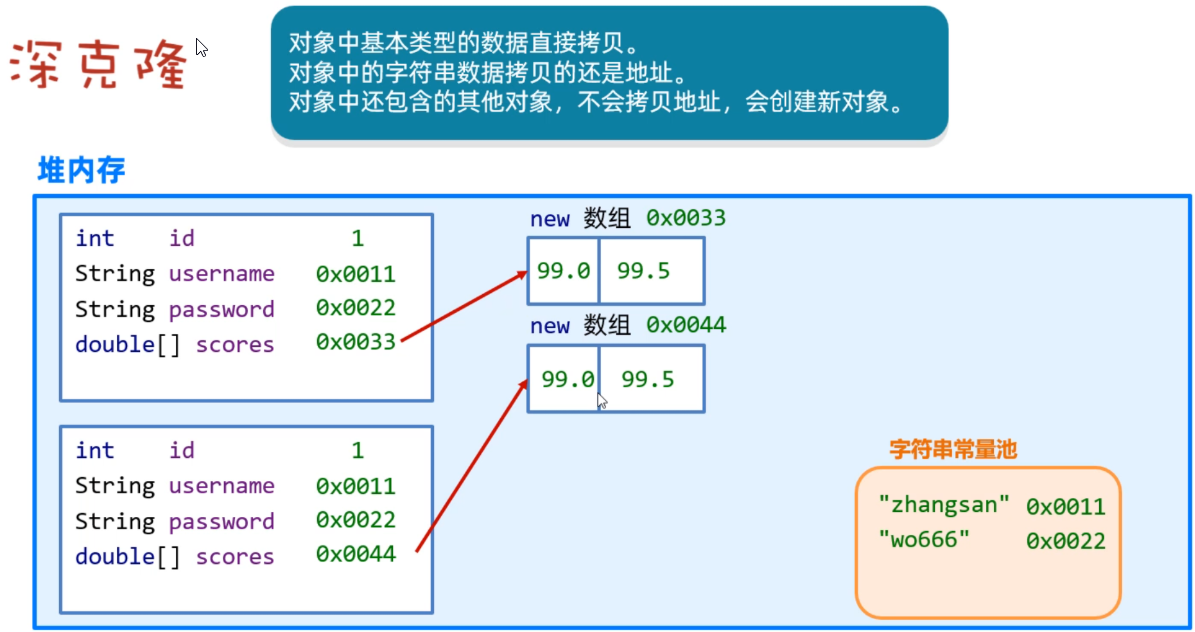
因为clone中默认的是使用浅拷贝,所以如果我们需要进行深拷贝的话,就需要我们自己来重写clone方法,重写clone代码如下:实现对User类的深拷贝。
@Override
protected Object clone() throws CloneNotSupportedException {
//先克隆得到一个新对象
User u = (User) super.clone();
//再将新对象中的引用类型数据,再次克隆
u.scores = u.scores.clone();
return u;
}
首先先将自己的基本数据类型进行一个浅拷贝,然后再对引用类型进行一个拷贝。
这里的数组,因为其中的数据是基本数据类型,是神拷贝,所以就可以直接调用当前对象的clone方法,对数组中的数据和当前对象进行一个拷贝。然后在将拷贝后的对象的引用给原本的数组,这样就实现了对User的一个深拷贝。
2,Objects
Objects是一个工具类,提供了一些方法可以对任意对象进行操作
记一个就可以,
public static boolean equals(Object a, Object b)
// 源码 先做非空判断,在比较两个对象,通过这个方法就可以避免空指针异常的出现
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
3,基本数据类型的包装类
Java中有一句很经典的话,万物皆对象,Java中的8种基本数据类型还不是对象,所以要把它们变成对象,变成对象之后,可以提供一些方法对数据进行操作。
Java中8种基本数据类型都用一个包装类与之对一个,如下所示:
| 基本数据类型 | 对应的包装类(引用数据类型) |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
首先知道两个概念: 装箱 基本数据类型 —> 对应的包装类
拆箱 包装类 —> 基本的数据类型
在jdk5之前都是自己手动的进行装箱和拆箱:
方法如下 拿 Integer 举例:
装箱使用的是 Integer中的一个静态方法valueOf(int类型),由此转换为Integer对象
装箱:
Integer integer = Integer.valueOf(100);
拆箱使用的是 Integer类中的成员方法 intValue()方法实现的
拆箱:
int i = integer.intValue();
这样就可以通过两个方法来实现由基本数据类型,转换为其对应的包装类型。
而在jdk5之后java实现了自动的转换,即如下代码:
// 自动装箱
Integer num = 1001;
// 自动拆箱
int num2 = num;
另外在开发中,我们总会遇到将字符串转换为基本的数据类型:而当我们使用了包装类型之后就可以很容易的来实现字符串到基本数据类型的转换;
具体的方法为 包装类.parseXxx(“字符串” ),这样即可装换为Xxx类型。代码如下
int i = Integer.parseInt("123");
这样就可以把一个字符串转换为基本数据类型
这里特此说明,Character中没有parseChar(“ ”)方法,可以通过字符串的charAt()方法来获取
对于将基本数据类型转换为字符串,我们只需要拼接空串就可以代码如下:
String str = 123 + "";
总结:对于包装类只需要知道装箱和拆箱和原理,以及字符串转基本数据类型,基本数据类型转字符串即可
最后Integer中还有一个注意的地方,就是在Integer自动装箱的时候,代码的实现:源码如下:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
先通过下面的代码来体验一下:
Integer integer1 = 200;
Integer integer2 = 200;
Integer integer3 = 20;
Integer integer4 = 20;
System.out.println(integer1 == integer2); // false
System.out.println(integer3 == integer4); // true
看结果不免会产生怀疑:为啥呢?原来是这样呀!结合这源码
在Integer类装载入内存时,把[-128, 127]范围内的整型数据装包成Integer类,并将其对应的引用放入到cache数组中。
从上面的源码可以看出,valueOf()在返回之前,会进行判断,判断当前 i的值是否在 -128到127之间。如果存在,则直接返回引用,不再重新开辟内存空间。如果不存在,就创建一个新的对象。利用缓存,这样做既能提高程序执行效率,还能节约内存。
最后我们只需要记住,当值在 -128到127之间的时候不会创建新的对象直接返回缓存中的数值,而当不在这个范围就会new Integer(),因为开辟了新的空间所以这里为false

 浙公网安备 33010602011771号
浙公网安备 33010602011771号