


关于数组的前沿技术介绍 - 详解
目录
前沿
而在现代软件开发中,数组的高级用法、性能优化、替代结构以及在高并发、大数据、AI 等领域中的演进与前沿应用。
以下是对数组的各种前沿技术的介绍:
1、高性能数组处理:向量化
1、定义
现代 CPU 支持 SIMD(Single Instruction, Multiple Data) 指令,可以一条指令处理多个数组元素。
Java 中的 Project Panama(Project Vector)
- Oracle 正在推进的项目,旨在让 Java 更好地支持向量化计算。
- 提供
Vector API(JEP 338, 438, 448),允许开发者编写自动向量化的代码。
⚠️注意:
在编译和使用的过程中,至少需要java16以上的版本。
运行时加参数:--add-modules jdk.incubator.vector |

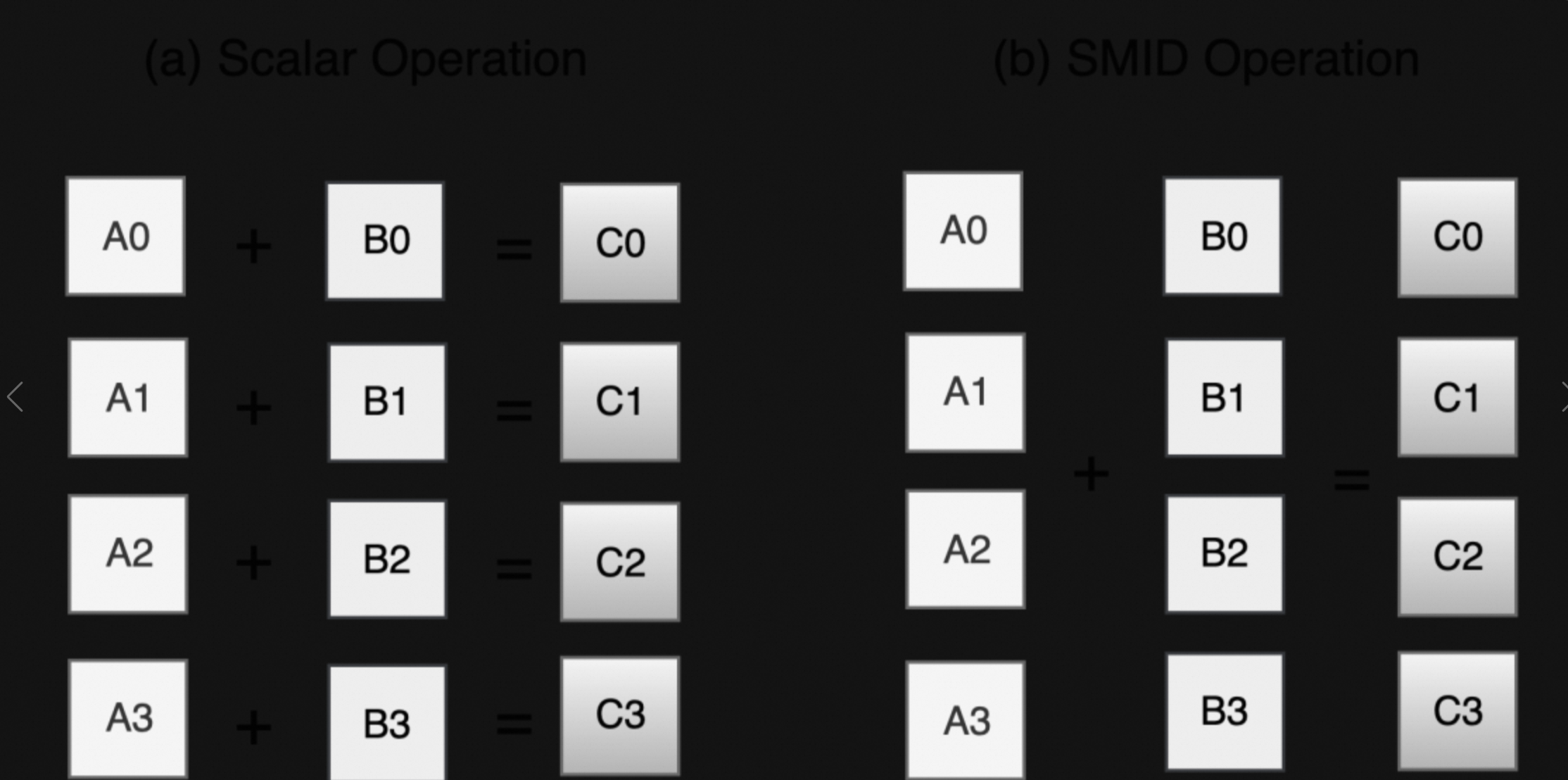
1.2、情景:
你在快餐店打包 8 个汉堡
对应❌ 传统方式(Java 8 的普通循环):
你对服务员说:
打包第1个汉堡
打包第2个汉堡
打包第3个汉堡
……打包第8个汉堡
慢!效率低,服务员要听8次指令。
✅ 向量化方式(现代 Java 的 SIMD):
你对服务员说:
“把这8个汉堡一起打包!”
一条指令,完成8个操作,快得多!
如下所示:
3、代码应用
代码如下所示:
// 示例:使用 Vector API 加速数组加法
DoubleVector a = DoubleVector.fromArray(DoubleVector.SPECIES_256, arr1, i);
DoubleVector b = DoubleVector.fromArray(DoubleVector.SPECIES_256, arr2, i);
DoubleVector c = a.add(b);
c.intoArray(result, i);以下是两个数组进行加法计算的代码示例:
// 文件名:VectorAddDemo.java
import jdk.incubator.vector.FloatVector;
import jdk.incubator.vector.VectorSpecies;
import java.util.Arrays;
public class VectorAddDemo {
// 定义向量规格:使用 256 位宽度(可同时处理 8 个 float)
private static final VectorSpecies SPECIES = FloatVector.SPECIES_256;
// 数组大小(建议是 8 的倍数,便于向量化)
private static final int SIZE = 100_0000; // 100万
public static void main(String[] args) {
// 创建两个大数组
float[] a = new float[SIZE];
float[] b = new float[SIZE];
float[] result = new float[SIZE];
// 初始化数据
Arrays.fill(a, 1.5f);
Arrays.fill(b, 2.5f);
System.out.println("数组大小: " + SIZE);
// 传统方式:普通 for 循环
long start = System.nanoTime();
traditionalAdd(a, b, result);
long time1 = System.nanoTime() - start;
System.out.printf("传统 for 循环耗时: %.2f ms\n", time1 / 1_000_000.0);
// 向量化方式:Vector API
long start2 = System.nanoTime();
vectorizedAdd(a, b, result);
long time2 = System.nanoTime() - start2;
System.out.printf("向量化加法耗时: %.2f ms\n", time2 / 1_000_000.0);
// 性能提升倍数
double speedup = (double) time1 / time2;
System.out.printf("性能提升: %.2fx\n", speedup);
// 验证结果正确性
System.out.println("结果正确: " + (result[0] == 4.0f)); // 1.5 + 2.5 = 4.0
}
// 方法1:传统 for 循环
public static void traditionalAdd(float[] a, float[] b, float[] result) {
for (int i = 0; i < a.length; i++) {
result[i] = a[i] + b[i];
}
}
// 方法2:向量化加法
public static void vectorizedAdd(float[] a, float[] b, float[] result) {
int i = 0;
int length = a.length;
// 向量化部分:每次处理一个向量(如8个元素)
for (; i < length - SPECIES.length() + 1; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
FloatVector vc = va.add(vb); // SIMD 加法(一条指令加8个数)
vc.intoArray(result, i); // 写回数组
}
// 处理剩余元素(如果数组长度不是向量长度的整数倍)
for (; i < length; i++) {
result[i] = a[i] + b[i];
}
}
}编译和运行时候:
# 1. 编译(启用孵化模块)
javac --add-modules jdk.incubator.vector VectorAddDemo.java
# 2. 运行
java --add-modules jdk.incubator.vector VectorAddDemo预期输出:
数组大小: 1000000
传统 for 循环耗时: 3.21 ms
向量化加法耗时: 0.48 ms
性能提升: 6.69x
结果正确: true✅ 优势:比传统 for 循环快 2~10 倍
✅ 应用:科学计算、图像处理、机器学习推理
这是目前 Java 数组最前沿的优化方向之一。
2、多维数组与张量(Tensor)
AI 的基础:在深度学习中,张量(Tensor)本质上就是多维数组。

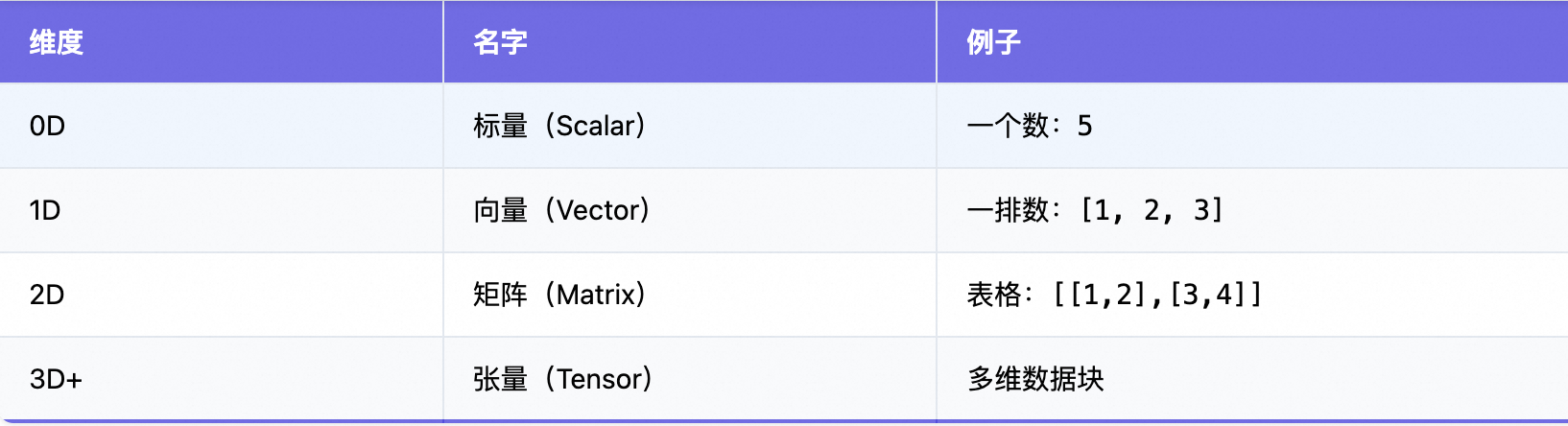
一、先从“数组”说起:从 1D 到 3D,像切披萨
1. 一维数组(1D)——一排数字
int[] arr = {1, 2, 3, 4};像一排小盒子,每个盒子里放一个数。
类比:一条直线上的点。
2. 二维数组(2D)——表格 / 矩阵
int[][] matrix = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};像一个表格,有行有列。
类比:Excel 表格、棋盘。
3. 三维数组(3D)——立体魔方
int[][][] cube = new int[3][3][3]; // 3×3×3 的立方体像一个魔方,有“层、行、列”。
类比:一栋楼:
- 第1层:一楼平面图
- 第2层:二楼平面图
- 第3层:三楼平面图
4. 四维及以上?——抽象空间
int[][][][] data = new int[10][3][224][224];看不懂?别急,这就是 张量的起点!
Tensor张量 = 多维数组 + 数学意义 + 可计算。
但它不是简单的“数组”,而是带有数学变换规则的多维数据结构。
所以可以理解为:张量是“多维数组”的科学化、工程化叫法,尤其是在 AI 领域。
形状(shape)是:[4, 4, 3]
高度 4
↓
┌──────────────────────┐
│ [100, 100, 100] [80, 80, 80] [110,110,110] [90, 90, 90] │
│ [95, 95, 95] [105,105,105] [98, 98, 98] [102,102,102]│
│ [100,100,100] [97, 97, 97] [103,103,103] [99, 99, 99] │
│ [101,101,101] [96, 96, 96] [100,100,100] [100,100,100]│
└───────────────────────────────────────────────────────────┘
↑ ↑ ↑ ↑
列 0 列 1 列 2 列 3
宽度 4
↓
每个像素有 3 个数:R, G, B → 通道数 3 这就是一个 3D 张量:4×4×3 = 48 个数字
✅ 它本质上是一个 三维数组,但 AI 框架叫它 “Tensor” 是因为它可以参与计算和学习。

✅ 示例目标:
创建一个“猫图片”的张量,然后“假装分类”。
// 文件名:SimpleTensorDemo.java
public class SimpleTensorDemo {
public static void main(String[] args) {
// 模拟一张非常小的灰度图(4x4),1通道(灰度图不需要RGB)
// 值越大越白,越小越黑 → 猫的轮廓用数字表示
float[][] catImage = {
{0.0f, 1.0f, 1.0f, 0.0f}, // 0=黑(背景),1=白(猫)
{1.0f, 0.0f, 0.0f, 1.0f},
{1.0f, 0.0f, 0.0f, 1.0f},
{0.0f, 1.1f, 1.0f, 0.0f}
};
// 这就是一个 2D 张量(可以扩展成 3D 加 RGB)
System.out.println("张量数据(模拟猫的轮廓):");
for (float[] row : catImage) {
System.out.println(Arrays.toString(row));
}
// 假设模型“看到”这个张量后,计算出结果
double catScore = computeCatLikelihood(catImage);
System.out.printf("\nAI 判断:这是猫的概率 = %.0f%%\n", catScore * 100);
}
// 模拟“AI模型”的判断逻辑(简化版)
static double computeCatLikelihood(float[][] tensor) {
// 简单规则:如果四个角是黑的,中间是白的 → 像猫头
boolean corner1 = (tensor[0][0] 0.5 && tensor[2][2] > 0.5);
if (corner1 && corner2 && corner3 && corner4 && center) {
return 0.9; // 90% 是猫
} else {
return 0.3; // 30% 是猫
}
}
}输出结果:
张量数据(模拟猫的轮廓):
[0.0, 1.0, 1.0, 0.0]
[1.0, 0.0, 0.0, 1.0]
[1.0, 0.0, 0.0, 1.0]
[0.0, 1.0, 1.0, 0.0]
AI 判断:这是猫的概率 = 90%2、实际应用
一张彩色图片(224×224 像素)在计算机中表示为一个 3D 张量:
shape: [224, 224, 3]
↑ ↑ ↑
| | └── 红、绿、蓝 三个颜色通道(RGB)
| └─────── 宽度(列)
└──────────── 高度(行)它就是一个三维数组:
- 每个像素有 3 个值:R、G、B
- 总共 224×224×3 = 150,528 个数字
在深度学习中,我们说:“把图片转成张量”,其实就是把它变成一个多维数组。
如果你有 10 张这样的图片,要一起输入 AI 模型,就变成:
shape: [10, 224, 224, 3]
↑ ↑ ↑ ↑
| | | └── 颜色通道
| | └──────── 宽度
| └───────────── 高度
└────────────────── 图片数量(批量大小 batch size)
多个图像?那就是 4D 张量!3、张量的实现
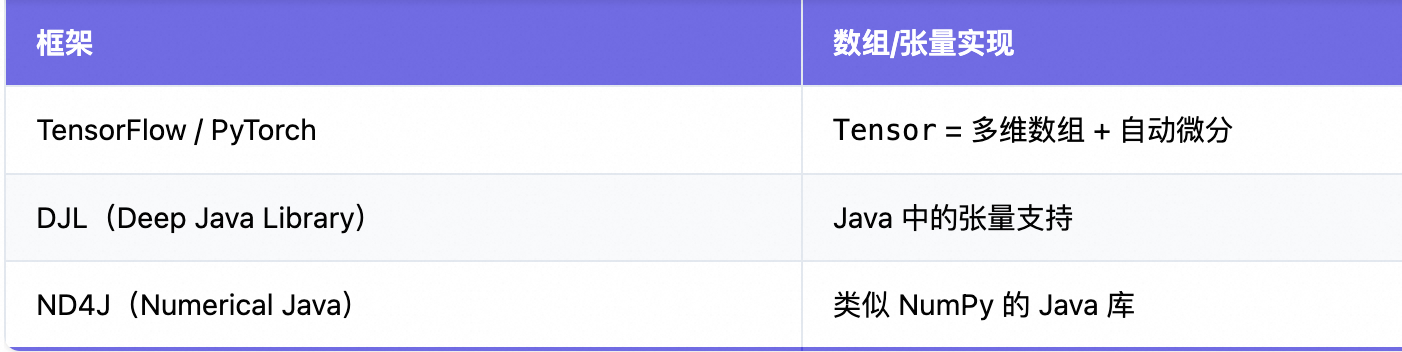
Java 本身没有内置 Tensor 类型,但可以通过以下方式使用:
1. 使用 ND4J(Java 的 NumPy)
ND4J 是 Java 中最接近“张量”的库,语法像 Python 的 NumPy。
pom.xml依赖:
// Maven 依赖:
org.nd4j
nd4j-native
1.0.0-M2import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.api.ndarray.INDArray;
public class TensorDemo {
public static void main(String[] args) {
// 创建一个 2x3 的二维张量(矩阵)
INDArray tensor = Nd4j.create(new float[][]{
{1.0f, 2.0f, 3.0f},
{4.0f, 5.0f, 6.0f}
});
System.out.println(tensor);
// 输出:
// [[1.00, 2.00, 3.00],
// [4.00, 5.00, 6.00]]
// 矩阵乘法
INDArray result = tensor.mmul(tensor.transpose());
System.out.println(result);
}
}✅ ND4J 支持:
多维数组(张量)
数学运算(加、乘、卷积)
自动广播(broadcasting)
GPU 加速(可选)
2. 使用 DJL(Deep Java Library)
由 Amazon 开发,让 Java 能直接运行深度学习模型。
代码如下所示:
// 加载一个图像,自动转成张量
Bitmap image = ...;
NDArray input = image.toTensor(); // 自动变成 [1, 3, 224, 224] 的 4D 张量
Model model = Model.load("resnet50");
NDArray output = model.forward(input); // 推理✅ 适合:Java 后端做 AI 推理(如图像识别、NLP)
关于张量的实现如下所示:
总结:

- 多维数组 就像“储物箱”,用来装数据。
- 张量就像“会学习的储物箱”,不仅能装数据,还能参与 AI 训练和推理。
- 在 AI 时代,张量就是多维数组的“升级版”,是图像、语音、文字的统一表示方式。
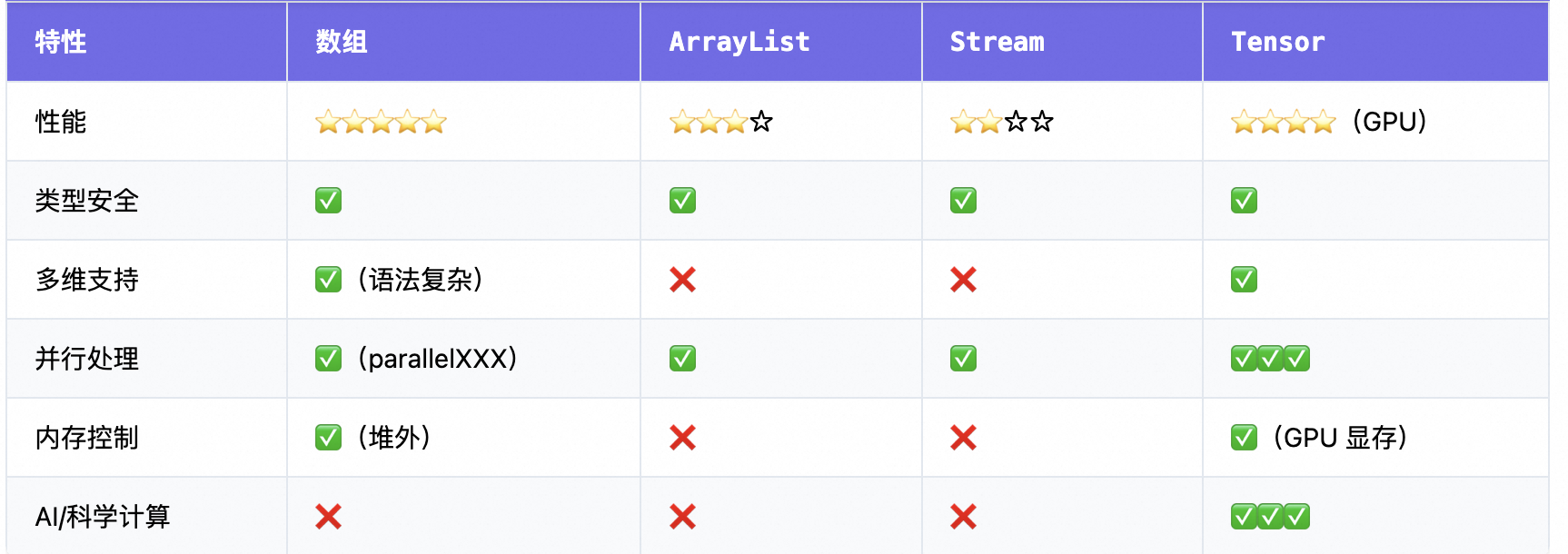
3、并行数组操作
Java 8+ 提供了并行数组操作 API:Fork/Join 与
Arrays.parallelSetAll()。
代码如下所示:
int[] arr = new int[1000000];
// 并行初始化
Arrays.parallelSetAll(arr, i -> i * 2);
// 并行排序(比传统快很多)
Arrays.parallelSort(arr);
// 并行归约
int sum = Arrays.stream(arr).parallel().sum();✅ 利用多核 CPU,适合大数据量处理
✅ 前沿趋势:从串行到并行数组处理
4、内存优化:堆外数组
传统数组存储在 JVM 堆内,可能引发 GC 压力。前沿做法是使用 堆外内存(Off-Heap):
// 使用 Unsafe 或 ByteBuffer 分配堆外数组
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024); // 1MB 堆外或使用 MemorySegment(Java 17+,Project Panama):
try (MemorySegment segment = MemorySegment.allocateNative(1024)) {
segment.set(ValueLayout.JAVA_INT, 0, 42);
}✅ 优势:减少 GC、提升性能、接近 C 语言效率
✅ 应用:高频交易、实时系统、大数据流处理
5、不可变数组与函数式风格
现代编程更倾向于使用 不可变集合 和 流式处理:
// 使用 Stream 处理数组(函数式)
List result = Arrays.stream(arr)
.filter(x -> x > 10)
.map(x -> x * 2)
.boxed()
.toList(); // Java 16+或使用 Record + 数组构建不可变数据结构:
public record Matrix(int rows, int cols, double[] data) {
// 不可变矩阵
}前沿趋势:从可变数组 → 不可变数据 + 函数式处理。
6、JVM 层优化
对数组访问性能的提升,JVM 对数组做了大量优化:
- 边界检查消除(Bounds Check Elimination)
- 循环展开(Loop Unrolling)
- 数组访问内联
- GraalVM 编译优化
例如,以下代码会被 JIT 编译器优化为近乎 C 语言的速度:
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
}
未来趋势:
- 通用编程:
Stream+List为主 - 高性能计算:数组 + 向量化 + 堆外内存
- AI/大数据:张量(Tensor) 成为“超级数组”
参考文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号