


从零入门 R 语言:基础语法、数据结构与常用函数全解析 - 指南
作为数据分析与统计领域的 “明星工具”,R 语言凭借开源免费、生态丰富的优势,成为数据科学家、研究者的首选。但对新手来说,入门往往卡在 “语法混乱”“数据结构不清” 上。今天这篇文章,就带大家从最核心的基础语法、数据结构入手,再结合高频实用函数,通过代码示例一步步吃透 R 语言入门要点。
一、R 语言基础语法:从 “写对代码” 开始
语法是编程的 “普通话”,R 语言的语法简洁直观,但有几个核心规则必须掌握。
1. 变量赋值:数据的 “容器”
变量是存储数据的载体,R 语言中推荐用<-赋值(=也可用,但在R语言编写中属于不规范),变量名需以字母开头,可包含数字、下划线(_)或点(.)。
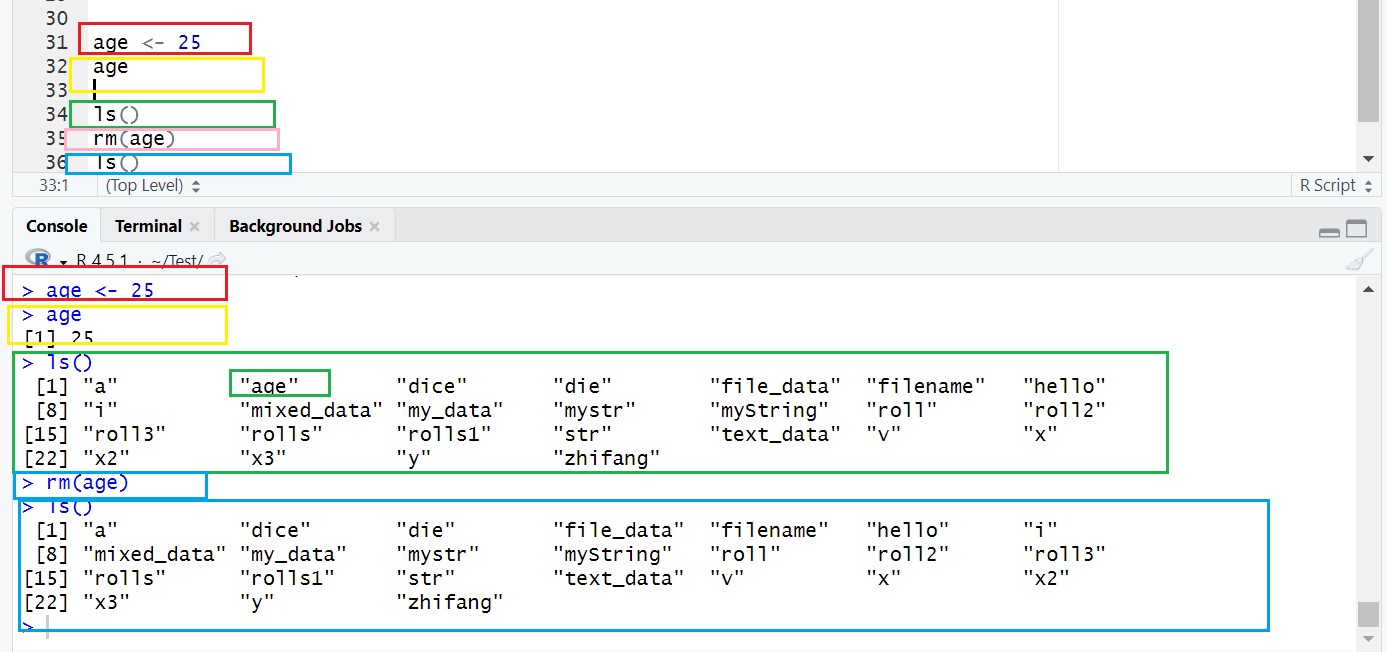
示例 1:变量赋值与查看
# 赋值:将数值、字符、逻辑值存入变量
age <- 25 # 数值型变量
name <- "小明" # 字符型变量(必须用引号包裹)
is_student <- TRUE # 逻辑型变量(TRUE/FALSE,注意大写)
# 查看变量:直接输入变量名,或用print()函数
age # 输出:[1] 25
print(name) # 输出:[1] "小明"注:
避免用TRUE/FALSE、mean/sum等 “关键字” 作为变量名(会覆盖内置函数);
用ls()可查看当前所有变量,rm(变量名)可删除指定变量(如rm(age)删除 age)。
2. 数据类型:R 语言的 “基本单位”
所有数据都有明确类型,R 语言最核心的原子类型有 4 种,决定了数据的处理方式:
| 类型 | 描述 | 示例 | 检测函数 |
|---|---|---|---|
| 数值型(numeric) | 整数 / 小数(默认类型) | 10、3.14 | is.numeric() |
| 字符型(character) | 文本数据 | "R语言"、"123"(带引号) | is.character() |
| 逻辑型(logical) | 布尔值 | TRUE、FALSE | is.logical() |
| 因子型(factor) | 分类数据(如性别、职业) | factor(c("男","女")) | is.factor() |
示例 2:数据类型检测与转换
# 检测类型
x <- 3.14
is.numeric(x) # 输出:[1] TRUE
is.character(x) # 输出:[1] FALSE
# 查看类型
class(x) #输出:[1] "numeric"
# 类型转换(用as.XXX()函数)
x_char <- as.character(x) # 数值转字符
x_char # 输出:[1] "3.14"
is.character(x_char) # 输出:[1] TRUE
# 因子型示例(适合分类数据,自动记录类别)
gender <- factor(c("男", "女", "男", "男"))
gender # 输出:[1] 男 女 男 男;Levels: 女 男(自动排序类别)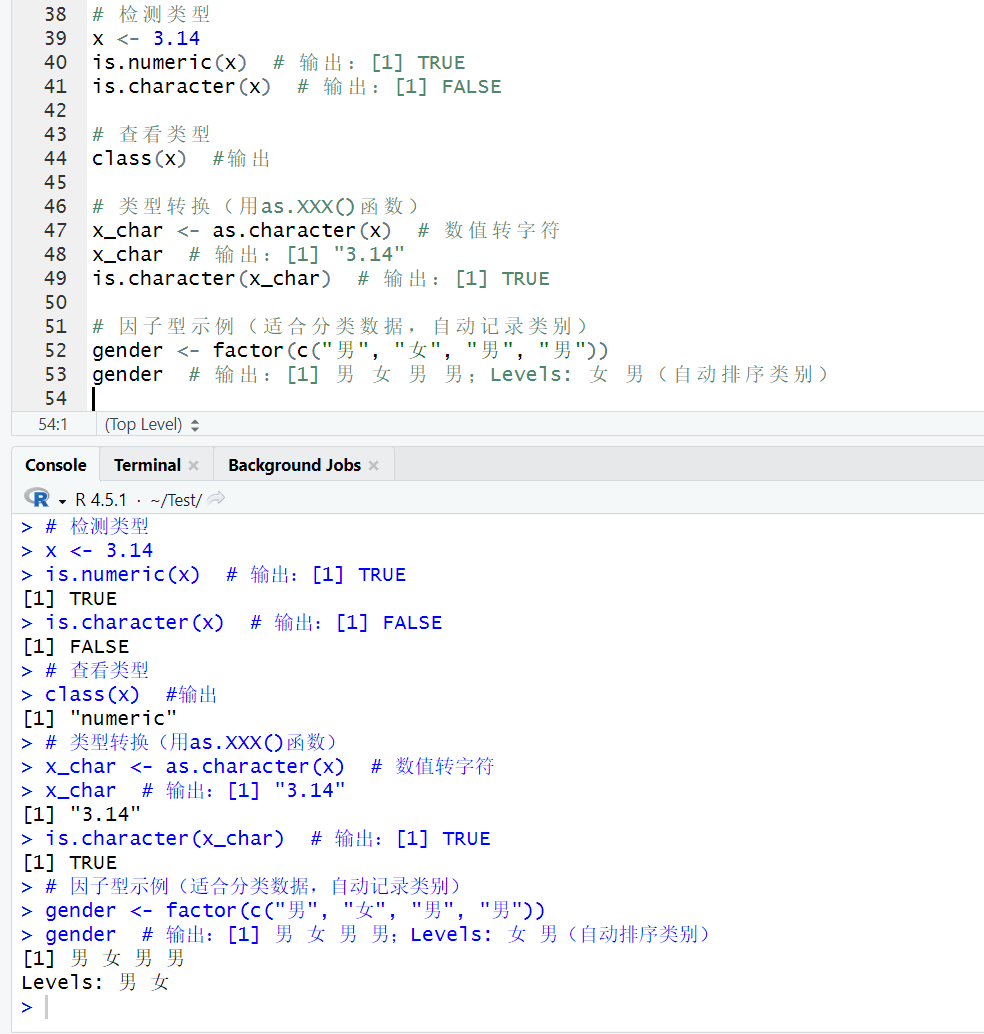
3. 运算符:数据的 “计算工具” 常用运算符分三类,覆盖数学计算、条件判断和逻辑组合:
(1)算术运算符:数值计算
| 运算符 | 作用 | 示例 | 结果 |
|---|---|---|---|
+- | 加 / 减 | 5+3 | 8 |
*/ | 乘 / 除 | 10/2 | 5 |
^ | 幂运算 | 2^3 | 8 |
%% | 取余 | 7%%3 | 1 |
%/% | 整除 | 7%/%3 | 2 |
(2)比较运算符:条件判断(返回逻辑值)
| 运算符 | 作用 | 示例 | 结果 |
|---|---|---|---|
== | 等于 | 5==3 | FALSE |
!= | 不等于 | 5!=3 | TRUE |
>< | 大于 / 小于 | 5>3 | TRUE |
>=<= | 大于等于 / 小于等于 | 5>=5 | TRUE |
(3)逻辑运算符:组合条件(仅对逻辑值生效)
| 运算符 | 作用 | 示例 | 结果 |
|---|---|---|---|
& | 且(全部为真则真) | TRUE & FALSE | FALSE |
| | | | | 或(一个为真则真) | TRUE |
! | 非(取反) | !TRUE | FALSE |
示例 3:运算符综合使用
# 算术运算
a 2*b # 10>6 → TRUE
# 逻辑运算:判断a是偶数且b<5
(a %% 2 == 0) & (b < 5) # TRUE & TRUE → TRUE
(a %% 2 == 0) | (b < 5) # TRUE | TRUE → TRUE
(a %% 2 != 0) | (b < 5) # FALSE | TRUE → TRUE
(a %% 2 != 0) & (b < 5) # FALSE & TRUE → FALSE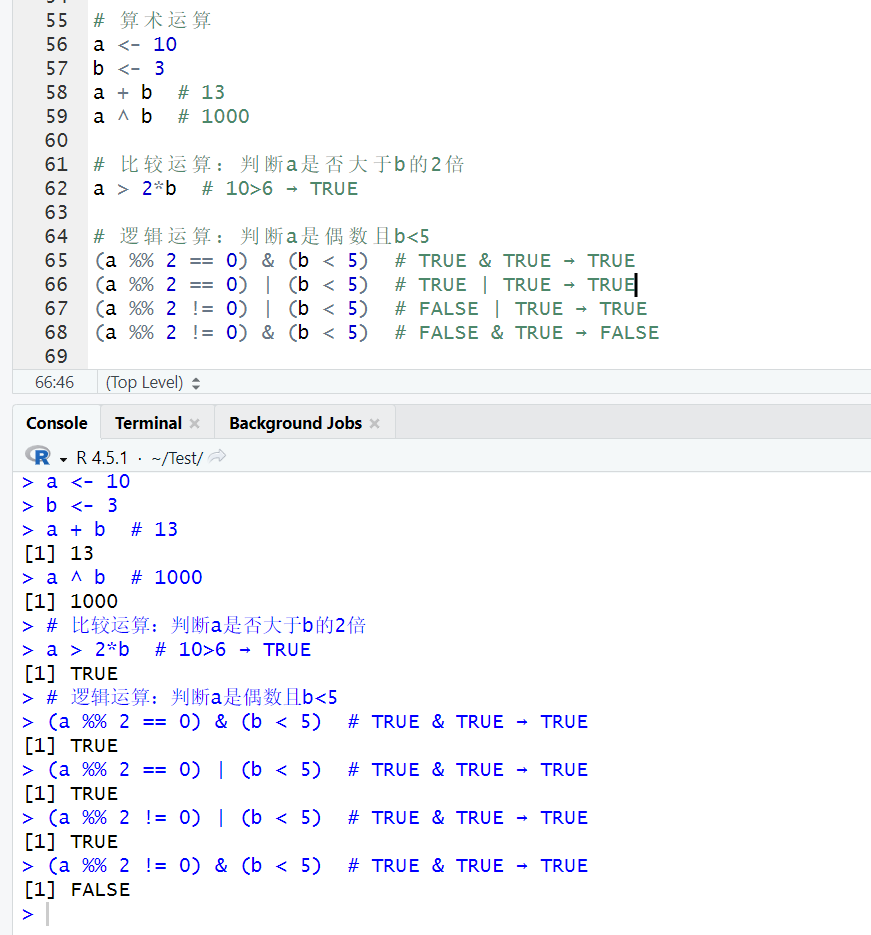
4. 流程控制:让代码 “有逻辑地跑” 当需要根据条件执行不同代码,或重复执行某段代码时,就需要流程控制语句。 (1)if-else:条件分支
# 示例:根据分数判断等级
score = 90) {
print("优秀")
} else if (score >= 80) {
print("良好")
} else {
print("继续努力")
}
# 输出:[1] "良好"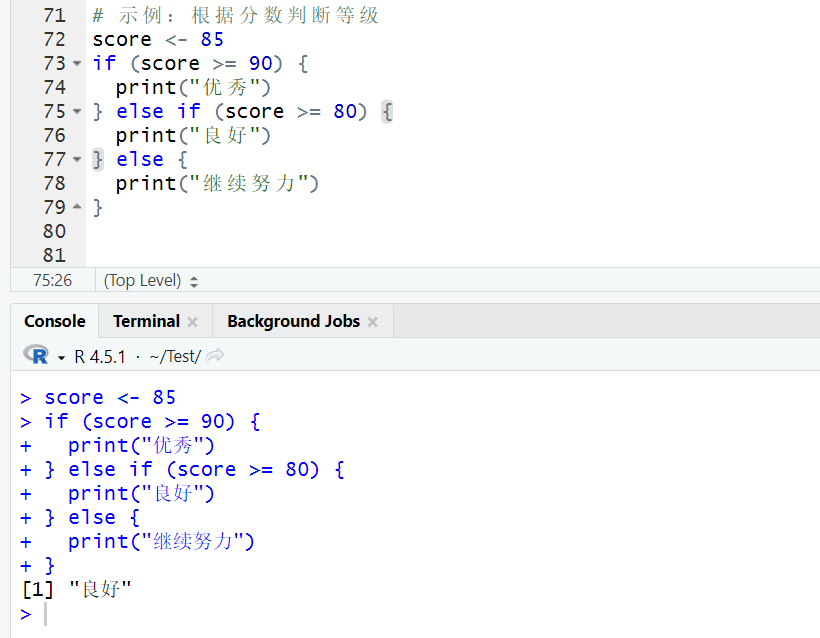
(2)for 循环:重复执行
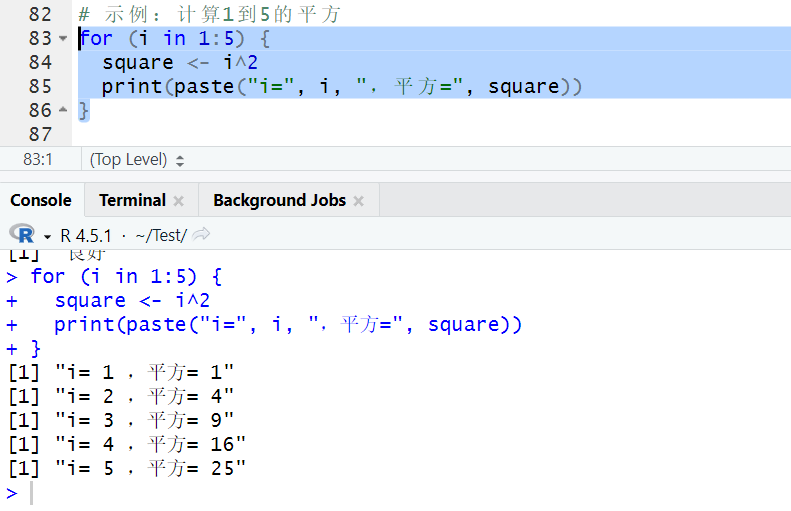
# 示例:计算1到5的平方
for (i in 1:5) { # i依次取1、2、3、4、5
square <- i^2
print(paste("i=", i, ",平方=", square))
}
二、R 语言核心数据结构:数据的 “组织形式”
如果说变量是 “小容器”,数据结构就是 “大仓库”。R 语言有 5 种核心数据结构,覆盖从一维到多维、从单一类型到混合类型的需求:
| 结构 | 维度 | 数据类型 | 核心特点 | 创建函数 |
|---|---|---|---|---|
| 向量(Vector) | 1 维 | 单一类型 | 最基础结构,所有元素类型一致 | c() |
| 矩阵(Matrix) | 2 维 | 单一类型 | 行 + 列的表格,元素类型一致 | matrix() |
| 数组(Array) | N 维 | 单一类型 | 矩阵的扩展(如 3 维:行 + 列 + 层) | array() |
| 列表(List) | 1 维 | 混合类型 | 可存放向量、矩阵、甚至列表 | list() |
| 数据框(DataFrame) | 2 维 | 混合类型 | 表格形式,列可不同类型(最常用!) | data.frame() |
1. 向量(Vector):最基础的 “一维数组”
向量是 R 语言的 “原子结构”,所有元素必须是同一类型,用c()(combine)函数创建。
示例 4:向量创建与操作
# 1. 创建向量
num_vec <- c(1, 3, 5, 7) # 数值向量
char_vec <- c("苹果", "香蕉", "橙子") # 字符向量
log_vec <- c(TRUE, FALSE, TRUE) # 逻辑向量
# 2. 访问向量元素(用“索引”,R语言索引从1开始!)
num_vec[2]
char_vec[1:2]
num_vec[-1]
log_vec[1]
# 3. 向量运算(自动对每个元素生效)
num_vec * 2 # 每个元素乘2 → 2 6 10 14
num_vec + c(2,4,6,8) #相加减要满足长对象是短对象的整数倍
num_vec + c(2,4,6)
num_vec + c(2,4)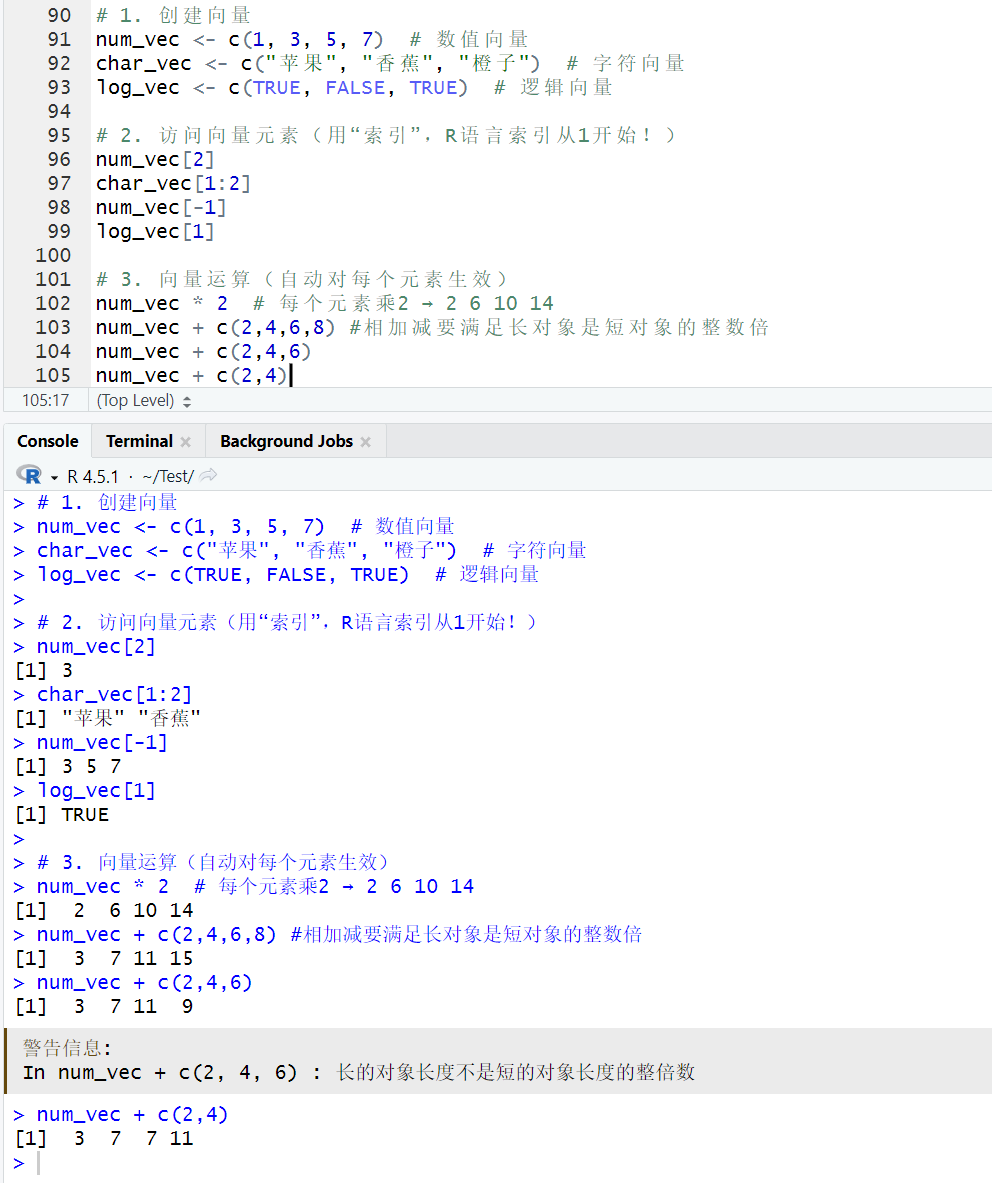
注意:对于相加减要满足长对象是短对象的整数倍,在后续《R语言入门与实践》中同样会介绍,内容如下图所示,可提前比对学习。

2. 数据框(DataFrame):数据分析的 “主力”
数据框是表格形式的 2 维结构,列可不同类型(如一列数值、一列字符),完全对应 Excel 表格,是 R 中最常用的数据结构(内置数据集iris、mtcars都是数据框)。
示例 5:数据框创建与操作
# 1. 创建数据框(用data.frame(),每列是一个向量)
student_df <- data.frame(
name = c("小明", "小红", "小刚"), # 字符列
age = c(20, 21, 19), # 数值列
major = c("数学", "计算机", "英语") # 字符列
)
student_df # 查看数据框
# 2. 访问数据框(三种常用方式)
# (1)按列名访问($符号,最常用)
student_df$name
# (2)按索引访问:[行, 列]
student_df[1, ]
student_df[, 2]
# (3)按列名筛选
student_df[, c("name", "major")]
# 3. 数据框常用操作
nrow(student_df)
ncol(student_df)
head(student_df, 2) # 查看前2行(后面讲head()函数)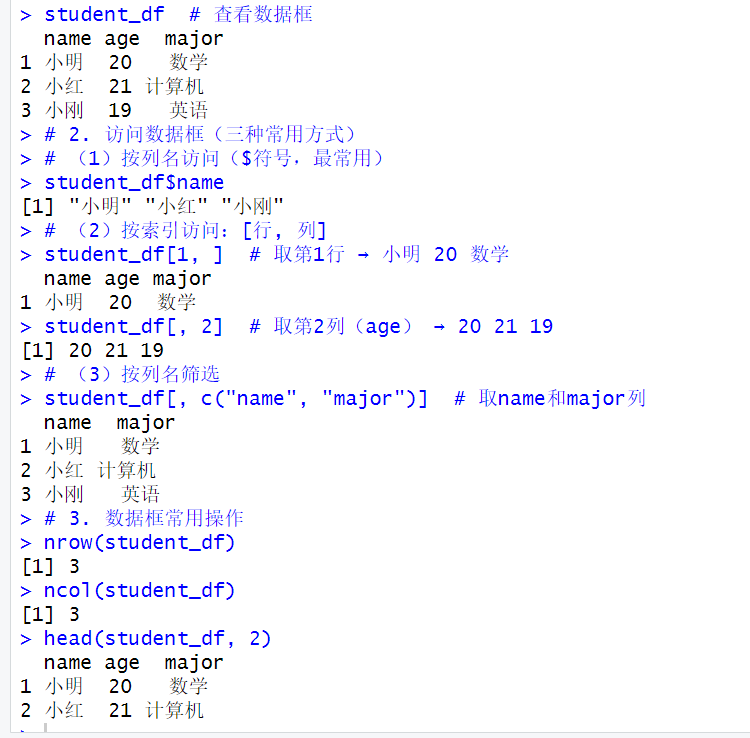
3. 列表(List):最灵活的 “混合容器”
列表可存放不同类型、不同结构的数据(如向量 + 数据框 + 矩阵),用list()创建,适合存储复杂数据。
示例 6:列表创建与访问
# 1. 创建列表(元素可任意类型)
my_list <- list(
vec = c(1,2,3),
df = student_df,
mat = matrix(1:4, nrow=2)
)
my_list # 查看列表
# 2. 访问列表元素
# (1)按名称访问($符号)
my_list$df
# (2)按索引访问([[ ]],注意双括号!)
my_list[[1]]
my_list[[2]]
4. 矩阵(Matrix):单一类型的 “二维表格”
矩阵是2 维结构,但所有元素必须是同一类型,用matrix()创建,适合数学运算(如矩阵乘法)。
示例 7:矩阵创建与操作
# 1. 创建矩阵(data=数据,nrow=行数,byrow=是否按行填充)
mat <- matrix(
data = 1:6, # 数据1-6
nrow = 2, # 2行
byrow = TRUE # 按行填充(默认FALSE:按列填充,可见上述的my_list)
)
mat # 查看矩阵
transpose <- t(mat) #(t()是转置函数)
transpose
# 2. 矩阵运算(矩阵乘法用%*%)
mat %*% transpose # 矩阵乘其转置
三、R 语言常用函数:效率提升的 “快捷键”
函数是 “封装好的代码块”,调用即可实现特定功能。以下是初学者必掌握的 3 类高频函数:
1. 数据查看函数:快速了解数据
| 函数 | 作用 | 示例 |
|---|---|---|
head(x, n) | 查看前 n 行(默认 n=6) | head(iris, 3) 查看 iris 前 3 行 |
tail(x, n) | 查看后 n 行(默认 n=6) | tail(student_df, 2) |
str(x) | 查看数据结构(类型、维度等) | str(iris) 分析 iris 结构 |
summary(x) | 查看统计摘要(均值、中位数等) | summary(student_df$age) |
dim(x) | 查看维度(行数 + 列数) | dim(iris) 输出 iris 的行和列 |
示例 8:数据查看实战(用内置数据集 iris)
# 查看iris数据集前5行
head(iris, 5)
# 查看iris结构(150行、5列,最后一列是因子型)
str(iris)
# 查看iris中Sepal.Length列的统计摘要
summary(iris$Sepal.Length)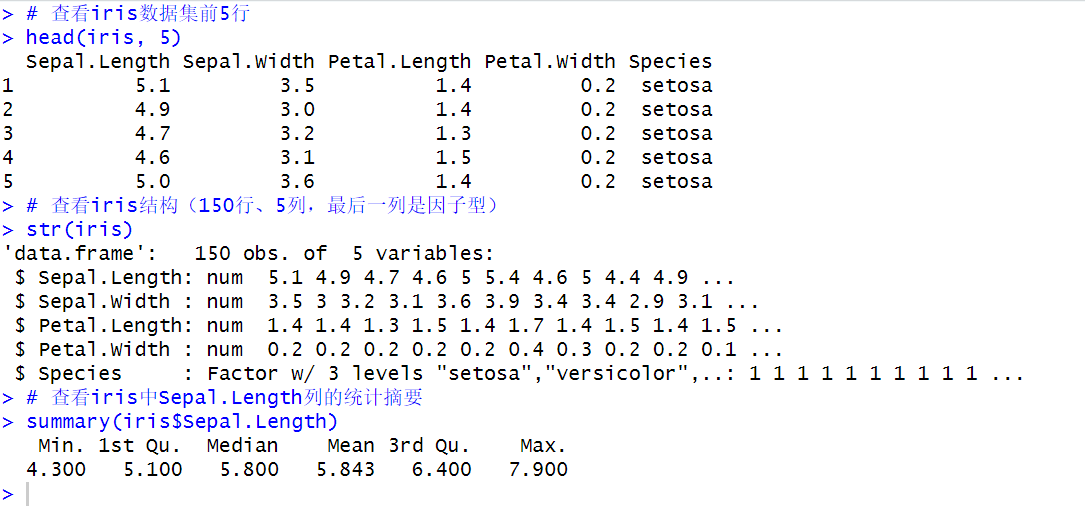
summary()函数执行后的参数类型含义如下
| 统计指标 | 数值 | 含义解释 |
|---|---|---|
| Min.(最小值) | 4.300 | 所有鸢尾花样本的萼片长度中,最短的为 4.3 个单位(数据集默认单位为厘米)。 |
| 1st Qu.(第一四分位数) | 5.100 | 将所有萼片长度按从小到大排序后,处于 25% 位置的数值(即 25% 的样本萼片长度≤5.1)。 |
| Median(中位数) | 5.800 | 排序后处于 50% 位置的数值(即一半样本萼片长度≤5.8,另一半≥5.8),反映数据 “中间水平”。 |
| Mean(均值) | 5.843 | 所有样本萼片长度的平均值,计算方式为 “总长度之和 / 样本总数”,反映数据 “平均水平”。 |
| 3rd Qu.(第三四分位数) | 6.400 | 排序后处于 75% 位置的数值(即 75% 的样本萼片长度≤6.4,25% 的样本≥6.4)。 |
2. 数据处理函数:清洗与筛选
| 函数 | 作用 | 示例 |
|---|---|---|
subset(x, condition) | 按条件筛选行 | subset(iris, Species=="setosa") 筛选 setosa 品种 |
na.omit(x) | 删除含缺失值(NA)的行 | na.omit(student_df) |
sort(x) | 排序(默认升序) | sort(c(3,1,5)) → 1 3 5 |
unique(x) | 去重 | unique(c(1,1,2,3)) → 1 2 3 |
merge(x,y, by) | 合并两个数据框(类似 SQL 连接) | merge(df1, df2, by="name") 按 name 合并 |
示例 9:数据筛选与合并
# 1. 筛选iris中Sepal.Length>6的setosa品种
iris_sub 6)
iris_sub # 仅返回满足条件的行
# 2. 合并两个数据框
df1 <- data.frame(
name=c("小明","小红"),
score=c(90,85)
)
df2 <- data.frame(
name=c("小明","小刚"),
age=c(20,19)
)
merge(df1, df2, by="name") # 按name合并(仅保留共同name的行)
3. 统计与可视化函数:数据分析核心
(1)统计函数(描述性统计)
| 函数 | 作用 | 示例 |
|---|---|---|
mean(x) | 计算均值 | mean(iris$Petal.Length) |
sd(x) | 计算标准差 | sd(iris$Sepal.Width) |
max(x)/min(x) | 最大值 / 最小值 | max(student_df$age) |
cor(x,y) | 计算相关系数 | cor(iris$Sepal.Length, iris$Petal.Length) |
(2)基础可视化函数(plot())
plot()是 R 的基础绘图函数,支持散点图、线图等,语法简单:
# 示例:绘制iris的Sepal.Length与Petal.Length散点图
plot(
x = iris$Sepal.Length, # x轴
y = iris$Petal.Length, # y轴
main = "萼片长度vs花瓣长度", # 标题
xlab = "萼片长度(cm)", # x轴标签
ylab = "花瓣长度(cm)", # y轴标签
col = iris$Species, # 按品种着色
pch = 16 # 点的形状(16是实心圆)
)
legend("topleft", legend=unique(iris$Species), col=1:3, pch=16) # 添加图例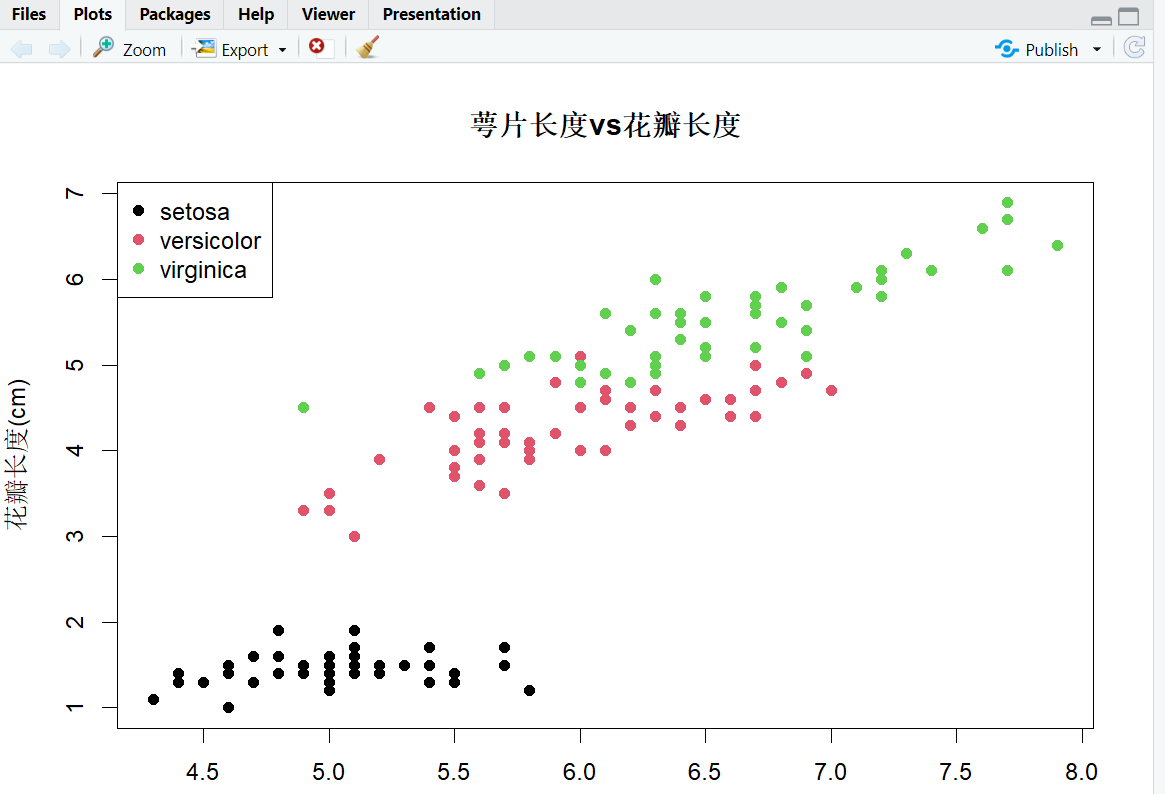
(3)ggplot2基础绘图(更美观的可视化)
ggplot2是 R 的 “绘图神器”,基于图层语法,之后的文章也会提及,这里先补一个基础示例:
# 加载ggplot2包(需先安装:install.packages("ggplot2"))
library(ggplot2)
# 绘制散点图
ggplot(data = iris, aes(x=Sepal.Length, y=Petal.Length, color=Species)) +
geom_point(size=2) + # 散点图层
labs(
title = "萼片长度vs花瓣长度",
x = "萼片长度(cm)",
y = "花瓣长度(cm)"
) +
theme_minimal() # 简洁主题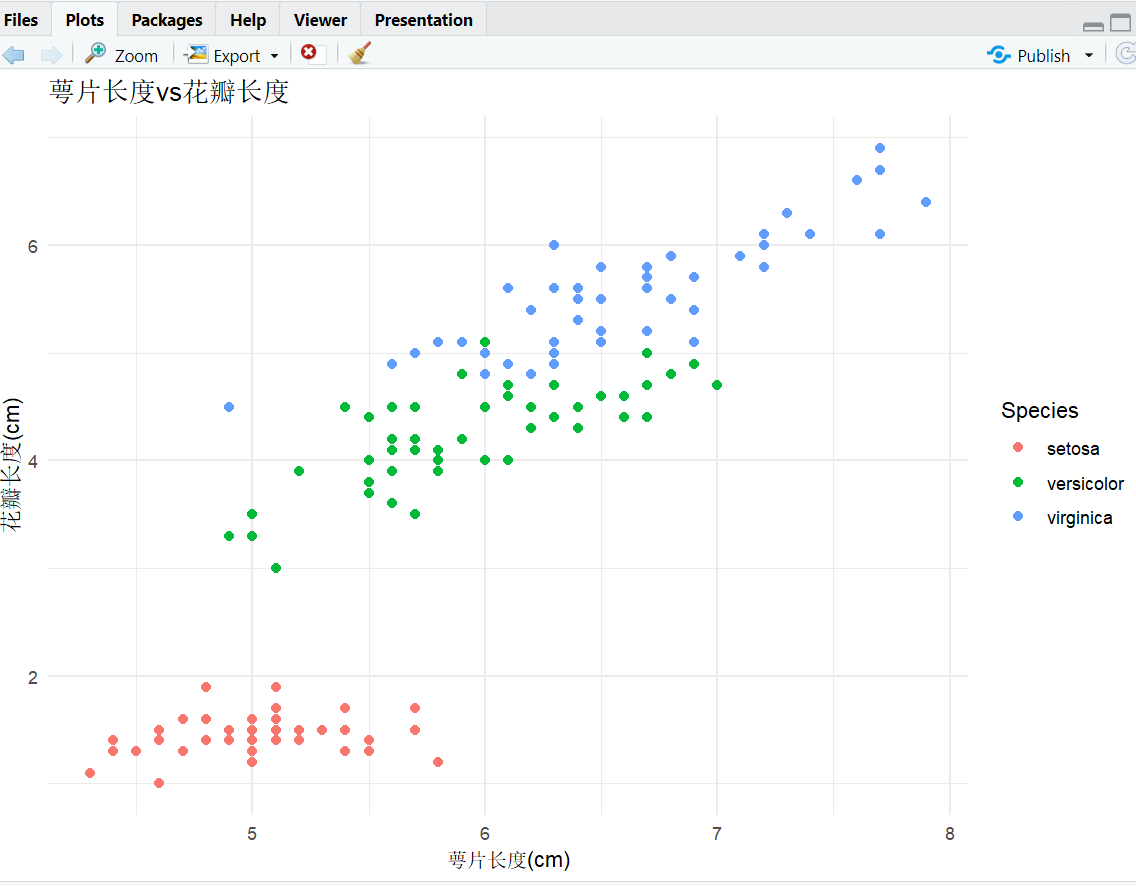
四、实战案例:用基础语法完成一次简单分析
最后,我们用一个完整案例串联前面的知识,分析 “学生成绩数据”:
# 1. 准备数据(创建数据框)
score_df 85的学生
high_math 85)
print("数学成绩>85的学生:")
print(high_math$name)
# 4. 可视化:各科成绩对比(箱线图)
# 先将数据框转换为长格式(适合箱线图)
library(reshape2) # 需安装:install.packages("reshape2")
score_long <- melt(score_clean, id="name", variable.name="subject", value.name="score")
# 绘图
ggplot(score_long, aes(x=subject, y=score, fill=subject)) +
geom_boxplot() +
labs(title="数学vs英语成绩分布", x="科目", y="成绩") +
theme_bw()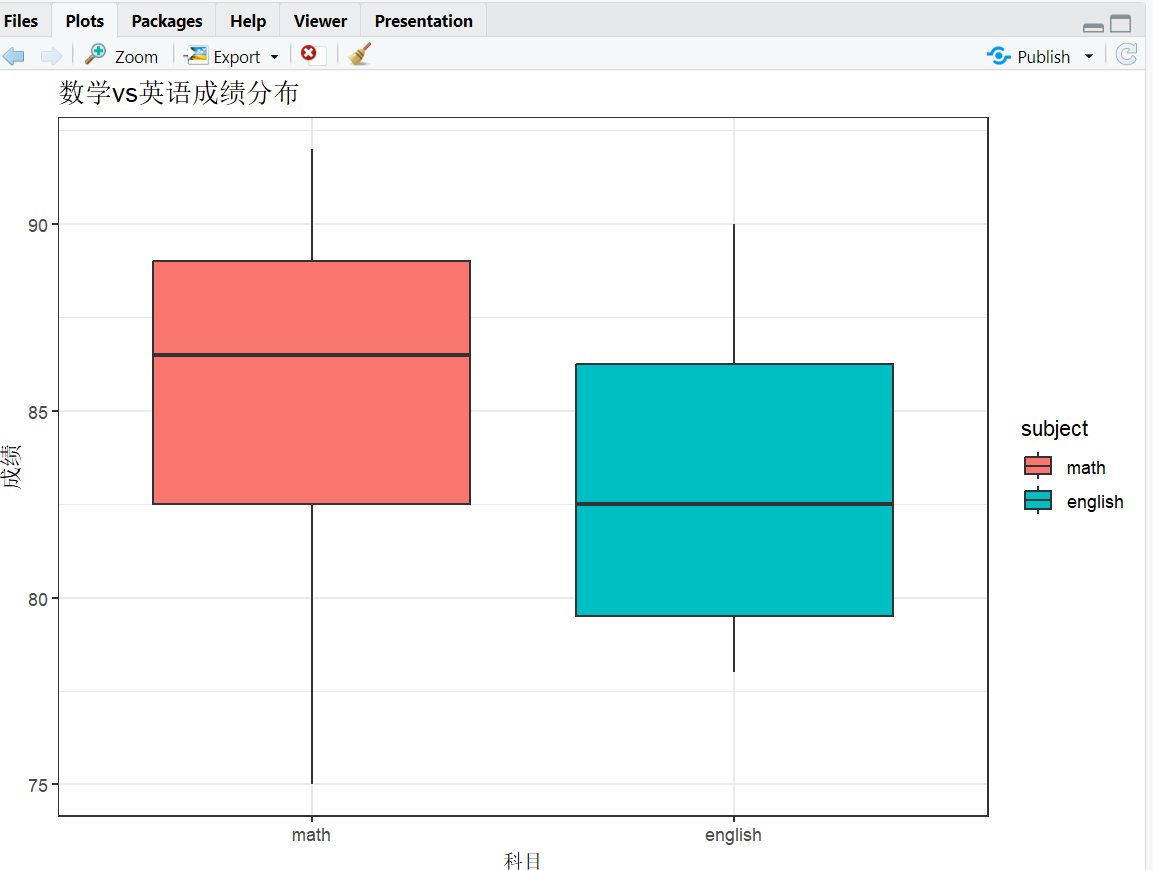
总结与进阶建议
今天我们梳理了 R 语言的基础语法(变量、类型、运算符、流程控制)、核心数据结构(向量、数据框、列表等)和常用函数(查看、处理、统计、可视化),这些是所有 R 语言分析的 “地基”。后续会根据《R语言入门与实践》这本书来详细逐步的进一步学习,欢迎大家点赞关注共同学习
对初学者的进阶建议:
- 多练内置数据集(
iris、mtcars),熟悉数据结构操作; - 学习
dplyr包(数据处理更高效,如filter()、mutate()); - 用
R Markdown写分析报告,整合代码、结果和文本。
如果在练习中遇到具体问题(如函数报错、数据结构混乱),欢迎在评论区交流!
可点击下方链接进入正式系统学习,打好基础后,你会发现数据分析原来这么简单~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号