
RoboTron-Nav:美团融合感知、规划与预测的具身导航统一框架 - 教程
- 作者:Yufeng Zhong, Chengjian Feng, Feng Yan, Fanfan Liu, Liming Zheng, Lin Ma
- 单位:美团
- 论文标题:RoboTron-Nav: A Unified Framework for Embodied Navigation Integrating Perception, Planning, and Prediction
- 论文链接:https://arxiv.org/pdf/2503.18525
- 项目主页:https://yvfengzhong.github.io/RoboTron-Nav/
主要贡献
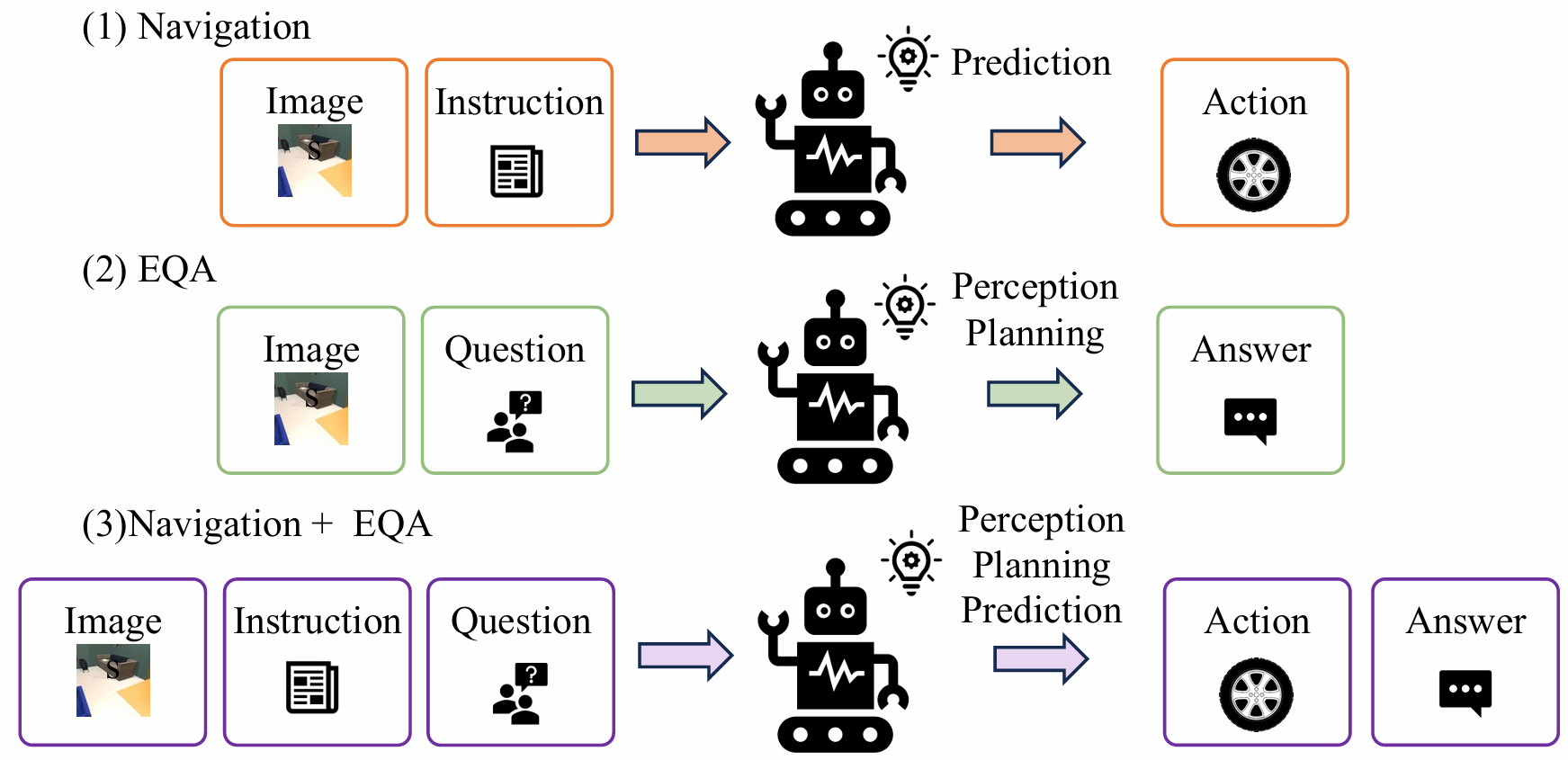
- 提出了用于具身导航的统一框架RoboTron-Nav,经过在导航任务和具身问答(EQA)任务上的多任务协作,整合了感知、规划和预测能力,从而提升了导航性能。
- 引入了自适应的3D感知历史采样策略,通过控制历史采样在空间和语义域中的密度和多样性,有效地减少了观测冗余,提高了导航效率。
- 在CHORES-S基准测试的ObjectNav任务上,RoboTron-Nav达成了81.1%的成功率,创下新的最高水平,比之前的方法绝对提升了9%。
研究背景
- 具身导航的重要性:具身导航是具身人工智能的关键组成部分,尤其是语言引导的视觉导航。与自动驾驶不同,语言引导的视觉导航要求智能体根据自然语言指令在未见过的视觉环境中自主探索以定位目标对象,这带来了独特的挑战,包括在不熟悉的视觉环境中有效感知周围场景、规划实现目标的策略以及预测合适的导航动作。
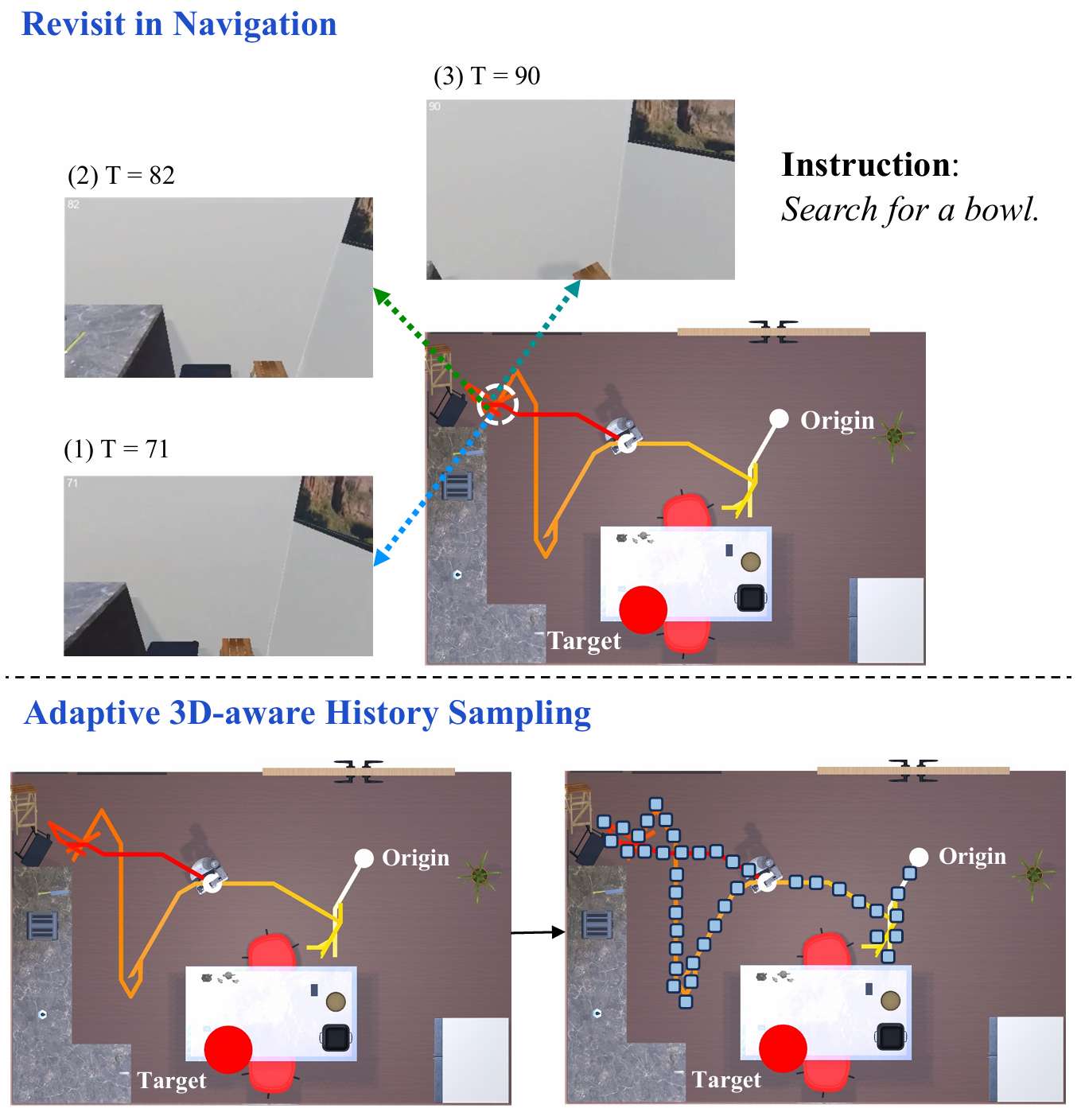
- 现有途径的局限性:尽管当前的导航模型在定位目标对象方面表现出色,但它们通常难以提供高效的路径规划,并且难以解释其路径选择背后的推理过程。此外,在长期导航过程中,智能体可能会多次重访同一区域,导致历史感知信息中存在大量无关和冗余的内容,从而影响导航结果。
研究方法
模型架构
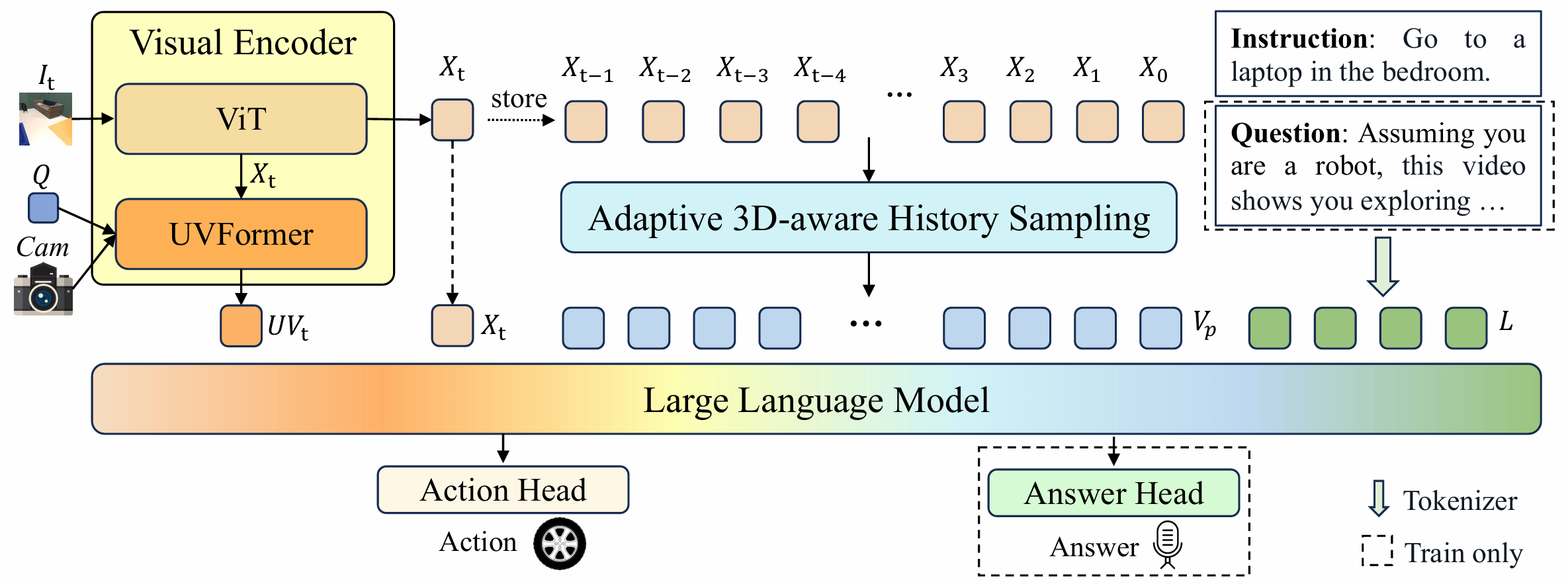
视觉编码器
视觉编码器通过2D和3D特征提取来表示当前观测帧,捕捉实时感知线索。它由两部分组成:
- ViT:用于2D特征提取。它以RGB图像ItI_tIt作为输入,输出2D特征XtX_tXt。
- UVFormer:用于3D空间编码。它处理图像特征XtX_tXt、相机参数Cam和可学习的查询Q,输出3D特征UVtUV_tUVt,聚合多视图视觉信息。
自适应3D感知历史采样
该策略通过控制历史采样在空间和语义域中的密度和多样性,减少观测冗余,同时保留关键位置的视觉信息。它包含三个阶段:
- 初始化:设置操作参数,初始化历史特征VVV和相对位置PPP的缓冲区。
- 3D感知采样:按逆时间顺序处理所有历史观测,通过相对位置阈值ϵ\epsilonϵ和语义相似性阈值τ\tauτ动态过滤冗余的视觉观测。
- 自适应填充:通过复制最终一个有效条目来填充历史特征缓冲区VVV,确保输出长度固定。
此外,该策略还引入了位置增强的历史特征(Position-enhanced Historical Features),利用智能体的位置信息来增强历史语义特征,防止重复探索同一位置。
大语言模型
将位置增强的历史特征VpV_pVp与视觉编码器的当前观测UVtUV_tUVt和XtX_tXt整合,形成视觉标记,输入到LLM中。同时,将输入指令或问题通过分词器转换为语言标记LLL,这些视觉和语言标记组合后输入到LLM中。LLM利用其多模态对齐和理解能力处理这些标记,并通过专门的头部进行解码,生成可执行动作或自然语言答案。
具身问答

为了解决当前导航模型缺乏深度思考和任务规划的问题,论文开发了一种新途径,经过扩展导航素材集来包含EQA对,从而明确建模导航中的决策过程。该方法包括三个阶段:
- 以指令为中心的问题:构建以指令为中心的疑问,激发全面的第一人称导航分析。
- 时空一致的上下文构建:从每个导航轨迹中系统地选择结果WWW帧,构建时空一致的上下文。
- 结构化响应:通过将文本挑战与精选的视觉序列相结合,合成与指令对齐的多模态提示。GPT-4o生成结构化响应,涵盖场景描述、路径规划分析和常识推理。
多任务协作
为了解决单任务学习的局限性,引入了多任务协作策略,通过在导航任务和EQA任务上进行联合训练,显著提升导航能力。在训练阶段,模型同时从两个任务中学习,输入包括导航指令和EQA疑问。在推理阶段,模型专注于预测导航动作,利用在训练过程中获得的感知和规划能力。
实验
实验设置
- 数据集和评估指标:在CHORES-S ObjectNav基准测试上评估所提出的途径,并扩展导航数据集以包含EQA对用于联合训练。使用成功率(SR)、按剧集长度加权的成功率(SEL)和访问房间的百分比(%Rooms)三个指标来全面评估途径的有效性。
- 训练策略:利用AdamW优化器进行训练,采用8个A100 GPU,每个GPU的批量大小为48,总批量大小为384,训练5个epoch。采用余弦学习率策略,初始学习率为1×10−41 \times 10^{-4}1×10−4,最终衰减到1×10−61 \times 10^{-6}1×10−6。
性能比较
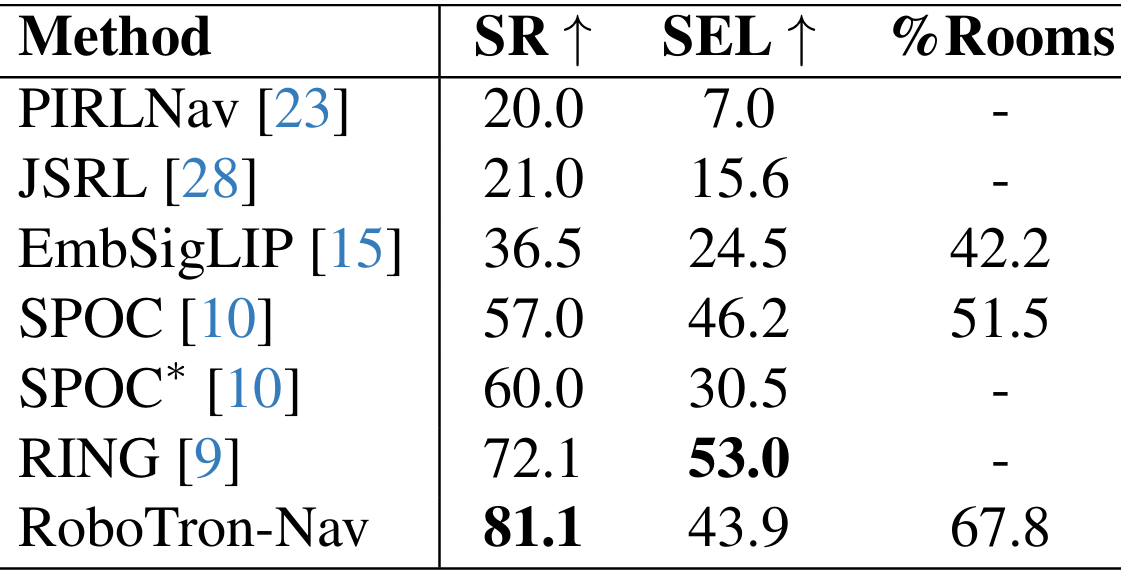
- 与其他办法的比较:与PIRLNav、JSRL、EmbSigLIP、SPOC、SPOC*和RING等方法相比,RoboTron-Nav在SR、SEL和%Rooms三个指标上均取得了最佳性能,证明了其在长期导航中的优越性。
- 关键数值结果:RoboTron-Nav在CHORES-S基准测试的ObjectNav任务上实现了81.1%的成功率,创下新的最高水平,比之前的方法绝对提升了9%。
定性结果
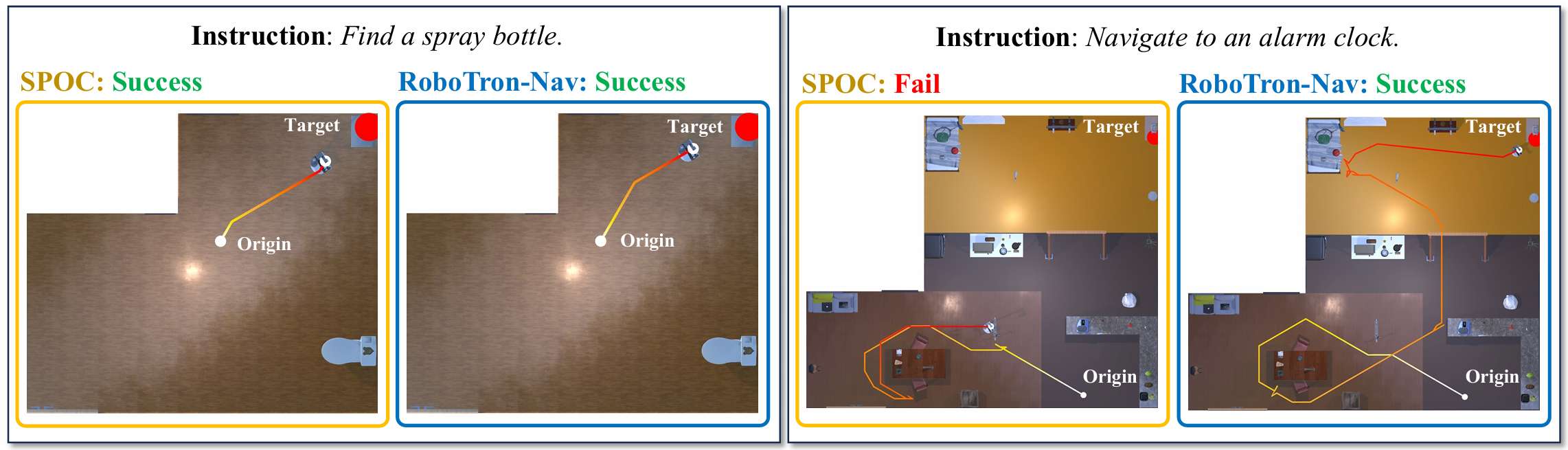
- 通过与SPOC方法的可视化结果比较,当智能体靠近目标时,RoboTron-Nav和SPOC都能生成最短路径;
- 然而,当智能体距离目标较远时,SPOC会重复搜索相同路径,而RoboTron-Nav能够避免重访已探索区域,探索新路径,提高导航效率。
消融研究
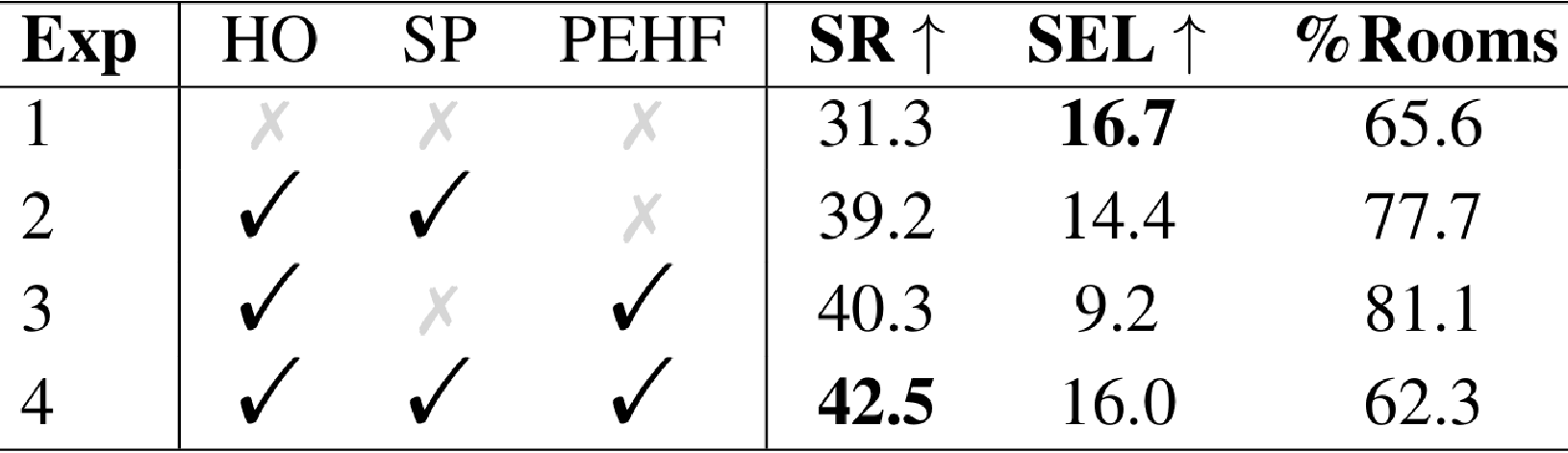
- 自适应3D感知历史采样策略的有效性:通过在ObjectNavRoom基准测试上的消融实验,验证了自适应3D感知历史采样策略中各个组件(历史观测、采样和位置增强历史特征)的有效性。实验结果表明,这些组件对提升导航性能起到了关键作用。
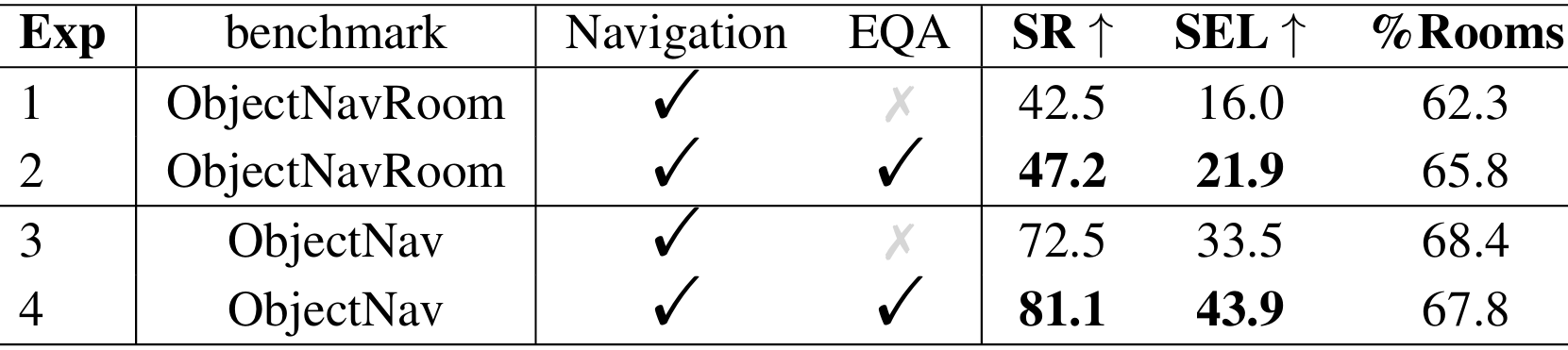
- 多任务协作策略的有效性:借助在导航任务和EQA任务上进行联合训练,显著提升了导航性能。实验结果表明,联合训练能够使模型更好地利用感知和规划能力,从而提高导航效率。
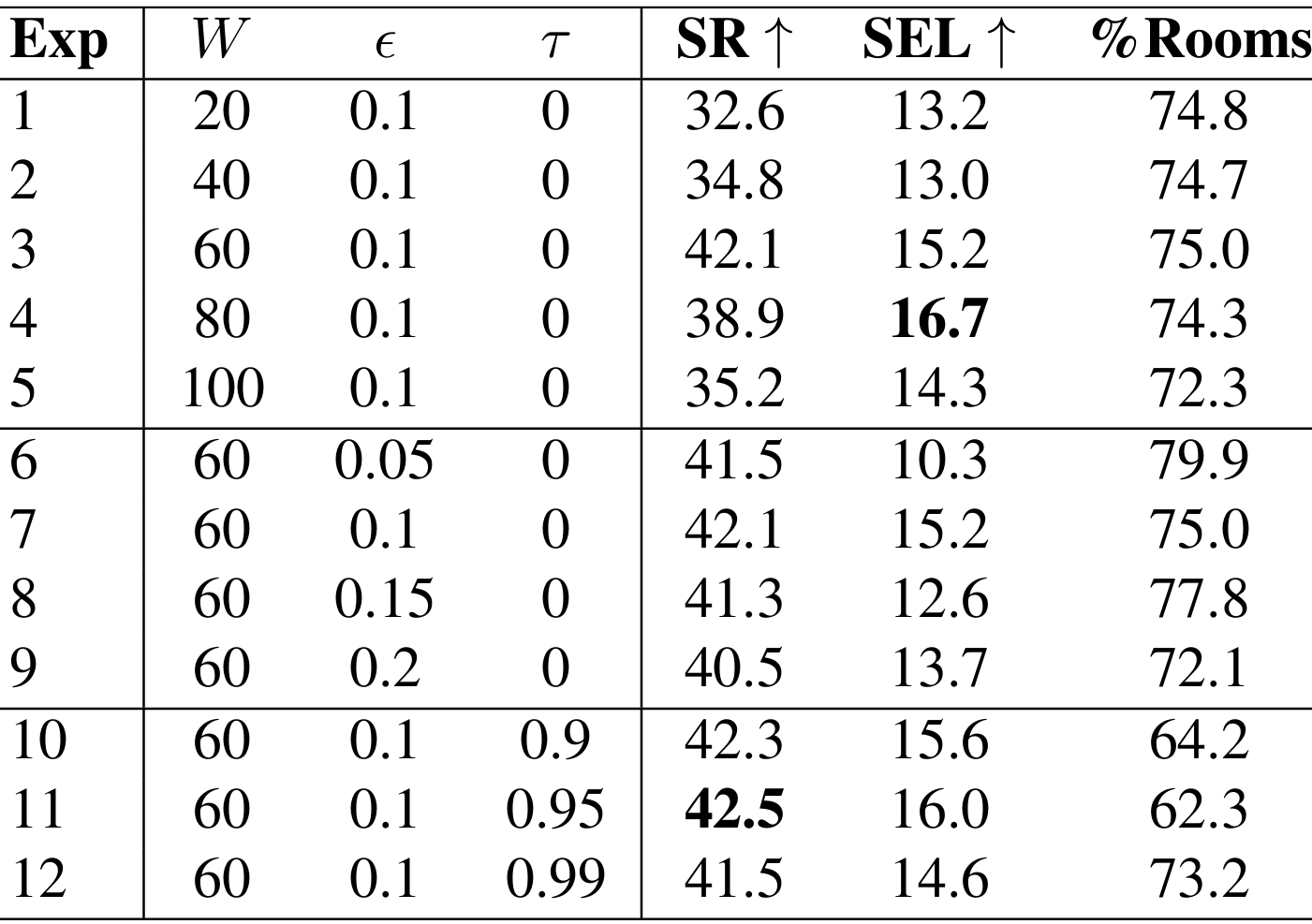
- 超参数分析:通过实验分析了3D感知历史采样策略中不同超参数(窗口大小WWW、相对位置阈值ϵ\epsilonϵ和语义相似性阈值τ\tauτ)对性能的影响,得出了最优的超参数设置:W=60W=60W=60、ϵ=0.1\epsilon=0.1ϵ=0.1和τ=0.95\tau=0.95τ=0.95。
结论与未来工作
- 结论:
- RoboTron-Nav框架依据奏效整合感知、规划和预测能力,显著提升了语言引导的视觉导航性能。
- 自适应3D感知历史采样策略能够高效利用历史数据以减少冗余,多任务协作策略则通过联合训练导航和EQA任务增强了模型的导航能力。
- 在CHORES-S基准测试上取得的81.1%的成功率证明了该框架的有效性。
- 未来工作:
- 尽管RoboTron-Nav在模拟环境中取得了显著成果,但要搭建真正类似人类的具身导航仍面临诸多挑战。
- 未来的工作将探索整合更大规模、更多样化的资料集,以进一步提升RoboTron-Nav在各种环境中的泛化能力。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号