


实用指南:第0记 cutlass 介绍及入门编程使用
0. 环境搭建
0.1. 实验部分的系统信息
ubuntu 22.04
cuda sdk toolkit 12.8
RTX 5080
cutlass main branch (cutlass 4.1 +, commit a49a78ffefc86a87160dfe0ccc3a3a2d1622c91 )
0.2. 编译cutlas
下载源码:
git clone https://github.com/NVIDIA/cutlass.git配置编译:
mkdir build/
cmake .. -DCUTLASS_NVCC_ARCHS="120" -DCMAKE_BUILD_TYPE="Debug"
make -j18示例代码的编译成果在 build/examples/ 中
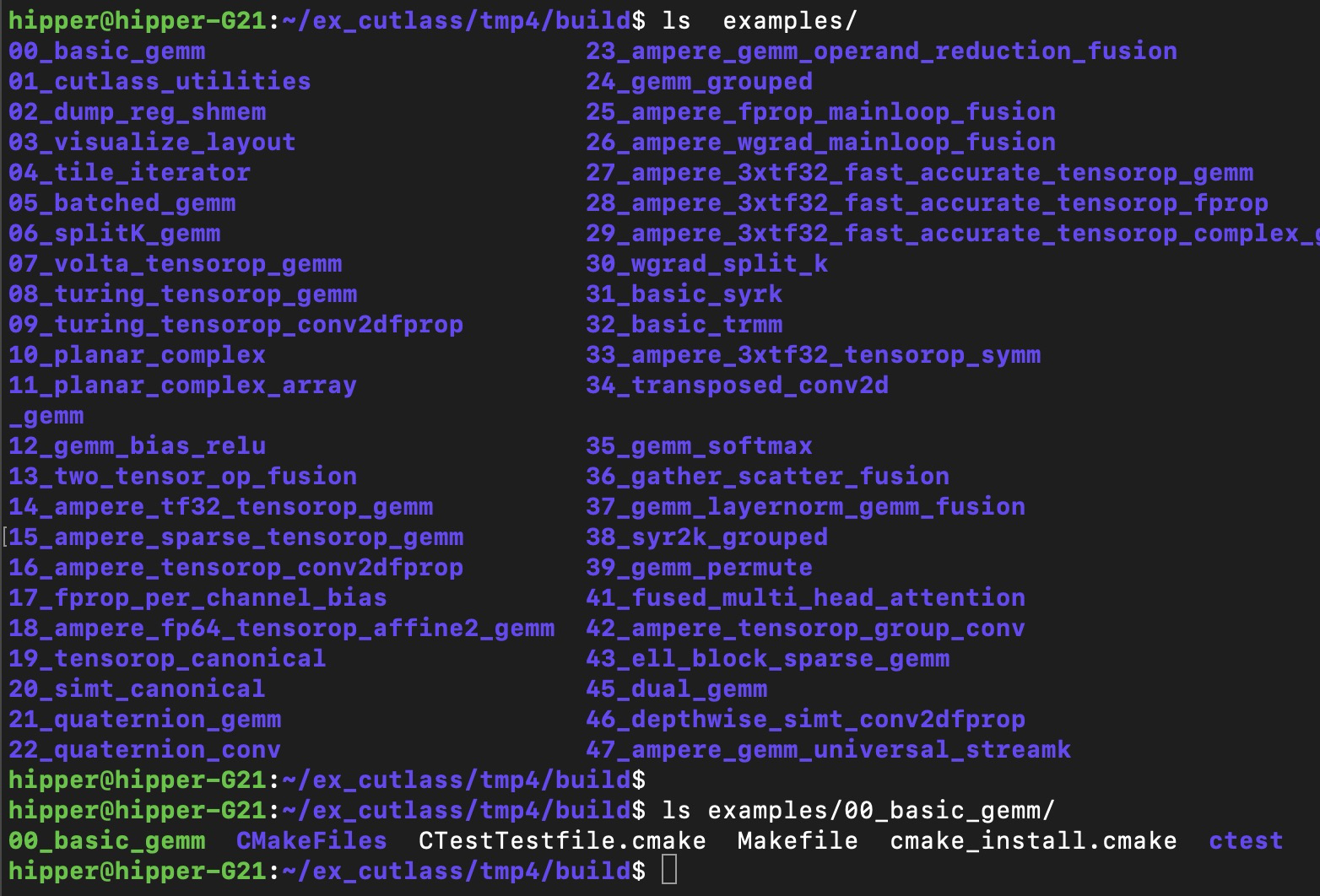
修改源码后,重新回到 build/ 中执行 make -j18
接下来先介绍一下 cutlass 的一些常用理念。
1. CUTLASS 简介
CUTLASS 是 NVIDIA 开发的一个开源 CUDA C++ 模板头文件库,用于在 NVIDIA GPU 上实现高性能矩阵乘法(GEMM)和相关计算。它的设计目标是模块化和可扩展性,让研究人员和开发者能够轻松地构建、组合和优化自己的 GEMM 内核,而无需从零开始编写复杂的 CUDA 代码。
核心设计理念:
分层与组合 将复杂的 GEMM 操作分解为多个层次化的、可重用的组件(如线程块、Warp、线程级别的计算)。
模板元编程 使用 C++ 模板在编译时确定算法、数据类型和硬件特性,以实现最大性能。
接近硬件的性能 通过精细控制内存层次(全局内存、共享内存、寄存器)的数据移动和计算流水线,其性能可以媲美高度调优的 cuBLAS 库。
2. CUTLASS 的核心概念与 API 功能
CUTLASS 的 API 主要由一系列模板类和宏构成,它们定义了计算的各个层次。
2.1. 关键层次结构 (Hierarchy)
一个典型的 CUTLASS GEMM 内核由下至上包含以下几个层次:
1. 线程块切片 (Threadblock-level Tile)
功能:定义一个线程块(Thread Block)负责处理的大块数据(Tile)。
API:cutlass::gemm::ThreadblockTileShape<M, N, K>;它决定了从全局内存到共享内存的数据加载量。
2. Warp 切片 (Warp-level Tile)
功能:定义一个 Warp(32个线程)负责处理的子数据块。
API:cutlass::gemm::WarpTileShape<M, N, K>它决定了共享内存到寄存器(Warp级)的数据移动。
3. 指令切片 (Instruction-level Tile)
功能:定义由 Tensor Core 或 CUDA Core 单条指令处理的最小数据块。
API:cutlass::gemm::GemmShape<M, N, K> 用于 Tensor Core 指令,例如 cutlass::arch::Mma<>。这是性能调优最精细的级别。
4. 全局迭代器 (Global Memory Iterator)
功能:负责将数据从全局内存高效地加载到共享内存。
API:例如 cutlass::transform::threadblock::PredicatedTileIterator
5. 共享内存迭代器 (Shared Memory Iterator)
功能:负责将数据从共享内存高效地加载到寄存器。
API:例如 cutlass::transform::warp::RegularTileIterator
6. 主循环流水线 (Mainloop Pipeline)
功能:组织整个计算过程,通过双缓冲(Double Buffering)等技术重叠数据加载和计算,隐藏内存延迟。
API:cutlass::pipeline 相关类。
7.GEMM 内核入口 (Gemm Kernel Entry Point)
功能:将上述所有组件组合成一个完整的、可启动的 CUDA 内核。
API:cutlass::gemm::kernel::Gemm 或 cutlass::gemm::device::Gemm
2.2. 重要宏 (Macros)
CUTLASS 使用宏来简化基于模板的代码生成,尤其是在处理不同数据类型和架构时。
CUTLASS_ARCH_MMA_SM80_ENABLED, CUTLASS_ARCH_MMA_SM75_ENABLED 等
功能:条件编译宏,用于检查当前编译目标架构(如 SM80 for Ampere)是否支持特定的 Tensor Core 指令集。确保代码在兼容的 GPU 上编译和运行。
CUTLASS_NAMESPACE_OPEN / CUTLASS_NAMESPACE_CLOSE
功能:用于控制 CUTLASS 符号的命名空间,通常在自定义扩展时使用。
3. 使用示例
以下是三个由浅入深的使用示例。
3.1. 示例 1:使用高级 device::Gemm API(最简单)
这是使用 CUTLASS 最直接的方式,类似于使用 cuBLAS。你只需要指定数据类型、布局和架构,CUTLASS 会自动选择预定义的高效内核。
00_basic_gemm/basic_gemm.cu
// Standard Library includes
#include
#include
#include
// Helper methods to check for errors
#include "helper.h"
//
// CUTLASS includes needed for single-precision GEMM kernel
//
// Defines cutlass::gemm::device::Gemm, the generic Gemm computation template class.
#include "cutlass/gemm/device/gemm.h"
///////////////////////////////////////////////////////////////////////////////////////////////////
//
// This function defines a CUTLASS GEMM kernel instantiation, constructs its parameters object,
// and launches it on the CUDA device.
//
///////////////////////////////////////////////////////////////////////////////////////////////////
/// Define a CUTLASS GEMM template and launch a GEMM kernel.
cudaError_t CutlassSgemmNN(
int M,
int N,
int K,
float alpha,
float const *A,
int lda,
float const *B,
int ldb,
float beta,
float *C,
int ldc) {
// Define type definition for single-precision CUTLASS GEMM with column-major
// input matrices and 128x128x8 threadblock tile size (chosen by default).
//
// To keep the interface manageable, several helpers are defined for plausible compositions
// including the following example for single-precision GEMM. Typical values are used as
// default template arguments. See `cutlass/gemm/device/default_gemm_configuration.h` for more details.
//
// To view the full gemm device API interface, see `cutlass/gemm/device/gemm.h`
using ColumnMajor = cutlass::layout::ColumnMajor;
using CutlassGemm = cutlass::gemm::device::Gemm; // Layout of C matrix
// Define a CUTLASS GEMM type
CutlassGemm gemm_operator;
// Construct the CUTLASS GEMM arguments object.
//
// One of CUTLASS's design patterns is to define gemm argument objects that are constructible
// in host code and passed to kernels by value. These may include pointers, strides, scalars,
// and other arguments needed by Gemm and its components.
//
// The benefits of this pattern are (1.) a structured, composable strategy for passing host-constructible
// arguments to kernels and (2.) minimized initialization overhead on kernel entry.
//
CutlassGemm::Arguments args({M , N, K}, // Gemm Problem dimensions
{A, lda}, // Tensor-ref for source matrix A
{B, ldb}, // Tensor-ref for source matrix B
{C, ldc}, // Tensor-ref for source matrix C
{C, ldc}, // Tensor-ref for destination matrix D (may be different memory than source C matrix)
{alpha, beta}); // Scalars used in the Epilogue
//
// Launch the CUTLASS GEMM kernel.
//
cutlass::Status status = gemm_operator(args);
//
// Return a cudaError_t if the CUTLASS GEMM operator returned an error code.
//
if (status != cutlass::Status::kSuccess) {
return cudaErrorUnknown;
}
// Return success, if no errors were encountered.
return cudaSuccess;
}
///////////////////////////////////////////////////////////////////////////////////////////////////
//
// The source code after this point in the file is generic CUDA using the CUDA Runtime API
// and simple CUDA kernels to initialize matrices and compute the general matrix product.
//
///////////////////////////////////////////////////////////////////////////////////////////////////
/// Kernel to initialize a matrix with small integers.
__global__ void InitializeMatrix_kernel(
float *matrix,
int rows,
int columns,
int seed = 0) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
int j = threadIdx.y + blockIdx.y * blockDim.y;
if (i >>(matrix, rows, columns, seed);
return cudaGetLastError();
}
///////////////////////////////////////////////////////////////////////////////////////////////////
/// Allocates device memory for a matrix then fills with arbitrary small integers.
cudaError_t AllocateMatrix(float **matrix, int rows, int columns, int seed = 0) {
cudaError_t result;
size_t sizeof_matrix = sizeof(float) * rows * columns;
// Allocate device memory.
result = cudaMalloc(reinterpret_cast(matrix), sizeof_matrix);
if (result != cudaSuccess) {
std::cerr >>(M, N, K, alpha, A, lda, B, ldb, beta, C, ldc);
return cudaGetLastError();
}
///////////////////////////////////////////////////////////////////////////////////////////////////
/// Allocate several matrices in GPU device memory and call a single-precision
/// CUTLASS GEMM kernel.
cudaError_t TestCutlassGemm(int M, int N, int K, float alpha, float beta) {
cudaError_t result;
//
// Define several matrices to be used as operands to GEMM kernels.
//
// Compute leading dimensions for each matrix.
int lda = M;
int ldb = K;
int ldc = M;
// Compute size in bytes of the C matrix.
size_t sizeof_C = sizeof(float) * ldc * N;
// Define pointers to matrices in GPU device memory.
float *A;
float *B;
float *C_cutlass;
float *C_reference;
//
// Allocate matrices in GPU device memory with arbitrary seeds.
//
result = AllocateMatrix(&A, M, K, 0);
if (result != cudaSuccess) {
return result;
}
result = AllocateMatrix(&B, K, N, 17);
if (result != cudaSuccess) {
cudaFree(A);
return result;
}
result = AllocateMatrix(&C_cutlass, M, N, 101);
if (result != cudaSuccess) {
cudaFree(A);
cudaFree(B);
return result;
}
result = AllocateMatrix(&C_reference, M, N, 101);
if (result != cudaSuccess) {
cudaFree(A);
cudaFree(B);
cudaFree(C_cutlass);
return result;
}
result = cudaMemcpy(C_reference, C_cutlass, sizeof_C, cudaMemcpyDeviceToDevice);
if (result != cudaSuccess) {
std::cerr host_cutlass(ldc * N, 0);
std::vector host_reference(ldc * N, 0);
result = cudaMemcpy(host_cutlass.data(), C_cutlass, sizeof_C, cudaMemcpyDeviceToHost);
if (result != cudaSuccess) {
std::cerr
//
int main(int argc, const char *arg[]) {
//
// Parse the command line to obtain GEMM dimensions and scalar values.
//
// GEMM problem dimensions.
int problem[3] = { 128, 128, 128 };
for (int i = 1; i > problem[i - 1];
}
// Scalars used for linear scaling the result of the matrix product.
float scalars[2] = { 1, 0 };
for (int i = 4; i > scalars[i - 4];
}
//
// Run the CUTLASS GEMM test.
//
cudaError_t result = TestCutlassGemm(
problem[0], // GEMM M dimension
problem[1], // GEMM N dimension
problem[2], // GEMM K dimension
scalars[0], // alpha
scalars[1] // beta
);
if (result == cudaSuccess) {
std::cout << "Passed." << std::endl;
}
// Exit.
return result == cudaSuccess ? 0 : -1;
}
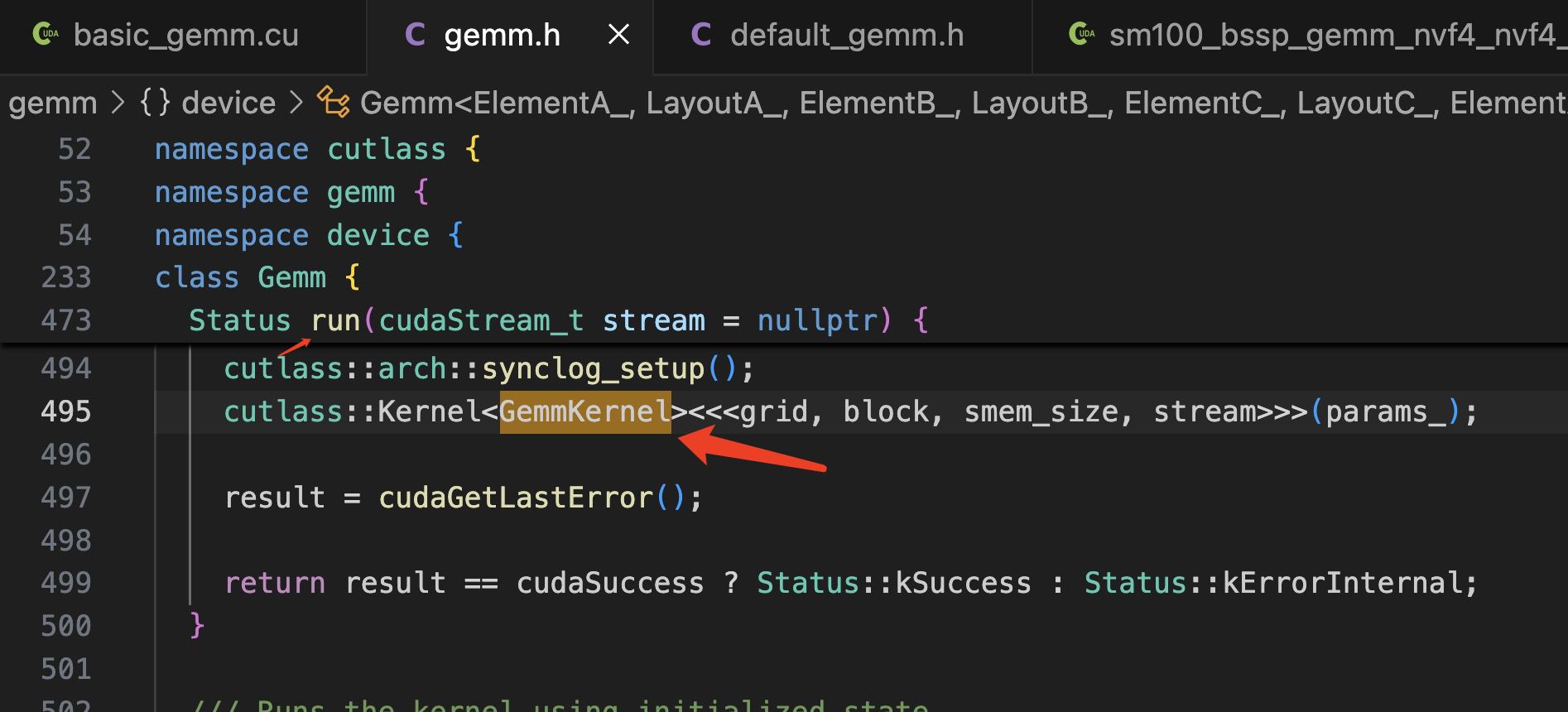
///////////////////////////////////////////////////////////////////////////////////////////////////从 main() 到 cutlass::Kernel<GemmKernel><<<grid, block, smem_size, stream>>>(params_);
其中:using GemmKernel = typename UnderlyingOperator::GemmKernel;
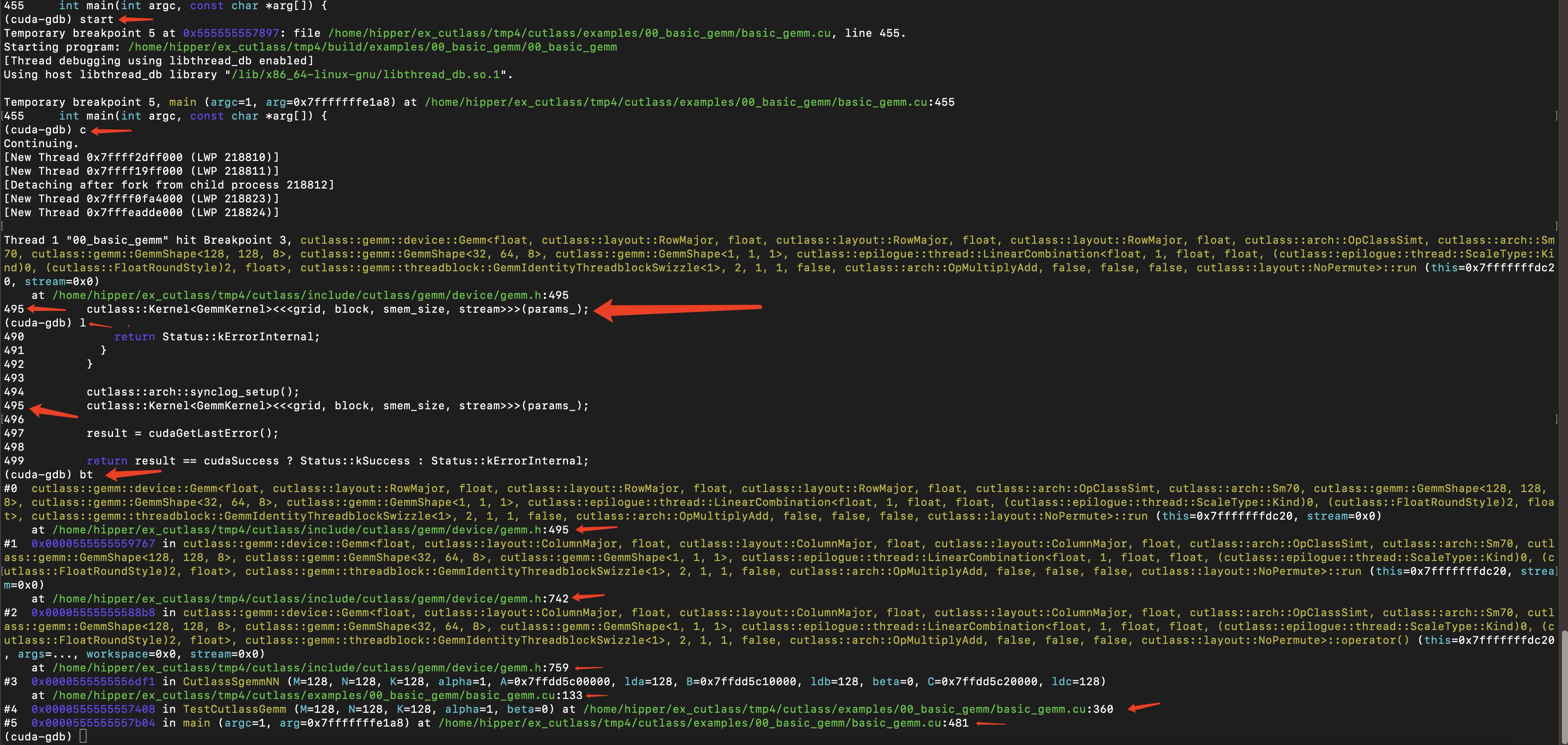
启动 cutlass::Kernel()
include/cutlass/device_kernel.h
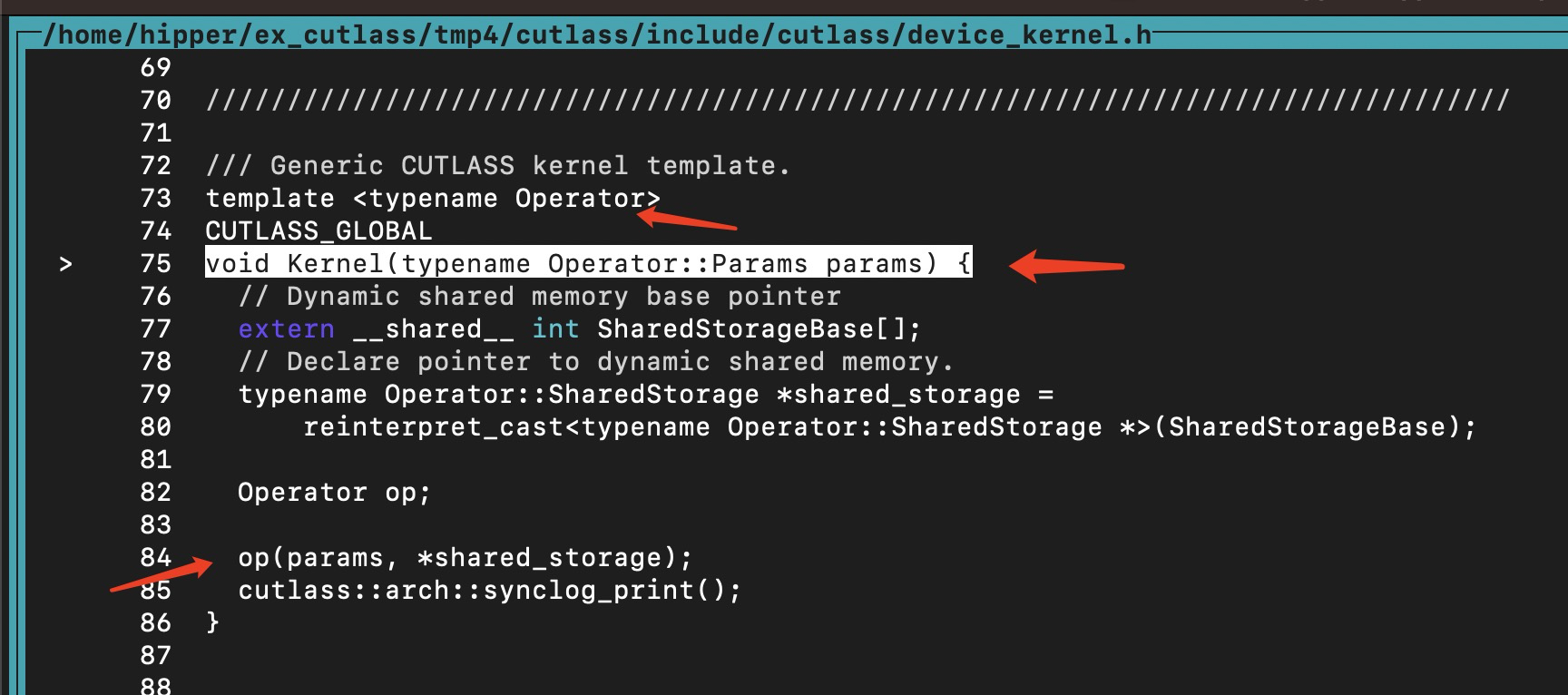
/// Generic CUTLASS kernel template.
template
CUTLASS_GLOBAL
void Kernel(typename Operator::Params params) {
// Dynamic shared memory base pointer
extern __shared__ int SharedStorageBase[];
// Declare pointer to dynamic shared memory.
typename Operator::SharedStorage *shared_storage =
reinterpret_cast(SharedStorageBase);
Operator op;
op(params, *shared_storage);
cutlass::arch::synclog_print();
}其中的 GemmKernel 就是这里的 template <typename Operator> 中的 Operator,
可以通过 ptype 来查看去具体名称和实现:
调试过程:
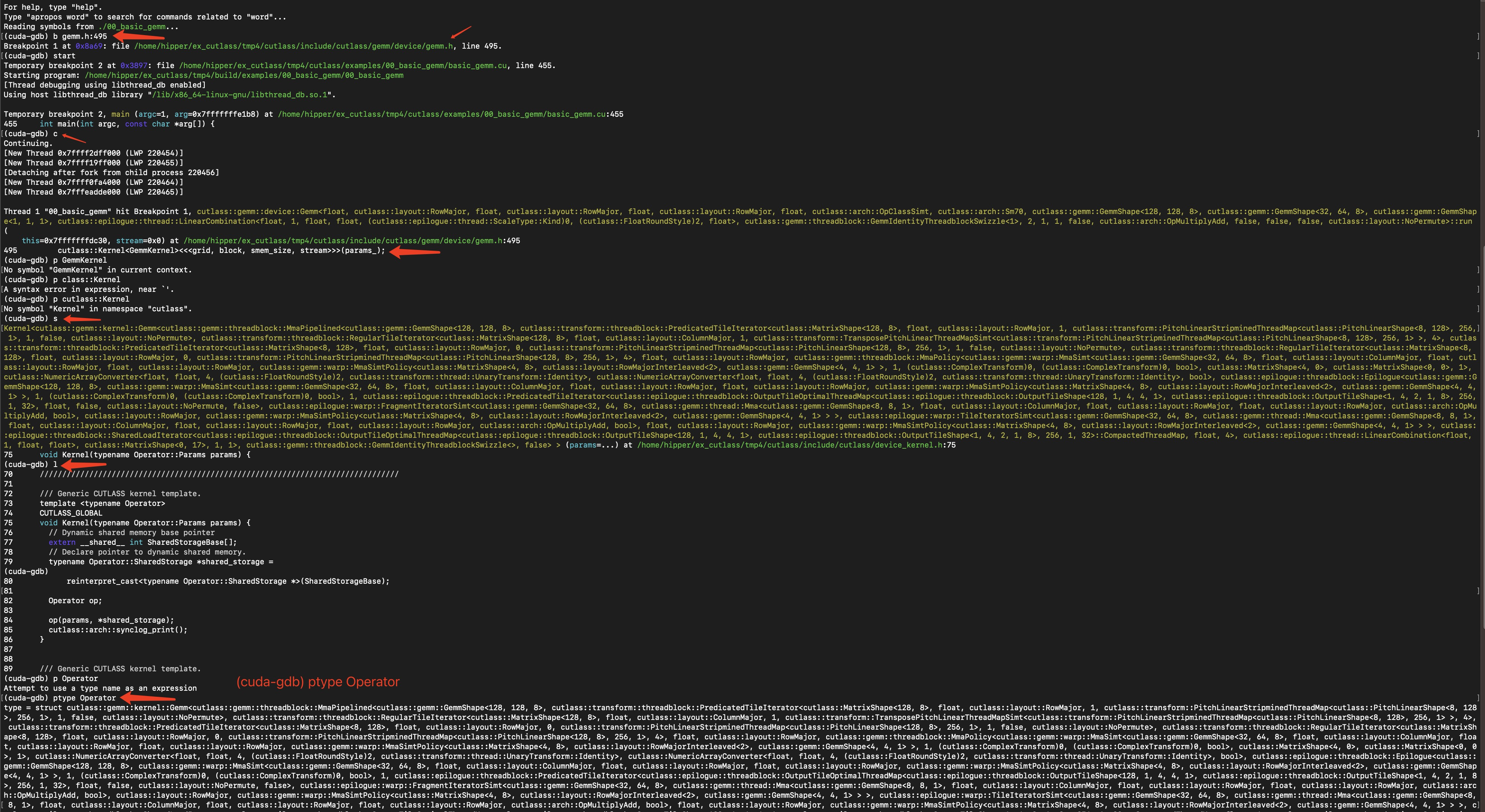
输出信息比较长,总体上,这个 Operator 是一个 模版函数 cuda kernel,包含四个模版参数,前两个参数非常长,这里用空行隔开了,图中红框是四个模版参数:
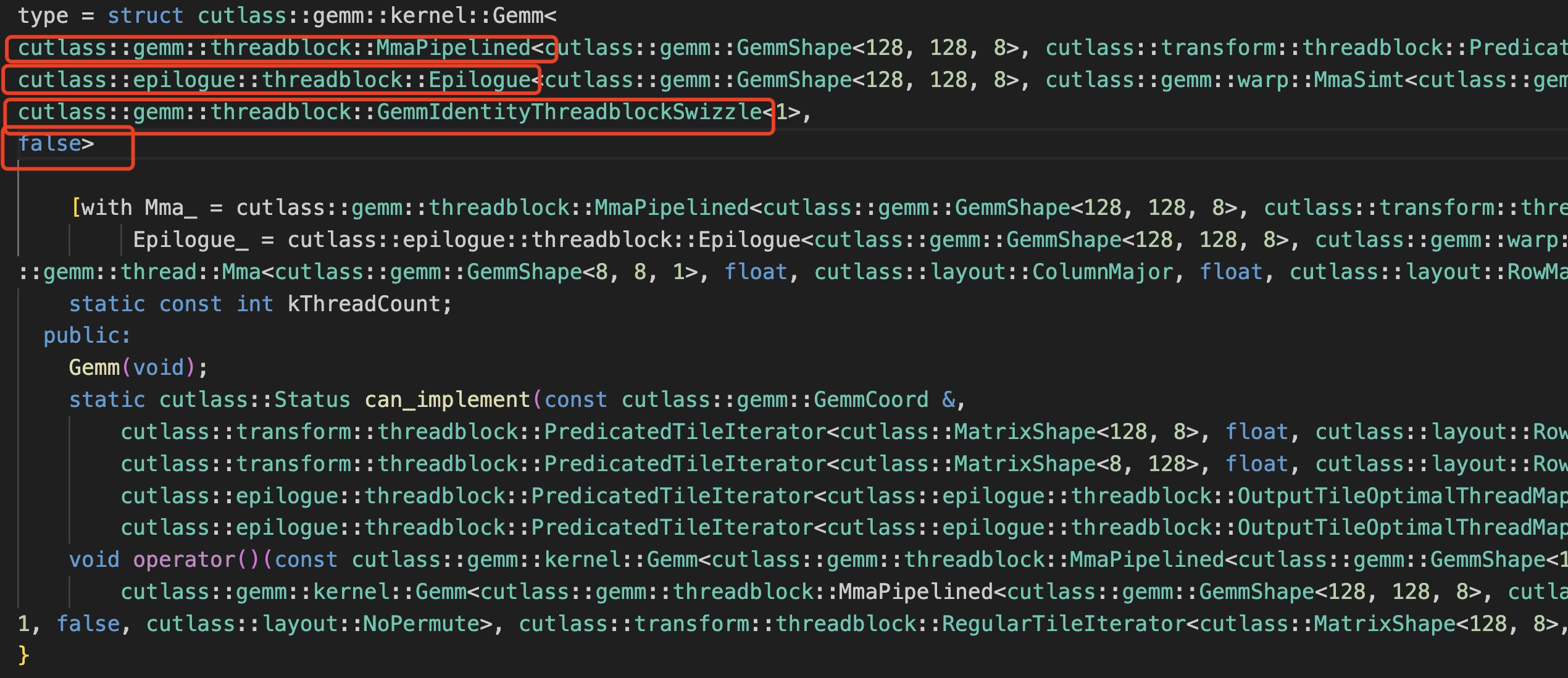
struct cutlass::gemm::kernel::Gemm
< cutlass::gemm::threadblock::MmaPipelined< ... >,
cutlass::epilogue::threadblock::Epilogue< ... >,
cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle< 1 >,
false>
ptype 完整的输出内容放在这里待考:
type = struct cutlass::gemm::kernel::Gemm
, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 1, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::ColumnMajor, 1, cutlass::transform::TransposePitchLinearThreadMapSimt, 256, 1> >, 4>, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 4>, float, cutlass::layout::RowMajor, cutlass::gemm::threadblock::MmaPolicy, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, cutlass::MatrixShape, cutlass::MatrixShape, 1>, cutlass::NumericArrayConverter, cutlass::NumericArrayConverter, bool>,
cutlass::epilogue::threadblock::Epilogue, cutlass::gemm::warp::MmaSimt, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, 1, cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>, cutlass::epilogue::warp::FragmentIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::warp::TileIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::threadblock::SharedLoadIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>::CompactedThreadMap, float, 4>, cutlass::epilogue::thread::LinearCombination, cutlass::MatrixShape, 1, 1>,
cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle,
false
>
[with Mma_ = cutlass::gemm::threadblock::MmaPipelined, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 1, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::ColumnMajor, 1, cutlass::transform::TransposePitchLinearThreadMapSimt, 256, 1> >, 4>, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 4>, float, cutlass::layout::RowMajor, cutlass::gemm::threadblock::MmaPolicy, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, cutlass::MatrixShape, cutlass::MatrixShape, 1>, cutlass::NumericArrayConverter, cutlass::NumericArrayConverter, bool>,
Epilogue_ = cutlass::epilogue::threadblock::Epilogue, cutlass::gemm::warp::MmaSimt, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, 1, cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>, cutlass::epilogue::warp::FragmentIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::warp::TileIteratorSimt, cutlass--Type for more, q to quit, c to continue without paging--
::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::threadblock::SharedLoadIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>::CompactedThreadMap, float, 4>, cutlass::epilogue::thread::LinearCombination, cutlass::MatrixShape, 1, 1>, ThreadblockSwizzle_ = cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle] {
static const int kThreadCount;
public:
Gemm(void);
static cutlass::Status can_implement(const cutlass::gemm::GemmCoord &,
cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 1, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>::TensorRef,
cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>::TensorRef,
cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>::TensorRef,
cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>::TensorRef);
void operator()(const cutlass::gemm::kernel::Gemm, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 1, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::ColumnMajor, 1, cutlass::transform::TransposePitchLinearThreadMapSimt, 256, 1> >, 4>, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 4>, float, cutlass::layout::RowMajor, cutlass::gemm::threadblock::MmaPolicy, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, cutlass::MatrixShape, cutlass::MatrixShape, 1>, cutlass::NumericArrayConverter, cutlass::NumericArrayConverter, bool>, cutlass::epilogue::threadblock::Epilogue, cutlass::gemm::warp::MmaSimt, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, 1, cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>, cutlass::epilogue::warp::FragmentIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::warp::TileIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::threadblock::SharedLoadIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>::CompactedThreadMap, float, 4>, cutlass::epilogue::thread::LinearCombination, cutlass::MatrixShape, 1, 1>, cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle, false>::Params &,
cutlass::gemm::kernel::Gemm, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 1, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, --Type for more, q to quit, c to continue without paging--
1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::ColumnMajor, 1, cutlass::transform::TransposePitchLinearThreadMapSimt, 256, 1> >, 4>, cutlass::transform::threadblock::PredicatedTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 1, false, cutlass::layout::NoPermute>, cutlass::transform::threadblock::RegularTileIterator, float, cutlass::layout::RowMajor, 0, cutlass::transform::PitchLinearStripminedThreadMap, 256, 1>, 4>, float, cutlass::layout::RowMajor, cutlass::gemm::threadblock::MmaPolicy, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, cutlass::MatrixShape, cutlass::MatrixShape, 1>, cutlass::NumericArrayConverter, cutlass::NumericArrayConverter, bool>, cutlass::epilogue::threadblock::Epilogue, cutlass::gemm::warp::MmaSimt, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape >, 1, (cutlass::ComplexTransform)0, (cutlass::ComplexTransform)0, bool>, 1, cutlass::epilogue::threadblock::PredicatedTileIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>, float, false, cutlass::layout::NoPermute, false>, cutlass::epilogue::warp::FragmentIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::warp::TileIteratorSimt, cutlass::gemm::thread::Mma, float, cutlass::layout::ColumnMajor, float, cutlass::layout::RowMajor, float, cutlass::layout::RowMajor, cutlass::arch::OpMultiplyAdd, bool>, float, cutlass::layout::RowMajor, cutlass::gemm::warp::MmaSimtPolicy, cutlass::layout::RowMajorInterleaved, cutlass::gemm::GemmShape > >, cutlass::epilogue::threadblock::SharedLoadIterator, cutlass::epilogue::threadblock::OutputTileShape, 256, 1, 32>::CompactedThreadMap, float, 4>, cutlass::epilogue::thread::LinearCombination, cutlass::MatrixShape, 1, 1>, cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle, false>::SharedStorage &);
}cuda kernel 启动的地方:
cutlass::Kernel>>(params_);具体代码出现如下图:
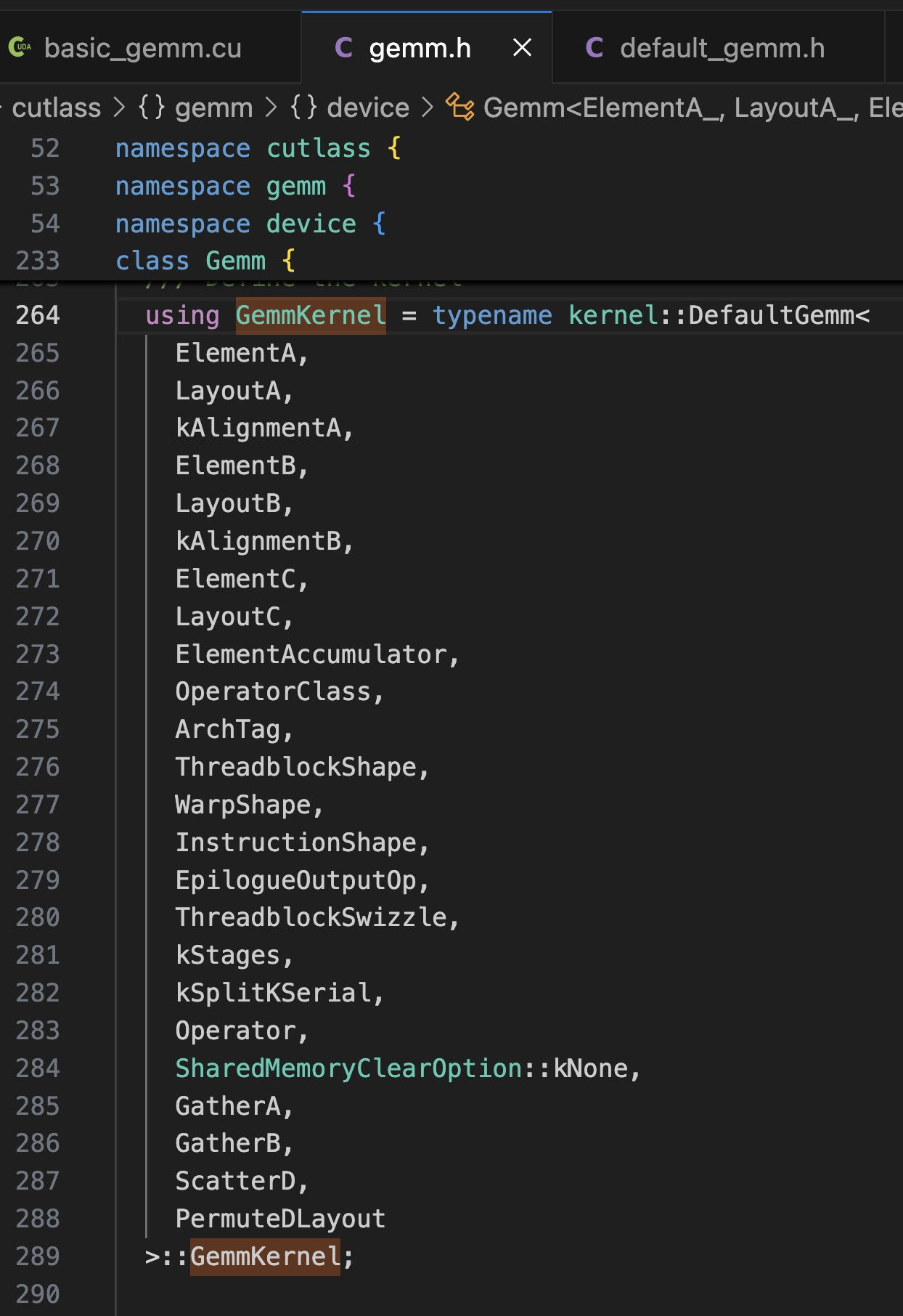
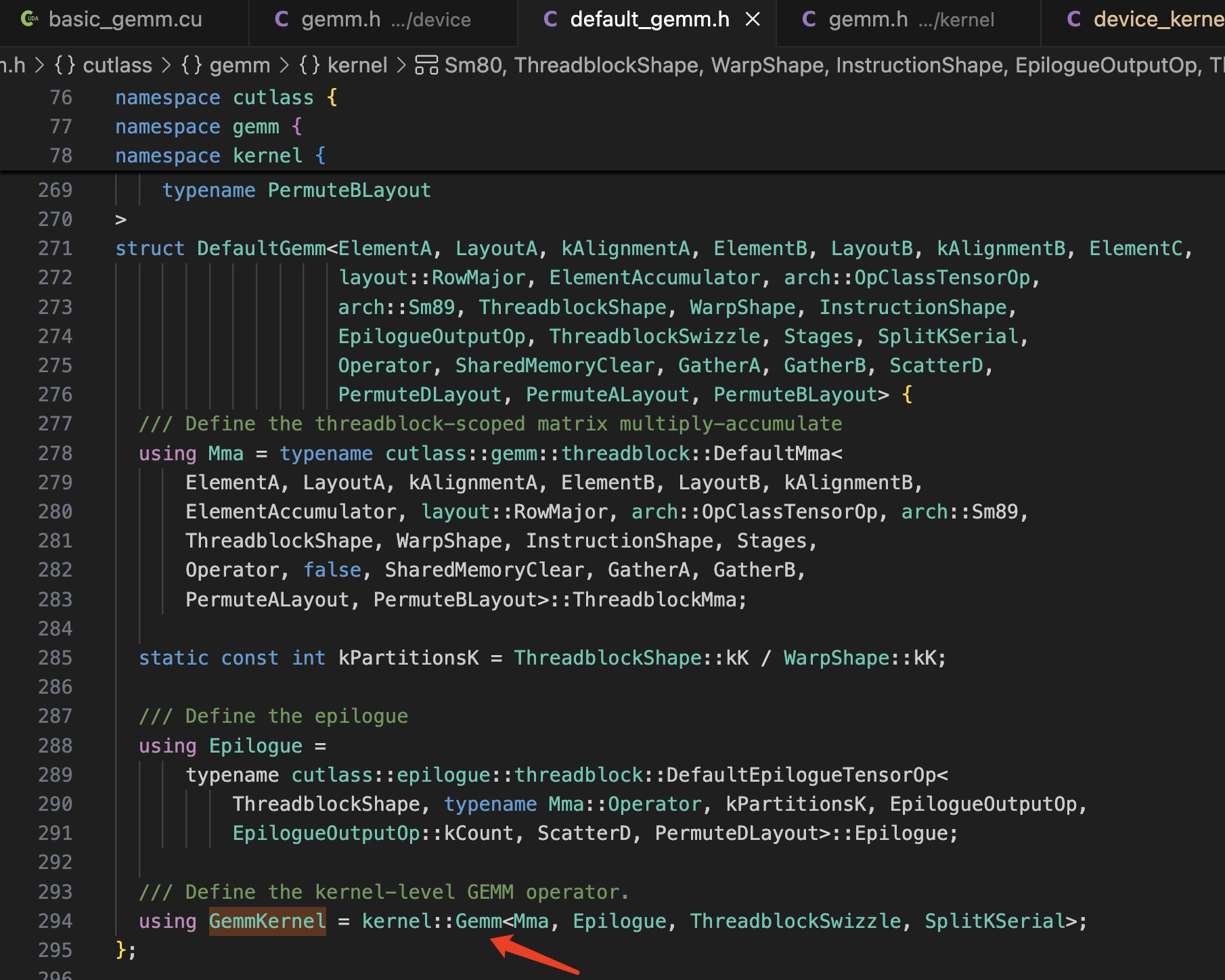
而模版参数 GemmKernel 的定义出现在:
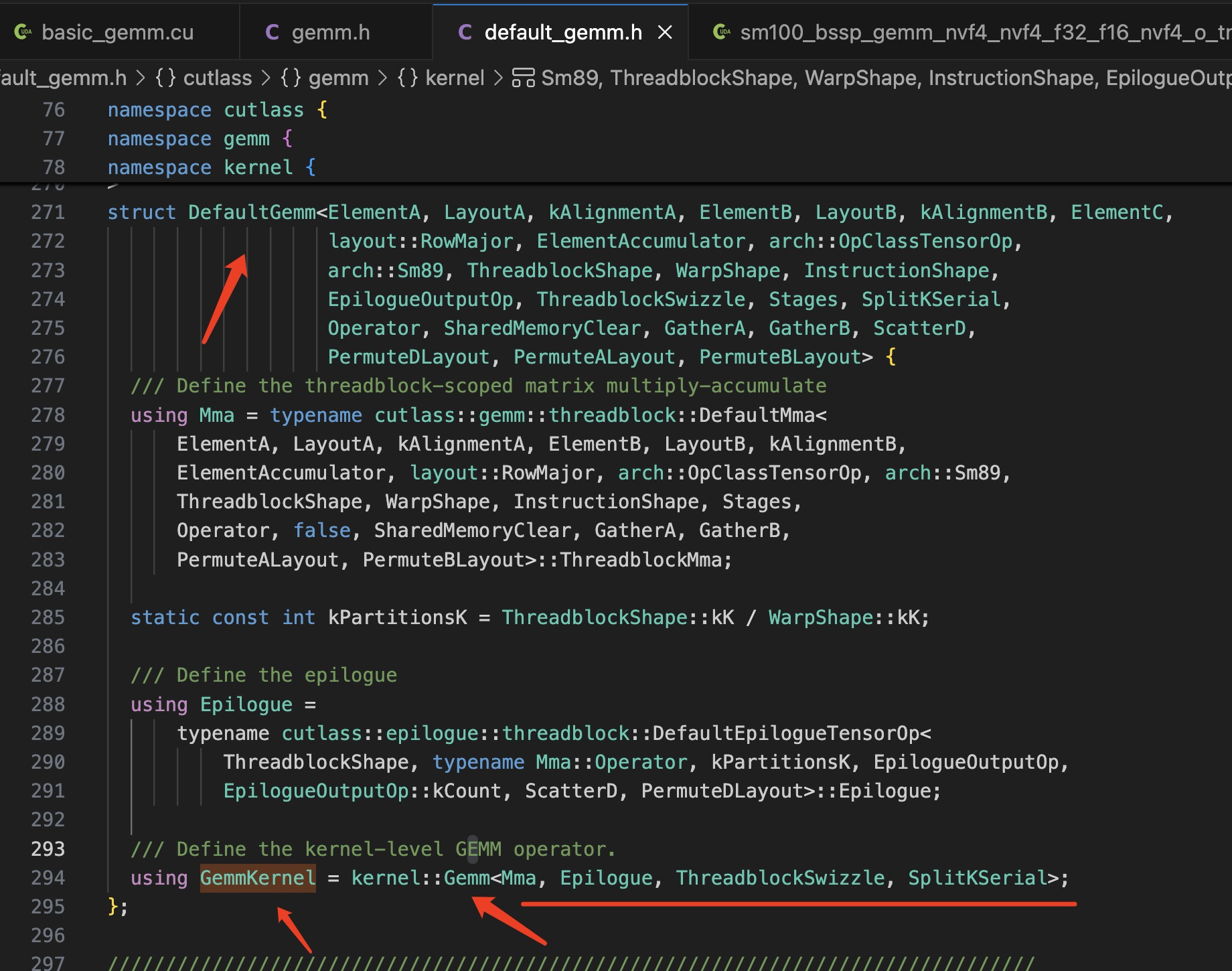
于是,定义走到了 kernel::DefaultGemm< ... >
关键信息:
using GemmKernel = kernel::Gemm;这里了的四个模版参数,对应之前 ptype 的输出信息:
struct cutlass::gemm::kernel::Gemm
<cutlass::gemm::threadblock::MmaPipelined< ... >,
cutlass::epilogue::threadblock::Epilogue< ... >,
cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle< 1 >,
false>
初步验证一下,加入一行打印:
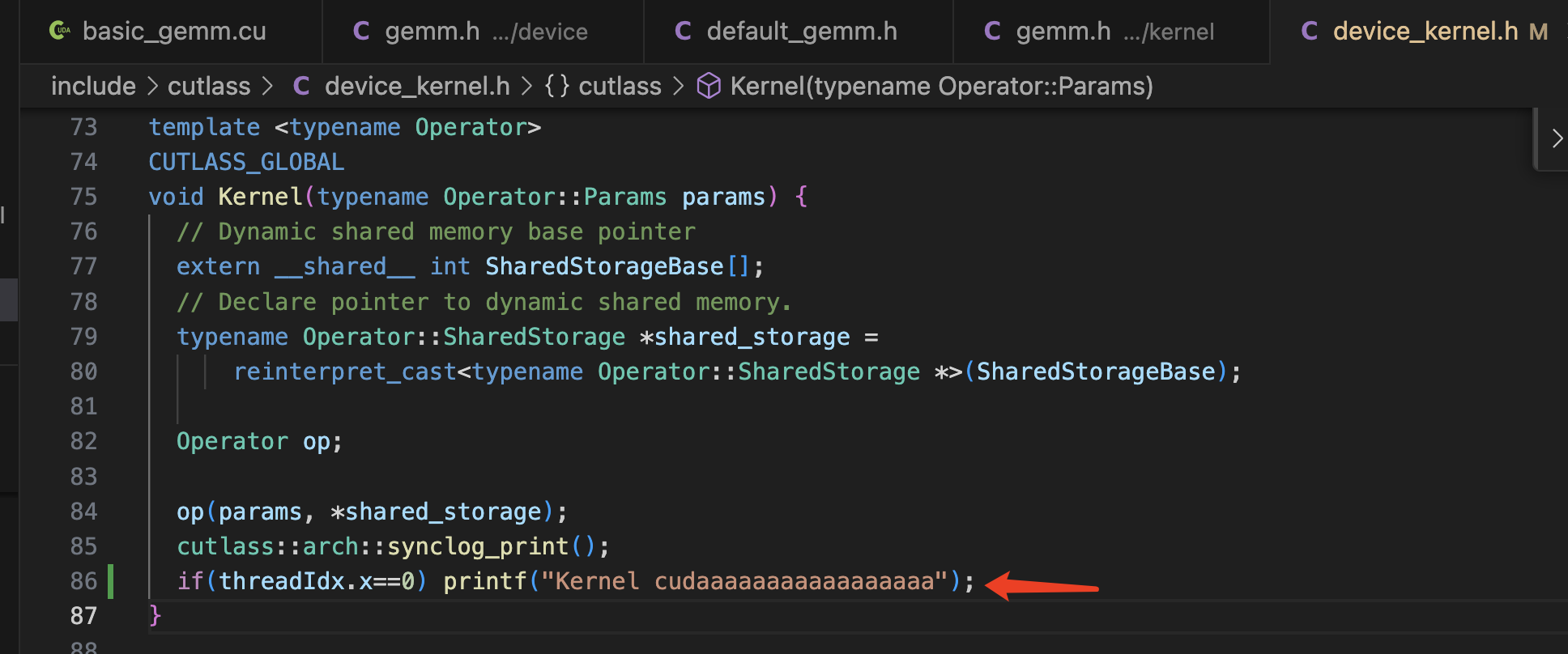
在 build/ 文件夹下重新 make -j18
然后重新执行 ./
$ ./00_basic_gemm可以看到 printf 从gpu 中执行输出:
![]()
真正执行 Gemm 的 cuda kernel 是哪一个呢?
跟踪 Gemm in using GemmKernel = kernel::Gemm<Mma, Epilogue, ThreadblockSwizzle, SplitKSerial>;
可以找到 gemm.h 文件中的 struct Gemm:: Operator() 的定义,这个定义便是 gemm cuda kernel 的主体:
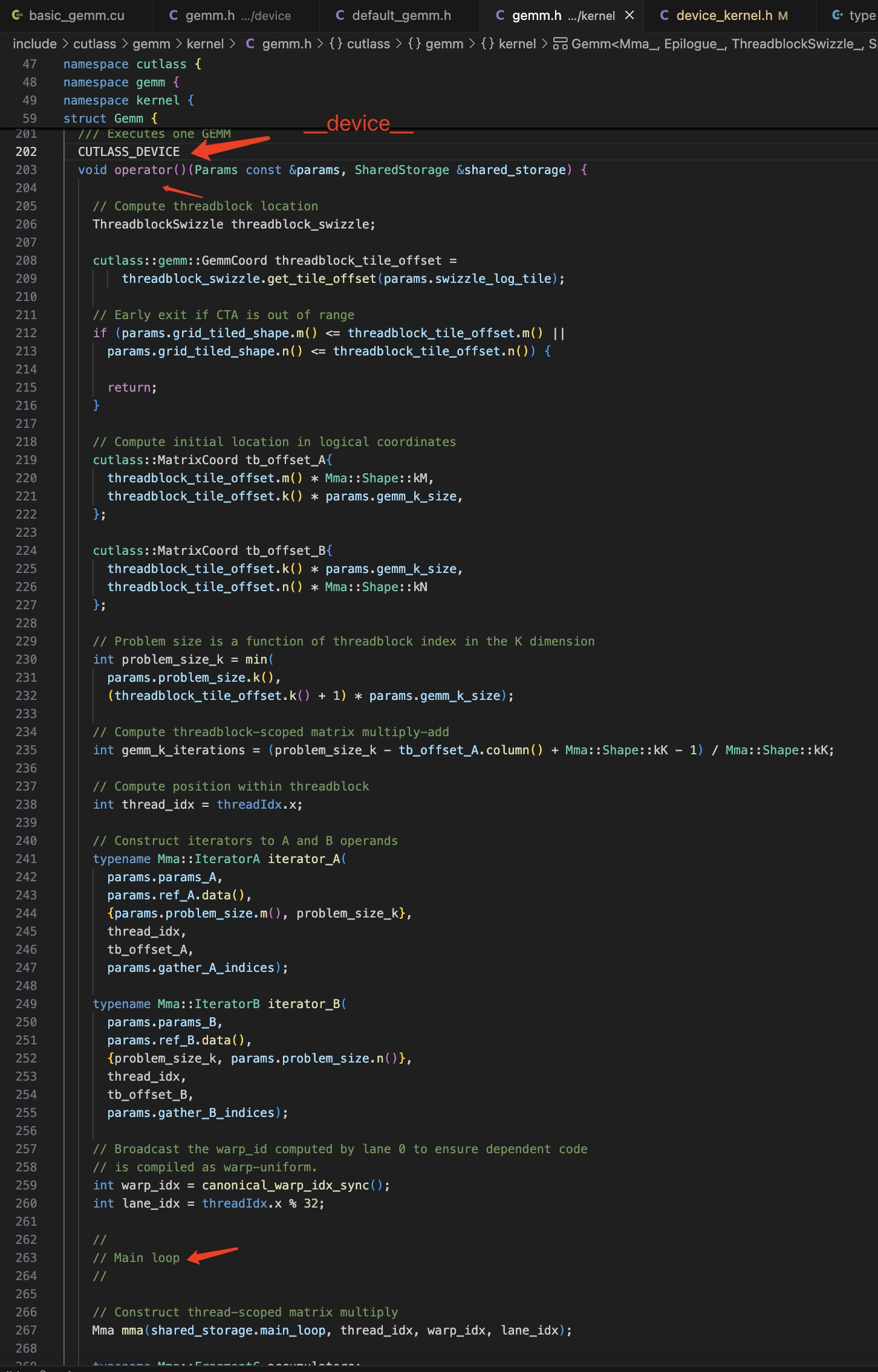
gemm kernel 写的多了,自然就知道哪些部分是主体框架,哪些部分是个性化的可以修改的代码区,于是就可以做成 template。
3.2. 示例 2:自定义内核配置(中级)
如果你想改变默认的平铺大小(Tile Size)或使用不同的数据流,你需要自定义内核配置。
#include
#include
// 自定义配置
using ElementA = cutlass::half_t;
using LayoutA = cutlass::layout::RowMajor;
using ElementB = cutlass::half_t;
using LayoutB = cutlass::layout::ColumnMajor; // 尝试不同的布局
using ElementC = float; // 累加器使用更高的精度
using LayoutC = cutlass::layout::RowMajor;
// 1. 定义线程块和Warp的平铺形状
using ThreadblockShape = cutlass::gemm::GemmShape; // Threadblock tile M, N, K
using WarpShape = cutlass::gemm::GemmShape; // Warp tile M, N, K
// 2. 定义指令形状 (对于 Tensor Core)
using InstructionShape = cutlass::gemm::GemmShape; // MMA instruction shape
// 3. 使用自定义配置定义Gemm内核
using GemmKernel = typename cutlass::gemm::kernel::DefaultGemmUniversal, // Epilogue
cutlass::gemm::threadblock::GemmIdentityThreadblockSwizzle<>, // Swizzling 函数
3 // Stages (用于共享内存双缓冲)
>::GemmKernel;
// 4. 定义设备级的 Gemm 操作
using GemmOp = cutlass::gemm::device::GemmUniversalAdapter;
int main() {
// ... (内存分配和初始化与示例1类似) ...
GemmOp gemm_op;
typename GemmOp::Arguments args(
{M, N, K}, // Problem size
{d_A, K}, // Tensor A
{d_B, K}, // Tensor B (列优先,ldb=K)
{d_C, N}, // Tensor C
{d_D, N}, // Tensor D
{alpha, beta} // Epilogue parameters
);
// 初始化 Gemm 操作 (分配共享内存等工作空间)
cutlass::Status status = gemm_op.initialize(args);
if (status != cutlass::Status::kSuccess) {
// ... error handling ...
}
// 启动内核
status = gemm_op.run();
if (status != cutlass::Status::kSuccess) {
// ... error handling ...
}
// ... (后续步骤与示例1相同) ...
}3.3. 示例 3:实现融合操作(高级)
CUTLASS 的强大之处在于其 Epilogue 可以自定义。你可以在 GEMM 计算结束后,在将数据写回全局内存之前,执行额外的逐元素操作(如激活函数、偏差相加等)。
#include
#include // 带 ReLU 的 Epilogue
using ElementCompute = float;
using ElementOutput = cutlass::half_t;
// 定义一个使用 ReLU 作为激活函数的 Epilogue
using EpilogueOp = cutlass::epilogue::thread::LinearCombinationRelu::value, // Alignment
ElementCompute, // Accumulator data type
ElementCompute // Epilogue computation data type
>;
// 将自定义的 Epilogue 应用到 Gemm 定义中
using Gemm = cutlass::gemm::device::Gemm,
cutlass::gemm::GemmShape,
cutlass::gemm::GemmShape,
EpilogueOp // 使用自定义的 Epilogue 替代默认的
>;
int main() {
// ... (内存分配和初始化) ...
// 注意:EpilogueOp 需要 alpha 和 beta 参数
float alpha = 1.0f;
float beta = 0.0f;
Gemm gemm_op;
// 执行 GEMM + ReLU: D = ReLU(alpha * A * B + beta * C)
auto status = gemm_op({
{M, N, K},
{d_A, K},
{d_B, N},
{d_C, N},
{d_D, N},
{alpha, beta} // 这些参数会被传递给 EpilogueOp
});
// ... (后续步骤) ...
} 在这个例子中,GEMM 的核心计算完成后,结果不会直接写回,而是会先经过一个 LinearCombinationRelu 操作(即 result = max(0, alpha * accumulator + beta * source)),然后再存放到 D 中。这个过程完全在芯片上的寄存器中进行,避免了额外的内核启动和全局内存读写,极大地提升了性能。
总结
| 特性/示例 | 示例 1 (基础) | 示例 2 (中级) | 示例 3 (高级) |
|---|---|---|---|
| 核心API | device::Gemm | kernel::DefaultGemmUniversal | epilogue::thread::LinearCombinationRelu |
| 自定义程度 | 低(使用默认配置) | 中(自定义平铺大小、数据流) | 高(自定义计算后的操作) |
| 优点 | 简单易用,类似 cuBLAS | 可针对特定问题尺寸优化 | 实现算子融合,极致性能 |
| 适用场景 | 快速原型、标准 GEMM | 需要特定性能调优 | 实现自定义激活函数的混合层 |
CUTLASS 是一个极其强大的工具,但它也有较高的学习曲线。对于大多数应用,从高级 API(示例1)开始是明智的选择。当你需要极致性能或特殊功能时,再逐步深入其底层配置(示例2和3)。官方文档和代码库(GitHub - NVIDIA/cutlass)提供了大量丰富的示例,是学习的最佳资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号