


IJCAI2025 | SoP策略:首次识别MTLC问题,模型无关、轻量易部署,时序预测新思路! - 详解
本篇论文来自IJCAI2025,最新前沿时序技术,针对时序预测提出了一个新策略-Socket+Plug(SoP)策略,它是一种模型无关的非集体校准策略,通过非集体校准缓解 MTLC 问题,无需从零训练新模型即可显著提升时间序列(含时空)预测性能,且兼具轻量化、模型无关、易部署的优势。
了解顶会最新技术,紧跟科研潮流,研究与写作才能保持在时代一线,全部49篇IJCAI2025前沿时序合集小时已经整理好了,在功浩“时序大模型”发送“资料”扫码回复“IJCAI2025时序合集”即可自取~其他顶会时序合集也可以回复相关顶会名称自取哈~(AAAI25,ICLR25,ICML25等)
文章信息
论文名称:Non-collectiveCalibratingStrategyforTimeSeriesForecasting
论文作者:BinWang、YongqiHan、MinboMa、TianruiLi、JunboZhang、FengHong、YanweiYu

研究背景
在时间序列预测中,时间序列数据存在季节性波动、趋势变化和领域特异性模式等繁琐动态特征,导致难以确定 “黄金模型架构”。尽管 CNN、RNN、GNN、Transformer 等深度学习模型不断发展,但模型性能争议持续(如简单 MLP 可能优于复杂 Transformer),且新 SOTA 模型层出不穷,企业在生产环境中测试新模型需大量试错,成本高昂。
现有的校准技巧存在局限,传统 “集体校准”策略会同时优化所有目标变量和预测步长,引发多目标学习冲突—— 不同目标的可学习性差异导致早期停止机制过早触发,模型学习能力未被充分利用,甚至性能退化。
因此文章提出了Socket+Plug(SoP)策略以解决上述问题。

模型框架
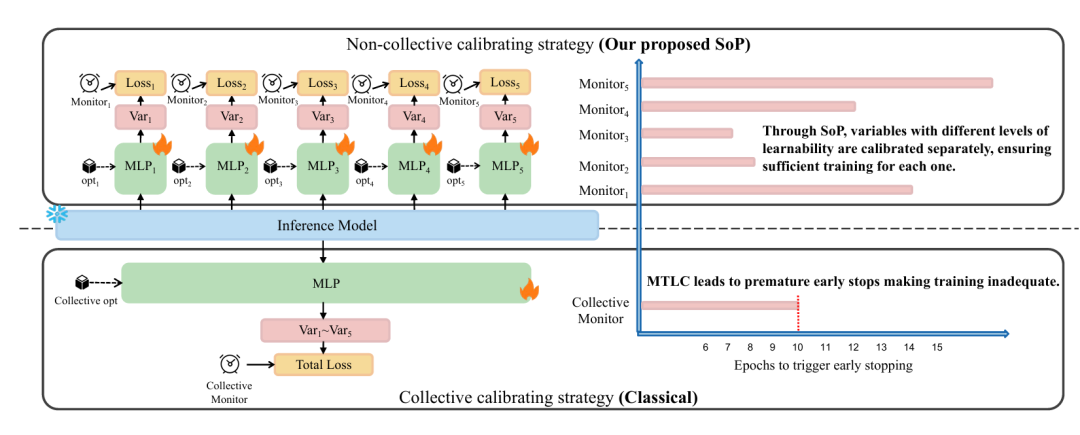
Socket+Plug(SoP)策略,是一种模型无关的非集体校准策略,无需从零训练新模型,而是通过 “Socket(基座)+Plug(校准模块)” 结构优化已训练模型的预测性能,核心是为每个预测目标分配专属优化器和早期停止监视器,缓解 MTLC 问题。
Socket:冻结的已训练 SOTA 预测模型(如 iTransformer、DLinear、Unet 等),负责捕捉变量间复杂关联,供应基础预测结果。
Plug:轻量级校准模块(如 MLP),针对 Socket 的预测结果进行校准。每个 Plug 对应特定目标(变量或时间步长),配备独立优化器和早期停止监视器,避免目标间优化冲突。
关键定义
集体校准:冻结推理模型,对所有目标变量和预测步长的模型层进行集体重训练,对应 SoP 中 “Plug 数量 = 1” 的特殊情况
非集体校准:对分组或单个变量 / 预测步长单独校准,SoP 属于此类
具体形式
变量级 SoP(variable-wise SoP):每个变量对应 1 个 Plug,Plug 数量 = 变量数(N),无需调试 Plug 数量,可作为 “快速启动版本”
步长级 SoP(step-wise SoP):每个预测步长对应 1 个 Plug,Plug 数量 = 预测步长数(S),同样无需调试 Plug 数量,为 “迅速启动版本”
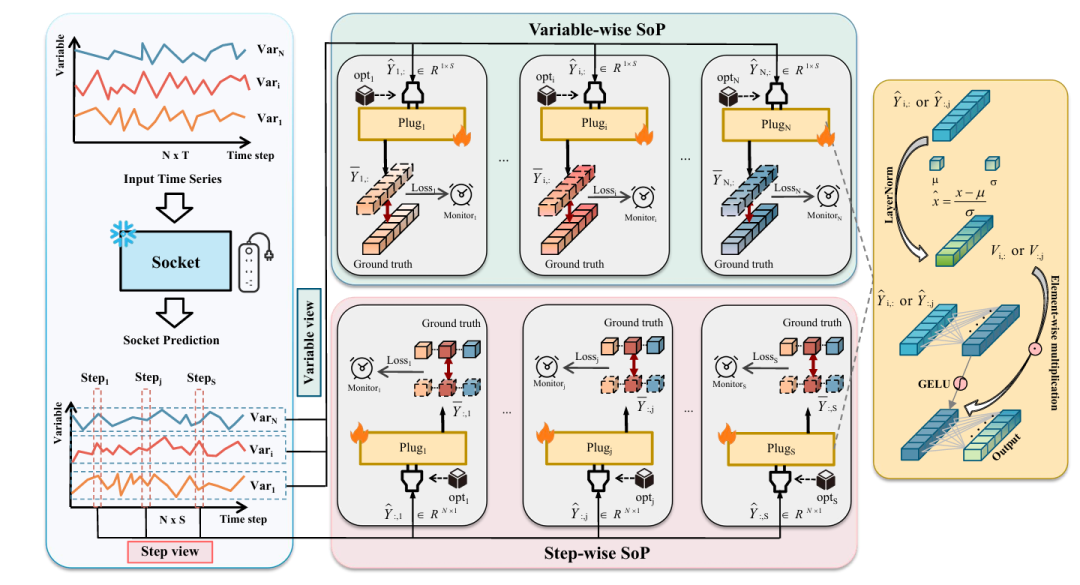
模型流程
推理阶段:输入时间序列数据,Socket 输出基础预测
校准准备:按变量 / 步长拆分,对每个子序列做层归一化(LayerNorm)以稳定训练
Plug 校准:每个 Plug 对对应子序列进行校准(如 MLP 映射 + 元素乘法)
结果整合:拼接所有 Plug 的输出,得到最终预测
实验数据
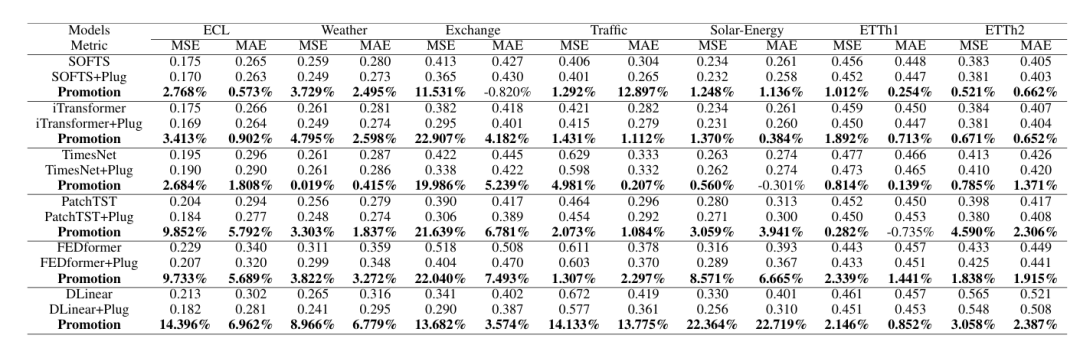
数据集:7 个时间序列基准数据集(ETTh1/ETTh2、ECL、Exchange、Weather、Solar-Energy、Traffic)+1 个时空气象数据集(ERA5,含 T2M、U10 等 5 个气象变量);
Socket 模型:覆盖 7 类 SOTA 模型,包括 Transformer 类(FEDformer、PatchTST、iTransformer)、MLP 类(DLinear、TSMixer、SOFTS)、TCN 类(TimesNet),以及时空任务的 Unet;
评价指标:均方误差(MSE)、平均绝对误差(MAE)。
主要实验结果
(1)SoP 对模型性能的提升(RQ1)
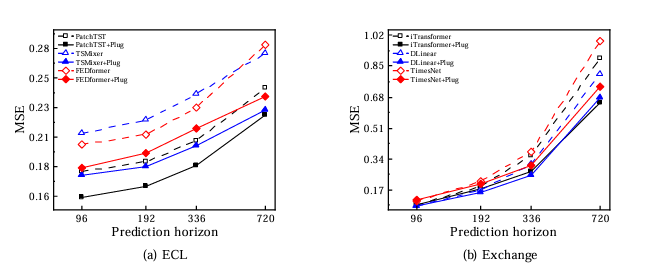
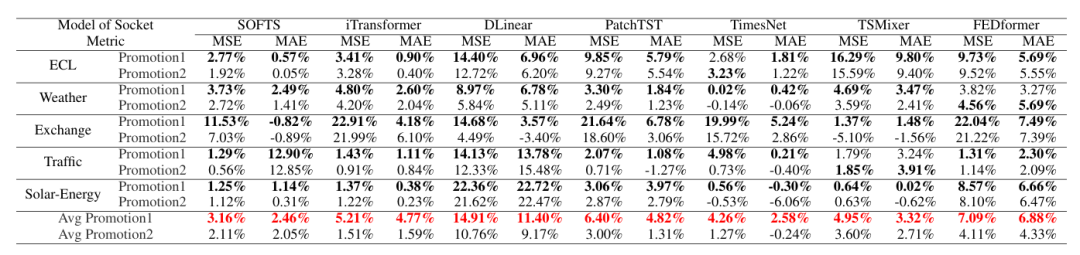
所有 Socket 模型结合 SoP 后性能均有改善,在 Exchange 数据集(低变量相关性)上提升最显著:iTransformer+Plug 的 MSE 降低 22.91%,FEDformer+Plug 降低 22.04%;
简便模型受益更明显:DLinear+Plug 在 ECL 数据集 MSE 降低 14.40%,在 Solar-Energy 数据集降低 22.72%,甚至超过 TimesNet+Plug 等繁琐模型;
长预测步长优势更突出:随预测步长(S=96→720)增加,SoP 的 MSE 降低幅度扩大(如 ECL 数据集,步长 720 时提升差异比步长 96 时更显著)。
(2)目标级 SoP 的有效性(RQ2)
变量级与步长级SoP 性能接近,且均无需调试 Plug 数量,可作为 “快速启动版本”;
非集体校准(Plug 数量 > 1)显著优于集体校准(Plug 数量 = 1):Weather 资料集上,集体校准的 MSE 甚至高于未校准模型,验证 MTLC 的负面影响。
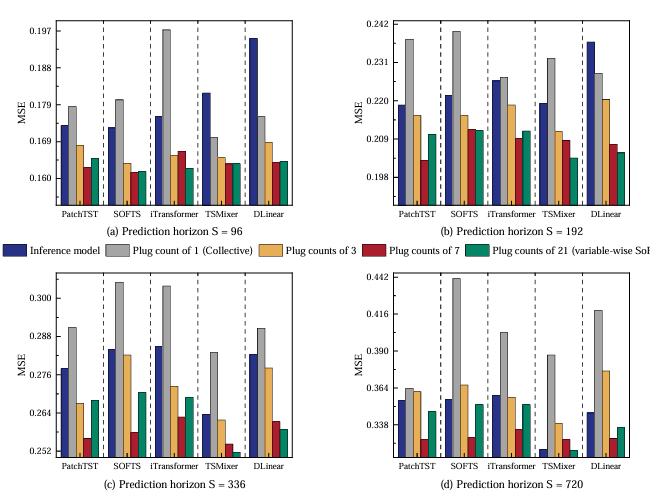
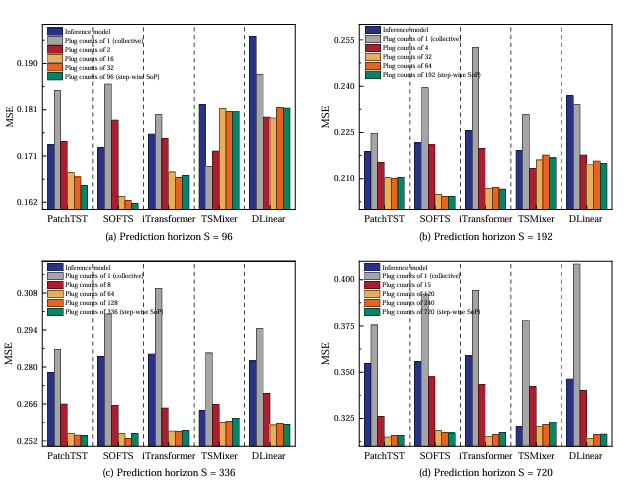
(3)非集体 vs 集体优化器(RQ3)
非集体优化器集体优化器(共享 1 个优化器)的 2 倍;就是(每个 Plug 独立优化)的平均性能提升
集体优化器可能导致性能退化(如 TSMixer 在 Exchange 材料集),而非集体优化器可避免此问题,且各 Plug 收敛速度差异符合 “不同目标可学习性不同” 的假设。
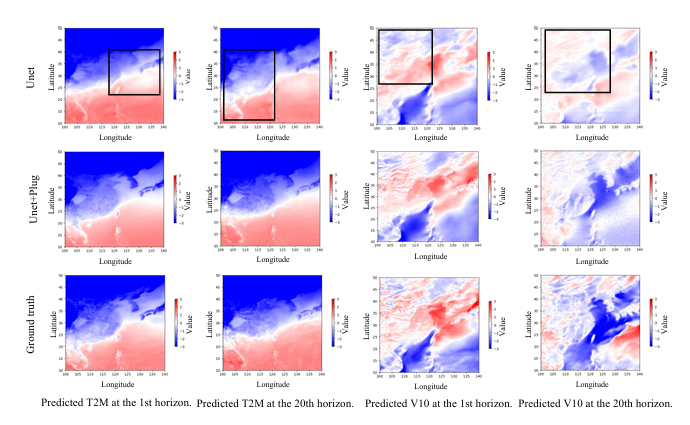
(4)时空预测任务的拓展(RQ4)
ERA5 气象数据集上,Unet+SoP 使 5 个气象变量的 MSE 显著降低(T2M、U10、V10 提升最明显);
可视化结果显示:Unet+SoP 的预测更接近真实值,避免了 Unet 单独预测时的 “过度平滑” 挑战,且在短 / 长预测步长(S=1→20)均实用。
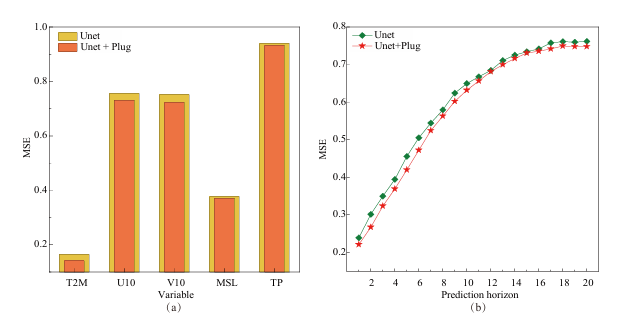
(5)与 LLM 方法的对比
轻量化替代方案。就是iTransformer+SoP 在 Traffic、Weather 材料集上的 MSE/MAE 优于 CALF、TimeLLM、GPT4TS 等 LLM 方法,且无需麻烦架构修改和高额训练 / 推理成本,
小小总结
文章首次识别 MTLC 问题,明确多目标学习冲突对时间序列预测模型的负面影响,指出传统早期停止机制的缺陷。
SoP策略通过非集体校准缓解 MTLC 问题,无需从零训练新模型即可显著提升时间序列(含时空)预测性能,且兼具轻量化、模型无关、易部署的优势。可以降低企业模型迭代成本,训练好的 Plug 可跨 Socket 迁移。
2025顶会前沿时序合集,攻豪关注“时序大模型”,回复“资料”即可自取~

关注小时,持续学习前沿时序技术!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号