面试总结
数据库
1 mysql中引擎有哪些,以及区别
主流的是InnoDB Myisam Memory
InnoDB跟Myisam的默认索引是B+tree,Memory的默认索引是hash
区别:
1.InnoDB支持事务,支持外键,支持行锁,写入数据时操作快,MySQL5.6版本以上才支持全文索引
2.Myisam不支持事务。不支持外键,支持表锁,支持全文索引,读取数据快
3.Memory所有的数据都保留在内存中,不需要进行磁盘的IO所以读取的速度很快, 、
但是一旦关机的话表的结构会保留但是数据就会丢失,表支持Hash索引,因此查找速度很快
2 mysql中事务隔离级别
InnoDB的四个事务级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
| https://www.cnblogs.com/wyaokai/p/10921323.html |
3 mysql中索引的数据类型
B+树的类型,与B树的数据类型有什么区别 https://blog.csdn.net/weixin_42265148/article/details/104711128
B+树的数据结构
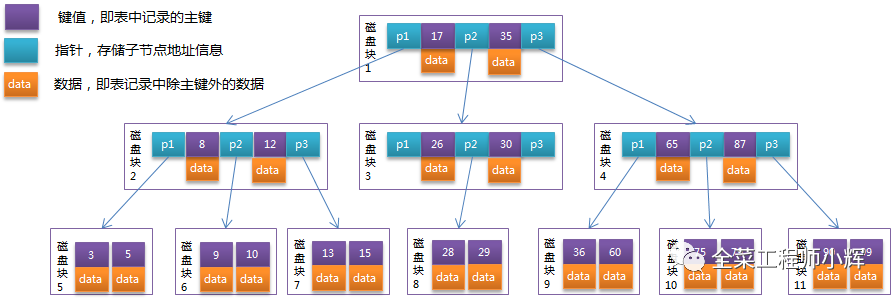
4 mysql中Myisam的非聚簇索引和InnoDB聚簇索引什么区别
Myisam存储为三个文件.frm、.MYD、.MYI
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
.frm:表的定义,就是描述表结构的文件
.MYD:数据存储文件
.MYI:索引存储文件
意思就是索引文件和数据是分来的
INNODB聚集索引存储的是一个文件,后缀为.frm
InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
意思就是索引和数据是是在同一个文件里的
python基础
1 python深浅拷贝有什么区别
1.1 python的浅拷贝只能复制元素外层的数据,内层不复制
举例
import copy
listb = [a , b , [c, b]]
lista = copy.copy(b) #对象拷贝,浅拷贝
listb[2].append[e]
print(lista)
获取到的lista 数据是[a , b , [c, b,e]]
原因就是元素的内部数据浅克隆不会复制,如果元素里面嵌套了可变数据比如列表[c,b],listb中对列表添加和修改,lista也会随着变
如果是深克隆的话
import copy
listb = [a , b , [c, b]]
lista = deep.copy(b) #对象拷贝,深拷贝
listb[2].append[e]
print(lista)
获取到的lista 数据是[a , b , [c, b,]]
原因就是深克隆拷贝过来的元素完全是属于自己的,不会因为父类中内部可变元素list变化而变化,如果元素里面嵌套了可变数据比如列表[c,b],listb中对列表添加和修改,lista不会改变
1.2 list中append和extend是什么区别
lis.append(a)添加的是a这个整体;
例如:
list1=[1,3,4,5]
a=(1,2)
list1.append(a)
print(list1)
结果:[1,3,4,5,(1,2)]
而 lis.extend(a) 会把a中的各个元素分开, a中的内容不再是一个整体
例如:
list1=[1,3,4,5]
a=(1,2)
list1.extend(a)
print(list1)
结果:[1,3,4,5,1,2]
1.3 list和dict实现的内部结构,为什么处理数据会快
百度
1.4 什么是闭包
print_msg是外围函数
def print_msg():
msg = "I'm closure"
# printer是嵌套函数
def printer():
print(msg)
return printer
这里获得的就是一个闭包
closure = print_msg()
输出 I'm closure
closure()
msg是一个局部变量,在print_msg函数执行之后应该就不会存在了。但是嵌套函数引用了这个变量,将这个局部变量封闭在了嵌套函数中,这样就形成了一个闭包。
在函数式语言中,当内嵌函数体内引用到体外的变量时,将会把定义时涉及到的引用环境和函数体打包成一个整体(闭包)返回。
https://www.cnblogs.com/baxianhua/p/10761546.html
1.5 什么是装饰器
https://www.jianshu.com/p/ee82b941772a
1.6生成器和迭代器的区别
迭代器是一个更抽象的概念,任何对象,如果它的类有 next 方法和 iter 方法返回自己本身,对于 string、list、
dict、tuple 等这类容器对象,使用 for 循环遍历是很方便的。在后台 for 语句对容器对象调用 iter()函数,iter()
是 python 的内置函数。iter()会返回一个定义了 next()方法的迭代器对象,它在容器中逐个访问容器内元素,next()
也是 python 的内置函数。在没有后续元素时,next()会抛出一个 StopIteration 异常。
生成器(Generator)是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数
据的时候使用 yield 语句。每次 next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置
和所有的数据值)
区别:生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁,而且
生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当
发生器终结时,还会自动抛出 StopIteration 异常。
1.6 自定义异常
1.7 python上下文管理器
即含有__enter__和__exit__方法的对象就是上下文管理器。
https://www.cnblogs.com/huchong/p/8268765.html
1.8 类对象中init和new区别
1.8 类中抽象类是什么, 类方法和静态方法
1.9 单例实现
就是实例化出来的对象id都一样
class MusicPlayer(object):
# 定义类属性记录单例对象引用
instance = None
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否已经被赋值
if cls.instance is None:
cls.instance = super().__new__(cls)
# 2. 返回类属性的单例引用
return cls.instance
https://blog.csdn.net/qq_26442553/article/details/94393191
1.10 类中的鸭子函数
1.11 python的内存管理机制
引用计数,标记清除,分代回收
具体百度
1.12 repr和str有什么区别
linux命令
查看磁盘df 查看文件du ,查看内存top或free,进程ps, 端口netstat,远程拷贝scp等
git的使用
5 关系型和非关系型数据库区别
百度
6 非关系数据库redis
django框架和flask框架
1. django和flask框架区别
2,django 中间件实现,跨域实现
3 ,django setting有哪些配置
4 , django restframework的使用
5 用户请求到django到django返回数据流程
6 django中MVC解释
10 celery使用
7 falsk 上下文管理
8 cookie和seesion区别,jwt实现
9 简述restful风格
网络编程
http和https区别
http1.0和http1.1区别
tcp和utp区别
简述tcp三次握手和四次挥手
此视频很详细 https://www.bilibili.com/video/BV1at4y1Q77b?t=220
爬虫
scrapy流程
正则表达式
docker使用
元组和列表区别
元组不可以变,list可变
Python中is和==的区别
https://juejin.cn/post/6844903538737299464
sorted()和sort区别
sort()与sorted()的不同在于,sort是在原位重新排列列表,而sorted()是产生一个新的列表。
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号