

5.线性回归算法
1.本节重点知识点用自己的话总结出来,可以配上图片,以及说明该知识点的重要。
答:机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签,最重要的内容线性回归模型,把线性回归问题转化为矩阵乘积的问题,矩阵在线性回归中扮演者非常重要的作用。矩阵:大多数算法的计算基础,矩阵的这种运算正好满足了线性回归的这种需求。掌握数组的加法运算和乘法运算还有矩阵的乘法,机器学习和预测值是存在一定误差的,需要使用迭代算法来减小误差,因此引入了损失函数。

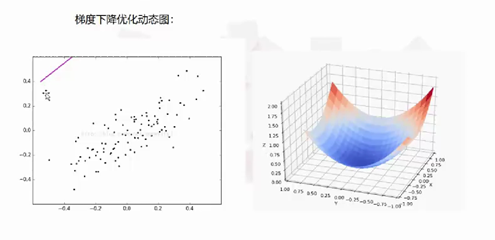

2.思考线性回归算法可以用来做什么?(大家尽量不要写重复)
答:对大量的观测数据进行处理,从而得到比较符合事物内部规律的数学表达式。也就是说寻找到数据与数据之间的规律所在,从而就可以模拟出结果,也就是对结果进行预测。解决的就是通过已知的数据得到未知的结果。例如:对房价的预测、判断信用评价、电影票房预估等。
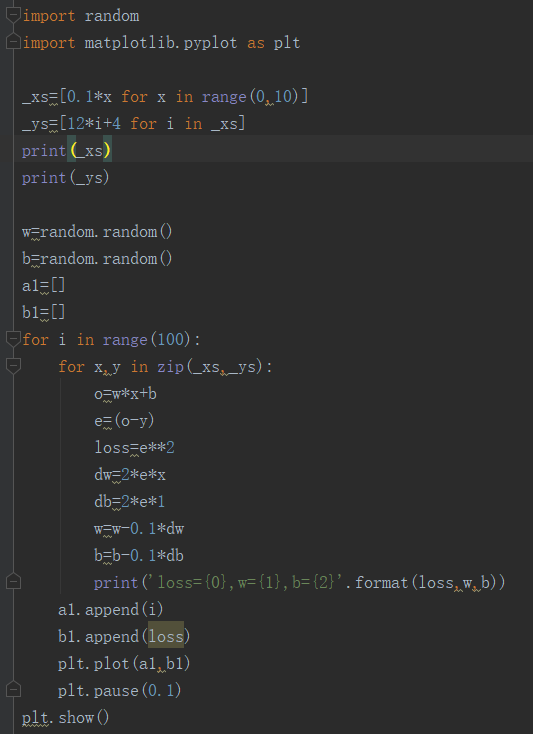
3.自主编写线性回归算法 ,数据可以自己造,或者从网上获取。(加分题)这里使用梯度下降法对计算回归参数,实现回归模型建立。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据格式:城市人口,食品经销商利润
# 读取数据
data = np.loadtxt('ex1data1.txt', delimiter=',')
data_X = data[:, 0]
data_y = data[:, 1]
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(data_X, data_y)
# 训练模型
model = LinearRegression()
model.fit(X_train.reshape([-1, 1]), y_train)
# 利用模型进行预测
y_predict = model.predict(X_test.reshape([-1, 1]))
# 结果可视化
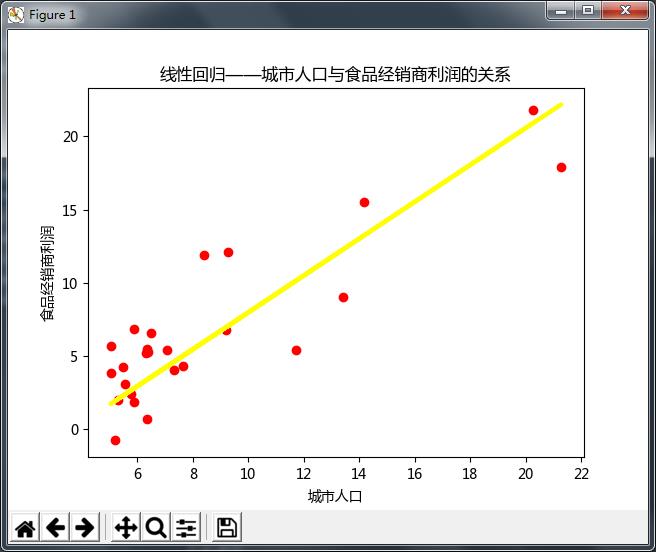
plt.scatter(X_test, y_test, color='red') # 测试样本
plt.plot(X_test, y_predict, color='yellow', linewidth=3)
plt.xlabel('城市人口')
plt.ylabel('食品经销商利润')
plt.title('线性回归——城市人口与食品经销商利润的关系')
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号