

xxl-job源码阅读二(服务端)
1、源码入口
xxl-job-admin是一个简单的springboot工程,简单翻看源码,可以很快发现XxlJobAdminConfig入口。
@Override
public void afterPropertiesSet() throws Exception {
adminConfig = this;
xxlJobScheduler = new XxlJobScheduler();
xxlJobScheduler.init();
}
我们就可以顺着这个XxlJobScheduler,分析下这个xxl-job-admin做了些什么。
2、初始化七大步
在XxlJobScheduler.init() 方法中,主要做了如下七件事情:
public void init() throws Exception {
// init i18n
initI18n();
// admin trigger pool start
JobTriggerPoolHelper.toStart();
// admin registry monitor run
JobRegistryHelper.getInstance().start();
// admin fail-monitor run
JobFailMonitorHelper.getInstance().start();
// admin lose-monitor run ( depend on JobTriggerPoolHelper )
JobCompleteHelper.getInstance().start();
// admin log report start
JobLogReportHelper.getInstance().start();
// start-schedule ( depend on JobTriggerPoolHelper )
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
按照代码的顺序,逐一看看这七步到底做了些什么。这里的7个方法分别对应下面的2.1 ~ 2.7小节
2.1、国际化
真正实现国际化的,可不是这个initI18n(),这个方法只是设置了几个title。真正实现国际化的实现是:
-
com.xxl.job.admin.core.util.I18nUtil 加载 国际化资源文件
这块实现充分利用spring的 EncodedResource和PropertiesLoaderUtils.loadProperties,嗯,利用好现有的轮子!
-
CookieInterceptor 把I18nUtil对象返回到ftl页面上去
-
在templates/common/common.macro.ftl中定义宏
<#global I18n = I18nUtil.getMultString()?eval /> var I18n = ${I18nUtil.getMultString()}; -
在ftl页面中使用,比如
<h1>${I18n.job_dashboard_name}</h1>
2.2、触发器
JobTriggerPoolHelper.toStart();里面启动了2个线程池,一快一慢。
默认情况下,会使用fastTriggerPool。如果1分钟窗口期内任务耗时达500ms超过10次,则该窗口期内判定为慢任务,慢任务自动降级进入”Slow”线程池,避免耗尽调度线程,提高系统稳定性;
这个JobTriggerPoolHelper里面有个很重要的方法,就是addTrigger
public void addTrigger(final int jobId,
final TriggerTypeEnum triggerType,
final int failRetryCount,
final String executorShardingParam,
final String executorParam,
final String addressList) {
// choose thread pool
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) { // job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
// trigger
triggerPool_.execute(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
try {
// do trigger
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
// check timeout-count-map
long minTim_now = System.currentTimeMillis()/60000;
if (minTim != minTim_now) {
minTim = minTim_now;
jobTimeoutCountMap.clear();
}
// incr timeout-count-map
long cost = System.currentTimeMillis()-start;
if (cost > 500) { // ob-timeout threshold 500ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) {
timeoutCount.incrementAndGet();
}
}
}
}
});
}
具体到真正触发执行的地方,就得看看XxlJobTrigger.trigger了。
XxlJobTrigger.trigger中,先查表看有哪些执行器(其实就是业务服务器,可以用来跑job的),如果配置的路由策略是分片,则组装好分片参数。
参数组装好之后,调用processTrigger方法,然后调到runExecutor去执行。
public static ReturnT<String> runExecutor(TriggerParam triggerParam, String address){
ReturnT<String> runResult = null;
try {
ExecutorBiz executorBiz = XxlJobScheduler.getExecutorBiz(address);
runResult = executorBiz.run(triggerParam);
} catch (Exception e) {
logger.error(">>>>>>>>>>> xxl-job trigger error, please check if the executor[{}] is running.", address, e);
runResult = new ReturnT<String>(ReturnT.FAIL_CODE, ThrowableUtil.toString(e));
}
StringBuffer runResultSB = new StringBuffer(I18nUtil.getString("jobconf_trigger_run") + ":");
runResultSB.append("<br>address:").append(address);
runResultSB.append("<br>code:").append(runResult.getCode());
runResultSB.append("<br>msg:").append(runResult.getMsg());
runResult.setMsg(runResultSB.toString());
return runResult;
}
这里首先利用执行器的地址,构造一个ExecutorBizClient对象,然后调用run方法。
public class ExecutorBizClient implements ExecutorBiz {
@Override
public ReturnT<String> run(TriggerParam triggerParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class);
}
}
前面在阅读xxl-job-core的代码的时候,就看到过,客户端基于netty创建了一个EmbedServer ,默认监听9999 端口,接收job-admin端发过来的任务处理命令。
这里的调用,就是调到客户端的执行,即触发客户端执行任务!
触发之后,客户端会立即有返回触发是否成功。真正任务执行是否成功,则是异步返回给admin端的。(可以回头看下 TriggerCallbackThread )
(调度触发 和 job执行是两码事,所以xxl_job_log表里面有trigger_code 和 handle_code,分别来存着两个动作的结果)
2.3、执行器维护
这里的执行器,其实就是业务服务器。很好理解,谁执行job,谁就是执行器。
接下来看看JobRegistryHelper.getInstance().start()。
- 开启一个线程池 registryOrRemoveThreadPool ,用来注册或者删除。对象对外提供registry和registryRemove方法
- 开启一个线程registryMonitorThread,每sleep 30秒(心跳时间) 移除失活业务服务器记录, 读取存活的xxl_job_registry信息,更新到 xxl_job_group 里面去 。 这个线程被设置为守护线程,通过改变变量标记toStop退出执行
- registry和registryRemove方法被进一步封装到 AdminBizImpl 中,供外部使用
2.4、失败处理器
任务调度执行的时候,会写xxl_job_log 记录。如果调度执行失败,需要重试或者发邮件通知。代码执行逻辑则是:
-
admin服务端启动一个 monitorThread线程,每隔10秒,扫描失败的记录
-
通过sql的cas的形式,逐条锁定失败的日志记录来处理
UPDATE xxl_job_log SET `alarm_status` = #{newAlarmStatus} WHERE `id`= #{logId} AND `alarm_status` = #{oldAlarmStatus} -
如果配置的重试次数大于0,则先重试
JobTriggerPoolHelper.trigger(log.getJobId(), TriggerTypeEnum.RETRY, (log.getExecutorFailRetryCount()-1), /*重试次数 -1 */ log.getExecutorShardingParam(), log.getExecutorParam(), null); -
如果配置了email,则发邮件告警
-
处理完之后,再通过sql的case更新 alarm_status
2.5、 job完成后续处理
如果job正常执行,那admin端只需要正常等着,接收client端的执行结果报告就行了。但是如果执行了好久没返回呢?所以在JobCompleteHelper里面做了这么几件事:
-
构造一个 callbackThreadPool 线程池,主要用来更新 xxl_job_log 记录 的执行结果
-
构造一个 monitorThread 线程,处理执行超时的。
找到【调度记录停留在 "运行中" 状态超过10min,且对应执行器心跳注册失败不在线,则将本地调度主动标记失败;】
-
更新job_log状态结果
2.6、定期清理日志
JobLogReportHelper里面做的事情主要就3点:
- 启动logrThread守护线程,定时扫描xxl_job_log 表
- 统计执行成功失败的数据,这个其实也是admin里面 执行报表数据的来源
- 根据配置,清理久远的xxl_job_log历史日志
2.7、 调度
调度中心的调度逻辑,最源头在这里--- JobScheduleHelper。这个类里主要做了如下几件事情:
-
启动scheduleThread
-
通过执行sql,获取数据库锁 (分布式锁),通过这种方式避免多个admin端重复调度
select * from xxl_job_lock where lock_name = 'schedule_lock' for update -
根据线程算力,计算出preReadCount,从xxl_job_info 表中找出 未来5秒内要执行的job,暂存 scheduleList
- 超时未调度(超过调度时间5秒)的任务,本次忽略,基于当前时间计算下次执行时间。
- 超过调度时间但未超时(超过5秒之内)的任务,立即放入执行线程池触发一次,再修改执行时间,接着判断下次执行时间若在5秒之内,加入timewheel的map后再次修改下次执行时间。
- 调度时间在未来5秒之内的(预读5s),基于timewheel时间轮(map<秒数,list<任务实体>>),根据5秒内即将执行的任务的执行时间的秒数,将其放到timeheel对应秒数的list中,修改下次执行时间。
-
启动ringThread ,处理timeRing里面的job
至此,除开某些细节,代码层面上基本差不多了。
3、总结
看完客户端+服务端的代码,现在来回顾小节一下。
3.1、 一次完整的任务调度通讯流程
- “调度中心”向“执行器”发送http调度请求: “执行器”中接收请求的服务,实际上是一台内嵌Server,默认端口9999;
- “执行器”执行任务逻辑;
- “执行器”http回调“调度中心”调度结果: “调度中心”中接收回调的服务,是针对执行器开放一套API服务;
3.2、 整体架构图
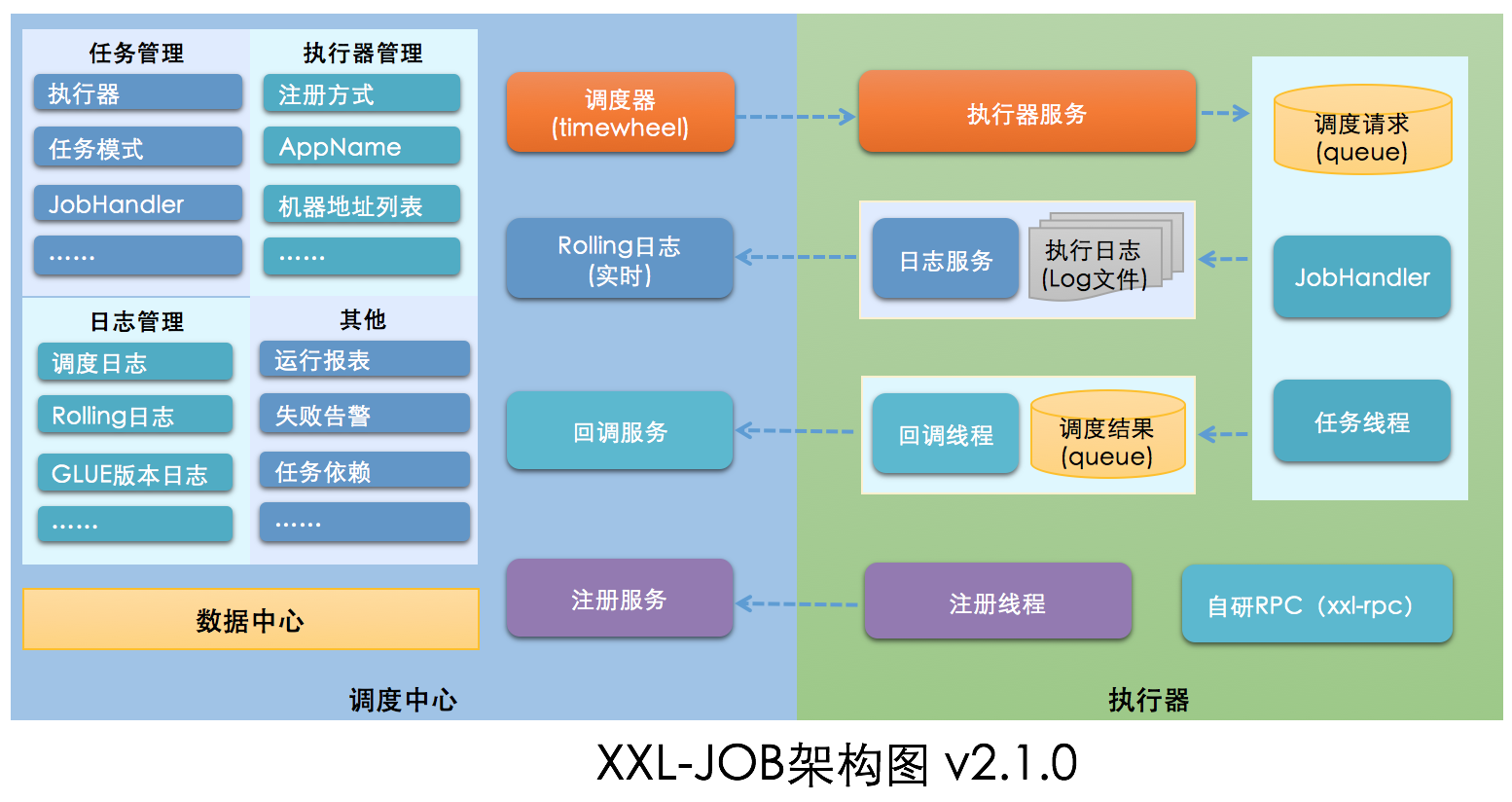
3.3、 xxl-job的优点
优点真的很明显:简单、轻量级、易扩展。
框架确实非常清晰、简单。代码写的也很有启发性。比如:
- 充分利用Spring现有的工具类,不重复造轮子
- 使用ThreadPoolExecutor的有参构造方法去创建线程池(阿里巴巴的开发手册里面貌似特意提到这一点)
- 尽量定义枚举类型,比如ExecutorRouteStrategyEnum(这里又将枚举和路由策略结合在一起,算是策略模式的一个变种吧)
- 遵循迪米特法则。比如说:XxlJobAdminConfig中,所有dao都通过这里注入、对外提供。不零散分布在各个类中
- .....
3.3、 xxl-job的建议
目前xxl-job只分了2个子模块:admin和core,admin依赖core
个人觉得再多分出一个模块,结构会更好一些【admin,core,common】,依赖关系改成这样子:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号