Pytorch神经网络实例分析总结
Pytorch神经网络基本结构
-
导入数据Dateset,自建的数据或者下载网上的数据如MNIST/CIFAR-10,将数据转换成Tensor类型,归一化处理
-
数据划分DataLoader,将数据分成多个Batch进行训练和测试
-
构建网络,定义网络层级和forward函数
-
实例化网络模型,添加优化方法和损失函数
-
训练网络,加载数据,调用模型进行预测,计算损失函数,梯度清零,反向传播,梯度更新
加载各种依赖包
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms导入数据,以MNIST为例
# 下载数据集
train_set = datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
]))- 第一个参数‘../data’为下载的数据集保存路径,此处为当前Python文件上一级路径下的data文件夹,如果想保存到当前路径下,可以修改为‘./data’。
- 第二个参数train=True表示训练数据,即从MNIST中获取训练用的数据,如果改成False,则获取测试用数据。
- 第三个参数download=True表示允许从网上下载数据集,如果已经下载过,并存放到第一个参数指定的路径下,则可以修改成download=False。
- 第四个参数transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1037,), (0.3081,))])表示将数据集转换成tensor类型,并以0.1037为均值,0.3081为标准差进行归一化。其中Compose函数为一个指令集,表示按照其中的顺序执行Tosensor和Normalize。如果有需要,也可以加入其他的transforms指令。
在进行测试的时候,需要导入测试数据集如下
test_set = datasets.MNIST('../data', train=False, download=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
]))数据划分
train_data = DataLoader(train_set, batch_size=128, shuffle=True)- 第一个参数train_set为数据集,即导入的MNIST训练数据集。
- 第二个参数batch_size=128为将数据集中每128个数据划分为一组进行训练。假设数据集总共有1024个数据,则将数据分为8组,每组128个。
- 第三个参数shuffle=True为将数据打乱,即每组数据训练完之后,将剩余数据打乱。如果shuffle=False,则不打乱数据。
同样,在进行测试时,也可以对测试数据集进行划分
test_data = DataLoader(test_set, batch_size=128, shuffle=False)构建网络
# 构建网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(3136, 7*7*64),
nn.Linear(3136, 10),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x继承nn.Model类构建网络CNN,定义__init__函数和forward函数,这两个函数是必须的。
__init__函数是构造函数,在实例化CNN类的时候会自动执行。第一行是必须的,用于对父类进行初始化。
super(CNN, self).__init__()在Python 3.x中,可以省略 super() 中的参数,因为它们会自动检测当前类和实例。如下
super().__init__()详细解释可以参考:super(NeuralNetwork, self).__init__() 与 super().__init__()_拟 禾的博客-CSDN博客
self.features=nn.Sequential()定义了一块网络层features,其中包含共4层网络,为2层卷积层和2层池化层。类似前文中的transforms.Compose()函数。
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2),
)nn.Conv2d()函数定义了第一个2维卷积层,主要用于处理二维图像,5个参数分别为输入通道数,输出通道数,卷积核大小,步进,边缘补偿。官方文档链接
nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2)其中卷积核的大小为5,表示一个5*5的卷积核,步进为1,表示每次移动一格,边缘补偿为2,表示在图像周围一圈加上2格数据,默认为0。
如下图所示,输入通道为2,输出通道为3,卷积核为2,步进为1,边缘补偿为0。即
nn.Conv2d(2, 3, kernel_size=2, stride=1, padding=0)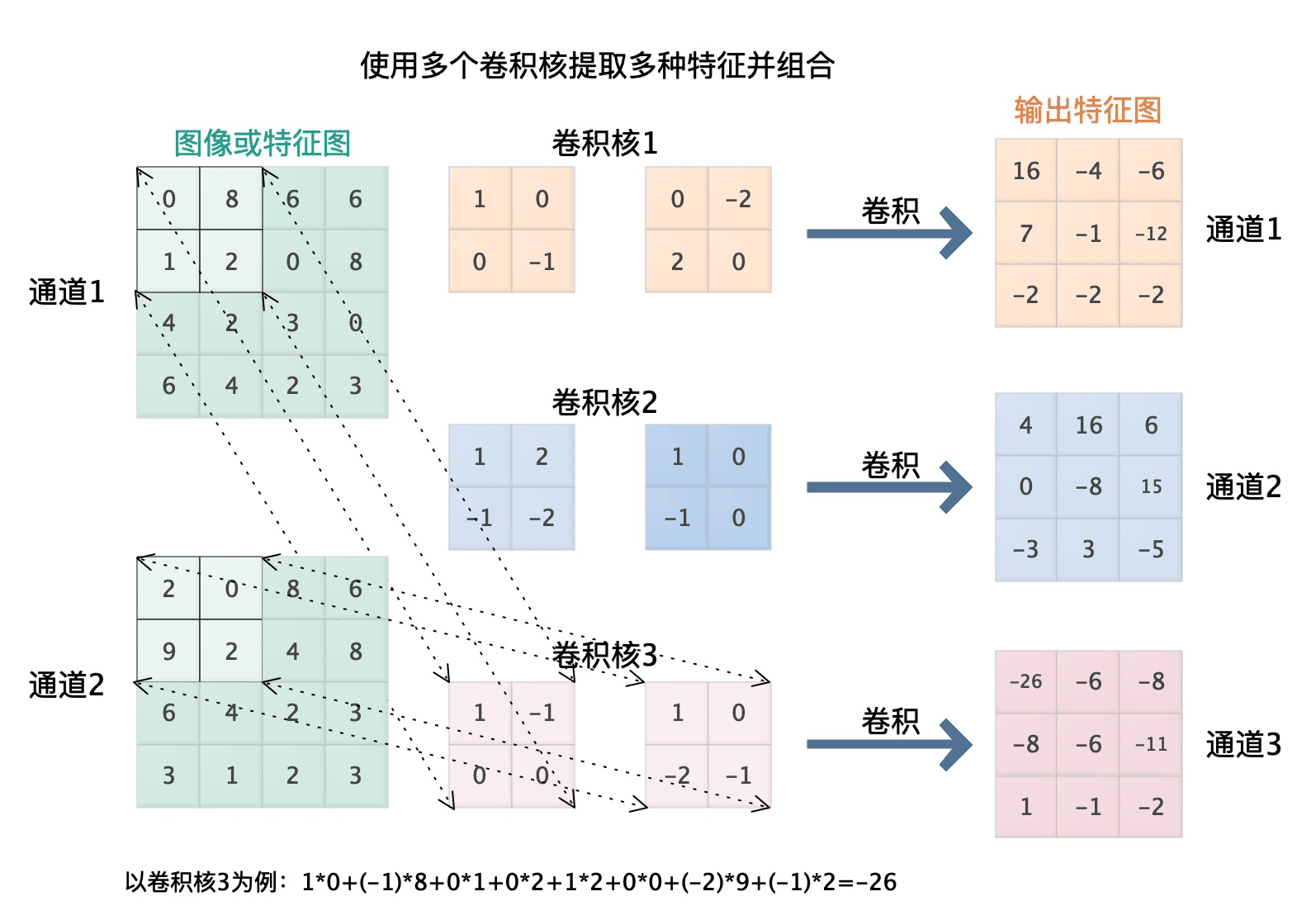
nn.Maxpool2d()函数定义了一个二维最大池化层,用于缩小数据大小,同时保留数据特征。2个参数分别为池化核大小,步进。官方文档链接
nn.MaxPool2d(kernel_size=2, stride=2)其中,池化核大小为2,表示一个2*2的池化核。步进为2,表示每次移动2格,默认步进等于池化核大小。
如下图所示,池化核大小为2,步进为2,4*4的数据池化后得到一个2*2的数据。下图展示了三种不同的池化方法。
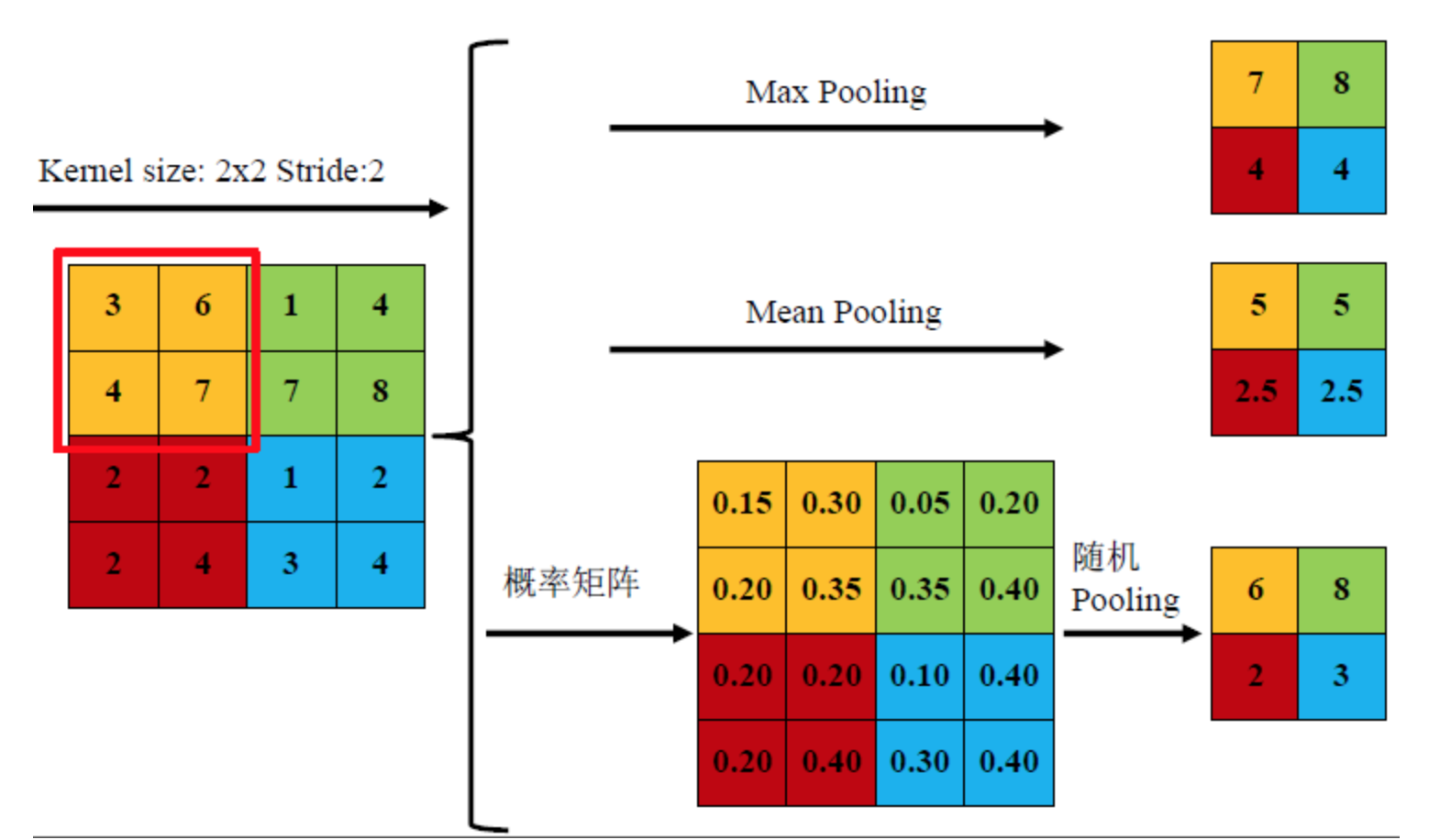
self.classifier=nn.Sequential()定义了另一块网络层,其中包含2层线性层网络。
self.classifier = nn.Sequential(
nn.Linear(3136, 7*7*64),
nn.Linear(3136, 10),
)nn.Linear()函数定义了两个线性层(全连接层)。其两个参数分别为输入样本数,输出样本数。官方文档链接
nn.Linear(3136, 7*7*64)其中,输入样本数为3136,表示输入3136个数据,输出样本数为7*7*64=3136,表示输出3136个数据。
如下图所示,输入样本数为n,输出样本数为s。即
nn.Linear(n, s)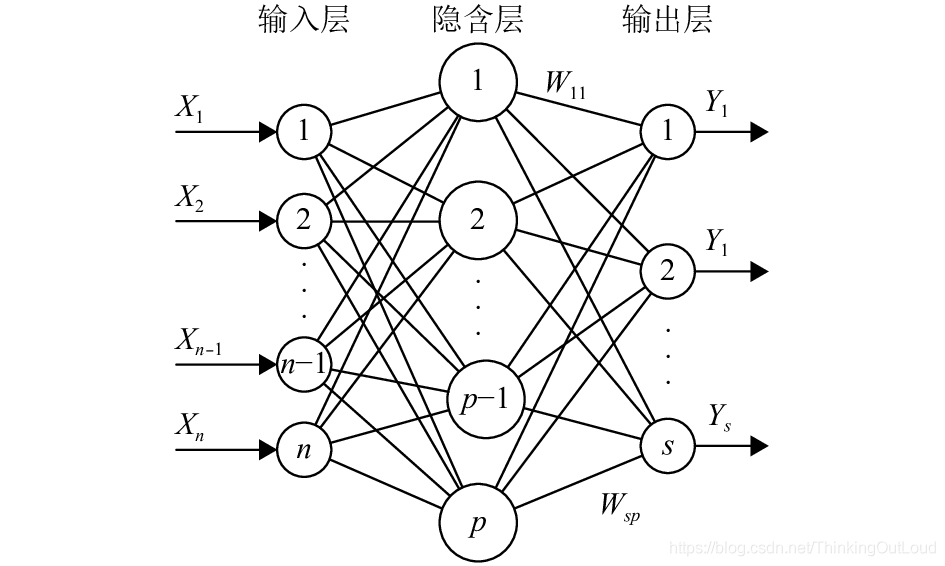
forward函数是前向传播函数,网络接收的输入input会经过forward函数处理后得到输出output。函数有一个参数input,用于接收网络输入。
def forward(self, input):
x = self.features(input)
x = torch.flatten(x, 1)
output = self.classifier(x)
return output网络输入input会调用feature方法进行卷积和池化处理,得到的结果存入x,x调用flatten函数对数据进行展平,变成一维数据。本文中,输入图像为128*1*28*28,即每组数据有128张图片,每张图片1个通道,28*28像素。
经过第一层卷积后,变为32*28*28,经过池化层后,变为32*14*14,
经过第二层卷积后,变为64*14*14,经过池化层后,变为64*7*7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号