


顺序查找(Sequential Search)
1、定义
顺序查找又叫线性查找,是最基本的查找技术。
2、基本思想
从表的一端开始(第一个或最后一个记录),顺序扫描线性表,依次将扫描到的结点关键宇和给定值K相比较。若当前扫描到的结点关键字与K相等,则查找成功;若扫描结束后,仍未找到关键字等于K的结点,则查找失败。
3、存储结构
顺序查找方法既适用于线性表的顺序存储结构,也适用于线性表的链式存储结构(使用单链表作存储结构时,扫描必须从第一个结点开始)。
注意:单链表为什么从第一个扫描,而不是最后一个,这与其存储结构有关,单链表名字即表示第一个第一个结点的地址,而不是最后一个结点的地址。
4、顺序查找算法
(1)类型说明
typedef struct{
KeyType key;
InfoType otherinfo; //此类型依赖于应用
}NodeType;
typedef NodeType SeqList[n+1]; //0号单元用作哨兵

(2)具体算法
/*顺序查找,参数说明:
a——数组;
n——要查找的数组个数;
key——要查找的关键字
*/
int SeqSearch(int *a,int n,int key)
//这里是指针引用
{
int i;
for(i=1;i<=n;i++){
//缺陷:每次循环都需要对i是否越界,即是否小于等于n做判断
if(a[i]=key)
return i;
}
return 0;
}
上述操作中,每次循环都需要对i是否越界,即是否小于等于n做判断,我们可以设置一个哨兵,不需要每次i与n作比较,改进方案如下:
/*有哨兵的顺序查找*/
int SeqSearch(int *a,int n,int key)
//这里是指针引用
{
int i;
a[0]=key;
/*设置a[0]为关键字值,我们称之为“哨兵”,当然也可以设置最后一个元素为“哨兵”*/
int n;
/*循环从数组尾部开始*/
while(a[i]!=key)
{
i--;
}
return i;
/*返回0说明查找失败*/
}
当然参数也可以如下设置,把元素个数放在数据结构体中定义:
int SeqSearch(Seqlist R,KeyType K)
{
//在顺序表R[1..n]中顺序查找关键字为K的结点,
//成功时返回找到的结点位置,失败时返回0
int i;
R[0].key=K;
//设置哨兵
for(i=n;R[i].key!=K;i--);
//从表后往前找
return i;
//若i为0,表示查找失败,否则R[i]是要找的结点
}
3、算法分析
① 算法中监视哨R[0]的作用
为了在for循环中省去判定防止下标越界的条件i≥1,从而节省比较的时间。
② 成功时的顺序查找的平均查找长度:
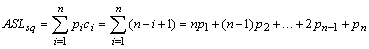
在等概率情况下,pi=1/n(1≤i≤n),故成功的平均查找长度为
(n+…+2+1)/n=(n+1)/2
即查找成功时的平均比较次数约为表长的一半。
若K值不在表中,则须进行n+1次比较之后才能确定查找失败。
③ 表中各结点的查找概率并不相等的ASL
【例】在由全校学生的病历档案组成的线性表中,体弱多病同学的病历的查找概率必然高于健康同学的病历,由于上式的ASLsq在pn≥pn-1≥…≥p2≥p1时达到最小值。
若事先知道表中各结点的查找概率不相等和它们的分布情况,则应将表中结点按查找概率由小到大地存放,以便提高顺序查找的效率。
为了提高查找效率,对算法SeqSearch做如下修改:每当查找成功,就将找到的结点和其后继(若存在)结点交换。这样,使得查找概率大的结点在查找过程中不断往后移,便于在以后的查找中减少比较次数。
④ 顺序查找的优点
算法简单,且对表的结构无任何要求,无论是用向量还是用链表来存放结点,也无论结点之间是否按关键字有序,它都同样适用。
⑤ 顺序查找的缺点
查找效率低,因此,当n较大时不宜采用顺序查找。
⑥ 适用情况
对那些查找少而又经常需要改动的线性表,可采用链表作存储结构,进行顺序查找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号