

05. scrapy框架使用
scrapy框架使用
1. scrapy安装
- windows、linux、mac : pip install scrapy
- 测试:cmd中scrapy按下回车,如果没有报错说明安装成功。
2. scrapy的基本使用
-
1.创建一个工程:
- scrapy startproject ProName(项目名)
- 目录结构:
- spiders:爬虫文件夹
- 必须要存放一个爬虫源文件
- settings.py:工程的配置文件
- spiders:爬虫文件夹
-
2.cd ProName(进入项目)
-
3.创建爬虫源文件:
- scrapy genspider spiderName www.xxx.com
- 编写对应的代码在爬虫文件中
-
4.执行工程
- scrapy crawl spiderName
- 执行工程后,默认会输出工程所有的日志信息。
- 指定类型日志的输出:
- settings.py:
- LOG_LEVEL = 'ERROR'
- settings.py:
-
5.配置settings.py:
- 1.禁止robots
- ROBOTSTXT_OBEY = 'False'
- 2.指定日志类型
- LOG_LEVEL = 'ERROR'
- 3.UA伪装
- USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
- 1.禁止robots

3. 数据解析
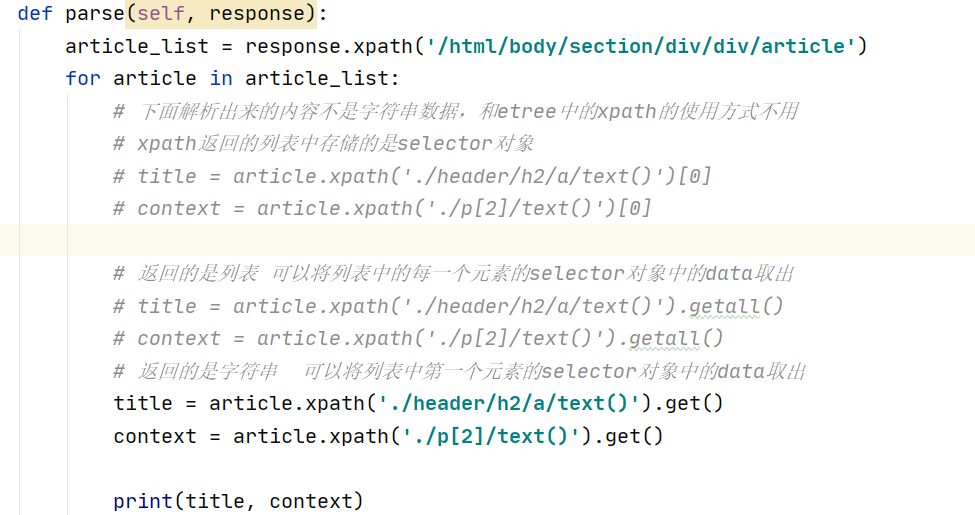
- 使用:response.xpath('xpath表达式')
- scrapy封装的xpath和etree中的xpath区别:
- scrapy中的xpath直接将定位到的标签中存储的值或者属性值取出,返回的是Selector对象,且相关
的数据值是存储在Selector对象的data属性中,需要调用get(), getall()取出字符串数据 ![数据解析]()
- scrapy中的xpath直接将定位到的标签中存储的值或者属性值取出,返回的是Selector对象,且相关
- scrapy封装的xpath和etree中的xpath区别:
4. 持久化存储
4.1 基于终端命令的持久化存储
- 要求:该种方式只可以将parse方法的返回值存储到本地指定后缀的文本文件中。
- 执行指令:scrapy crawl spiderName -o filePath (scrapy crawl duanzi -o duanzi.json)
- 文件格式只能是:json、jsonline、jl、csv、xml、marshal、pickle
- 中文乱码问题:
- Scrapy爬取到中文数据默认是 Unicode编码的
- 配置setting.py
- 添加FEED_EXPORT_ENCODING = 'utf-8'
4.2 基于管道的持久化存储
-
1.在爬虫文件中进行数据解析
-
2.在items.py中定义相关属性
- 步骤1中解析出了几个字段的数据,在此就定义几个属性
![item]()
-
3.在爬虫文件中将解析到的数据存储封装到Item类型的对象中
-
字典的形式
-
![导入item.py]()
-
![将数据放到item中]()
-
-
4.将Item类型的对象提交给管道
- yield item
-
5.在管道文件(pipelines.py)中,接收爬虫文件提交过来的Item类型对象,且对其进行任意形式的持久化存储操作
-
6.在配置文件中开启管道机制





1. 将数据存到txt文件中的管道编写
class DuanziproPipeline:
# 保证文件只打开一次文件,需要重写父类的一个方法
fp = None
def open_spider(self, spider):
print('我是open_spider,我只会在爬虫开始的时候只执行一次')
self.fp = open('duanzi.txt', 'w', encoding='utf-8')
# 关闭文件,也是只有一次
def close_spider(self, spider):
print('我是close_spider,我只会在爬虫结束的时候只执行一次')
self.fp.close()
# 该方法用来接收item对象的, 一次只能接收一个item, 该方法会被调用多次
# 参数item:就是接收到的item对象
def process_item(self, item, spider):
# print(item) # item就是一个字典
# 将item存储到文本文件中
self.fp.write(item['title']+':'+ item['content']+'\n')
return item
2. 将数据存到mysql中的管道编写
#将数据存储到mysql中
class MysqlPileLine(object):
conn = None
cursor = None
def open_spider(self,spider):
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='521221',db='spider',charset='utf8')
print(self.conn)
def process_item(self,item,spider):
self.cursor = self.conn.cursor()
sql = 'insert into duanzi values ("%s","%s")'%(item['title'], item['content'])
# 事务处理
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
3. 将数据存到redis中的管道编写
#将数据写入redis
class RedisPileLine(object):
conn = None
def open_spider(self,spider):
self.conn = Redis(host='127.0.0.1',port=6379)
print(self.conn)
def process_item(self,item,spider):
#报错:将redis模块的版本指定成2.10.6即可。pip install -U redis==2.10.6
self.conn.lpush('duanziData',item)
4.setting.py 中给管道开启并设置优先级
ITEM_PIPELINES = {
# 300表示: 管道类的优先级,越小优先级越高
'duanziPro.pipelines.DuanziproPipeline': 300,
'duanziPro.pipelines.MysqlPileLine': 301,
'duanziPro.pipelines.RedisPileLine': 302,
}
注意: 爬虫文件提交到管道的item是先给优先级最高的管道类使用,等到其使用完后需要返回return item给下一个管道类使用,不是并发的。
再坚持一下下,会越来越优秀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号