

02. python 存储结构
python存储结构
存储结构
"""
不可变序列 字符串, 元组 看内存地址是不是发生了改变
可变序列 列表, 字典
"""
1. 元组
1.1 元组相关操作

1.2 元组特性
1.3 元组代码
show code
# #元组的创建
# tup = ('python', 'java', '99')
# print(tup, '\t', type(tup))
#
# tup1 = 'python', 'java', '99' #没有小括号
# print(tup1, '\t', type(tup1))
#
# tup2 = ('python', ) #元组只要单个元素的元组后面要加 逗号
# print(tup2, '\t', type(tup2))
#
# str = ('python')
# print(str, '\t', type(str))
#
#
# t = tuple(('python', 'java', '99'))
# print(t, '\t', type(t))
#
# #空元组
# tup5 = ()
# tup6 = tuple()
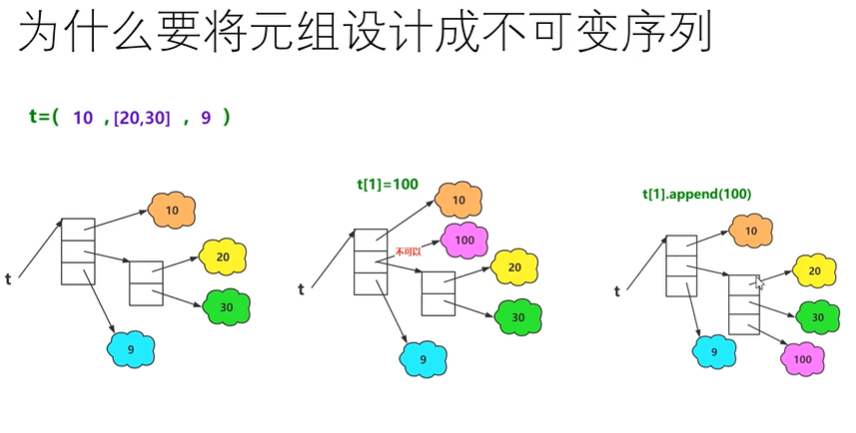
# 引用不可变,整数不可变,列表里面可增删改查,但是列表中的引用不可变
tup = (10, 20, [1, 2])
# print(tup[0], type(tup[0]))
# print(tup[1], type(tup[1]))
# print(tup[2], type(tup[2]))
# tup[0] = 2 #TypeError: 'tuple' object does not support item assignment
# print(tup[0])
tup[2].append(3)
print(tup) #(10, 20, [1, 2, 3])
#遍历元组
for i in tup:
print(i, end = '\t')
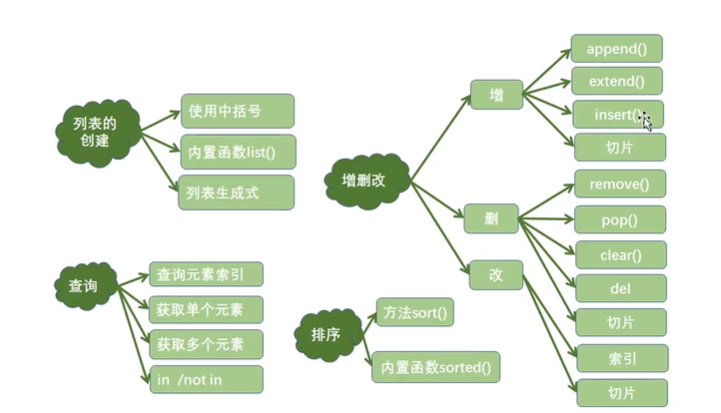
2. 列表
2.1 列表相关操作
2.2 列表代码
show code
# #创建:list , []
# list_1 = ['hello', 'world', 99, 'hello']
# list_2 = list(['hello', 'world', 99, 'hello'])
# print(list_1,"\t",list_2)
#
# #查
# #按照值查索引
# print(list_1.index('hello')) #多个只输出第一个
# print(list_1.index('hello', 2, 4))
# #print(list_1.index('98')) #ValueError: 'hello' is not in list
#
# #按照索引查值
# #获取单个元素
# print(list_1[1])
# print(list_1[-3])
# # print(list_1[10]) #IndexError: list index out of range
# 获取多个元素
# 切片 [start:stop:step] 左闭右开.step不写,默认为1
# step为正数
# lst = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# print(lst[1:5:2])
# print(lst[1:5:1])
# print(lst[:5:1])
# print(lst[1::2])
# print("++++++++++++++++++++++++")
# #step为负数
# print(lst[::-1])
# print(lst[7::-1]) #[8, 7, 6, 5, 4, 3, 2, 1]
# print(lst[7:4:-1])
"""
#列表的判断和遍历
#判断
lst = [10,20,'python','hello']
print(10 in lst)
print(10 not in lst)
#遍历
for item in lst:
print(item, end = '\t')
"""
#增
#lst = [10, 20, 30]
#添加一个元素
# print(lst, id(lst))
# lst.append(40) #[10, 20, 30, 40] 2364472512904
# print(lst, id(lst)) #还是同一个列表
# list_1 = lst.append(50)
# print(lst, id(list_1))
"""
#添加一个列表
#append
lst.append([40,50]) #[10, 20, 30, [40, 50]]
print(lst)
#extend #向列表的末尾加元素,而不是整个列表
lst.extend([60,70]) #[10, 20, 30, [40, 50], 60, 70]
print(lst)
#在任意位置添加
#下标为1的位置添加0,其它往后移动
lst.insert(1,0) #[10, 0, 20, 30, [40, 50], 60, 70]
print(lst)
"""
# #添加切片
# lst = [0,1,2,3,4,5,6,7,8,9,10]
# list_1 = [True, False, 'hello']
# #把下标为1的后面全部切片掉,添加list_1的元素
# lst[1:] = list_1 #[0, True, False, 'hello']
# print(lst)
#删
#根据值移除
# lst = [0, 1, 2, 3, 4, 1]
# lst.remove(1) #有重复元素将第一个1删掉
# #lst.remove(100) #list.remove(x): x not in list
# print(lst)
#pop 根据索引移除元素
# lst.pop(0)
# print(lst)
# #pop 如果不指定元素,则删除最后一个元素
# lst.pop()
# print(lst)
#删除切片
#产生新列表对象
lst = [0, 1, 2, 3, 4, 1]
# #只要 lst[1:5] 中的元素 (左闭右开)
# lst_new = lst[1:5] #[1, 2, 3, 4] 产生一个新的列表对象
# print(lst) #[0, 1, 2, 3, 4, 1]
# print(lst_new)
#不产生新列表对象
# lst[1:3] = [] #[0, 3, 4, 1] 在原列表中删除lst[1:3]的元素
# print(lst)
#
# #clear 清除列表中的全部元素
# lst.clear() #[]
# print(lst)
#
# #删除列表
# del lst
# print(lst)
#改
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9]
lst[2] = 100
print(lst)
#使用切片
lst[1:3] = [10,20,30,40]
print(lst)
#排序操作
#没有产生新的列表
list_1 = [2, 5, 4, 1, 3, 6, 5, 4]
print("排序前的列表:", list_1, id(list_1))
list_1.sort()
print("排序后的列表:", list_1, id(list_1))
#降序
list_1.sort(reverse=True)
print("降序:", list_1)
#产生新的列表
# print(id(list_1))
# lst_new = sorted(list_1)
# print(lst_new, id(lst_new))
#使用参数的降序
#sorted(list_1,reversed = True)
2.3 列表生成式
lst = [i for i in range(1, 10)] #[1, 2, 3, 4, 5, 6, 7, 8, 9]
print(lst)
lst = [i*i for i in range(1, 10)] #[1, 4, 9, 16, 25, 36, 49, 64, 81]
print(lst)
list_1 = [i*2 for i in range(1, 6)]
print(list_1)
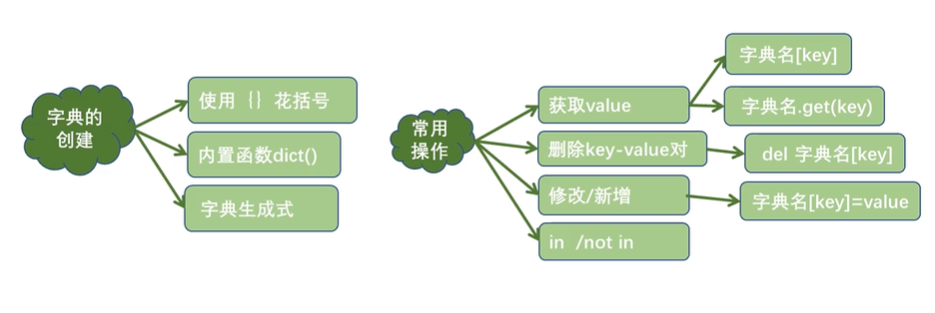
3. 字典
3.1 字典相关操作
3.2 字典代码
show code
"""
#字典的创建
scores = {'wesley':'100','leo':'90'}
print(scores,type(scores))
age = dict(wesley = '20',leo = '21')
print(age, type(age))
#空字典
d = {}
print(d)
"""
#查
# scores = {'wesley': '100', 'leo': '90'}
# print(scores['wesley'])
# #print(scores['linda']) #KeyError: 'linda'
#
# print(scores.get('wesley'))
# print(scores.get('linda')) #不会报错,None
# print(scores.get('叶宝宝', 99)) #在字典中查找叶宝宝,没有查到就输出99,99是默认值,而不是赋值
# print(scores)
"""
#in not in (判断)
scores = {'wesley': '100', 'leo': '90'}
print('wesley' in scores)
print('wesley' not in scores)
#del删除
del scores['leo'] #删除指定键值对 {'wesley': '100'}
print(scores)
scores.clear() #{} 清空
print(scores)
"""
#增
scores = {'wesley': '100', 'leo': '90'}
scores['linda'] = 95 #{'wesley': '100', 'leo': '90', 'linda': 95}
print(scores)
#改
scores = {'wesley': '100', 'leo': '90'}
scores['leo'] = 98 #{'wesley': '100', 'leo': 98}
print(scores)
3.3 字典生成式
#内置函数zip()
# names = ['wesley', 'leo', 'linda']
# scores = ['100', '99', '98']
# dic ={names:scores for names, scores in zip(names, scores)}
# d ={names.upper():scores for names, scores in zip(names, scores)} #names.upper() names变大写
# print(dic)
# print(d)
#当两个列表元素个数不同时,会以少的为准
names = ['wesley', 'leo', 'linda', '叶宝宝']
scores = ['100', '99', '98']
dic ={names:scores for names, scores in zip(names, scores)}
d ={names.upper():scores for names, scores in zip(names, scores)} #names.upper() names变大写
print(d)
3.4 字典视图操作
show code
scores = {'wesley': '100', 'leo': '90'}
# print(scores.keys()) #获取全部键
# print(scores.values()) #获取全部值
# print(scores.items()) #获取全部键值对
# names = scores.keys()
# print(type(names), "\t", names)
# print(list(names)) #将所有键转换成列表
#
# score = scores.values()
# print(list(score))
#
# item = scores.items()
# print(list(item)) #元组组成的列表
#字典的遍历
for name in scores.keys():
print(name)
#字典键不可以重复,重复会覆盖
print(scores)
scores['linda'] = 97
print(scores)
scores['linda'] = 98
print(scores)
4. 字符串
4.1 字符串代码
show code
#字符串的创建
# var1 = 'hello world!'
# var2 = 'python'
#print(var1, '\t', var2)
#查
#print(var1[0])
#连接
# print(var1+var2) #hello world!python
#字符串运算符
# a = "Hello"
# b = "Python"
#
# print("a + b 输出结果:", a + b)
# print("a * 2 输出结果:", a * 2)
# print("a[1] 输出结果:", a[1])
# print("a[1:4] 输出结果:", a[1:4])
#
# if ("H" in a):
# print("H 在变量 a 中")
# else:
# print("H 不在变量 a 中")
#
# if ("M" not in a):
# print("M 不在变量 a 中")
# else:
# print("M 在变量 a 中")
#
# print(r'\n')
# print(R'\n')
#字符串格式化输出
# print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
# f-string新的格式化字符串的语法,用了这种方式明显更简单了,不用再去判断使用 %s,还是 %d
name = "baby"
print(f'hello {name}')
print(f'{1+2}')
#3.6之后
w = {'name': 'Runoob', 'url': 'www.runoob.com'}
print(f'{w["name"]}: {w["url"]}')
# Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果
# print(f'{x+1=}') #3.8之后才可以用 'x+1=2'
#字符串内置函数
4.2 字符串内置函数
"""
大小写处理
判断字符串中的字符类型
字符串替换
去空格
用特定符连接单个字符
用字符串中的特定符分割字符串
搜索
"""
5. 集合
show code
"""
#集合的创建 特点:无序,不会有重复元素
s = {1, 2, 3, 3, 4}
#print(s) #{1, 2, 3, 4}
# s1 = set({1, 2, 3, 3, 4})
# print(s1)
#无序
s2 = set("python") #{'n', 'h', 'o', 'y', 't', 'p'}
print(s2)
"""
#
# #判断操作(in not in)
# s = {1, 2, 3, 3, 4}
# print(10 in s)
#
# #增
# #增加一个元素
# s.add(80) #{1, 2, 3, 4, 80}
# print(s)
# #增加多个元素
# s.update({100, 200})
# print(s)
#
# s.update([300, 200])
# print(s)
# #删
# s = {1, 2, 3, 4, 100, 200, 300, 80}
# s.remove(80) #没有会报错
# print(s)
# s.discard(500) #没有不会报错
# print(s)
# s.pop() #删除任意(随机)一个元素(不可以添加参数)
# print(s)
# s.clear() #清空
# print(s)
#特点
# s = {1, 2}
# s1 = {2, 1}
# print(s == s1) #True
#判断子集
s1 = {}
再坚持一下下,会越来越优秀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号