7.Spark SQL
一. 分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
二. 简述RDD 和DataFrame的联系与区别。
三. DataFrame的创建与保存:
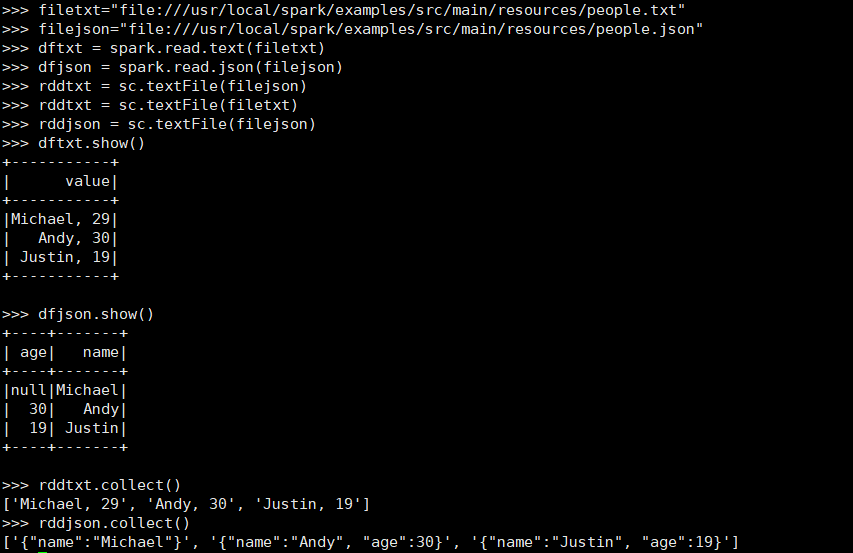
- PySpark-DataFrame创建:
- spark.read.text(url)
- spark.read.json(url)
- spark.read.format("text").load("people.txt")
- spark.read.format("json").load("people.json")
- 描述从不同文件类型生成DataFrame的区别。
- 用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
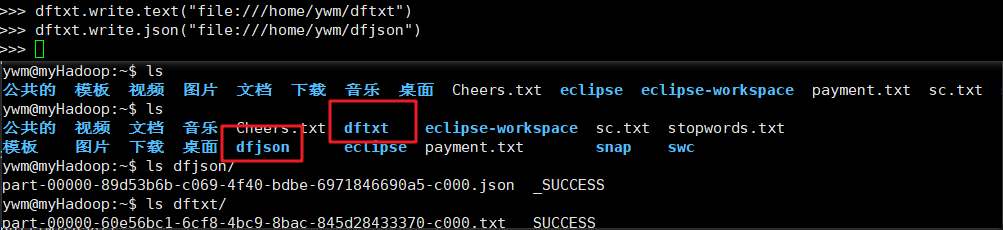
- DataFrame的保存
- df.write.text(dir)
- df.write.json(dri)
- df.write.format("text").save(dir)
- df.write.format("json").save(dir)
四. PySpark-DataFrame各种常用操作
- 基于df的操作:
- 打印数据 df.show()默认打印前20条数据
- 打印概要 df.printSchema()
- 查询总行数 df.count()
- df.head(3) #list类型,list中每个元素是Row类
- 输出全部行 df.collect() #list类型,list中每个元素是Row类
- 查询概况 df.describe().show()
- 取列 df[‘name’], df.name, df[1]

- 基于spark.sql的操作
- 创建临时表 df.registerTempTable('people')
- spark.sql执行SQL语句 spark.sql('select name from people').show()

五 Pyspark中DataFrame与pandas中DataFrame
- 分别从文件创建DataFrame
- 比较两者的异同
- pandas中DataFrame转换为Pyspark中DataFrame
- Pyspark中DataFrame转换为pandas中DataFrame
六 从RDD转换得到DataFrame
- 利用反射机制推断RDD模式
- 创建RDD sc.textFile(url).map(),读文件,分割数据项
- 每个RDD元素转换成 Row
- 由Row-RDD转换到DataFrame

- 使用编程方式定义RDD模式
- 下面生成“表头”
- 下面生成“表中的记录”
- 下面把“表头”和“表中的记录”拼装在一起

本文来自博客园,作者:是你,转载无需注明原文链接:https://www.cnblogs.com/ye092711/p/16197790.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号