5.RDD操作综合实例
一、词频统计
-
分步骤实现
- 准备文件
- 下载小说或长篇新闻稿
- 上传到hdfs上
- 读文件创建RDD
- 分词
- 排除大小写,标点符号,停用词,长度小于2的词
- 统计词频
- 排序
- 输出到文件
- 查看结果
- 准备文件
-
一句话实现
点击查看代码
'''
词频统计
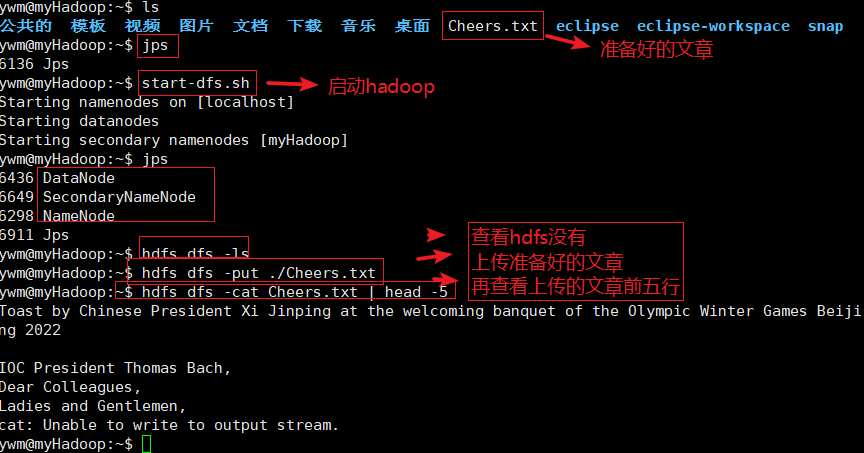
准备文件包括词频统计文件和停用词文件 存放于实验机或hdfs上
进入pyspark shell 执行以下操作
--停用词列表可自定义python函数 或 通过创建rdd来读取 或 使用其他现有的python停用词库......
(注意:生成新rdd时可以进行简单的打印输出操作 eg: .take(3) | .collect() | .foreach(print).....)
'''
import re # (导包用于分词)
stopwords = sc.textFile("file:///home/ywm/stopwords.txt").flatMap(lambda word:word.split()).collect()
# 读文件创建RDD
lines = sc.testFile("Cheers.txt")
# 分词
# 排除大小写,标点符号,停用词,长度小于2的词
words = lines.flatMap(lambda lines:re.split('[.,!?;:"\'\- ]',lines.lower())).filter(lambda word:(word!='') & (len(word)>2) & (word not in stopwords))
# 统计词频
wc = words.map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b)
# 排序 按值降序
swc = wc.sortBy(lambda a:a[1],False)
# 输出到文件
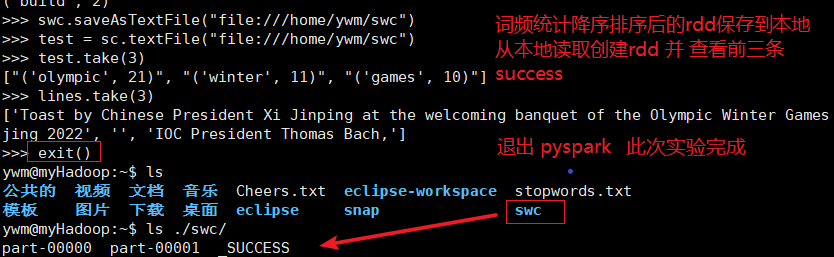
swc.saveAsTextFile("file:///home/ywm/swc")
# 查看结果
'''
打开终端执行 ls /home/ywm/
可以看到新生成了的'swc'文件夹及里面以一个或多个part开头和一个_SUCCESS文件
在pyspark shell里可以读取swc文件夹生成rdd
eg:
rrdd = sc.testFile("file:///home/ywm/swc")
最终效果结果看下面截图(注:步骤图略)
'''
# 一句话实现
lines.flatMap(lambda lines:re.split('[.,!?;:"\'\- ]',lines.lower())).filter(lambda word:(word!='') & (len(word)>2) & (word not in stopwords)).map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b).sortBy(lambda a:a[1],False).saveAsTextFile("file:///home/ywm/swc")
- 此次Spark编程实现词频统计和Python编程英文文本的词频统计 进行比较,理解Spark编程的特点
Spark编程的特点:
1. 重要概念RDD
2. 在进行RDD一系列操作
3. RDD在遇到行动操作前的一系列RDD转换操作可流式实现
4. RDD在没有遇到行动操作时是不会真正的执行数据的加载计算处理(惰性机制!!!)
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出Top3支付额的用户。
- 丢弃不合规范的行:
- 空行
- 少数据项
- 缺失数据
- 按支付金额排序
- 取出Top3
点击查看代码
'''
要求: 通过RDD操作实现选出 Top3 支付额的用户
payment.txt
文件字段:订单编号,用户编号,支付金额,商品编号
(注意:生成新rdd时可以进行简单的打印输出操作 eg: .take(3) | .collect() | .foreach(print).....)
'''
#1 丢弃不合规范的行:空行 少数据项 缺失数据
datas = sc.textFile('file:///home/ywm/payment.txt').map(lambda line:line.split(',')).filter(lambda line:('' not in line) and (len(line)==4))
# 2 按支付金额排序
sortdatas = datas.sortBy(lambda line:line[2],False)
#3 取出Top3
sortdatas.take(3)
# 一句话实现 取到消费金额 Top3 的用户记录
sc.textFile('file:///home/ywm/payment.txt').map(lambda line:line.split(',')).filter(lambda line:'' not in line).sortBy(lambda line:line[2],False).take(3)

本文来自博客园,作者:是你,转载无需注明原文链接:https://www.cnblogs.com/ye092711/p/16052141.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号