3.Spark设计与运行原理,基本操作
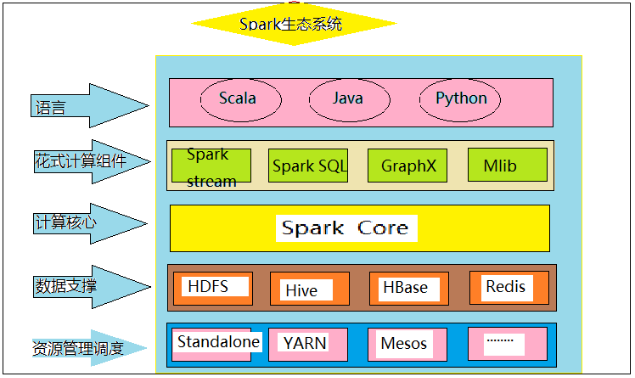
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
- Spark Core: Spark Core 是整个Spark生态的核心,是一种大数据分布式处理框架.不仅提供map和reduce函数,还提供了计算模型,join, filter等.
- HDFS: 分布式文件系统,能提供高吞吐量的数据访问.
- Spark Streaming: 是构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力.
- Mlib: 是Spark常用的一种机器学习算法的实现库.
- YARN: 是一种统一资源管理机制,在其上面可以运行多套计算框架.
2.请详细阐述Spark的几个主要概念及相互关系:
- Master, Worker;
- RDD, DAG;
- Application, job,stage, Task;
- Driver,Executor, Claster Manager, DAG Scheduler, Task Scheduler.
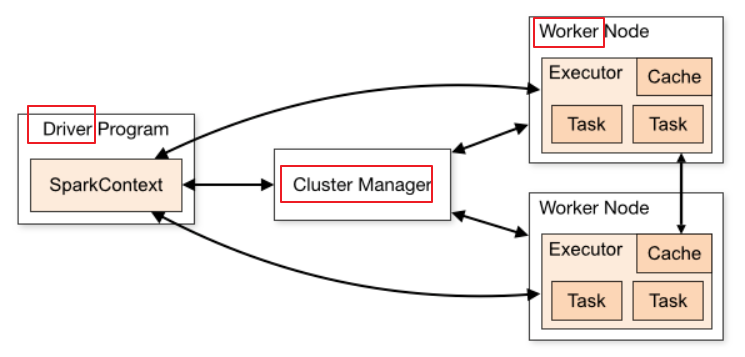
master和worker:
spark集群有多个master节点和多个worker节点
master节点常驻master守护进程,负责管理worker节点,我们从master节点提交应用
worker节点常驻worker守护进程,与master节点通信,并且管理executor进程
下图是某网扒的,参考下:
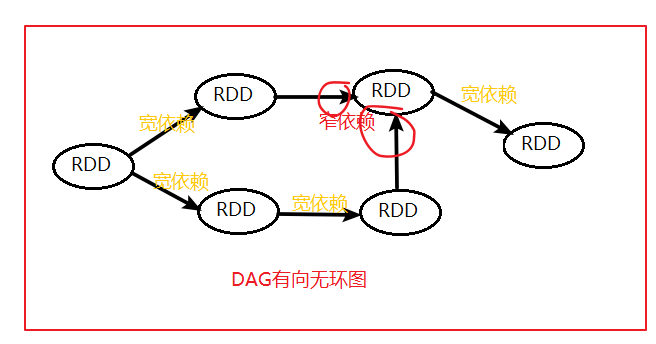
RDD和DAG:
Spark使用DAG来反映各RDD之间的依赖或血缘关系,RDD通过一系列的转换操作和行动操作就形成了一个DAG
RDD(Resilient Distributed Datasets): 弹性分布式数据集,是分布式内存的抽象概念.RDD可以通过sc读取存储系统的数据集转换生成或其他已存在的RDD转换生成.
DAG(Directed Acyclic Graph): 有向无环图及指的是一个无回路的有方向的图.
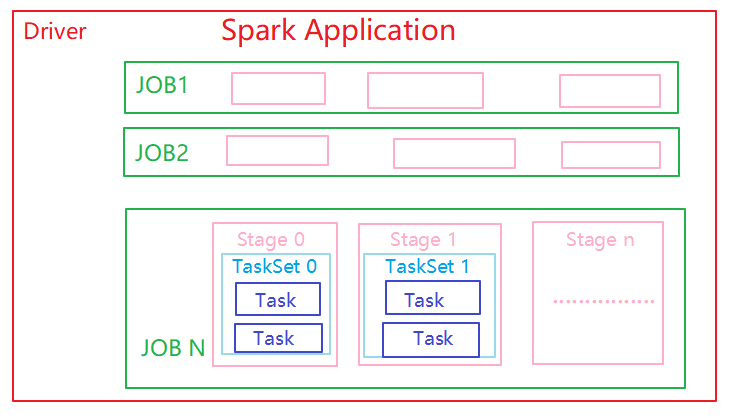
Application, job,stage,task:
Application: 就是基于spark构建的用户程序,由集群上的驱动程序和执行程序组成
job: 由多个任务组成的并行计算,为响应Spark Action操作(Spark操作可分为tramfrom和action操作)而产生的.一个action操作就生成一个job
Stage: 每个job都被分成更小的tasksss称为阶段,一个Stage的划分根据一个job是否有进行shuffle发生(RDD中依赖关系分为宽依赖和窄依赖:
窄依赖:父子关系是一对多或多对一不产生shuffle
宽依赖:父子关系是多对一或多对多就产生Shuffle)
简单来说,每次shuffle一下,就要划分一下stage哟
Driver,Executor,Cluster Manager,DAG Scheduler, Task Scheduler:
Driver: 运行应用程序的main函数并创建SparkContext进程
Executor: 在worker节点上Application启动的进程,执行运行任务并将数据保存在内存或disk中,每个Application都有自己的executorsss.
Cluster Manager: 获取集群资源的外部服务(eg: standalone manager,Mesos,YARN)
DAG Scheduler: 阶段调度器,通过RDD的转换操作转化成多个Stage,每个Stage生成一个Tasksss,并提交给TaskSchedule.
Task Scheduler: 任务调度器核心任务是提交Tasksss到集群运算并汇报结果
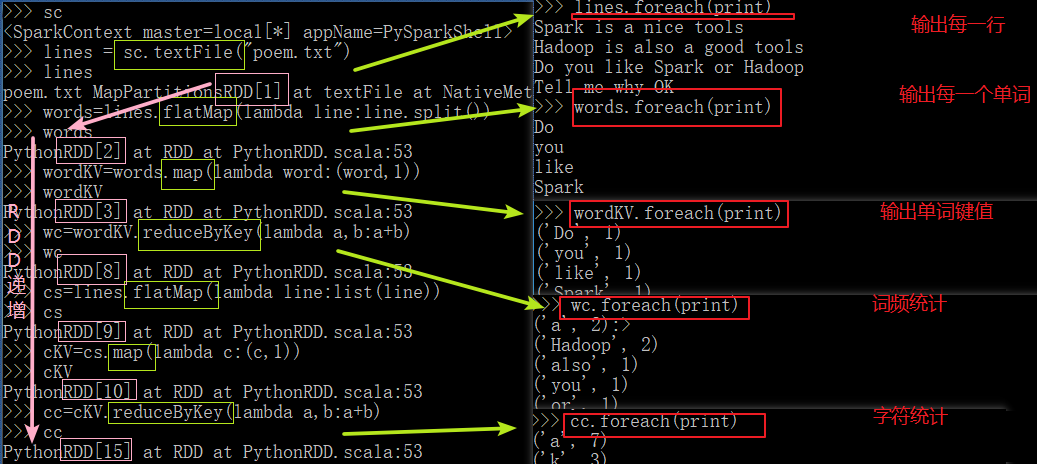
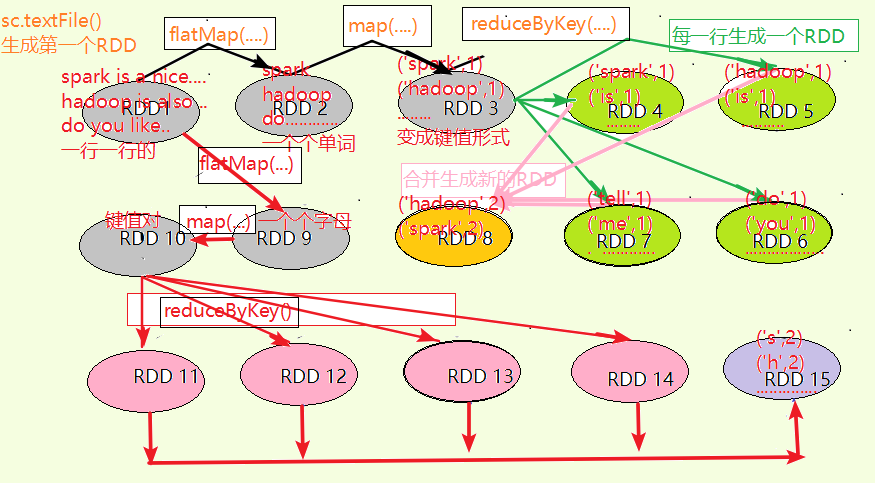
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
点击查看代码
sc
lines = sc.textFile("poem.txt")
lines
words=lines.flatMap(lambda line:line.split())
words
wordKV=words.map(lambda word:(word,1))
wordKV
wc=wordKV.reduceByKey(lambda a,b:a+b)
wc
cs=lines.flatMap(lambda line:list(line))
cs
cKV=cs.map(lambda c:(c,1))
cKV
cc=cKV.reduceByKey(lambda a,b:a+b)
cc
lines.foreach(print)
words.foreach(print)
wordKV.foreach(print)
cs.foreach(print)
cKV.foreach(print)
wc.foreach(print)
cc.foreach(print)
本文来自博客园,作者:是你,转载无需注明原文链接:https://www.cnblogs.com/ye092711/p/15986796.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号