1.大数据概述
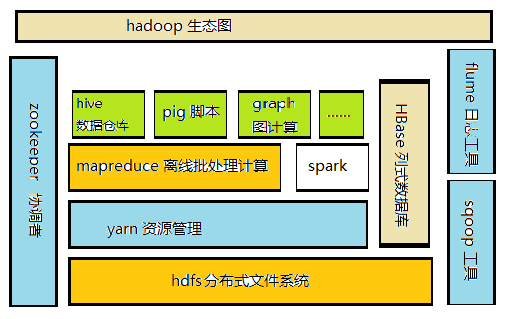
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
a. HDFS(hadoop分布式文件系统)是hadoop体系中数据存储管理者。
b. MapReduce(分布式计算框架)mapreduce是一种计算模型,用于处理大数据量的计算者。
c. Hive(基于hadoop的数据仓库)解决结构化的日志数据问题。
d. Zookeeper(分布式协调者)是分布式环境下各个组件的协调者。
e. Sqoop(数据同步工具)sqoop是传统数据库和hadoop之间数据转换与传输者。
f. YARN(资源管理器)是将所有的这些框架组件部署到同一个公共的集群上并共享集群资源者。
2.对比Hadoop与Spark的优缺点。
a. hadoop 优点:解决了海量数据的存储与处理。缺点:只提供map和reduce两个操作,抽象层次低,表现能力欠佳。mapreduce处理的中间结果放在磁盘,有大量的io耗时操作,延迟高,适合离线批处理.
b. spark 优点:提供了一个集群的分布式内存抽象,处理数据速度快。缺点:数据的操作处理基于内存,这也导致spark不适合处理超过一定规模的数据
3.如何实现Hadoop与Spark的统一部署?
可以在YARN之上统一部署,因为Hadoop Spark等组件都可以运行在资源管理框架YARN之上.
本文来自博客园,作者:是你,转载无需注明原文链接:https://www.cnblogs.com/ye092711/p/15926560.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号