
机器学习3
任务4
1、KNN的决策边界以及K的影响
决策边界分成两大类,分别是线性决策边界和非线性决策边界。拥有线性决策边界的模型我们称为线性模型,反之非线性模型.
随着K值的增加,决策边界确实会变得更加平滑。决策边界的平滑也意味着模型的稳定性。但稳定不代表这个模型就会越准确。虽然决策边界平滑会使得模型变得更加稳定,但稳定不代表模型的准确率更高。
2、交叉验证
在KNN里,通过交叉验证,可以得出最合适的K值。它的核心思想是把一些候选的K逐个去尝试一遍,然后选出效果最好的K值。常用的交叉验证技术叫做K折交叉验证(K-fold Cross Validation)。 我们先把训练数据再分成训练集和验证集,之后使用训练集来训练模型,然后再验证集上评估模型的准确率。举个例子,比如一个模型有个参数叫α,我们一开始不清楚要选择0.1还是1,所以这时候我们进行了交叉验证:把所有训练集分成K块,依次对每一个α值评估它的准确率。
交叉验证中经常使用K折(注意这个K不是KNN的K!)交叉验证,就是在已有的数据上重复做多次的验证。最后,对于交叉验证,绝不能使用测试数据来进行训练。
3、特征规范化
在应用KNN之前我们经常使用标准化的操作,也就是把特征映射到类似的量纲空间,目的是不让某些特征的影响变得太大。
有两种常见的特征标准化的方法。它们分别是线性归一化和标准差归一化。
其中,线性归一化指的是把特征值的范围映射到[0,1]区间,标准差标准化的方法使得把特征值映射到均值为0,标准差为1的正态分布。
product 用于求多个可迭代对象的笛卡尔积(Cartesian Product),它跟嵌套的 for 循环等价.即:product(A, B) 和 ((x,y) for x in A for y in B)的效果是一样的。
iterables 是可迭代对象, repeat指定 iterable 重复几次,即:
product(A,repeat=3)等价于product(A,A,A)。
np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵。(https://blog.csdn.net/zch1990s/article/details/80004518)
def multivariate_normal(mean, cov, size=None, check_valid=None, tol=None)
其中mean和cov为必要的传参而size,check_valid以及tol为可选参数。
mean:mean是多维分布的均值维度为1;
cov:协方差矩阵,注意:协方差矩阵必须是对称的且需为半正定矩阵;(https://blog.csdn.net/zch1990s/article/details/80001991)
np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组
np.hstack:按水平方向(列顺序)堆叠数组构成一个新的数组


In[4]: a = np.array([[1,2,3]]) a.shape Out[4]: (1, 3) In [5]: b = np.array([[4,5,6]]) b.shape Out[5]: (1, 3) In [6]: c = np.vstack((a,b)) # 将两个(1,3)形状的数组按垂直方向叠加 print(c) c.shape # 输出形状为(2,3) [[1 2 3] [4 5 6]]
numpy.meshgrid()——生成网格点坐标矩阵
plt.subplots()是一个函数,返回一个包含figure和axes对象的元组
kf = KFold(n_splits=5, shuffle=True, random_state=10)
这里的KFold入参就是这三个,n_splits分成几份,就是几折交叉验证。shuffle是否在划分之前重新洗牌,默认false,当shuffle=true的时候,random_state的设置才有意义,随机种子。
任务5
1、图像的读取及表示
import matplotlib.pyplot as plt img = plt.imread('G:/机器学习/1.png') print(img.shape) plt.imshow(img)
2、图片特征
常用的图片特征有:
颜色特征:颜色特征里最常用的是颜色直方图(color histogram),其实就是对R,G,B三种颜色做一个统计,比如有百分之多少的R颜色落在[10,20]的区间。
SIFT(Scale Invariant Feature Transform)尺度不变特征变换:SIFT特征是一种局部特征,其具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果,是一种非常稳定的局部特征。SIFT试图去寻找类似图片中的拐点这类的关键点,然后通过一系列的处理得到一个SIFT向量
HOG(HistogramoforientedGradient) 方向梯度直方图:其通过计算和统计图像局部区域的梯度方向直方图来构建特征。
任务6
1、文件的读取、可视化及采样。
# 文件的读取,我们直接通过给定的`load_CIFAR10`模块读取数据。 from load_data import load_CIFAR10 # 感谢这个magic函数,你不必要担心如何写读取的过程。如果想了解细节,可以参考此文件。 import numpy as np import matplotlib.pyplot as plt import random cifar10_dir = 'cifar-10-batches-py' #请把该文件夹放在与当前文件的同一目录 # 清空变量,防止重复导入多次。 try: del X_train, y_train del X_test, y_test print('清除之前导入过的变量...Done!') except: pass # 读取文件,并把数据保存到训练集和测试集合。 X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
import matplotlib.pyplot as plt classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] num_classes = len(classes) # 样本种类的个数 samples_per_class = 5 # 每一个类随机选择5个样本 # TODO 图片展示部分的代码需要在这里完成。 hint: plt.subplot函数以及 plt.imshow函数用来展示图片 plt.figure(figsize = (5,5)) for i in range(num_classes): indexs = np.where(y_train==i)[0] random.shuffle(indexs) for j in range(samples_per_class): ax = plt.subplot(7,10,10*j+i+1) if j==0: ax.set_title(classes[i]) plt.axis('off') plt.imshow(X_train[indexs[j]]/225)
plt.subplot(1,2,1) #一行两列的子图,最后的1是位置1 plt.imshow(X_train[1]/255)#在刚才指定位置绘制第1副图 plt.subplot(1,2,2)#一行两列的子图,最后的2是位置2 plt.imshow(X_train[2]/255)#在刚才指定的位置绘制第2副图
plt.figure(figsize = (8,8)) #创建一个指定大小的窗口(可根据需要调节)
plt.axis('off')#关闭窗口
随机采样训练样本5000个和测试样本500个。训练样本从训练集里采样,测试样本从测试集里采样。
# TODO 随机采样训练样本5000个和测试样本500个。训练样本从训练集里采样,测试样本从测试集里采样。 num_training = 5000 num_test = 5000 np.random.seed(200) np.random.shuffle(X_train) X_train = X_train[:5000] np.random.seed(200) np.random.shuffle(y_train) y_train = y_train[:5000] np.random.seed(50) np.random.shuffle(X_test) X_test = X_test[:500] np.random.seed(50) np.random.shuffle(y_test) y_test = y_test[:500] print (X_train.shape, y_train.shape, X_test.shape, y_test.shape)
python的random函数,千万不要用于numpy的矩阵,否则shuffle后结果混乱,要shuffle numpy的矩阵,要使用numpy.random。
2、使用knn算法识别图片
KNN有几个关键的参数:
K: 指定选择多少个
neighbors。 这个值越大,我们知道KNN的决策边界就会越平滑,而且越不容易过拟合, 但不保证准确率会很高。
p: 不同距离的指定,看以下的说明。
KNN依赖于两个样本的距离计算,这里简单介绍一下一个概念叫做Minkowski Distance,是一个种通用的距离计算方法。假如我们有两个点,分别由两个向量来表达𝑥=(𝑥1,𝑥2,...,𝑥𝑑)x=(x1,x2,...,xd)和𝑦=(𝑦1,𝑦2,...,𝑦𝑑)y=(y1,y2,...,yd),这时候根据Minkowski Distance的定义可以得到以下的结果:
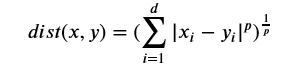
从上述的距离来看其实不难发现𝑝=1p=1时其实就是绝对值的距离,𝑝=2p=2时就是欧式距离。所以欧式距离其实是Minkowski Distance的一个特例而已。所以这里的𝑝p值是可以调节的比如𝑝=1,2,3,4,...p=1,2,3,4,...。
GridSearchCV,这是一种参数搜索的方法也叫作网格搜索,其实就是考虑所有的组合。 比如K=[1,3,5,7], p=[1,2,3], 则通过网格搜索会考虑所有可能的12种组合。
param_grid = [ { 'weights':['uniform'], 'n_neighbors':[i for i in range(1,11)] }, { 'weights':['distance'], 'n_neighbors':[i for i in range(1,11)], 'p':[i for i in range(1,6)] } ] grid_search = GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=2)
GridSearchCV常用超参数:
estimator:创建的对象,如上的knn_clf
param_grid:是一个列表,列表里是算法对象的超参数的取值,用字典存储
n_jobs:使用电脑的CPU个数,-1代表全部使用
verbose:每次CV时输出的格式
3、抽取图片特征,再用KNN算法来识别图片
一种解决图像识别问题中各种环境不一致的方案是抽取对这些环境因素不敏感的特征。这就是所谓的特征工程。在这里,我们即将会提取两种类型的特征,分别是color histogram和HOG特征,并把它们拼接在一起作为最终的特征向量。
对特征数据做归一化,由于特征提取之后的,每一个维度的特征范围差异有可能比较大,所以使用KNN之前需要做归一化。在这里请使用均值为0,标准差为1的归一化,调用StandardScaler。
StandardScaler:作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。
4、使用PCA对图片做降维,并做可视化
from sklearn.decomposition import PCA from sklearn import neighbors from sklearn import datasets from sklearn.model_selection import GridSearchCV from sklearn.pipeline import Pipeline import subprocess params_components = [10, 20, 50, 100] params_k = [13] # 可以选择的K值 params_p = [2] # 可以选择的P值 # TODO 首先使用PCA对数据做降维,之后再用KNN做交叉验证。 每一个PCA的维度都需要做一次KNN的交叉验证过程。 # 输入为原始的像素特征。 训练数据:X_train, y_train 测试数据: X_test, y_test。 pipe = Pipeline([ ('pca',PCA()), ('clf',neighbors.KNeighborsClassifier()), ]) params = { 'pca_n_components':params_components, 'clf_n_neighbors':params_k, 'clf_p':params_p } model = GridSearchCV(pipe,params,cv = 5,n_jobs=-1,verbose = 1) model.fit(X_train1,y_train) # 输出最好的 维度、K和p值 print(model.best_params) # 输出在测试集上的准确率 print("准确率为 %.3f"%(model.score(X_test1,y_test)))
(管道机制)Python的sklearn.pipeline.Pipeline()函数可以把多个“处理数据的节点”按顺序打包在一起,数据在前一个节点处理之后的结果,转到下一个节点处理。除了最后一个节点外,其他节点都必须实现'fit()'和'transform()'方法, 最后一个节点需要实现fit()方法即可。当训练样本数据送进Pipeline进行处理时, 它会逐个调用节点的fit()和transform()方法,然后点用最后一个节点的fit()方法来拟合数据。
使用PCA降维代码并没顺利通过,显示valueError。

总结:
在对照老师给的代码重复实现时,很多python自带库都得自行安装并加上去,才能运行,对于使用knn算法实现图象识别,总的看完之后,大概了解了如何实现得,但就自身来实现,还是有点困难,只能理解而对于相关的numpy之类的用法熟悉了许多,就我理解的使用knn算法来识别图象,是通过提炼图片特征值,然受利用knn算法训练再进行相关识别,可能还需要更多熟悉相关知识才能懂得更多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号