
机器学习.1
第一次接触机器学习的概念,其实对于这方面相当于从零开始,包括python的使用,一点都不了解,在上一周开始正式接触有关方面的知识。
1.机器学习及深度学习
机器学习是解决人工智能问题的最核心的技术。比如推荐系统、无人驾驶、人脸识别、竞技分析等应用都要依赖于机器学习技术。
机器学习的核心是,从数据中自动学出规律,而不是一个人拍脑袋定出来的。可以简单地理解为归纳总结。而且通过机器归纳出来的规律有可能很多是我们之前都没有想到的。
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。有三种主要类型的机器学习:监督学习、非监督学习和强化学习,所有这些都有其特定的优点和缺点。
深度学习,可以让神经网络自己学习如何抓取数据的特征,它把学习的性能提升到另一个高度,深度学习的学习对象同样是数据。
任务一、编写第一个AI程序
首先就数据可视化直观理解一番,就是将数据集中以图形或图像显示出来再进行一系列数据分析,在刚开始按照指导写代码的时候,不知道为什么我的python里好像没有sklearn这个包,通过一系列查询理解,通过cmd直接pip下载了这个包之后代码才能正常运行。
接着对数据的读出发生了疑问,在之前所学的c++与java中,并没有见到过这种读数据方式,而reshape函数也没有使用过,通过查找python的资料才了解具体比如x,y = data[:,0].reshape(-1,1),data[:,1],data [:,]每行的第一列的所有数据,data[:,1]每行的第二列所有数据,reshape(m,-1) #改变维度为m行、1列,reshape(-1,m) #改变维度为1行、m列。reshape(-1,1) 转换为1列。shape是查看数据有多少行多少列,reshape()是数组array中的方法,作用是将数据重新组织。
import matplotlib.pyplot as plt# 引用matplotlib库,主要用来画图,讲数据以图形呈现出来。
接着是对sklearn线性回归模型在linear_model模块里的理解。

对于训练数据(x,y),通常通过sklearn中的fit(x,y)来实现模型的训练。这里x可以看做是特征部分,y可以看做是真实的值或者标签。
调用plt.plot()函数即可以画出一条线。
regr.predict()返回预测的标签。
任务二、使用sklearn自带的工具实现KNN
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
第一个import是用来导入一个样本数据。sklearn库本身已经提供了不少可以用来测试模型的样本数据,所以通过这个模块的导入就可以直接使用这些数据了。 第二个import是用来做数据集的分割,把数据分成训练集和测试集,这样做的目的是为了评估模型。第三个是导入了KNN的模块,是sklearn提供的现成的算法。
iris = datasets.load_iris()
x = iris.data
y = iris.target
print(x,y)
这里我们导入的数据集叫做iris数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=2003)
X存储的是数据的特征,y存储的每一个样本的标签或者分类,train_test_split来把数据分成了训练集和测试集。
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train,y_train)
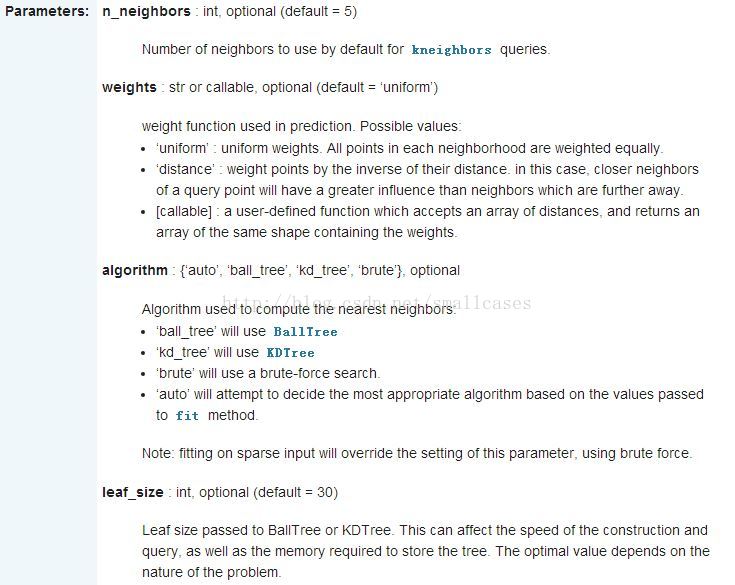
输出结果:KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=None, n_neighbors=3, p=2, weights='uniform')
n_neighbors=3, 意思就是说我们选择的K值是3.
n_neighbors:就是选取最近的点的个数:k
leaf_size:这个是构造树的大小,值一般选取默认值即可,太大会影响速度。
n_jobs :默认值1,选取-1占据CPU比重会减小,但运行速度也会变慢,所有的core都会运行。

correct = np.count_nonzero((clf.predict(x_test)==y_test)==True)
这部分的代码主要用来做预测以及计算准确率。计算准确率的逻辑也很简单,就是判断预测和实际值有多少是相等的。如果相等则算预测正确,否则预测失败。
个人感悟:
对于第一次接触机器学习方面相关知识,可能刚刚开始还是很多不懂得地方,对于python也有很多不会的地方,本次两个任务慢慢再努力理解当中,还没有很详细的记住并且合理运用,只能说在尝试去理解掌握它,自己在这方面的努力还需要加强学习,对于不会的地方还需要多查资料获得更多知识,要继续加油。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号