
第二次作业-python爬取网页及数据分析与展示
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 培养良好的编码习惯及博客记录,提升自学能力 |
| Gitee 地址 | https://gitee.com/yu-huangqiang/get-data |
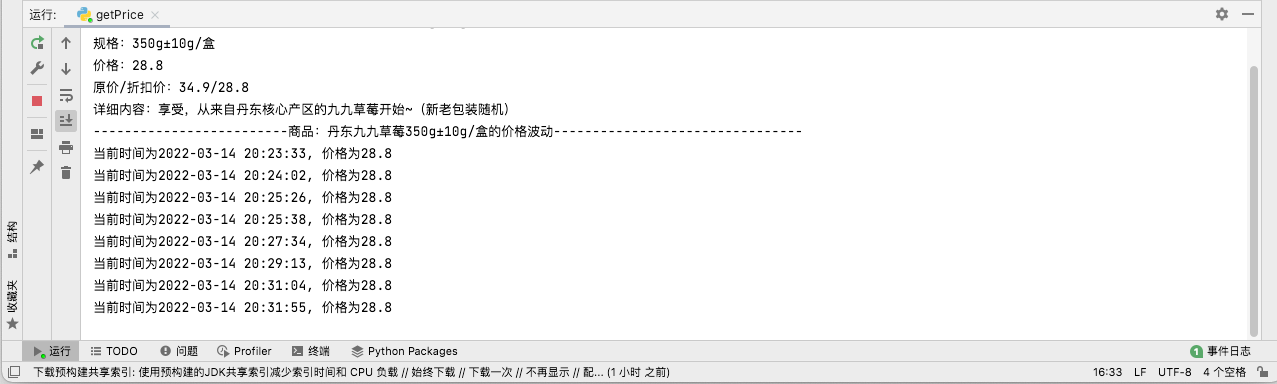
朴朴商城价格监控
解题思路描述
- 说实话拿到这个课题还是挺兴奋的,爬虫是当下非常火的一项技术,作为计算机专业学生不会爬虫都说不过去,早就想爬取一些东西了。刚好借用这个机会实现一下。
- 查找资料后大致理解了爬虫的基本原理,以及fiddler的原理及使用。fiddler抓包工具,可以理解为是一个代理,是用户到服务器的一个中间层,通过它可以监控到用户-服务器的请求。由于爬取的朴朴商城是移动端的数据,在pc端是不能直接访问移动端的接口的。所以我们要借助fiddler工具对移动端接口进行抓取接口。
设计实现过程
- 第一步:首先安装fiddler软件,(我使用的是mac端的,注册账号后就可以使用,如果是windows版的需要修改配置后才能抓取到同一局域网上的设备请求)
- 第二步: 修改配置:将手机和电脑连在同一wifi上,修改手机wifi配置:添加代理,将代理地址和端口修改fiddler的地址和端口,这一步是让手机发送的请求通过fidller层,fiddler在后台就可以监控到手机发送的所有请求。最后在手机浏览器访问刚刚添加的代理地址和端口,然后下载证书。(手机厂商为了保护用户安全默认情况下是不允许通过第三方代理来发送请求的,需要安装信任证书!)
- 第三步: 抓取app接口:使用手机打开app访问页面,在fiddler上寻找接口地址。
- 第四步: 获取数据:使用python来模拟手机向服务器发送请求来获取数据
最终效果
代码说明
点击查看代码
添加请求头,这里的 user-agent 是设备标识
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
url = 'https://www.zhihu.com/api/v4/people/fcc808ca04188e8fbfebd590592583ec/collections?include=data%5B*%5D.updated_time%2Canswer_count%2Cfollower_count%2Ccreator%2Cdescription%2Cis_following%2Ccomment_count%2Ccreated_time%3Bdata%5B*%5D.creator.vip_info&offset=0&limit=10'
# 获取收藏夹的id 和 收藏夹名。想打开收藏夹需要收藏夹的id
favoriteId = []
def getFavoriteId():
r = requests.get(url,headers=headers).json()
for i in range(0,len(r['data'])):
id = r['data'][i]['id']
title = r['data'][i]['title']
temp = [
id,
title
]
favoriteId.append(temp)
# 根据获取到的收藏夹的id生成打开收藏夹的链接
favoriteLinks = []
def getLink():
for i in range(0,len(favoriteId)):
url = 'https://www.zhihu.com/api/v4/collections/'+str(favoriteId[i][0])+'/items?offset=0&limit=20'
favoriteLinks.append(url)
# 解析收藏夹链接里面的内容,提取出内容标题和内容链接
def getConent(favoriteLink):
r = requests.get(favoriteLink,headers=headers).json()
for i in range(0,len(r['data'])):
em =r['data'][i]
result = str(em['content']['question']['title']) + str( em['content']['question']['url'])
print(result)
if __name__ == '__main__':
getFavoriteId()
getLink()
for i in range(0,len(favoriteLinks)):
print(favoriteId[i][1]+'************************************************************************************************************************')
getConent(favoriteLinks[i])
gitee提交:
有关git工具的使用
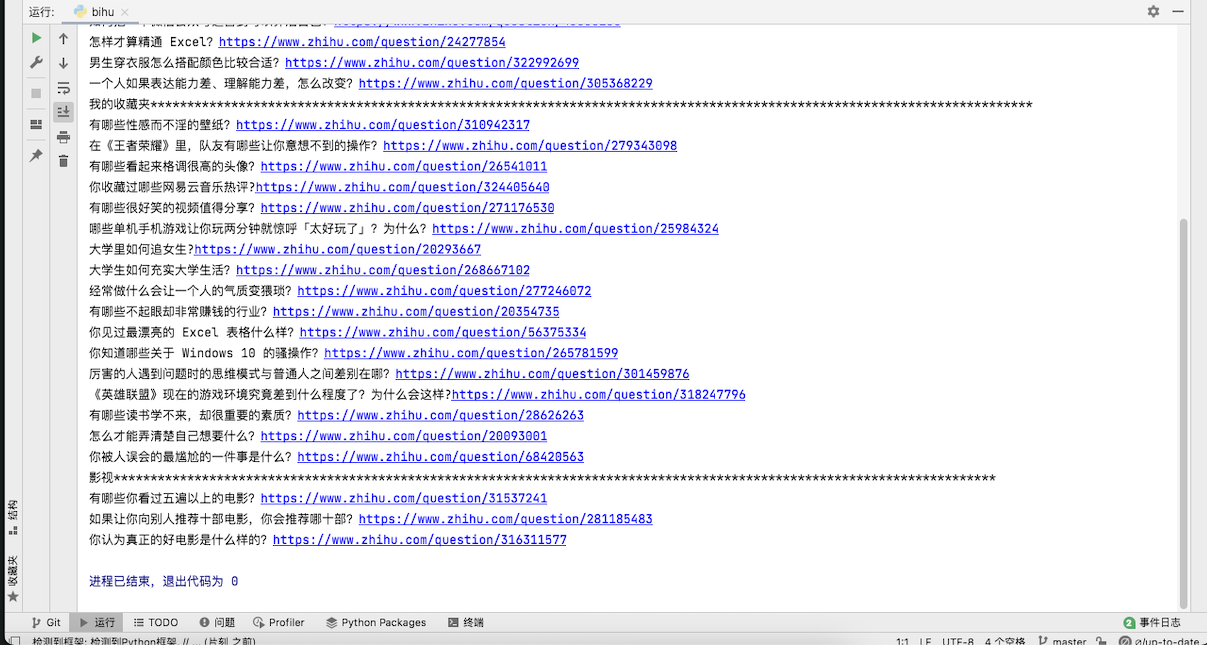
知乎收藏栏
解题思路描述
- 有了第一题的铺垫,对爬虫技术有了大致的了解上手后,想象爬取知乎数据不是轻车熟路吗?甚至不需要使用fiddler就可以轻松获取到接口链接(知乎有web版)。可以直接使用谷歌浏览器的开发者工具查看网页的请求头。但是对于实现过程中还是踩了不少小坑的。让我们开始吧!
设计实现过程
- 第一步:轻车熟路,先拿到接口链接再说!
- 第二步:对接口返回的数据进行解析
- 第三步:整合数据输出
最终效果
代码说明
添加请求头
# 添加请求头
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
url = 'https://www.zhihu.com/api/v4/people/fcc808ca04188e8fbfebd590592583ec/collections?include=data%5B*%5D.updated_time%2Canswer_count%2Cfollower_count%2Ccreator%2Cdescription%2Cis_following%2Ccomment_count%2Ccreated_time%3Bdata%5B*%5D.creator.vip_info&offset=0&limit=10'
获取收藏夹的id 和 收藏夹名。想打开收藏夹需要收藏夹的id
# 根据接口返回的数据,发现每个收藏夹底下有一个id,经过对比后发现这个id是打开收藏夹的链接关键组成部分,想要打开收藏夹就必须获取到这个id合成链接
favoriteId = []
def getFavoriteId():
r = requests.get(url,headers=headers).json()
for i in range(0,len(r['data'])):
id = r['data'][i]['id']
title = r['data'][i]['title']
temp = [
id,
title
]
favoriteId.append(temp)
根据获取到的收藏夹的id生成打开收藏夹的链接
# 这个列表是用来放每个收藏夹的链接的,传入刚刚获取到的id列表,组合成链接后存到favoriteLinks列表中
favoriteLinks = []
def getLink():
for i in range(0,len(favoriteId)):
url = 'https://www.zhihu.com/api/v4/collections/'+str(favoriteId[i][0])+'/items?offset=0&limit=20'
favoriteLinks.append(url)
解析收藏夹链接里面的内容,提取出内容标题和内容链接
# 拿到收藏夹的链接后,我们对每个链接发送请求,根据返回的内容进行提取输出
def getConent(favoriteLink):
r = requests.get(favoriteLink,headers=headers).json()
for i in range(0,len(r['data'])):
em =r['data'][i]
result = str(em['content']['question']['title']) + str( em['content']['question']['url'])
print(result)
if __name__ == '__main__':
getFavoriteId()
getLink()
for i in range(0,len(favoriteLinks)):
print(favoriteId[i][1]+'************************************************************************************************************************')
getConent(favoriteLinks[I])
- 这里有几个小坑说一下:第一是收藏夹里的内容接口链接分为两种 。 一种是你收藏了一个相关问题(打开这个链接是去到相关问题下)第二种是你收藏了某用户的原创回答。
这两个链接返回的数据以及接口形式都不一样,不能统一处理。一开始我也是纳闷了好久,为什么爬到一半就报错,提示我keyValue值不对,然后我就想是不是返回的数据不同,一看链接都不同,果然是这样!这里需要对返回的链接进行判断属于哪一种,然后分开提取,统一输出。
反思
- 爬取知乎时大部分时间用在了数据筛选上,对正则和python的基本数据格式使用不熟练,很多都是一遍Google一遍写代码,我使用的是爬取网站返回的json数据,如果直接爬html里的内容应该会相对轻松些,拿到题目还是要先思考一下怎么做效率更高,等做到一半才发现也只能硬着头皮接着做。
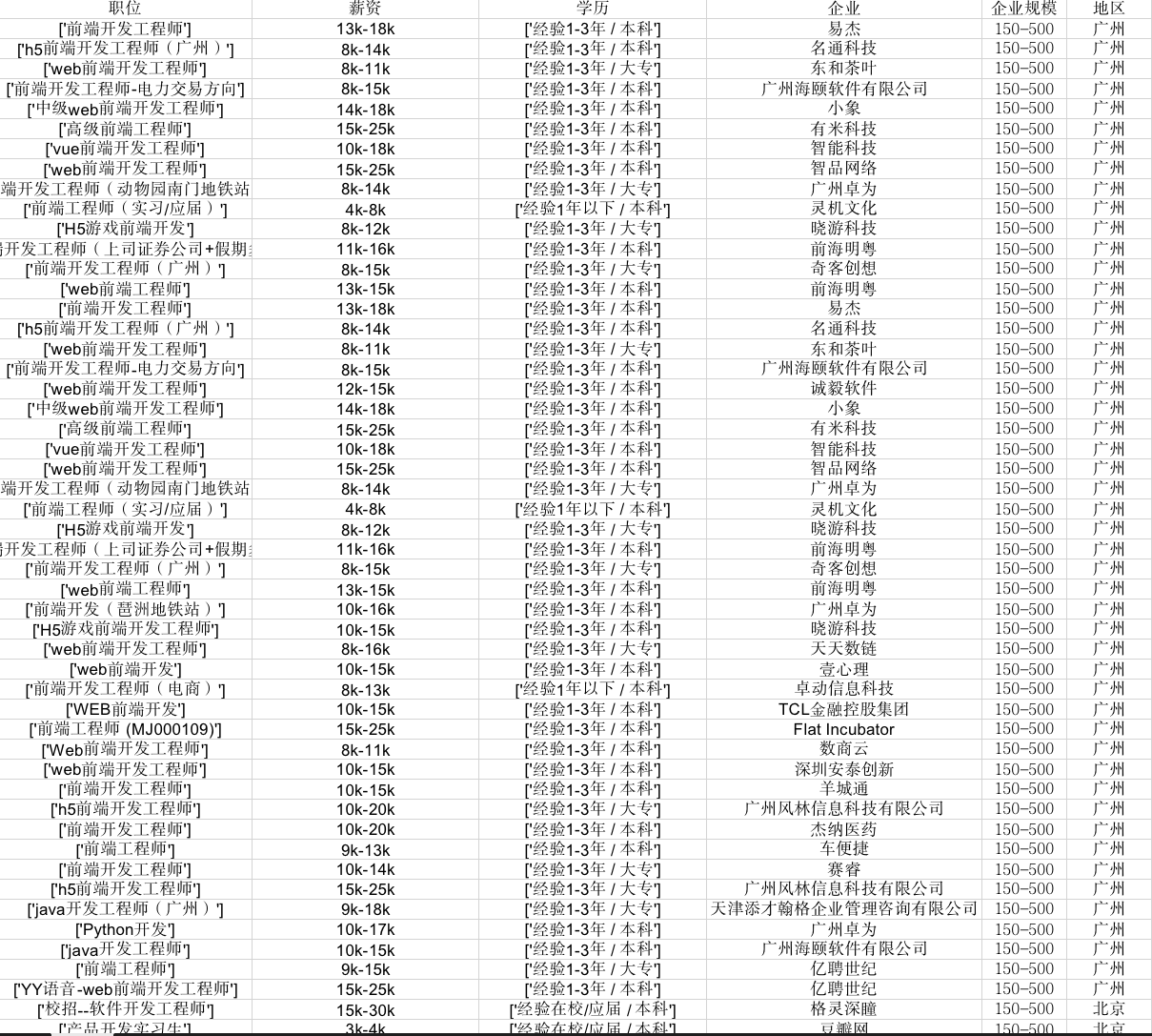
拉勾网址数据爬取
前言
- 根据前两次爬取的经验,爬虫无非就是找到网站接口返回的json数据,然后对数据进行清洗嘛!也没啥新花招。但这次就直接打脸。我在开发中工具找后台返回的json数据时就发现了个问题,压根找不到!找到的也是一大串看不懂含义的字符。这下咋办?后来Googe了一下,是后台对数据进行了加密,那咋办?我还能给它解密?抱歉我本事没那么大!但是我又想,既然页面展示的html数据我能看懂,为何不直接爬取html的数据呢?既然如此,给我爬!
设计实现过程
- 第一步:找到返回html文件的接口。
- 第二步:使用BeautifulSoup保存格式化后的html数据
- 第三步:BeautifulSoup配合正则提取数据
- 第四步:使用xlwt将数据保存到excel表格中
最终效果
代码说明
添加请求头
import re
import time
import requests
import urllib3
from bs4 import BeautifulSoup
import xlwt
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# url='https://www.lagou.com/wn/jobs?gj=%E5%9C%A8%E6%A0%A1%2F%E5%BA%94%E5%B1%8A&gm=150-500%E4%BA%BA&kd=%E5%89%8D%E7%AB%AF&fromSearch=true&city=%E7%A6%8F%E5%B7%9E&pn=1'
url = 'https://www.lagou.com/wn/jobs?pn=1&gj=3%E5%B9%B4%E5%8F%8A%E4%BB%A5%E4%B8%8B&gm=150-500%E4%BA%BA&kd=%E5%89%8D%E7%AB%AF&fromSearch=true&city=%E5%B9%BF%E5%B7%9E'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
}
date = {
'__lg_stoken__':'d68685c3b049a61aa2b859d085106a80c6f2e695613c2d7e5ae7073c19008bdf69fb5e4a6eece2622e02627ebe2859a5222371409d168a503f115ef6c239a46b2348f92696a3',
'X_HTTP_TOKEN':' 42daf4b72327b2810802347461bf5e71415983ed09',
'JSESSIONID':'ABAAAECABFAACEA8440B880856F1D2E85C1AEE70BE1EA44',
'WEBTJ-ID':'20220316200124-17f929aac8f5f0-0946ee9b10d426-113f645d-3686400-17f929aac90f74',
'sajssdk_2015_cross_new_user':'1',
'sensorsdata2015session':'%7B%7D',
'sensorsdata2015jssdkcross':'%7B%22distinct_id%22%3A%2217f929aafd7cc8-0a64961186fcef-113f645d-3686400-17f929aafd816e7%22%2C%22first_id%22%3A%22%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22MacOS%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2299.0.4844.51%22%7D%2C%22%24device_id%22%3A%2217f929aafd7cc8-0a64961186fcef-113f645d-3686400-17f929aafd816e7%22%7D'
}
对接口链接进行拼接
urlLists = []
def urlList():
for i in range(1,7):# 获取7个
u = 'https://www.lagou.com/wn/jobs?pn='+str(i)+'&gm=150-500%E4%BA%BA&cl=false&fromSearch=true&labelWords=sug&suginput=%E5%90%8E%E7%AB%AF&kd=%E5%90%8E%E7%AB%AF%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88&city=%E4%B8%8A%E6%B5%B7'
urlLists.append(u)
def getUrls(urls):
result=requests.get(urls,cookies=date,headers=headers,verify=False)
result.encoding='utf-8'
# f2 = open('date01.html','w',encoding='utf-8')
# f2.write(result.text)
htmlDate = result.text
soup = BeautifulSoup(htmlDate,'lxml')
return soup
提取数据
# 数据粗清洗,返回一个列表,列表中的数据也是一个列表
def cleaDateFirst(soup):
li = soup.findAll(class_='item-top__1Z3Zo')
return li
def clearFinal(soup):
# 职位
position = []
positionTemp = soup.findAll(class_='p-top__1F7CL')
for i in positionTemp:
s = re.findall(r'<a>(.*)<!',str(i.a))
position.append(s)
# 薪资
money = []
money__3Lkgq = soup.findAll(class_='money__3Lkgq')
for i in money__3Lkgq:
money.append(i.string)
# 学历
education = []
pbom__JlNur = soup.findAll(class_='p-bom__JlNur')
for i in pbom__JlNur:
e = re.findall(r'</span>(.*)</div>',str(i))
education.append(e)
# 公司
companyname = []
companyname__2SjF =soup.findAll(class_='company-name__2-SjF')
for i in companyname__2SjF:
companyname.append(str(i.a.string))
return position, money, education, companyname
反思
做这个一开始还是挺懵的,不知道怎么提取html数据,不知道怎么将数据保存到excel,甚至复习了一遍正则。一遍查资料,一遍敲代码,现学现用,硬是被我拼凑了出来。遇到了不少问题,幸运的是我所生活的这个年代,已经有很多前人写好了轮子,你只需会用即可!很多坑也有人替你躺过了,你只需避开,不用在一个问题上死磕几小时,站在前人的肩膀上开发轻松了不少,这里也感谢那些大牛写的博客,为我提供了宝贵的经验,作为开发人员写博客不仅仅能为自己标记踩过的坑,同时也给其它开发中提供了一份宝贵的经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号