23.4.23 文献总结——efficient model
CVPR23 RIFormer: Keep Y our Vision Backbone Effective But Removing Token Mixer
主要贡献如下:
1.提出简单的视觉网络架构,可以用于实际应用。
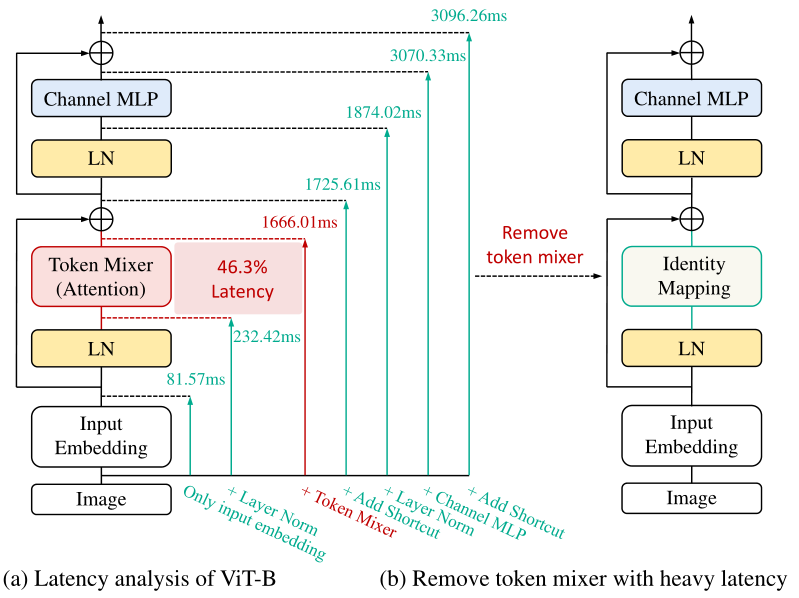
2.使用re-parameterizing提出了一个没有token-mixer的视觉网络,RIFormer,在提高推理效率的同时,提高了对归纳偏置的建模能力。
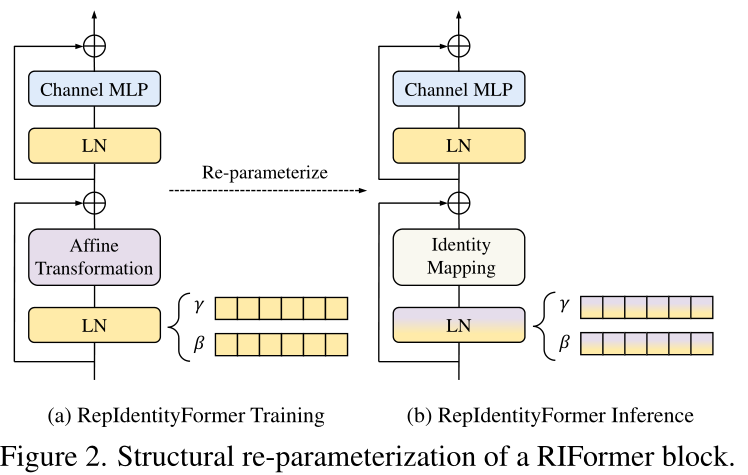
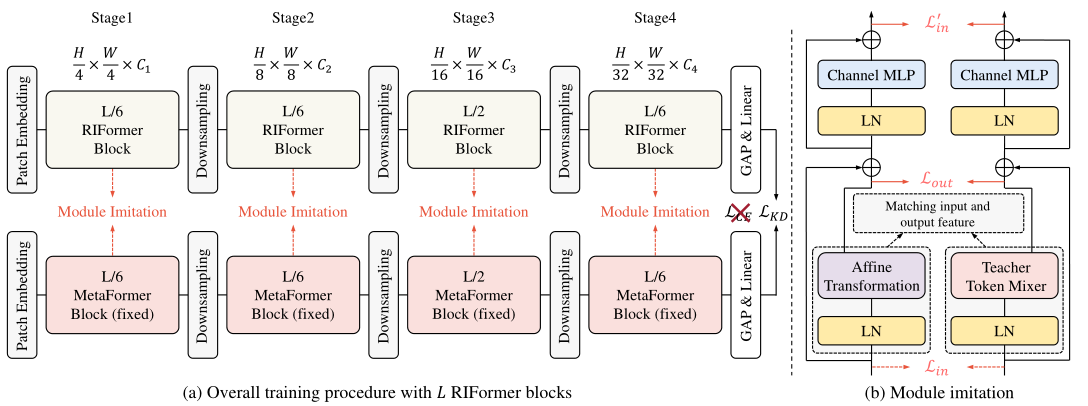
3.提出了有效的模型蒸馏策略,在保持性能的同时消除了token-mixer。
CVPR23 FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
主要贡献如下:
1.提出fastvit, 使用structural reparameterization来获得更少的内存成本和更好的性能。
用 reparameterization 去掉了跳跃连接。使用 Linear Train-time Overparameterization,在复杂度提高较少的情况下获得性能提升。在网络前期用大卷积核来扩大视野域。
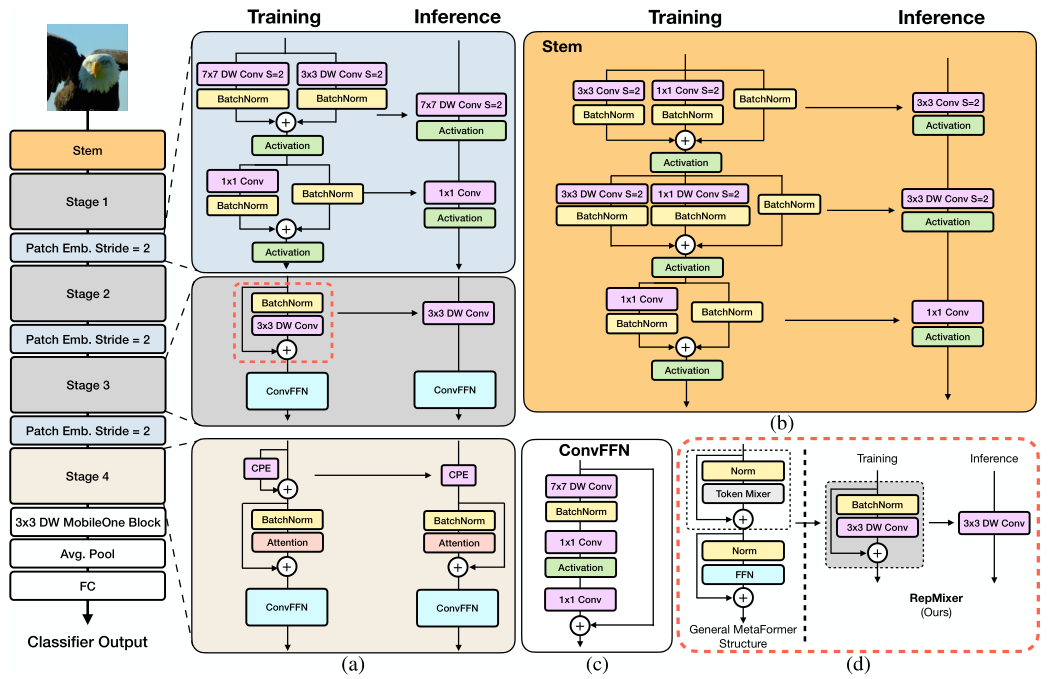
2.在移动设备和GPU上有最少的延迟。
3.对corruption和out-of-distribution的样本具有鲁棒性。
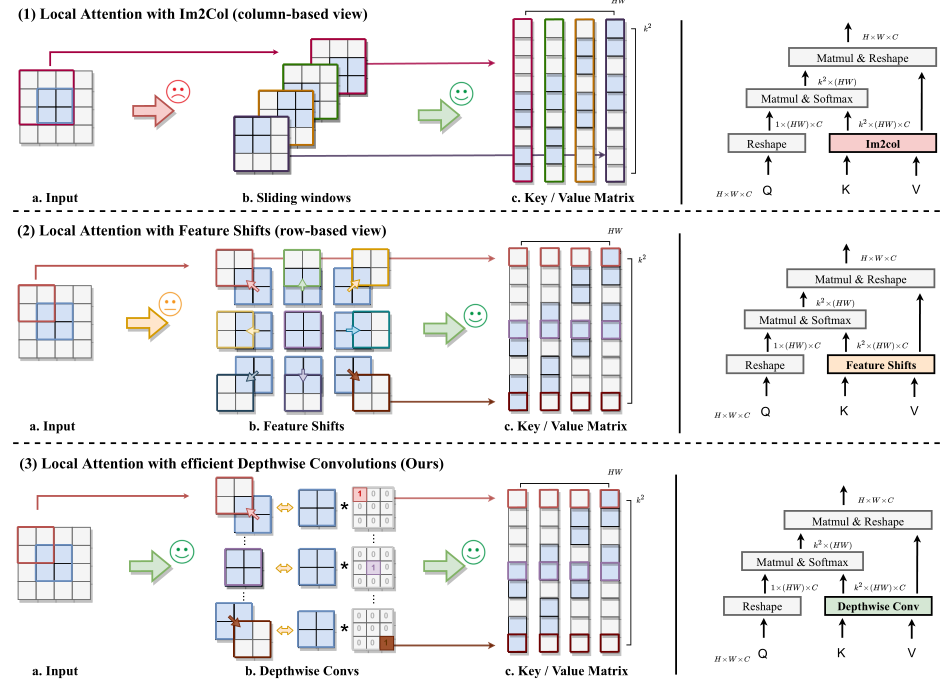
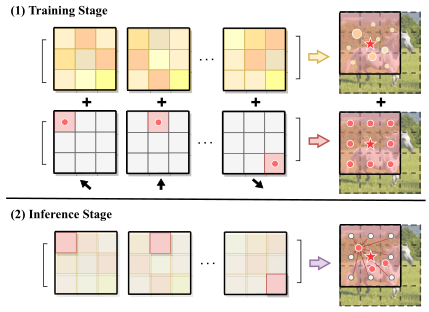
CVPR23 Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention
提出了新的局部注意力模块 Slide Attention。
CVPR22 Residual Local Feature Network for Efficient Super-Resolution
主要贡献如下:
1.研究了RFDN的速度瓶颈,提出了Residual Local Feature Network,在不牺牲SR精度的情况下,使模型更加紧凑而且提高了推理速度。
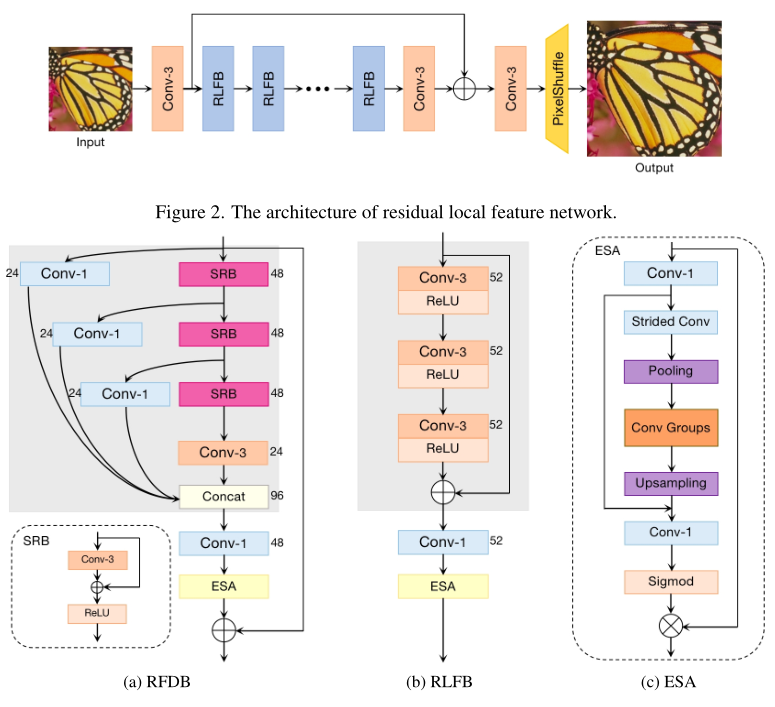
2.使用了对比学习并进行分析,观察到浅层特征对于面向psnr的模型至关重要。

3.提出了多阶段热启动训练策略。利用之前阶段的训练权重来提高SR性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号