Attention is all you need (一)公式和图表解读笔记
2017年,Google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。是transformer在NLP中应用的开山之作。transformer成为了独立于cnn的一种网络架构。
1、Motivation:
使用attention机制,不使用rnn和cnn,并行度高;
通过attention,抓长距离依赖关系比rnn强。
2、创新点:
通过self-attention,自己和自己做attention,使得每个词都有全局的语义信息;
由于 Self-Attention 是每个词和所有词都要计算 Attention,所以不管他们中间有多长距离,最大的路径长度也都只是 1。可以捕获长距离依赖关系;
提出multi-head attention,可以看成attention的ensemble版本,不同head学习不同的子空间语义。
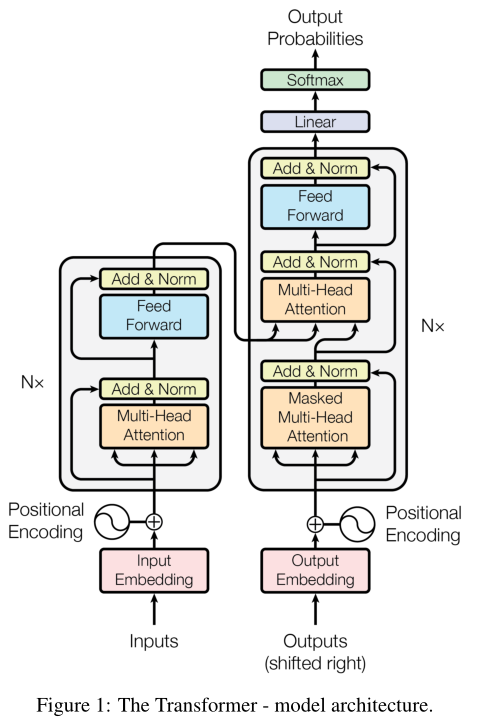
上图为网络架构。左边为encoder,右边为decoder。
Attention is all you need中的要点:1.transformer中的self-attention;2.位置编码;3.网络编码模块;4.网络解码模块;
(一)self-attention
参考:教你最快最好的来理解Transformer-Attention is All You Need_哔哩哔哩_bilibili #这个视频深入浅出地解释了self-attention机制,对attention is all you need这篇文章的解读也很细致。
self-attention设计q,k,v的计算。
q : query (to match others) qi=Wqai
k : key (to be matched) ki=Wkai
v : query (to match others) vi=Wvai
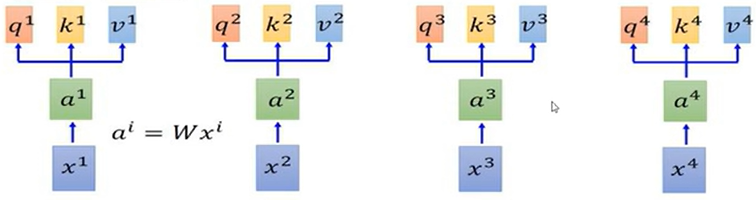
简单来说,就是将输入x通过线性变换生成q,k,v。
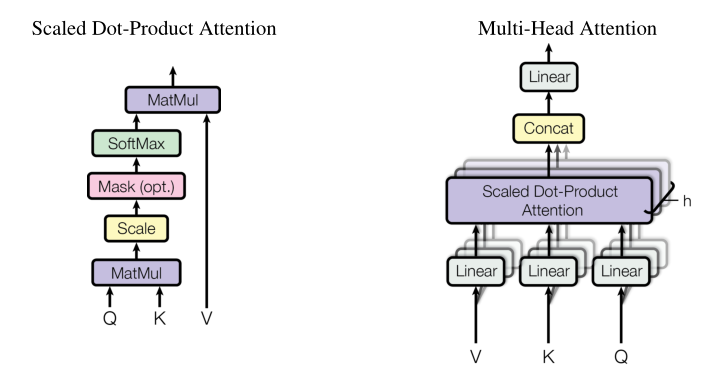
下面从网络架构图中拆解出multi-head attention模块,再从multi-head attention模块中拆解出scaled dot-product attention模块进行解读。如下图所示。
scaled dot-product attention模块中的mask模块在encoder中是没有的,在decoder中是有的。
上图可以描述为如下公式,这里的Q,K,V分别是由qi,ki,vi拼接成的矩阵,dk是q和k的维度。
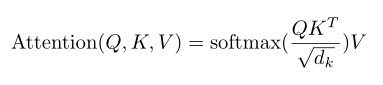
更为形象的理解可以去看推荐的视频。
上面的讨论只针对其中一个attention。那如何理解multi-head attention多头注意力呢?
多头注意力把Q,K,V经过多次不同的线性投影得到不同的head,再把多个head进行concat,再乘以一个Wo进行线性投影得到最终的MultiHead(Q,K,V)。

每个head关注到的信息是不同的。比如在一个汉译英的机器翻译任务中,可以看到一个关注到整体的联系,一个专注到细节的联系。
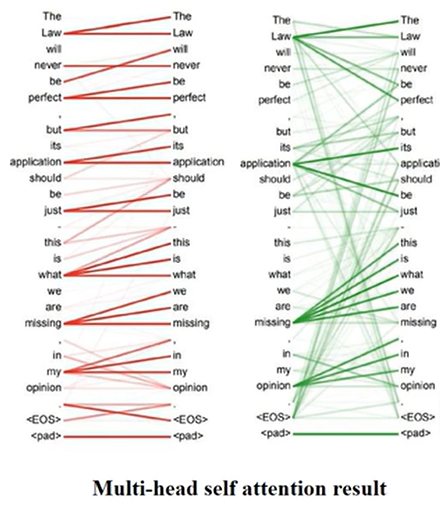
(二)positional encoding
参考:组会前抱佛jio/动画讲CV/Positional embeddings/Attention is all you need/双语字幕_哔哩哔哩_bilibili #positional embedding的形象讲解
embeding如果采用one-hot形式,在较长的句子中就会把维度拉到很高造成维度灾难。同时one-hot也无法体现词与词之间的联系,例如在embedding的向量空间中,话筒和麦克应该是接近的。
而位置编码在embedding的向量空间中提供的其实是一种指向性。在网络架构图中,positional encoding会与input embedding和output embedding相加。比如input embedding是ktv,那么input embedding与positional encoding相加后,就会被拉向距离sing更近的地方(ktv和sing这两个词有联系且在句子中通常距离较近)。
至于为什么采用sinx,cosx,sin2x,cos2x…交替编码的形式呢?首先是余弦和正弦函数只在-1和1之间取值,在positional encoding中不会产生很大的值。可以联想傅里叶变化,多个不同频率的正弦和余弦就可以确定一个信号了,这里采用这种编码形式也是保证了positional encoding的唯一性。
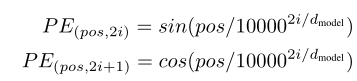
(三)encoder block and decoder block
参考:【必知必会-2】残差连接 - 知乎 (zhihu.com)
encoder中的Add表示残差连接(Residual Connection),用于防止网络退化和梯度消失。
思想为始终保留了原始信息,还增加了网络中获取的新知识。试想如果一个网络的最优层数为m,但实际训练中使用了m+n层。那么后面这n层其实是没用的,最好就是保持住前面的结果。但对于神经网络来说,保持不变是比较困难的(比如让xL=xL-1比较困难)。但如果描述成如下形式,让网络学习让F=0就比较容易了。
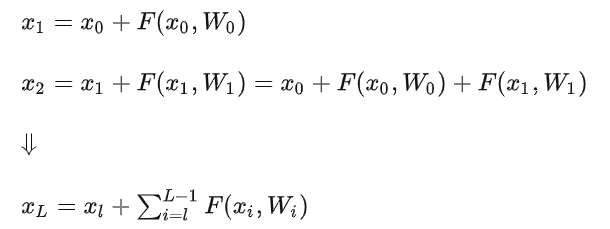
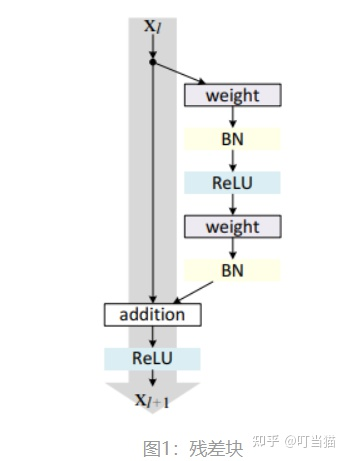
参考:(18条消息) BatchNorm和LayerNorm的区别_DataAlgo的博客-CSDN博客_layernorm
encoder中的norm为layer-norm。
通常有batch-norm和layer-norm。
BatchNorm: 对一个batch-size样本内的每个特征做归一化
LayerNorm: 针对每条样本,对每条样本的所有特征做归一化
简单举例:
假设现在有个二维矩阵:行代表batch-size, 列表示样本特征
BatchNorm就是对这个二维矩阵中每一列的特征做归一化,也就是竖着做归一化
LayerNorm就是对这个二维矩阵中每一行数据做归一化
相同点: 都是在深度学习中让当前层的参数稳定下来,避免梯度消失或者梯度爆炸,方便后面的继续学习。
不同点:如果你的特征依赖不同样本的统计参数,那BatchNorm更有效, 因为它不考虑不同特征之间的大小关系,但是保留不同样本间的大小关系。Nlp领域适合用LayerNorm, CV适合BatchNorm。对于Nlp来说,它不考虑不同样本间的大小关系,保留样本内不同特征之间的大小关系。
什么是shifted right 向右移动呢?
比如encoder输入机器学习。decoder input输入首先为代表begin的符号\,再输出machine。下一步 decoder input输入就为\machine,再输出learing。

decoder中的multi-head attention多了一个masked步骤,这是因为在训练时的output都是ground truth。比如在输入I have a的时候,就把cat给mask掉。确保训练第i个位置的时候不会接触到未来的信息。
以上就是我关于这篇论文所做的笔记,还有很多地方没有理解透。如果有说错的请告诉我!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号