
022304105叶骋恺数据采集第二次作业
作业1
代码与运行结果
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {
"福州": "101230101",
"北京": "101010100",
"上海": "101020100",
"广州": "101280101",
"深圳": "101280601"
}
def forecastCity(self, city):
url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml"
data = urllib.request.urlopen(urllib.request.Request(url, headers=self.headers)).read()
data = UnicodeDammit(data, ["utf-8", "gbk"]).unicode_markup
soup = BeautifulSoup(data, "lxml")
if ul := soup.find("ul", class_="t clearfix"):
for li in ul.find_all("li", recursive=False):
date= li.select_one('h1').text
weather=li.select_one('p.wea').text
tem = li.select_one('p.tem')
temp = f"{tem.span.text}/{tem.i.text}" if tem.span else (tem.i.text if tem.i else "未知")
self.db.insert(city, date, weather, temp)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()

作业心得
通过这个天气爬虫项目,我深入掌握了网页数据抓取与解析的全流程,不仅学会了使用BeautifulSoup精准提取目标信息,还理解了如何设计合理的数据库结构来存储数据。在解决中文编码和异常处理的过程中,我的实际问题解决能力得到了显著提升。同时,对于温度标签的处理要更加留意,有些结构不一致,就要正确使用if/else的方法分开讨论
作业2
代码与运行结果
def main():
col_config = [('left', True), ('left', False), ('right', True), ('right', True), ('right', True), ('right', True),
('right', True), ('right', True)]
plates = {"沪深A股": "m:1+t:2+f:!2,m:1+t:23+f:!2", "创业板": "m:0+t:81+s:262144+f:!2"}
for plate, secid in plates.items():
all_stocks, page = [], 1
def to_num(key):
val = item.get(key)
if isinstance(val, (int, float)): return val
if isinstance(val, str):
try:
return float(val)
except:
return 0
return 0
while page < 5:
raw_data = parse_js(save_js(secid, plate, page))
page_stocks = []
for item in raw_data:
f2, f3, f4, f6, f7 = map(to_num, ["f2", "f3", "f4", "f6", "f7"])
page_stocks.append([
str(item.get("f12", "")), str(item.get("f14", "")),
f"{f2 / 100:.2f}" if f2 else "-", f"{f3 / 100:.2f}%" if f3 else "-",
f"{f4 / 100:.2f}" if f4 else "-", str(item.get("f5", "")),
f"{int(f6) / 1000000:.1f}万" if f6 else "-", f"{f7 / 100:.2f}%" if f7 else "-"
])
all_stocks.extend(page_stocks)
page += 1
if all_stocks:
max_w = get_max_col_widths(all_stocks)
print(f"\n【{plate}】结果(共{len(all_stocks)}条):")
headers = ["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "涨幅"]
max_idx_w = str_width(str(len(all_stocks))) + 2
h_line = align(headers[0], max_idx_w, 'right', True) + " "
h_line += " ".join(align(headers[i], max_w[i - 1], *col_config[i - 1]) for i in range(1, 9))
print(h_line)
for idx, stock in enumerate(all_stocks, 1):
row = align(str(idx), max_idx_w, 'right', True) + " "
row += " ".join(align(stock[i], max_w[i], *col_config[i]) for i in range(8))
print(row)
export_excel(plate, all_stocks)

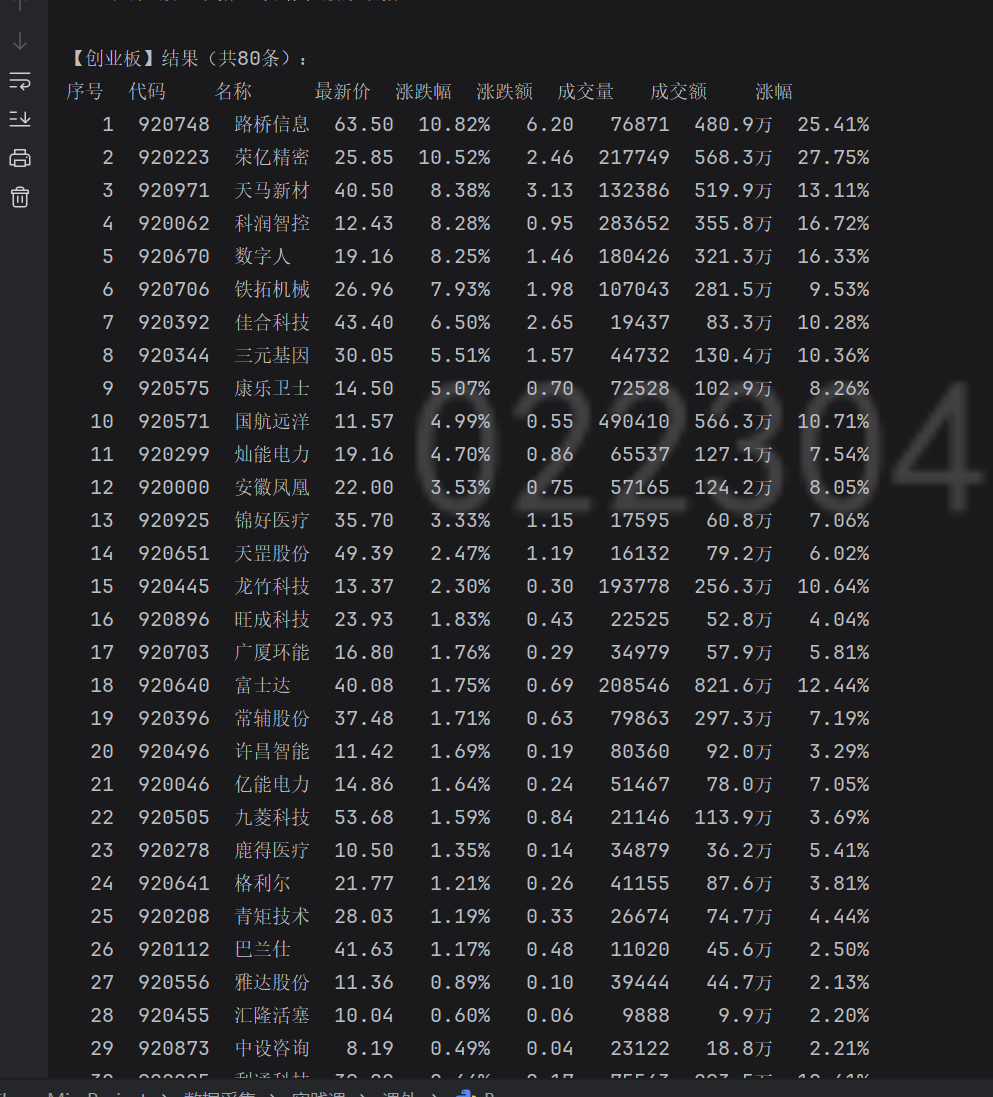
作业心得
通过这次实验,让我对数据处理的 “全流程思维” 有了更具体的认知:从用to_num函数统一清洗接口返回的非标准化数值(解决字符串转数字异常、空值占位问题),到通过col_config和max_w实现表格的结构化对齐,再到用字典plates配置板块信息实现迭代爬取,每个环节都在平衡 “功能实现” 与 “健壮性”。尤其是隐形的异常处理和输出细节把控,让我意识到:数据类工具的价值不仅在于获取和展示信息,更在于通过细节设计,让数据处理过程更稳定、结果更易读,而这种 “细节思维” 正是提升代码实用性的关键。
作业3
代码与运行结果
import urllib.request
import re
import ssl
import execjs
import sqlite3
from datetime import datetime
url = "https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js"
def extract_data(params, body, args):
args_py = args.replace('false', 'False') \
.replace('true', 'True') \
.replace('null', 'None')
ctx = execjs.compile(f"function f({params}){{{body}}};")
result = ctx.call("f", *eval(args_py))
return [
{'排名': u.get('ranking'), '学校': u.get('univNameCn'),
'省市': u.get('province'), '类型': u.get('univCategory'),
'总分': u.get('score')}
for u in result['data'][0]['univData']
]
def init_database():
conn = sqlite3.connect('university_rankings.db')
cursor = conn.cursor()
cursor.execute(
'CREATE table if not exists bcur_rankings (id integer primary key autoincrement, ranking text, university_name text, province text, category text, score text, crawl_time datetime)')
conn.commit()
conn.close()
def save_to_database(univs):
conn = sqlite3.connect('university_rankings.db')
cursor = conn.cursor()
crawl_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
data_list = [
(u['排名'], u['学校'], u['省市'], u['类型'], u['总分'], crawl_time)
for u in univs
]
cursor.executemany('''INSERT INTO bcur_rankings(ranking, university_name, province, category, score, crawl_time)VALUES (?, ?, ?, ?, ?, ?)''', data_list)
conn.commit()
print(f"\n成功保存 {len(univs)} 条数据到数据库")
conn.close()
def main():
init_database()
req = urllib.request.Request(url)
data = urllib.request.urlopen(req).read().decode()
m = re.search(r'__NUXT_JSONP__.*?function\(([^)]*)\){([\s\S]*)}\(([^)]*)\)', data)
univs = extract_data(m.group(1), m.group(2), m.group(3))
print(f"{'排名':<4} {'学校':<16} {'省市':<6} {'类型':<8} {'总分'}")
print("-" * 50)
for u in univs:
school = u['学校']
school_len = len(school)
if 5 <= school_len <8:
school_padding = 11
elif school_len == 4:
school_padding = 12
else:
school_padding = 10
print(
f"{str(u['排名']):<6} "
f"{school:<{school_padding}} "
f"{u['省市']:<8} "
f"{u['类型']:<10} "
f"{u['总分']}"
)
save_to_database(univs)
if __name__ == "__main__":
main()
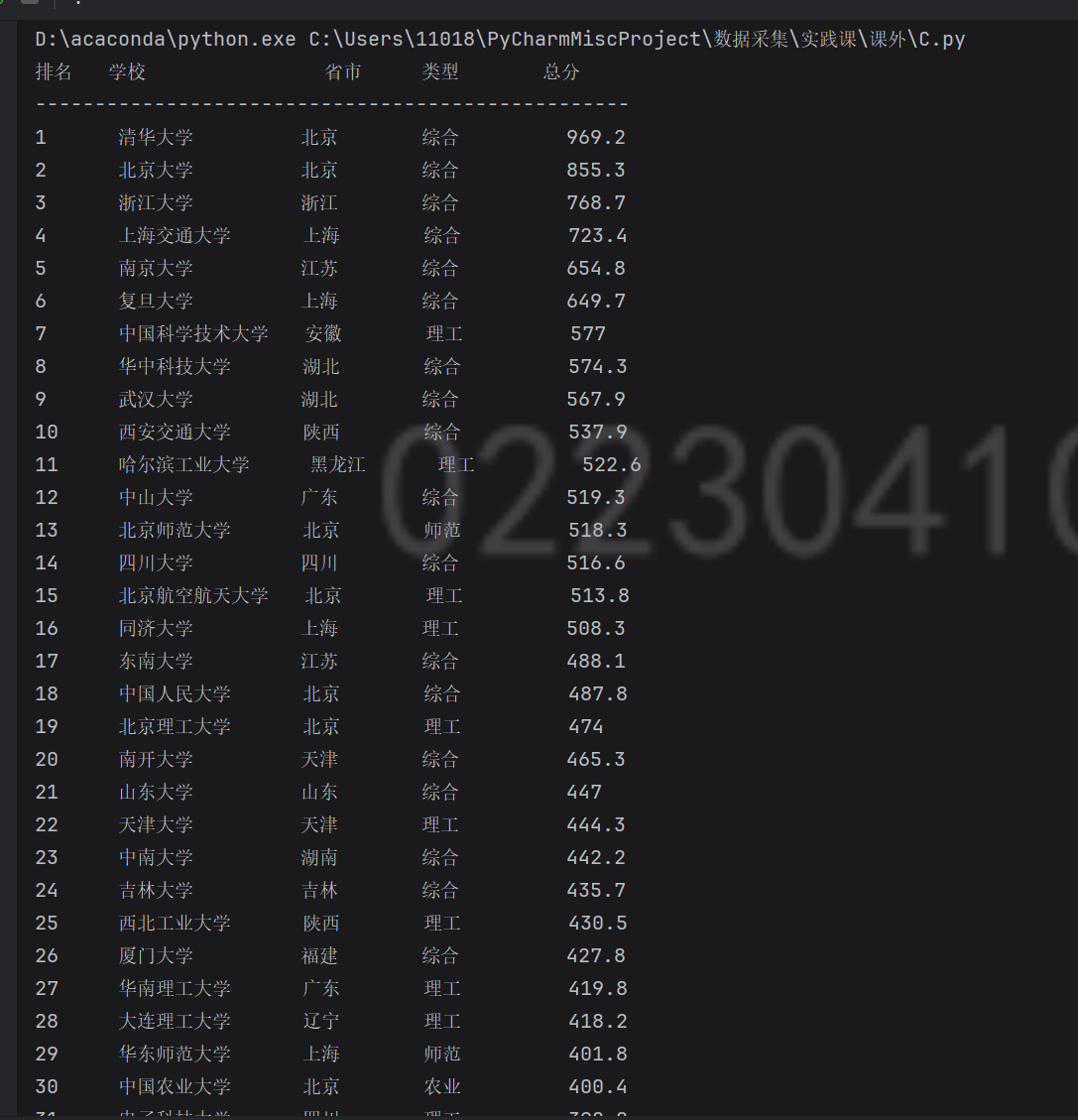

作业心得
这段代码的编写过程,让我对动态数据爬取与结构化存储”有了更深刻的实践认知。从解析远程 JS 文件中提取关键函数与参数,到用 execjs 执行 JavaScript 逻辑获取数据,再到将结果标准化后存入数据库,整个流程环环相扣,每个环节都体现着 “适配与转化” 的思维 —— 面对非直接暴露的数据,需要逆向解析代码逻辑;面对异构数据,需要统一结构便于后续处理;面对持久化需求,需要设计合理的数据库表结构并关联爬取时间,让数据可追溯。其中,用正则提取 JS 中的函数参数、体和调用参数的部分尤为巧妙,既避开了复杂的页面渲染分析,又精准定位了数据生成逻辑。而打印时根据学校名称长度动态调整占位符,以及数据库设计中增加自增 ID 和爬取时间,则体现了对细节的打磨 —— 数据不仅要能获取,更要易读、可管理。
代码地址:https://gitee.com/xiaoyeabc/2025_crawl_project/tree/master/作业2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号