

Redis Zset 类型全解析 - 指南
文章目录
- 1.引言
- 2.Zset 类型的核心特性
- 3.Zset 类型核心命令
- 4.Zset 类型的底层编码
- 5. Zset 类型的核心应用场景
- 6.小结
1.引言
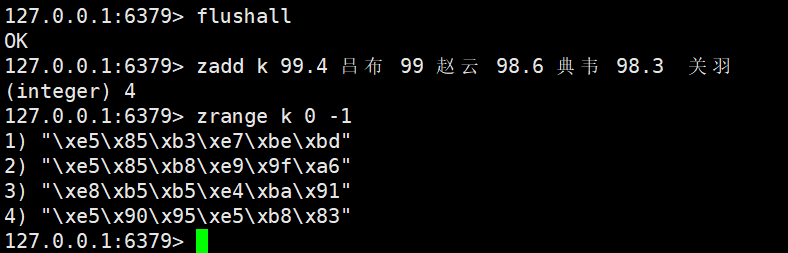
在 Redis 常用数据类型中,Zset(有序集合)是兼顾 “元素唯一性” 与 “排序性” 的核心类型 —— 它在 Set “去重” 基础上,为每个元素绑定一个score(分数),通过分数实现 “升序 / 降序排列”。从热搜排行榜、游戏天梯到成绩排名,Zset 凭借高效的排序与查询能力,成为分布式系统中 “有序数据管理” 的关键器具。本文将从核心特性出发,逐条拆解命令、解析底层编码,再结合实际业务场景说明应用逻辑,帮你吃透 Zset 类型的所有关键知识点。
2.Zset 类型的核心特性
“Set 的去重能力” 与 “排序需求” 的结合就是Zset 的设计
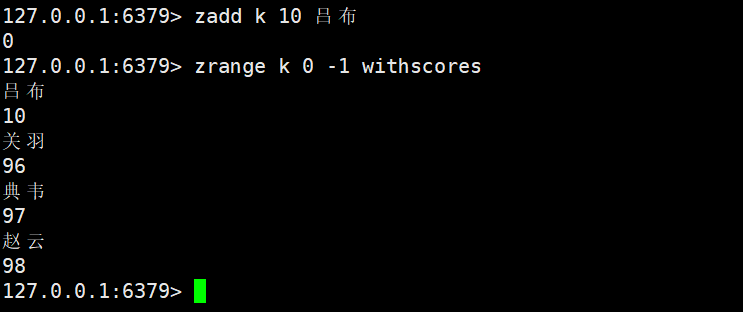
- 元素唯一性:与 Set 一致,Zset 中不会存在重复member(元素),即使重复添加(如zadd zset1 10 a 20 a),最终也只会保留 1 个a,且score以最后一次添加为准;
- 排序性:每个member对应一个score(浮点类型),Zset 会按score自动排序(默认升序);若score相同,则按member的 “字典序”(二进制存储顺序)排序;
- 双重查询能力:支持两种查询维度 —— 按score范围查询元素(如 “分数 100-200 的用户”),或按排名(下标)查询元素(如 “前 10 名用户”)。
与 Set、List 的关键差异
| 类型 | 元素唯一性 | 排序性 | 核心适用场景 |
|---|---|---|---|
| Zset | 唯一 | 按score排序(升 / 降) | 排行榜、带权重的有序材料 |
| Set | 唯一 | 无序 | 去重存储、关系计算(交集) |
| List | 可重复 | 按插入顺序排序 | 有序数据、消息队列 |
3.Zset 类型核心命令
3.1 元素添加与基础查询:zadd、zrange
zadd
zadd key [NX|XX] [LT|GT] [CH] [INCR] score member [score member ...]
- 功能:向 Zset 中添加 1 个或多个 “score+member” 对;支持多种可选参数,适配不同业务需求。
- 关键参数说明:
- NX:仅当member不存在时添加,存在则忽略;
- XX:仅当member存在时更新score,不存在则忽略;
- LT:仅当新score小于原score时更新;
- GT:仅当新score大于原score时更新;
- CH:返回值具备 “新增元素个数 + 更新score的元素个数”(默认仅返回新增个数);
- INCR:将score视为增量(如zadd zset1 INCR 2 a,若a已存在,score+2)。
- 时间复杂度:O (logN)(N 为 Zset 元素总数,需找到score对应排序位置)。
- 返回值:默认返回 “新增元素个数”;指定CH时返回 “新增 + 更新元素总数”;指定INCR时返回更新后的score。
zrange
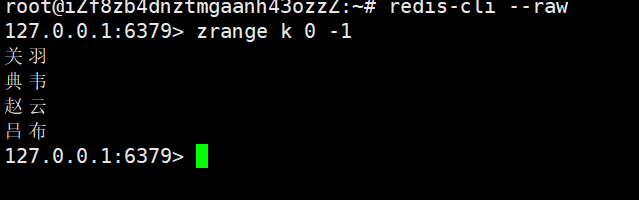
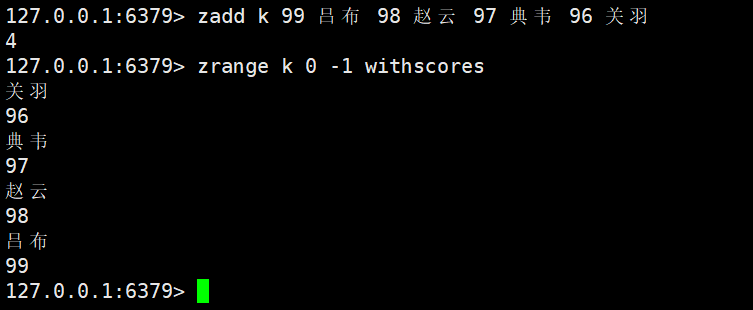
zrange key start stop [WITHSCORES]
- 机制:按 “升序” 获取 Zset 中[start, stop]排名区间的元素(start=0为第一名,stop=-1为最后一名);指定WITHSCORES时,同时返回元素的score。
- 时间复杂度:O (logN + M)(N 为 Zset 总数,M 为查询区间的元素个数)。
- 返回值:默认返回元素列表;指定WITHSCORES时,返回 “元素 1+score1 + 元素 2+score2” 的列表。
nx: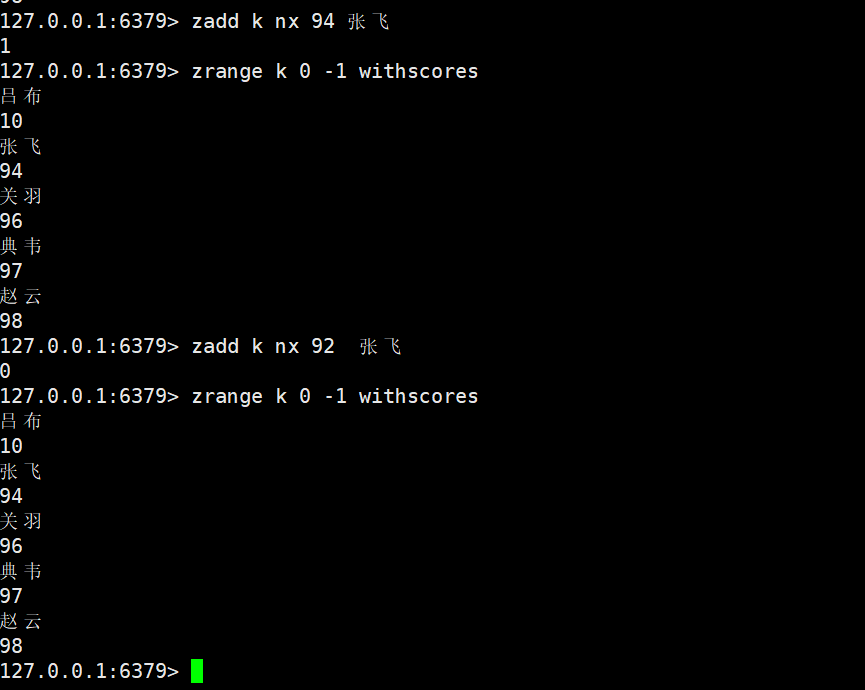
xx: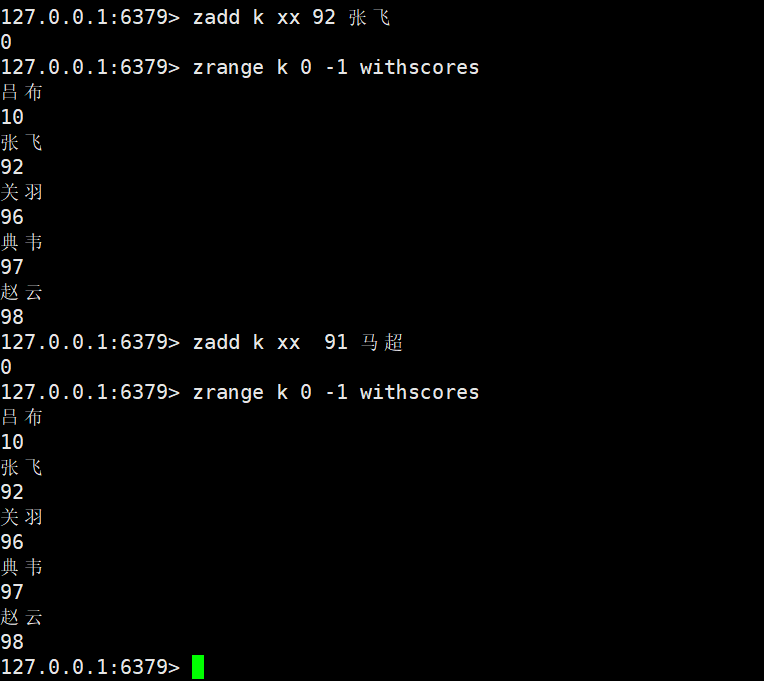
LT: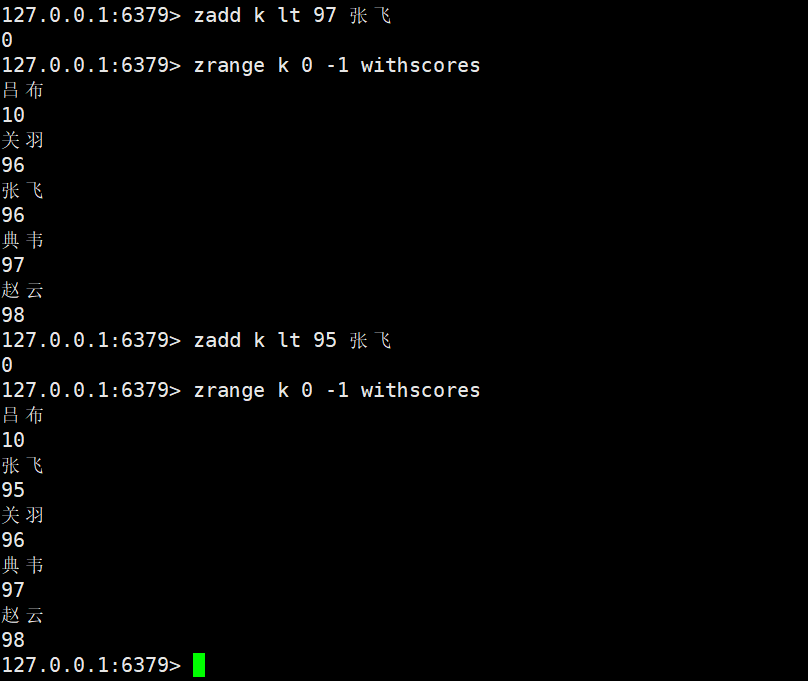
GT: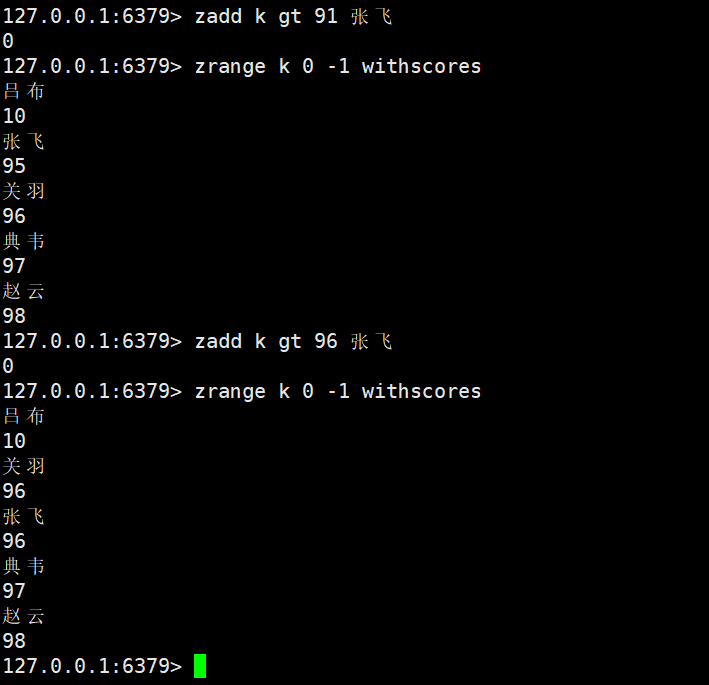
CH: 默认情况下zadd返回的是本次新增的元素个数。指定CH后,返回值还涵盖本次更新的元素个数
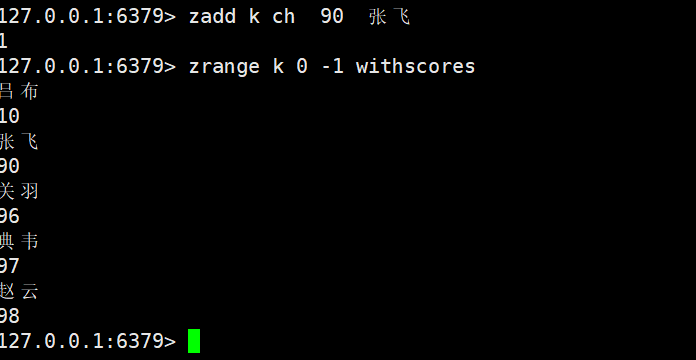
INCR: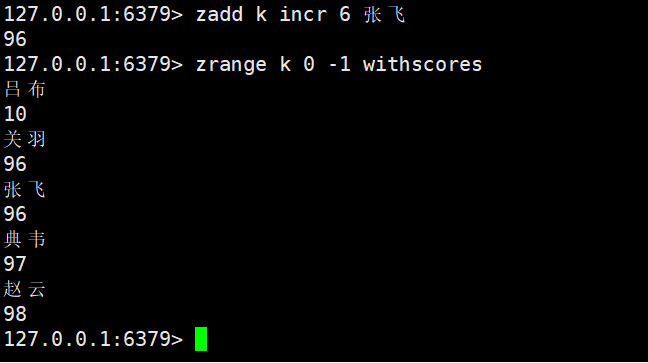
3.2 元素计数:zcard、zcount
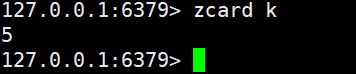
zcard
zcard key
- 功能:获取 Zset 中的元素总个数(类似 Set 的scard)。
- 时间复杂度:O (1)(底层维护元素计数器,直接返回)。
- 返回值:元素个数(Key 不存在时返回 0)。
zcount
zcount key min max
- 功能:获取 Zset 中score在[min, max]区间内的元素个数(默认闭区间,可通过(min或max)表示开区间)。
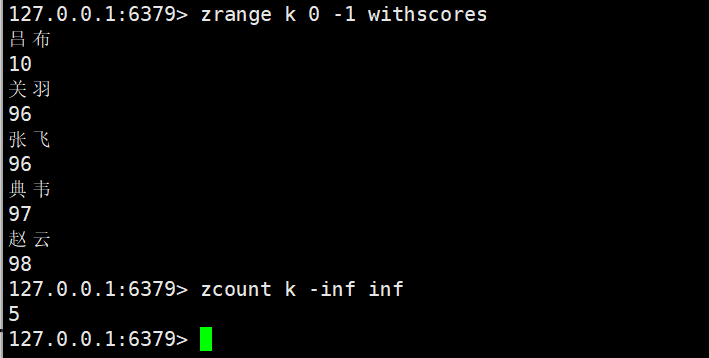
- 特殊符号:inf表示正无穷(如+inf),-inf表示负无穷(如-inf),可用于 “所有小于 X” 或 “所有大于 Y” 的场景。
- 时间复杂度:O (logN)(通过score定位区间边界,无需遍历元素)。
- 返回值:区间内的元素个数
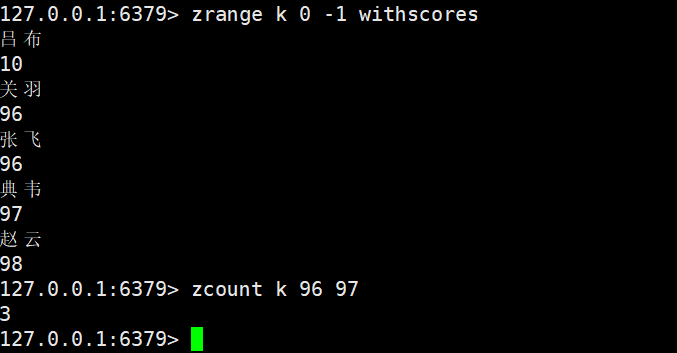
开区间表示:
96变成开区间
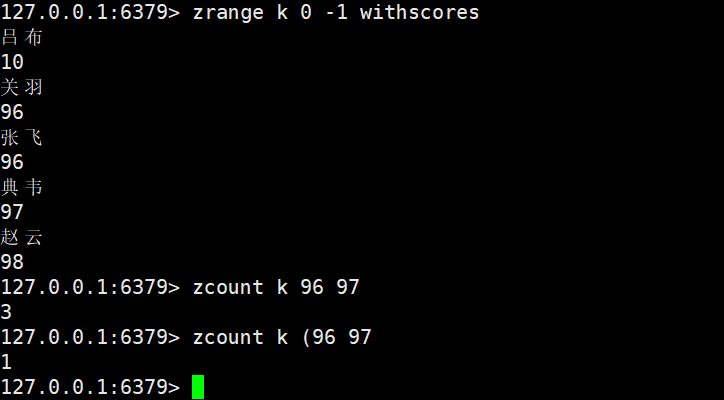
97 变开区间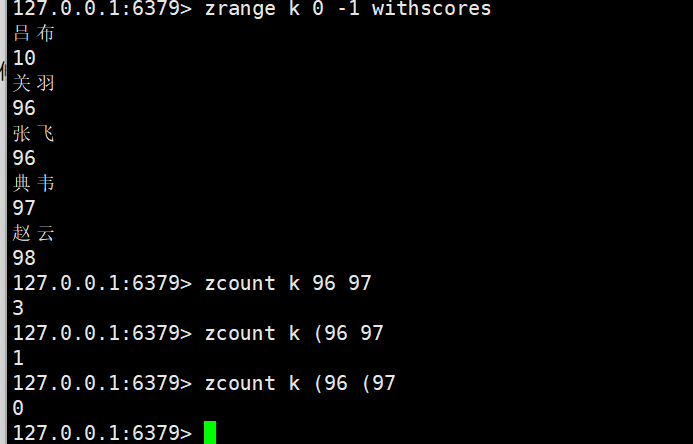
这个设定比较反直觉,不过考虑到兼容性(在其他广泛利用的软件也采用了这样的设定)一改全要改,成本高
min、max可以写成 浮点数。
在浮点数中: inf:无穷大 -inf:负无穷大
3.3 排序与排名查询:zrevrange、zrangebyscore、zrank、zrevrank、zscore
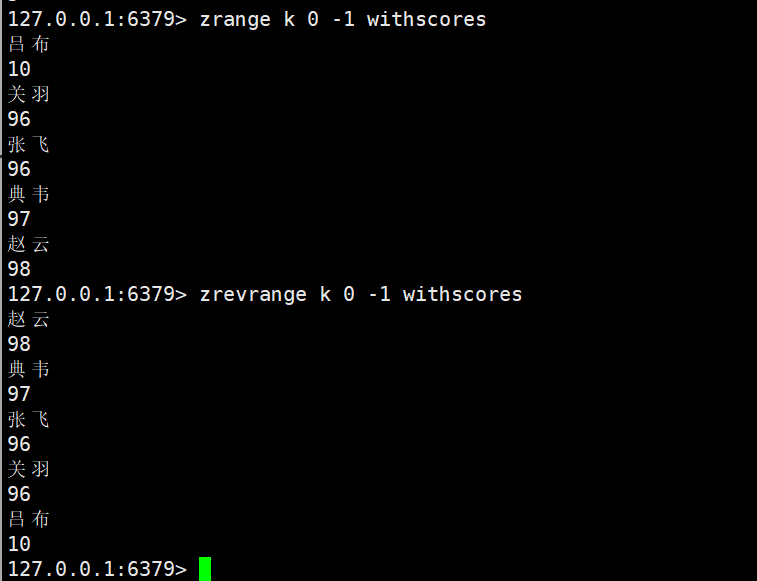
zrevrange
zrevrange key start stop [WITHSCORES]
- 功能:按 “降序” 获取 Zset 中[start, stop]排名区间的元素(start=0为score最高的第一名),与zrange逻辑相反。
- 时间复杂度:O(logN + M)。
zrangebyscore
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]
- 效果:按 “升序” 获取score在[min, max]区间内的元素;支持LIMIT分页(offset为起始位置,count为获取个数),机制与zrange互补。
- 注意:该命令未来可能被zrange合并,建议优先使用zrange。
- 时间复杂度:O(logN + M)。
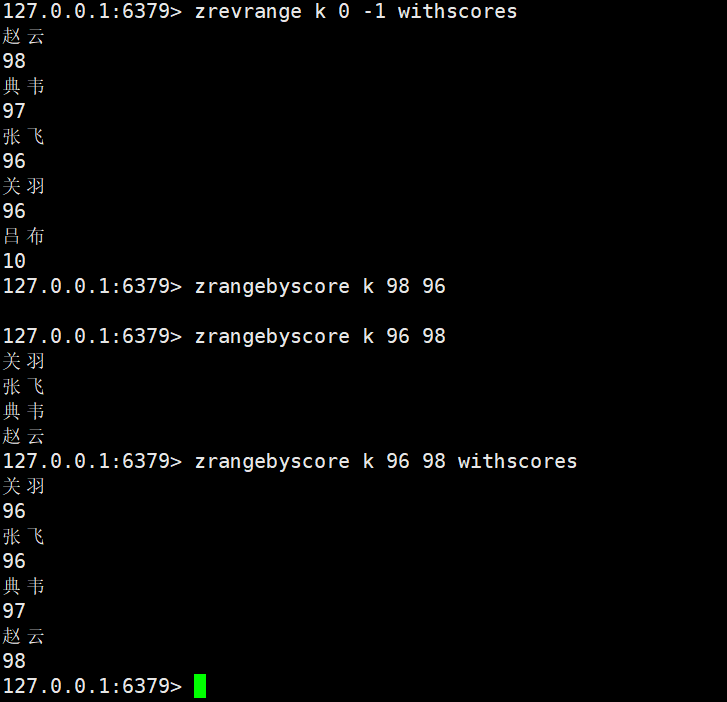
zrank
zrank key member
- 功能:获取member在 Zset 中的 “升序排名”(rank=0为第一名,即score最小的)。
- 时间复杂度:O (logN)(基于跳表快速定位元素)。
- 返回值:排名(member不存在时返回nil)。
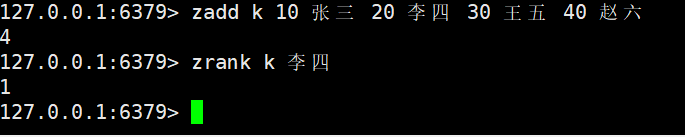
zrevrank
zrevrank key member
- 功能:获取member在 Zset 中的 “降序排名”(rank=0为第一名,即score最大的),与zrank逻辑相反。

zscore
zscore key member
- 功能:获取指定member对应的score。
- 时间复杂度:O (1)(Redis 对该操作做特殊优化,通过哈希表直接映射member到score,牺牲少量空间换效率)。
- 返回值:score(浮点型字符串,member不存在时返回nil)。

3.4 元素删除:zpopmax、bzpopmax、zpopmin、bzpopmin、zrem、zremrangebyrank、zremrangebyscore
zpopmax
zpopmax key [count]
- 功能:按 “降序” 删除并返回count个score最大的元素(默认count=1,删除 1 个)。
- 时间复杂度:O (logN * M)(M 为删除的元素个数,每个元素删除需定位)。
- 返回值:默认返回 “元素 + score” 的列表;count>1时返回多个 “元素 + score” 对。
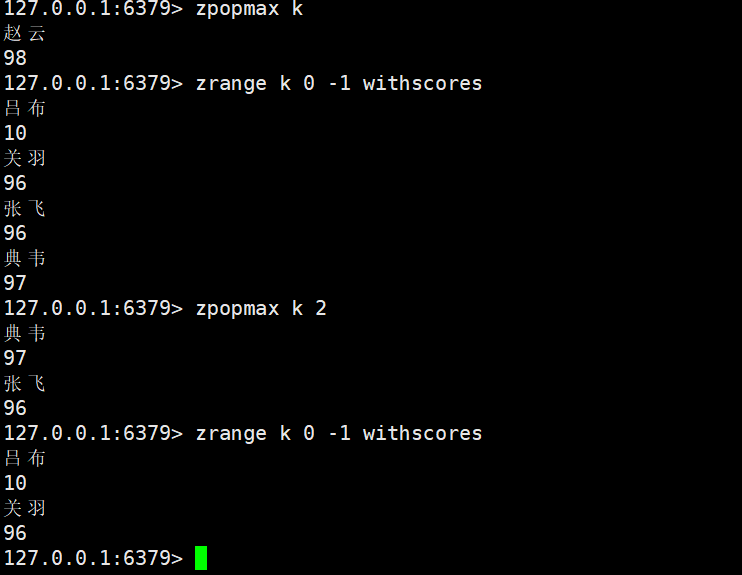
score相同,只删一个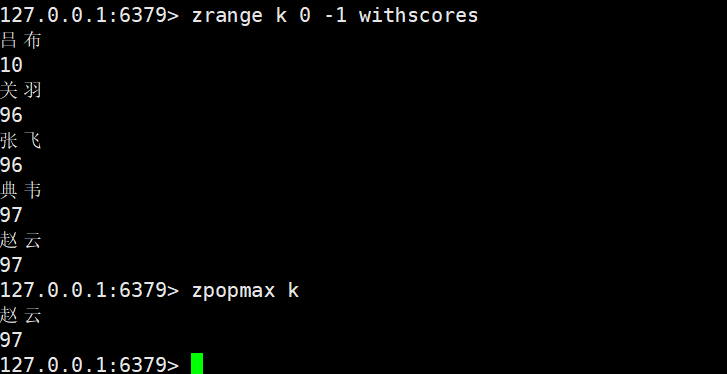
此处删除最大值,在有序集合,也就是尾删。尾删许可把最后一个元素的位置特殊记录下来,后续删除就可以O(1)了。不过redis源码中没有采用,虽然记录了“尾部”,不过还是调用了 通用的删除函数(给定一个member,查找后删除)
存在优化空间,不过优先级不高,一般优化还是先找到瓶颈,再针对性能降序优化。其次log N 在N不是特别特有大的时候,和O(1)是差不多的。
bzpopmax
bzpopmax key [key ...] timeout
- 功能:zpopmax的阻塞版本 —— 若所有 Key 对应的 Zset 为空,阻塞timeout秒(timeout=0表示永久阻塞);直到任一 Zset 有元素,删除并返回score最大的元素。
- 时间复杂度:O (logN)(单个元素删除时间)。
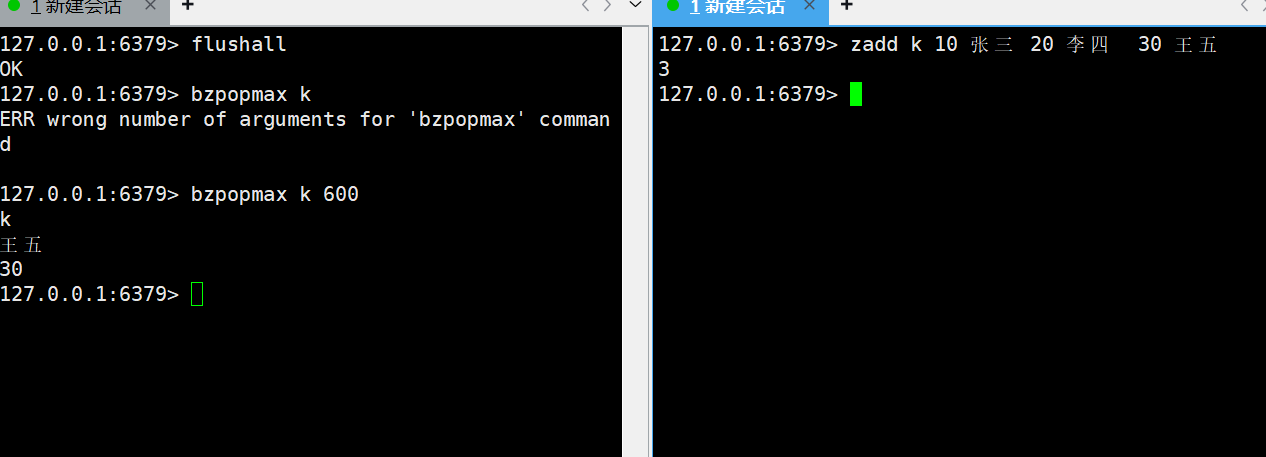
为空阻塞,直到添加元素时返回max
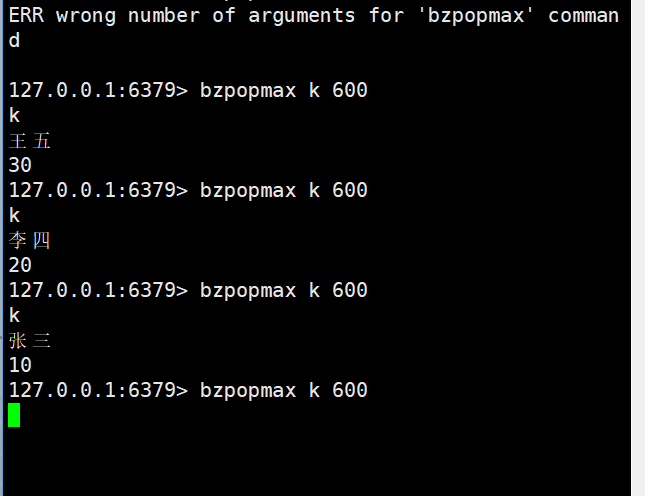
有元素就会直接返回,直到再次空。
时间复杂度:O(logN) 通用方法删除最大值所用时间。
zpopmin
zpopmin key [count]
- 功能:按 “升序” 删除并返回count个score最小的元素,与zpopmax逻辑相反。
- 时间复杂度:O(logN * M)。
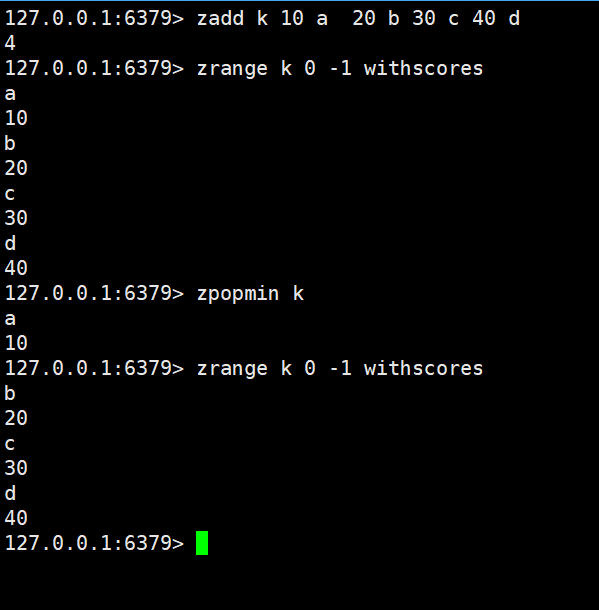
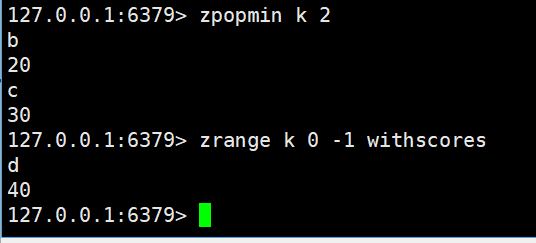
bzpopmin
bzpopmin key [key ...] timeout
- 效果:zpopmin的阻塞版本,逻辑与bzpopmax一致,仅删除score最小的元素。
- 时间复杂度:O(logN)。
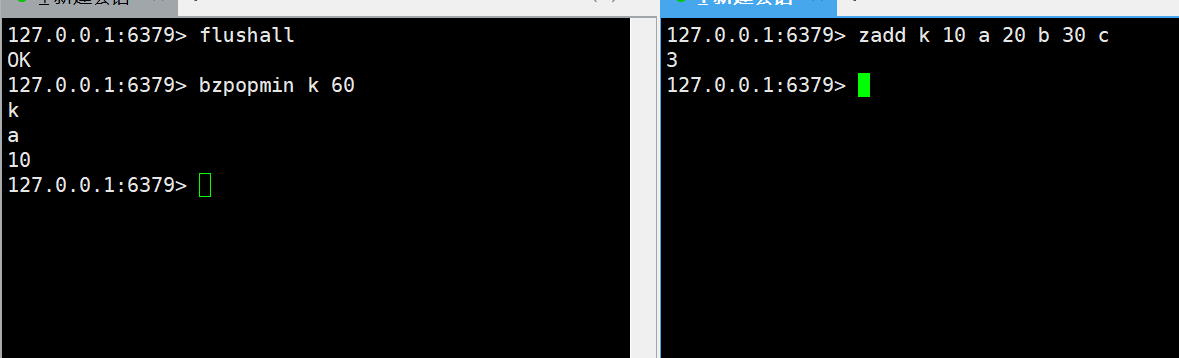
zremrangebyrank
zremrangebyrank key start stop
- 特性:按 “升序排名” 删除[start, stop]区间内的元素(start=0为第一名,stop=-1为所有元素)。
- 时间复杂度:O (logN + M)(M 为删除的元素个数)。
- 返回值:成功删除的元素个数。
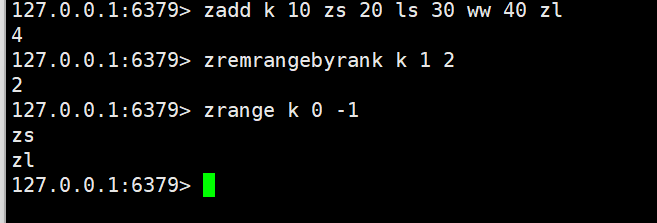
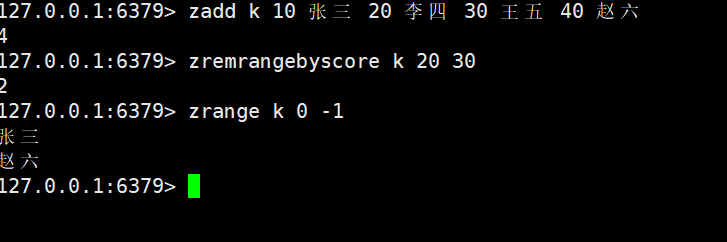
zremrangebyscore
zremrangebyscore key min max
- 特性:按score范围删除[min, max]区间内的元素(默认闭区间,支持(min或max)表示开区间,-inf/+inf表示负无穷 / 正无穷)。
- 时间复杂度:O (logN + M)(定位score边界为 O (logN),删除元素为 O (M))。
- 返回值:成功删除的元素个数。
3.5 元素分数修改:zincrby
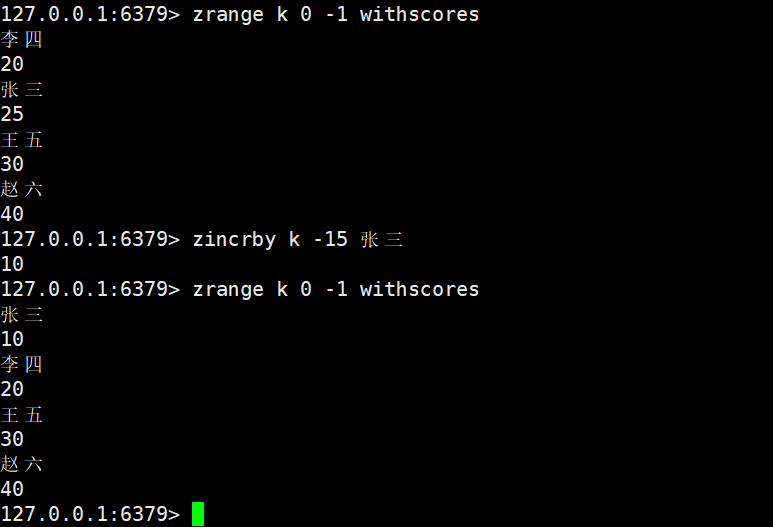
zincrby key increment member
- 功能:对 Zset 中指定member的score进行 “增量修改”(increment为正数时score增加,为负数时score减少);若member不存在,会自动创建并将score设为increment。
- 关键特性:修改score后,Zset 会自动重新排序,保证元素仍按score升序排列。
- 时间复杂度:O (logN)(修改后需重新定位元素位置)。
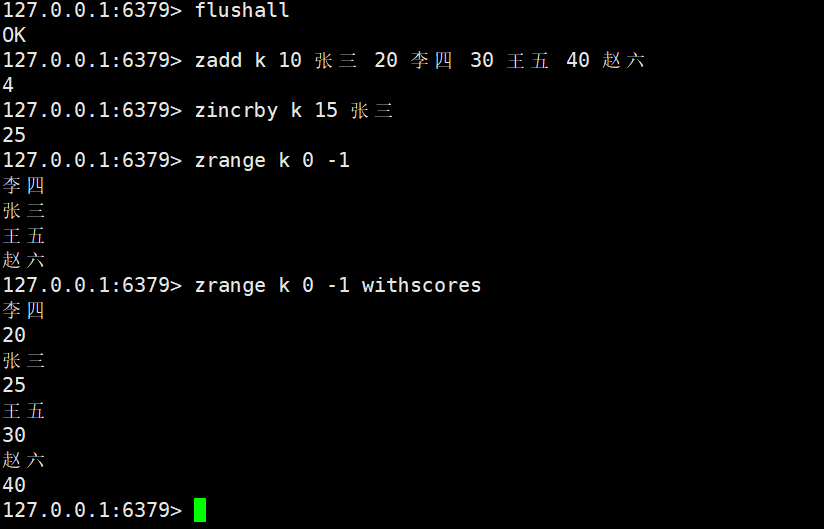
不光修改分数内容,也会移动元素位置保证有序集合是升序的。
小数: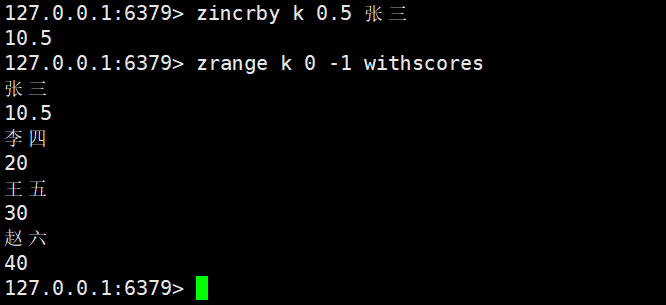
3.6 集合间运算:zinterstore、zunionstore
这类命令用于计算多个 Zset 的 “交集”“并集”,并将结果存储到新 Zset 中,拥护权重设置与分数聚合规则,是 Zset 处理 “多维度有序数据” 的核心应用。
zinterstore
zinterstore destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
- 能力:计算numkeys个 Zset 的 “交集”(仅保留所有 Zset 中都存在的member),将结果存储到destination中;若destination已存在,会先清空原有元素。
- 关键参数说明:
- numkeys:指定参与交集运算的 Zset 个数(必须为正整数);
- WEIGHTS:为每个 Zset 设置 “权重系数”,计算时member的score会乘以对应权重(默认权重为 1);
- AGGREGATE:指定交集后member的score聚合规则(SUM:分数求和,默认;MIN:取最小分数;MAX:取最大分数)。
- 时间复杂度:O(NK)+O(Mlog(M))
- 返回值:交集结果的元素个数。

N:最小的集合的元素个数
K:集合的个数
M:最终结果的集合元素的个数
化简:K一般不多,近似1。N和M认为是同一数量级(近似)==》O(M*log(M))
默认就是相加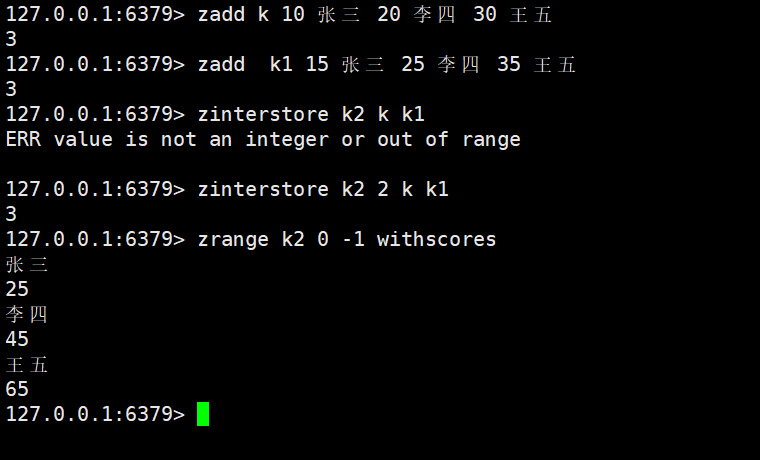
带权: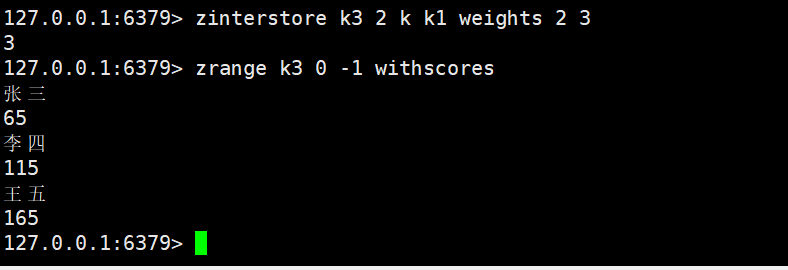
改变运算方式:取最大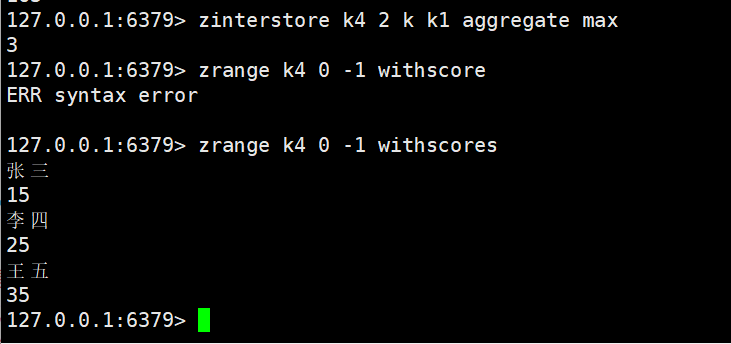
取最小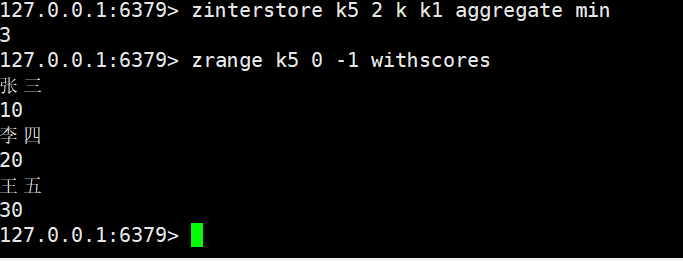
zunionstore
zunionstore destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX]
- 功能:计算numkeys个 Zset 的 “并集”(保留所有 Zset 中存在的member,自动去重),将结果存储到destination中;参数逻辑与zinterstore一致,仅运算规则不同(并集 vs 交集)。
- 返回值:并集结果的元素个数。
默认运算方式是求和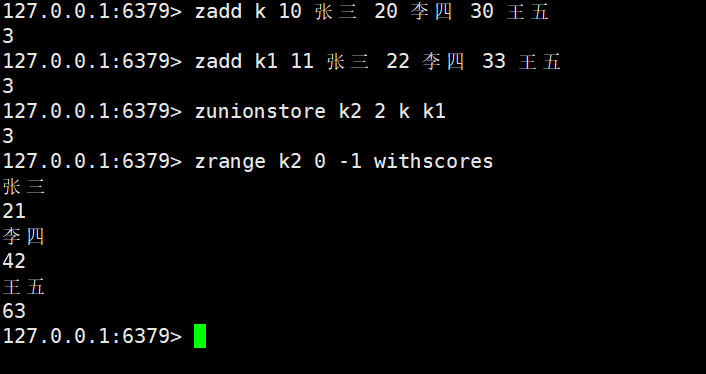
带权重:
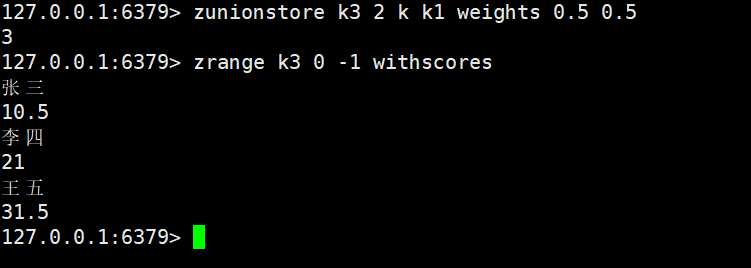
最大/小值: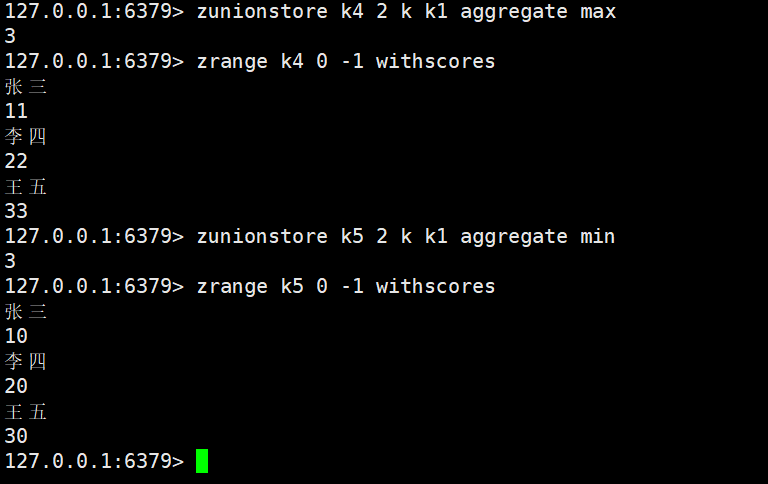
3.7 小结


4.Zset 类型的底层编码
- 假设有序集合中元素个数少/单个元素体积小 : ziplist (压缩列表,节省空间)(6.2.0版本后引入了listpack,替代ziplist)
- 如果有序集合中元素个数多/单个元素体积大 : skiplist(跳表)
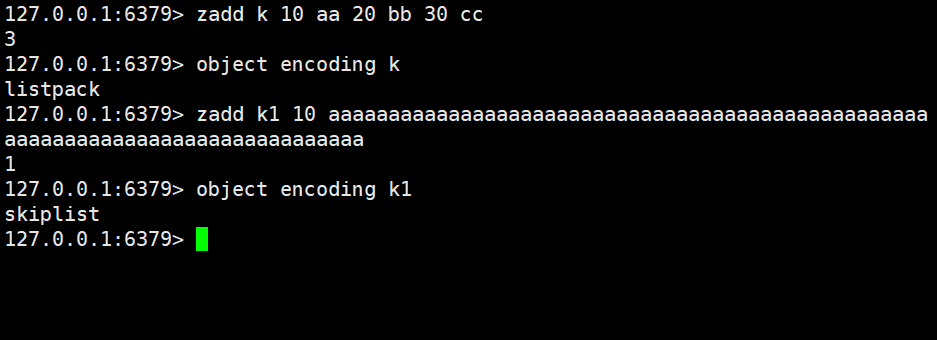
跳表:复杂链表
跳表上查询元素的时间复杂度:O(logN)
类似二叉搜索树,相比于树形结构,更适合按照范围获取元素。
跳表(skiplist)的核心原理
Zset 的skiplist编码是其高效排序的关键,本质是 “多层有序链表”,经过 “索引层” 减少查询时的遍历次数:
- 结构组成:跳表具备 “底层有序链表” 和多层 “索引链表”—— 底层链表存储所有member(按score升序),索引层仅存储部分member,高层索引的 “跨度” 大于低层索引;
- 查询逻辑:从最高层索引开始,按score比较,若当前元素的score小于目标值,跳至下一个元素;若大于目标值,降至下一层索引继续查询,直到底层链表找到目标元素;
- 效率优势:跳表的查询、插入、删除时间复杂度均为 O (logN),且相比红黑树(同样 O (logN)),跳表的 “范围查询”(如zrange)更高效(无需中序遍历,直接遍历底层链表区间)。
轻松点说就是有多层索引,然后越高级的索引表中,索引的数量越少,从最高级的索引开始遍历,如果是升序的话,比索引大继续遍历,比索引小就找到一个范围,然后根据这个范围在下一层索引里找,一直锁定到原始数据的范围,再在这个范围中遍历。这样到达logN ,类似二分,不过不是按照中分的,是范围分。
5. Zset 类型的核心应用场景
5.1 排行榜架构(微博、热搜、游戏天梯、成绩…)
比如游戏的排行,只需要把玩家信息和对应的分数放到有序集合中即可。随着分数发生变化,使用zincrby修改,排行榜的顺序也会自动调整。
像排行榜此种使用到的内存并不大,假设4字节存userid 8字节存score。一个玩家也就12字节,一亿玩家–》12亿字节 差不多是1.2GB。
像王者荣耀的战力系统,胜场战力,挑战战力,巅峰系数等待,允许通过ziterstore/zunionstore提供的加权重的方式处理。
再比如热点事件,浏览量、点赞量、转发量、评论量 ,这些权重怎么分配,也可以提供weight去设置。
zset是一个选择,倘若有些场景可以用到有序集合,又不方便使用redis,可以考虑其他方式的有序集合。
5.2 带权重的消息队列
传统消息队列(如 List 实现)无法按 “优先级” 处理消息,而 Zset 可通过score设置消息优先级(score越大优先级越高),达成 “高优先级消息优先消费”,适用于 “订单处理(VIP 订单优先)”“告警通知(紧急告警优先)” 等场景。
5.3 业务视角
选择是否用 Zset,需判断业务需求是否符合以下核心特征:
- 需求 1:数据需按指定指标排序(如排行榜、优先级队列)——Zset 按score自动排序,无需额外维护排序逻辑;
- 需求 2:需按范围快速查询 / 统计(如分数区间、时间范围)——zrangebyscore/zcount命令协助 O (logN)级别的范围操作;
- 需求 3:需多维度数据聚合(如多标签匹配、多指标评分)——zinterstore/zunionstore协助权重聚合,灵活计算交集 / 并集。
6.小结
Redis Zset 类型的核心价值在于 “有序性 + 高效性”—— 它在 Set “去重” 基础上,通过score实现自动排序,同时借助跳表底层结构,保证增删查及范围操作的高效性,是分布式系统中 “有序数据管理” 的核心工具。
建议:
- 合理设计score:score不仅是排序依据,还可结合业务需求承载 “优先级”“时间戳”“权重” 等信息(如用时间戳实现时间范围查询),提升 Zset 的复用性;
- 控制 Zset 大小:单个 Zset 的元素个数建议不超过 10 万,超过后采用 “分桶存储”(如按用户 ID 哈希分桶、按时间分桶),避免跳表层级过深导致性能下降;
- 优先用zrevrange替代zrange:排行榜、优先级队列等场景多需 “降序” 展示(如分数最高在前),zrevrange可直接返回降序结果,无需额外处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号