

第 8 篇 RAG 必知概念及原理详解 - 实践
文章目录
目标:了解 RAG 的基本概念,及实现原理。为后续介绍 Dify 知识库做铺垫。
前置知识
什么是 Embedding?
嵌入(**Embedding**)将文本、图像和视频转换为称为就是的工作原理向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度(Dimensionality)。
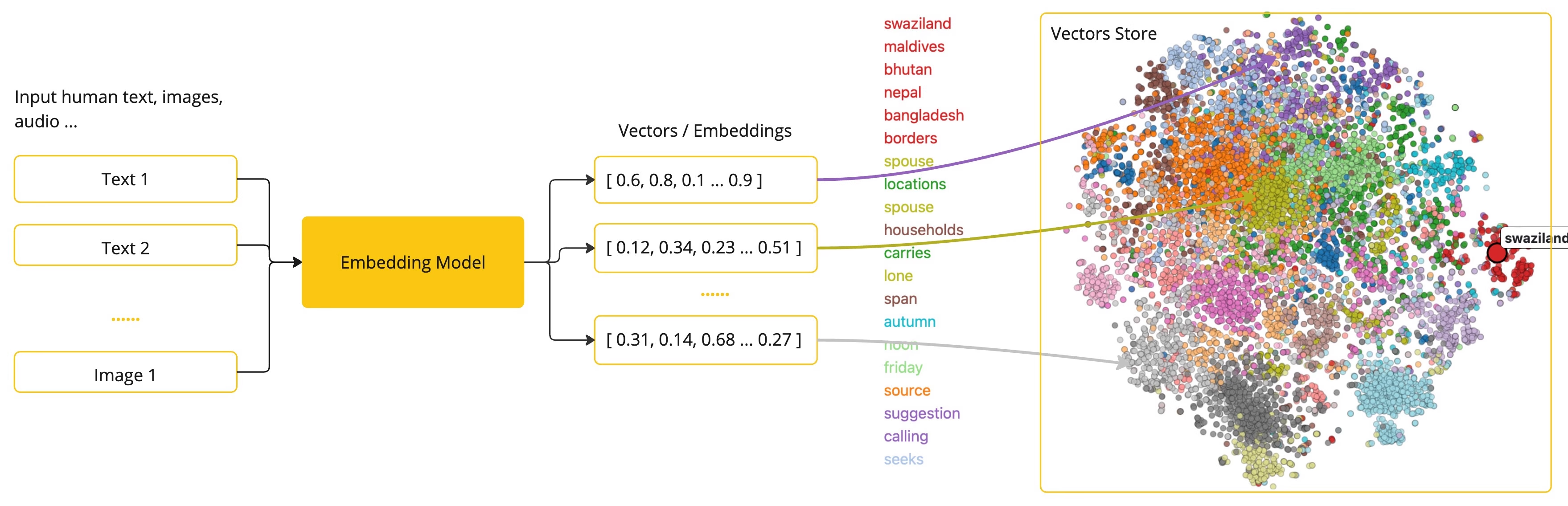
向量(Vector)的用途:通过计算两个文本片段的向量表示之间的数值距离,应用程序可以确定用于产生嵌入向量的对象之间的相似性。Embedding 在检索增强生成(RAG)模式中,具有重要意义。它使数据能够在语义空间中表示为点,这类似于欧几里得几何的二维空间,但在更高的维度中。二维空间中平面的点可以根据其坐标的远近而接近或远离,而语义空间中,点的接近程度反映了意义的相似性。这种相似性有助于文本分类、语义搜索、产品推荐等任务。【从上图中可以看出,文本、图片、音频等通过 Embedding Model 转换为了 Vector,而在 Vector Store 中可以看出不同的向量之间的距离,即反应源头文档的语义相似性。】
什么是 Embedding Model?
嵌入模型(Embedding Model,也称之为向量化模型)是嵌入过程中采用的模型,模型能够将文本、图像和视频数据转化为数值向量,并用于后续的语义搜索、推荐、聚类、分类、异常检测等任务。
模型选择:根据输入数据类型和应用场景,选择合适的向量化模型。【以百炼平台内的模型为例】
- 处理纯文本或代码:推荐使用
text-embedding-v4。它是当前性能最强的模型,支持任务指令(instruct)、稀疏向量等高级功能,能覆盖大多数文本处理场景。 - 处理多模块内容:对于包含图像、文本或视频的混合内容,可选择针对视觉能力进行优化提升的
tongyi-embedding-vision-plus与tongyi-embedding-vision-flash或通用多模态模型multimodal-embedding-v1。 - 处理大规模材料:
text-embedding-v4并结合 OpenAI兼容-Batch调用,以显著降低成本。
切换向量维度:向量维度,即 Embedding 数组的长度。维度更高,则能保留更高的语义信息,但也会增加存储和计算成本。text-embedding-v4 和 text-embedding-v3 支持自定义向量维度。
- 通用场景(推荐):1024 维度是性能与成本的最佳平衡点,适合大多数语义检索任务。
- 追求精度:可选 1536 或 2048 维度,精度提升的同时,存储和计算开销也会显著增加。
- 资源受限:可选 768 及以下维度,显著降低资源消耗的同时,会损失部分语义信息。
检索增强生成(RAG)
什么是 RAG?
Retrieval-augmented Generation,检索增强生成。以向量检索为核心的 RAG 框架已成为**解决大模型获取最新外部知识,同时解决其生成幻觉问题**的主流技术框架,并已在相当多的场景中落地实践。
为什么应该 RAG?
1**、大模型知识的局限性**:把大模型比作超级专家,熟悉人类各个领域的知识,但也有一些局限性。比如它不知道你个人的一些情况,基于这些信息是私人的,不会在互联网上公开,所以它没有提前学习的机会。【公开材料 LLM 能学习到,私有化数据大模型就得不到,无法学习】
2、RAG 技巧所做的事情
- 举个例子来说,如果你想要一个超级专家作为你的家庭财务顾问,那么你再问它疑问前,得告诉它家里的投资理财情况、家庭消费支出数据等信息,这样它才能根据你的个人情况提供专业的建议。
- RAG 的作用:帮助大模型临时地获得它不具备的外部知识,允许它在回答问题之前先找答案。从而输出更加准确的答案,使结果变得真实可信,减少幻觉障碍。
- RAG 架构的核心:外部知识的检索环节。假如不能精确找到所得的信息(比如想找投资理财记录,结果找到的是减肥计划),那么再厉害的超级专家和无能为力。
RAG vs 其它文本训练方案
微调(Fine-tuning) vs RAG:在达到相似结果时,RAG 胜
- RAG 在成本效率和实时性性能方面具有显著优势。
- 微调技术对材料的质量和数量要求很高,另外采用微调模型的时候可能也需要 RAG 技术的支持
长文本 vs RAG:LLM 在处理分析长文本时存在一个问题,即随着文本长度的增加,检索的准确性持续下降。将 LLM 的长文本能力与 RAG 技术完美结合,相互学习长处,弥补各自的不足。
RAG 实现原理
实现原理图如下:
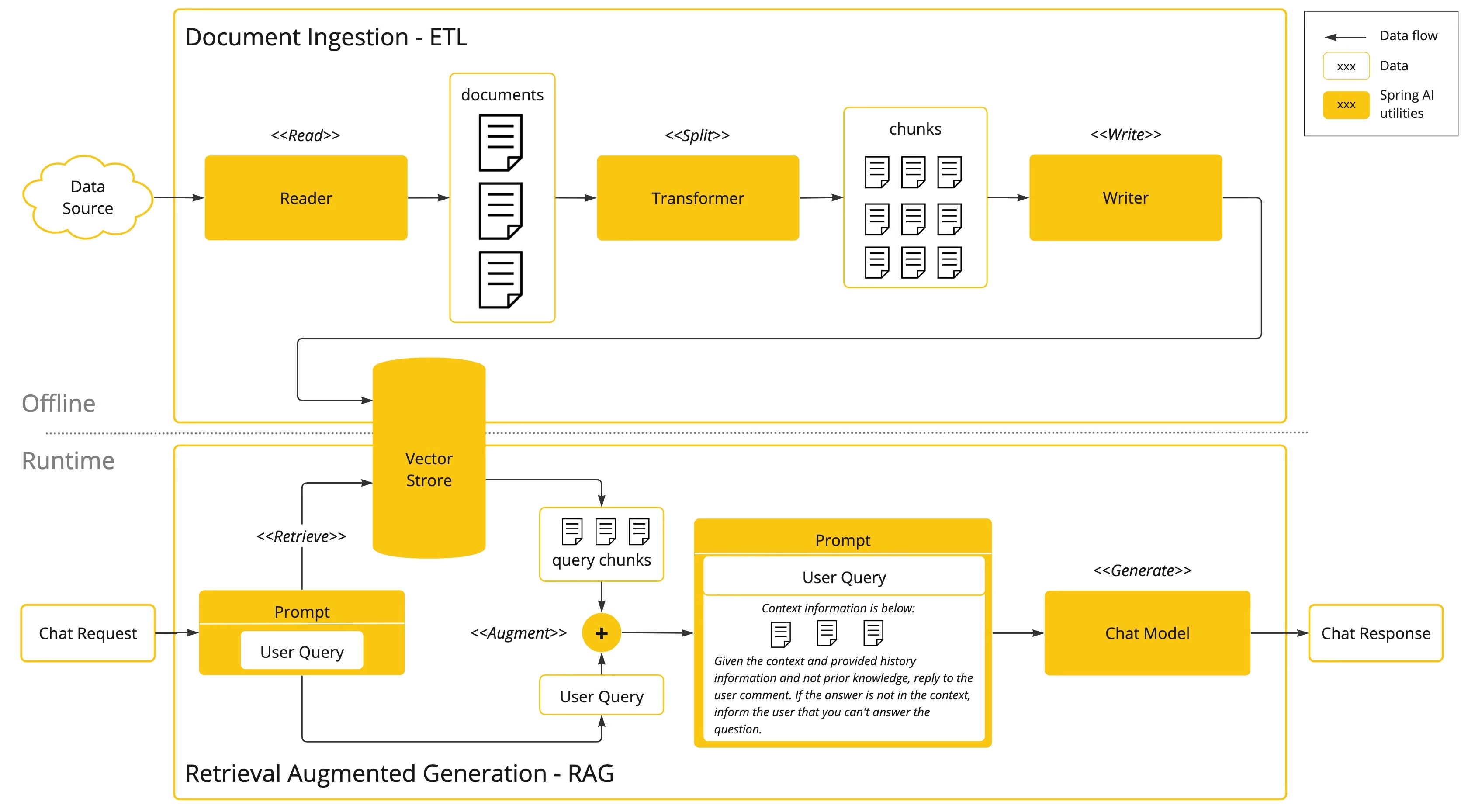
主要分为两部分:
1、Offline 离线操控【提前准备好数据源并向量化及存储】
首先,使用 Reader 从 Data Source 中读取文档,并利用 Transformer 将其分割为若干个 chunk 分块(原来的文档太大,得拆分为更小的部分)。然后,利用 Writer 将 chunk 分块数据写入到向量数据库(Vector Store)中。
2、Runtime 运行时操作【与大模型沟通前检索向量存储】
首先,用户提出了问题。会先拿障碍到向量数据库中检索相关的 trunk 分块,即找到与用户问题语义相关的内容。然后,将这些语义相关的内容作为大模型提示词的一部分【这里体现的就是增强,augment】,发送给大模型。最后,大模型基于 chunk 分块内容+用户问题,给出精准的回复。
RAG 应用场景及示例
RAG 技术的应用场景:比如 AI 智能客服、企业智能知识库、AI 搜索引擎等。
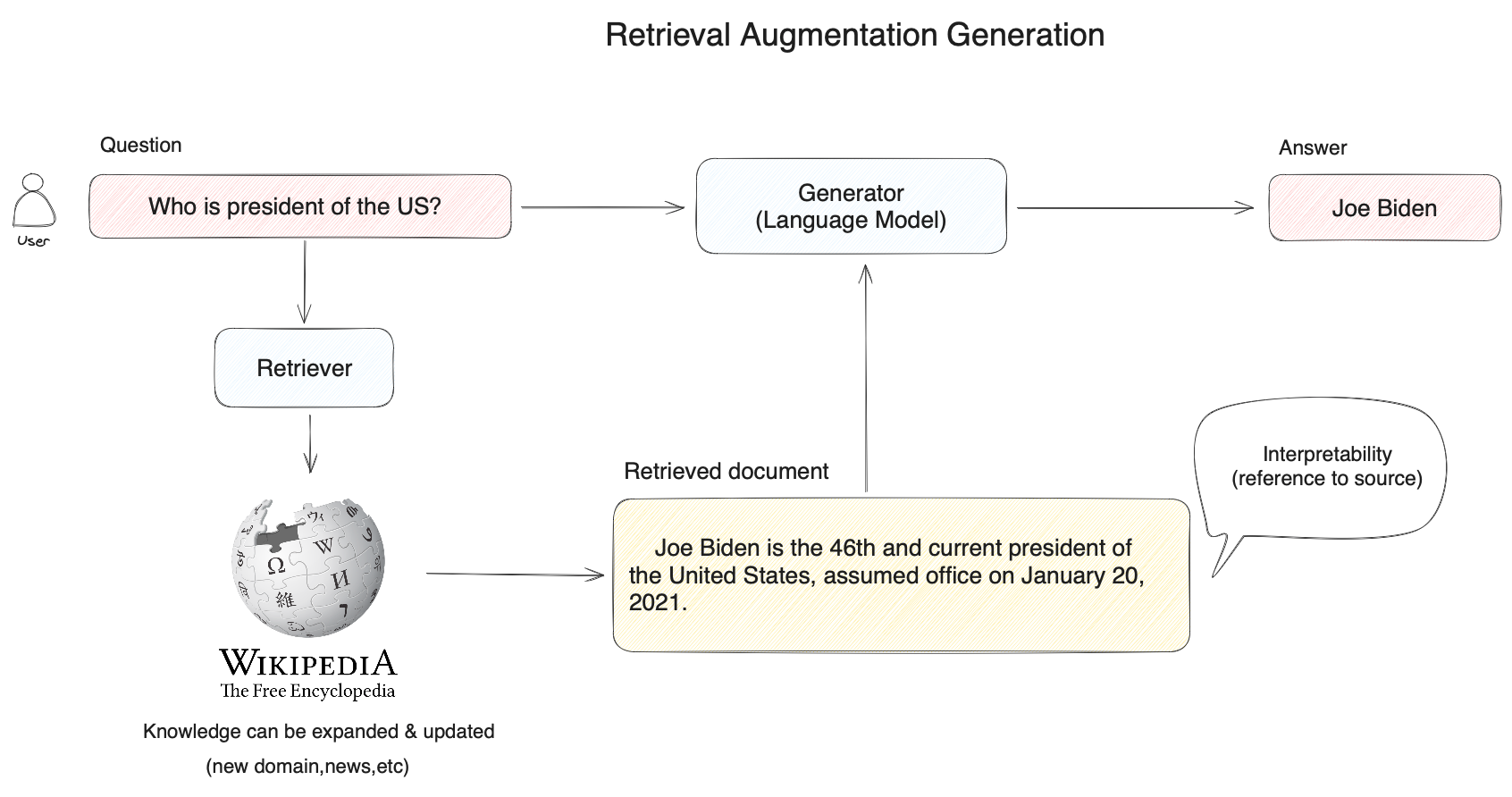
RAG 技术的应用案例:比如,用户提问“美国总统是谁”?
- 常规思路:直接交给大模型回答
- RAG 技术思路:先将用户的困难在知识库(如下图中的维基百科)中进行向量搜索,通过语义相似度匹配的方式查询到相关的内容(拜登是美国现任第 46 届总统),然后再将用户问题及搜索到的相关知识提供给大模型,使得大模型获得足够完备的知识来回答问题,以此获得更可靠的问答结果。
混合检索
向量检索(语义相关性匹配)
RAG 检索环节中的主流方法是向量检索,即语义相关度匹配的方式。技术原理是通过将外部知识库的文档先拆分为语义完整的段落或句子,并将其转换(Embedding)为计算机能够理解的一串数字表达(多维向量),同时对用户问题进行同样的转换运行。
**计算机能够发现用户问题与句子之间细微的语义相关性。**比如“猫追逐老鼠”和“小猫捕猎老鼠”的语义相关度会高于“猫追逐老鼠”和“我喜欢吃火腿”之间的相关度。将相关度最高的文本内容查找后,RAG 系统会将其作为用户问题的上下文一同提供给大模型,帮助大模型回答难题。
向量检索的优势:
- 复杂语义的文本查找
- 相近语义理解(如老鼠/捕鼠器/奶酪,谷歌/必应/搜索引擎)
- 多语言理解(跨语义理解,如输入中文匹配英文)
- 多模态理解(支持文本、图像、音视频等的相似匹配)
- 容错性(处理拼写错误、模糊的描述)
向量检索的劣势:
- 搜索一个人或物体的名字,比如小米 10
- 搜索缩写词或短语,比如 RAG
- 搜索 ID,比如 gpt-3.5-turbo
关键词检索(传统 keyword 检索)
上面的缺点,恰恰都是传统关键词搜索的优势所在,传统关键词搜索擅长:
- 精确匹配,如产品名称、姓名
- 少量字符的匹配
- 倾向低频词汇的匹配(低频词汇往往承载了语言中的关键意义,比如“你想跟我去喝咖啡吗?”这句话中的分词,“喝”、“咖啡”会比“你”,“想”,“吗”在句子中承载更重要的含义)
为什么需要混合检索?
在大多数文本搜索的场景中,首先的是确保潜在最相关结果能够出现在候选结果中。向量检索和关键词检索在检索领域各有优势,混合搜索正是结合了这两种搜索技术的优点,同时弥补了两方的缺点。
在混合检索中,你需要在数据库中提前建立向量索引和关键词索引。在用户问题输入时,分别通过两种检索器在文档中检索出最相关的文本。
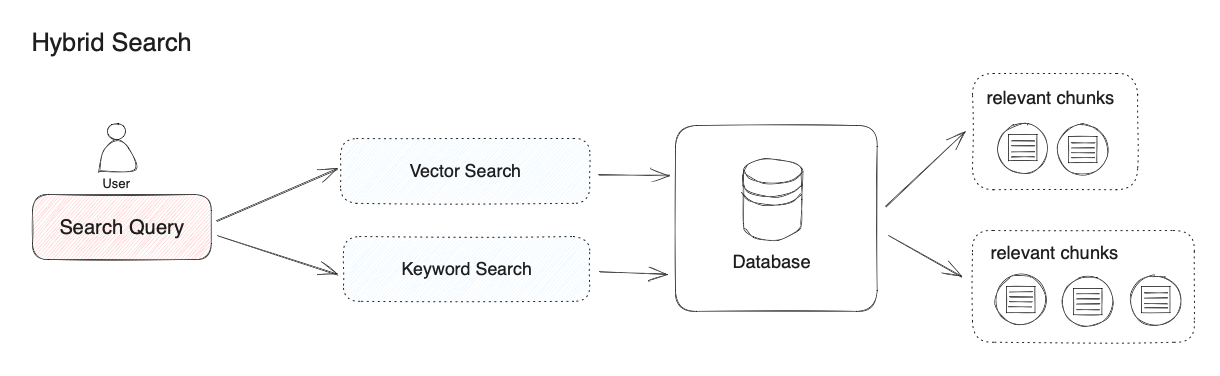
混合检索,并没有明确的定义,上面是向量检索与关键词检索的组合。其它检索算法的组合,也行称之为混合检索。
不同的检索系统各自擅长寻找文本(段落、语句、词汇)之间不同的细微联系,这包括了精确关系、语义关系、主体关系、结构关系、实体关系、事件关系等。行说,没有一种检索模式能够适应所有场景。混合检索通过多个检索系统的组合,实现了多个检索技术之间的互补。
重排序 rerank
为什么必须重排序?
混合检索能够结合不同检索科技的优势以获得更好的召回结果,但不同检索模式下的查询结果应该进行合并或归一化(将材料转换为统一的标准范围或分布,以便更好地进行比较、分析和处理),然后再一起给出给大模型。这个时候,我们需引入一个评分系统:重排序模型(Rerank Model)。【混合检索得到多个结果,需要对多个结果排序,选择最优的,这就是 rerank 模型】
计算用户问题与给定的每个候选文档之间的相关性分数,并返回按相关性从高到低的文档列表。就是重排序模型会计算候选文档列表与用户障碍的语义匹配度,根据语义匹配度重新进行排序,从而改进语义排序的结果。其原理重排序一般放在搜索流程的最后阶段,非常适合用于合并和排序来自不同检索系统的结果。【如果放在前面,那么要评估用户问题与 N 个文档之间的相关性得分,则肯定会非常低效】
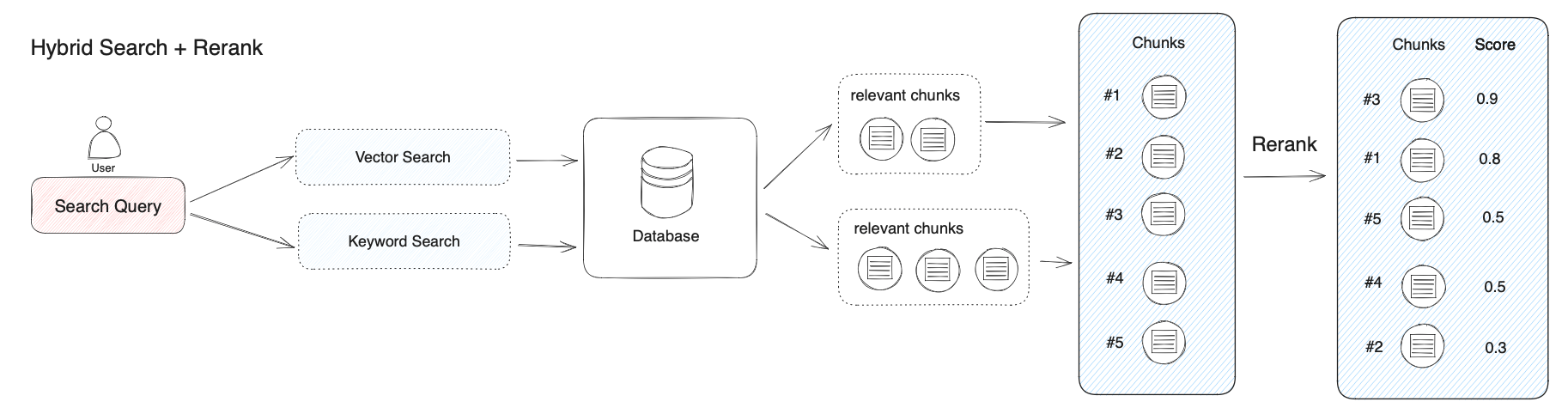
常见的 Rerank 模型
- gte-rerank、gte-rerank-v2,阿里通用文本排序模型,非开源
- Qwen3-Reranker:阿里巴巴开源文本重排序模型,比如dengcao/Qwen3-Reranker-8B
- bge-reranker:北京智源人工智能研究院开源,比如xitao/bge-reranker-v2-m3
- Cohere rerank:商业闭源 rerank 模型
参考
2.向量化_大模型服务平台百炼(Model Studio)-阿里云帮助中心
4.检索增强生成
相关博文
1.第 1 篇 Linux 下部署 Dify 1.7.1
2.第 2 篇 Dify 插件离线安装
3.第 3 篇 Dify 入门示例 - 聊天助手
4.第 4 篇 Dify 示例:数据库执行Agent
5.第 5 篇 Dify 报错解决:The length of output variable xxx must be less than 30 elements
6.第 6 篇 Dify 接入大模型并利用
7.第 7 篇 Dify 应用介绍 + 聊天助手&Agent 应用关键点说明
8.第 8 篇 RAG 必知概念及原理详解
9.第 9 篇 Dify 知识库原理详解
10.第 10 篇 Dify 知识库手把手案例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号