

【Linux】Ext系列文件(2) - 实践
1. ext2 文件系统
1.1 宏观认识
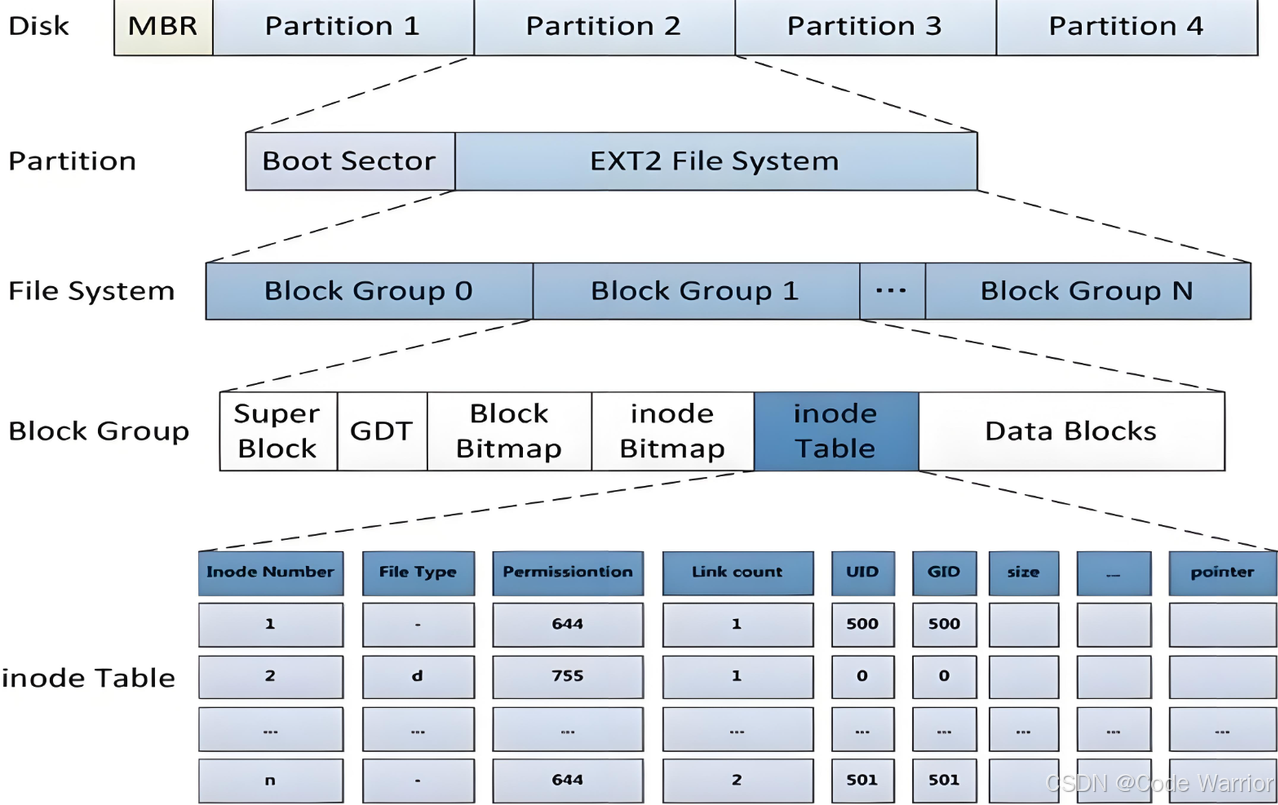
1.2 Block Group
1.3 块组内部构成
1.3.1 超级块(super Block)
超级块在每个块组的开头都有⼀份拷⻉(第⼀个块组必须有,后⾯的块组可以没有)。 为了保证⽂件系统在磁盘部分扇区出现物理问题的情况下还能正常⼯作,就必须保证⽂件系统的super block信息在这种情况下也能正常访问。所以⼀个⽂件系统的super block会在多个block group中进⾏备份,这些super block区域的数据保持⼀致。
1.3.2 GDT(Group Descriptor Table)
1.3.3 块位图(Block Bitmap)
1.3.4 inode位图(Inode Bitmap)
1.3.5 i节点表(Inode Table)
1.3.6 Data Block
1.4 inode和datablock映射(弱化)
__le32 i_block[EXT2_N_BLOCKS](EXT2_N_BLOCKS = 15),该数组存储指向 Data Blocks 的 “指针”—— 通过这些指针,系统能快速找到 inode 对应的文件数据存放在哪些 Data Blocks 中,从而关联 “文件属性(inode)” 和 “文件内容(Data Block)”。1.5 目录与文件名
在 ext2 中,目录本质是一种特殊文件:
- 目录的数据块中,存储的是 “键值对”—— 键是 “文件名”,值是该文件对应的 “inode 编号”;
- 当执行
ls时,系统先读取目录的数据块,拿到文件名和对应的 inode 编号,再通过 inode 编号找到 inode 表中的属性信息,最终展示文件详情。
1.6 路径解析
当访问一个文件(如 /home/user/test.txt)时,系统会按 “路径层级” 逐步解析:
- 从根目录(
/)的 inode 开始,找到根目录的数据块,从中获取home目录的 inode 编号; - 通过
home的 inode 编号,找到home目录的 inode 和数据块,再从中获取user目录的 inode 编号; - 重复步骤,直到找到
test.txt的 inode 编号,最终通过 inode 找到对应的 Data Blocks,读取文件内容。
1.7 路径缓存
为提升路径解析效率,系统会将 “最近解析过的路径(如 /home/user)” 和对应的 inode 编号缓存起来。后续再次访问同一路径时,无需重新逐层解析,直接从缓存中获取 inode 编号,减少磁盘 I/O 操作。
1.8 挂载分区:解决跨分区访问与定位问题
我们已知 inode 无法跨分区,且 Linux 支持多分区存储,那如何识别当前操作的分区、实现跨分区访问?挂载(Mount)就是核心解决方案,以下结合实验和原理详细说明:
1.8.1 实验:通过循环设备模拟分区挂载
我们用 dd 制作虚拟磁盘文件、格式化并挂载,直观理解挂载过程:
步骤 1:创建虚拟磁盘文件(模拟分区)
用 dd 命令生成一个 5MB 的空文件 disk.img,当作 “虚拟分区”:
$ dd if=/dev/zero of=./disk.img bs=1M count=5if=/dev/zero:从 “零设备” 读取空数据(用于填充文件);of=./disk.img:输出到当前目录的disk.img文件;bs=1M:每次读写 1MB;count=5:共读写 5 次,最终文件大小为 5MB。
步骤 2:格式化虚拟磁盘(写入 ext4 文件系统)
分区需先写入文件系统才能存储数据,这里用 mkfs.ext4 格式化为 ext4 系统:
$ mkfs.ext4 disk.img执行后,disk.img 就具备了 ext4 文件系统的结构(如块组、inode 表等)。
步骤 3:创建挂载点(分区的 “访问入口”)
挂载需要一个空目录作为 “桥梁”,将分区与 Linux 根文件系统关联,这里创建 /mnt/mydisk:
$ mkdir /mnt/mydisk步骤 4:查看挂载前的分区状态
用 df -h 查看当前已挂载的分区,此时列表中没有 /mnt/mydisk 相关条目:
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 956M 0 956M 0% /dev
tmpfs 198M 724K 197M 1% /run
/dev/vda1 50G 20G 28G 42% / # 系统根分区
# 其他临时文件系统(tmpfs)...步骤 5:执行挂载(关联分区与挂载点)
用 mount -t ext4 指定文件系统类型,将 disk.img 挂载到 /mnt/mydisk:
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/-t ext4:明确指定文件系统为 ext4(若不指定,系统会自动检测);./disk.img:待挂载的 “虚拟分区”(实际场景中可能是/dev/sdb1等物理分区);/mnt/mydisk/:挂载点目录。
步骤 6:查看挂载后的状态
再次执行 df -h,会新增一行 /dev/loop0 相关条目,说明挂载成功:
$ df -h
# ... 其他分区 ...
/dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk # 已挂载的虚拟分区关键说明:/dev/loop0 是什么?
/dev/loop0 是 Linux 的循环设备(Loop Device),属于 “伪设备”:
- 作用:将普通文件(如
disk.img)模拟成 “块设备”(类似物理硬盘分区),让系统能像操作真实分区一样读写文件; - 查看循环设备列表:
bash
$ ls /dev/loop* -l brw-rw---- 1 root disk 7, 0 Oct 17 18:24 /dev/loop0 # 块设备(b开头) brw-rw---- 1 root disk 7, 1 Jul 17 10:26 /dev/loop1 # ... 其他循环设备 ... crw-rw---- 1 root disk 10,237 Jul 17 10:26 /dev/loop-control # 循环设备控制器
步骤 7:卸载分区(解除关联)
若需断开分区与挂载点的关联,用 umount 命令(注意:卸载时需确保无进程访问挂载点):
$ sudo umount /mnt/mydisk再次执行 df -h,/dev/loop0 条目消失,说明卸载成功。
1.8.2 核心结论:挂载的本质与分区定位
分区必须挂载才能使用即使分区已写入文件系统(如 ext4),也无法直接访问 —— 必须通过 “挂载” 关联到一个目录(挂载点),才能将分区融入 Linux 根文件系统,实现文件读写。
通过 “路径前缀” 判断当前分区挂载后,访问 “挂载点 + 文件路径”(如
/mnt/mydisk/test.txt)时,系统会根据 “路径前缀/mnt/mydisk” 识别出对应的分区(如/dev/loop0),从而找到该分区的 inode 表和数据块 —— 这就解决了 “inode 不跨分区” 和 “多分区定位” 的问题。例如:- 访问
/home/user/file.txt:路径前缀/对应根分区/dev/vda1; - 访问
/mnt/mydisk/data.txt:路径前缀/mnt/mydisk对应分区/dev/loop0。
- 访问
1.9 文件系统总结
ext2 是一种 “基于块组” 的日志型文件系统(ext3/ext4 新增日志功能),核心优势在于:
- 通过 “块组 + 位图” 实现高效的 inode 和 block 分配 / 回收;
- 通过 “超级块 + GDT 备份” 保证数据可靠性;
- 用 inode 分离 “文件属性” 和 “文件内容”,逻辑清晰,便于管理;
- 后续的 ext3(新增日志)、ext4(支持更大容量、更快速度)均基于 ext2 演进,兼容 ext2 的核心结构。
2. 软硬链接
2.1 硬链接
硬链接的核心是多个文件名指向同一个 inode,即不同文件名关联到同一份文件数据。
创建示例:
[root@localhost linux]# touch abc # 创建文件abc [root@localhost linux]# ln abc def # 给abc创建硬链接def [root@localhost linux]# ls -li abc def # 查看inode编号 263466 -rw-r--r--. 2 root root 0 9月 15 17:45 abc 263466 -rw-r--r--. 2 root root 0 9月 15 17:45 def可见
abc和def的 inode 编号相同(均为 263466),硬链接数为 2(表示有 2 个文件名指向指向该 inode)。删除机制:删除文件时,系统会先删除目录中对应的文件名记录,再将硬链接数减 1。只有当硬链接数减为 0 时,才会真正释放 inode 和对应的数据块(即彻底删除文件内容)。
2.2 软链接
软链接(符号链接)是独立的文件,自身有独立的 inode,内容存储的是目标文件的路径(类似 Windows 快捷方式)。
创建示例:
[root@localhost linux]# ln -s abc abc.s # 给abc创建软链接abc.s [root@localhost linux]# ls -li 263563 -rw-r--r--. 2 root root 0 9月 15 17:45 abc 261678 lrwxrwxrwx. 1 root root 3 9月 15 17:53 abc.s -> abc # 软链接标识 263563 -rw-r--r--. 2 root root 0 9月 15 17:45 def软链接
abc.s的 inode 编号(261678)与目标文件abc(263563)不同,权限位以l开头,箭头->指向目标路径。文件的三个时间属性:
Access:最后访问时间(如读取文件内容);Modify:文件内容最后修改时间;Change:文件属性(如权限、所有者)最后修改时间。
2.3 软硬链接对比
| 特性 | 硬链接 | 软链接 |
|---|---|---|
| inode 编号 | 与目标文件相同 | 自身独立,与目标不同 |
| 本质 | 文件名与 inode 的映射关系 | 独立文件,存储目标路径 |
| 独立性 | 不独立,依赖目标 inode | 独立文件,有自己的元数据 |
| 跨文件系统 | 不支持(inode 不可跨分区) | 支持(通过路径指向) |
| 目标删除影响 | 无影响(链接数减 1) | 变为 “死链接”(无法访问) |
2.4 软硬链接的用途
硬链接:
- 目录中的
.(当前目录)和..(父目录)本质是硬链接; - 用于文件备份(修改任一链接文件,其他链接同步更新,删除备份不影响原文件)。
- 目录中的
软链接:
- 简化路径访问(将深层目录文件链接到常用位置);
- 版本切换(通过修改软链接指向,快速切换不同版本的文件 / 程序);
- 类似 Windows 的 “快捷方式”,方便访问目标文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号