

详细介绍:百度贴吧爬虫实战:完整实现与使用指南
一、爬虫实战前置说明
1、环境依赖
在运行爬虫代码前,需先安装以下 Python 依赖库(建议使用 Python 3.8 及以上版本):
- beautifulsoup4:用于解析 HTML 页面内容
- urllib:Python 内置库,用于发送 HTTP 请求(无需额外安装)
- csv:Python 内置库,用于处理 CSV 文件(无需额外安装)
- re:Python 内置库,用于正则表达式匹配(无需额外安装)
- json:Python 内置库,用于解析 JSON 数据(无需额外安装)
安装命令:
pip install beautifulsoup4二、核心功能说明
本爬虫实现三大核心能力:
1、HTML 获取页面内容:从贴吧列表页的 HTML 中获取数据。
2、JSON 数据解析:从接口返回的 JSON 数据中提取帖子信息(适配动态加载页面)
3、数据持久化:将提取的帖子信息保存到 CSV 文件,便于后续分析
三、实战
1、获取页面内容
该方法用于发送 HTTP 请求获取百度贴吧指定页面的 HTML 内容。通过构建自定义请求头的 request 对象,模拟浏览器行为进行页面访问,避免被服务器识别为爬虫而拒绝服务。获取到的响应内容将以 UTF-8 编码格式解码为字符串返回,便于后续解析处理。若请求过程中出现异常(如网络错误、连接超时等),会捕获并打印错误信息,并返回 None。
def fetch_page_content(self, url):
"""获取网页内容"""
try:
request = urllib.request.Request(url, headers=self.headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
except Exception as e:
print(f"获取网页内容时出错: {e}")
return None2、解析页面内容
此方法负责解析 HTML 内容以提取帖子的标题和链接。首先使用 BeautifulSoup 解析器处理页面内容,定位包含帖子列表的特定区域(通过 id 查找 code 标签)。由于帖子列表内容通常被包裹在 HTML 注释中,因此需要从注释中提取有效的 HTML 片段并再次解析。接着遍历帖子列表中的每个条目,提取标题文本和对应的链接,对于相对路径的链接会自动补全为完整的 URL。最终将提取到的标题和链接以字典形式返回,方便后续处理和存储。
def parse_html_content(self, html_content):
"""解析HTML内容,提取标题和链接"""
post_dict = {}
try:
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含帖子列表的 pagelet
pagelet = soup.find('code', id='pagelet_html_frs-list/pagelet/thread_list')
if not pagelet:
print("未找到帖子列表区域")
return post_dict
# 提取注释内容(注释是 pagelet 的子节点)
comments = pagelet.find_all(string=lambda text: isinstance(text, Comment))
if not comments:
print("未找到注释内容")
return post_dict
# 取第一个注释内容(即帖子列表的 HTML)
comment_html = comments[0]
# 将注释内容转为可解析的 BeautifulSoup 对象
post_soup = BeautifulSoup(comment_html, 'html.parser')
# 提取标题和链接,以字典形式存储
for li in post_soup.select('li.j_thread_list'):
a_tag = li.select_one('a.j_th_tit')
if a_tag:
title = a_tag.text.strip()
link = a_tag.get('href', '')
# 确保链接是完整的 URL
if link and not link.startswith('http'):
link = 'https://tieba.baidu.com' + link
post_dict[title] = link
except Exception as e:
print(f"解析HTML内容时出错: {e}")
return post_dict3、清理并解析 JSON
清理并解析 JSON该方法用于处理包含 JSON 数据的内容,通常适用于处理通过 API 接口获取的贴吧数据。首先检查内容是否为空,然后通过查找 JSON 结构的起始({)和结束(})位置,提取有效的 JSON 片段。为确保解析成功,会移除内容中可能存在的控制字符。使用 json 模块对处理后的 JSON 内容进行解析,若解析失败会捕获错误并打印详细信息(包括错误位置及附近内容),帮助排查问题。解析成功后返回 JSON 数据对象,否则返回 None。
def clean_and_parse_json(self, content):
"""清理并解析JSON内容"""
if not content:
return None
# 提取JSON部分
json_start = content.find('{')
json_end = content.rfind('}') + 1
if json_start == -1 or json_end == 0:
print("未找到有效的JSON结构")
return None
json_content = content[json_start:json_end]
json_content = re.sub(r'[\x00-\x1f\x7f]', '', json_content) # 移除控制字符
try:
return json.loads(json_content)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
return None4、从 JSON 提取标题和链接
从 JSON 提取标题和链接此方法专门用于从解析后的 JSON 数据中提取帖子标题和对应的链接。通过分析百度贴吧 API 返回的 JSON 数据结构,定位到包含帖子列表的 feed_list 数组。遍历每个帖子项,从组件信息中提取标题文本和线程 ID(tid),再利用线程 ID 构建完整的帖子链接(https://tieba.baidu.com/p/[tid])。提取到的标题和链接以字典形式返回,键为标题,值为对应的完整链接。若 JSON 数据结构不符合预期或提取过程中出现错误,会捕获异常并打印错误信息。
def extract_posts_from_json(self, data):
"""从JSON数据中提取标题和链接"""
post_dict = {}
if not data:
return post_dict
try:
feed_list = data.get('page_data', {}).get('feed_list', [])
for feed_item in feed_list:
feed = feed_item.get('feed', {})
title = ""
thread_id = ""
# 遍历组件提取标题和线程ID
for component in feed.get('components', []):
if component.get('component') == 'feed_title':
title_data = component.get('feed_title', {}).get('data', [])
title = ''.join(item.get('text_info', {}).get('text', '') for item in title_data)
elif component.get('component') == 'feed_social':
thread_id = component.get('feed_social', {}).get('tid', '')
if title and thread_id:
post_dict[title] = f"https://tieba.baidu.com/p/{thread_id}"
except Exception as e:
print(f"提取数据时出错: {e}")
return post_dict5、保存CSV
该方法用于将提取到的帖子标题和链接数据持久化到 CSV 文件中。使用 csv 模块创建写入器,首先写入表头("标题" 和 "链接"),然后遍历帖子字典,将每个标题和链接作为一行写入文件。文件采用 UTF-8 编码格式保存,确保中文等特殊字符能正确显示。若保存成功,会打印提示信息并返回 True;若出现异常(如文件权限不足、磁盘空间不足等),会捕获并打印错误信息,返回 False。默认保存的文件名为 "combined_posts.csv",也可通过参数指定其他文件名。
def save_to_csv(self, post_dict, csv_filename='combined_posts.csv'):
"""将提取的标题和链接保存到CSV文件"""
try:
with open(csv_filename, 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['标题', '链接'])
writer.writerows(post_dict.items())
print(f"数据已成功保存到 {csv_filename} 文件中!")
return True
except Exception as e:
print(f"保存CSV文件时出错: {e}")
return False四、完整爬虫代码实现
import json
import csv
import re
import urllib.request
from bs4 import BeautifulSoup, Comment
class TiebaCombinedParser:
def __init__(self):
self.headers = {
'User-Agent': "你的请求头",
"Cookie": "你的cookie"
}
def fetch_page_content(self, url):
"""获取网页内容"""
try:
request = urllib.request.Request(url, headers=self.headers)
response = urllib.request.urlopen(request)
return response.read().decode('utf-8')
except Exception as e:
print(f"获取网页内容时出错: {e}")
return None
def parse_html_content(self, html_content):
"""解析HTML内容,提取标题和链接"""
post_dict = {}
try:
soup = BeautifulSoup(html_content, 'html.parser')
# 查找帖子列表区域
pagelet = soup.find('code', id='pagelet_html_frs-list/pagelet/thread_list')
if not pagelet:
print("未找到帖子列表区域")
return post_dict
# 提取注释内容
comments = pagelet.find_all(string=lambda text: isinstance(text, Comment))
if not comments:
print("未找到注释内容")
return post_dict
# 解析注释中的HTML内容
post_soup = BeautifulSoup(comments[0], 'html.parser')
# 提取标题和链接
for li in post_soup.select('li.j_thread_list'):
a_tag = li.select_one('a.j_th_tit')
if a_tag:
title = a_tag.text.strip()
link = a_tag.get('href', '')
if link and not link.startswith('http'):
link = 'https://tieba.baidu.com' + link
post_dict[title] = link
except Exception as e:
print(f"解析HTML内容时出错: {e}")
return post_dict
def clean_and_parse_json(self, content):
"""清理并解析JSON内容"""
if not content:
return None
# 提取JSON部分
json_start = content.find('{')
json_end = content.rfind('}') + 1
if json_start == -1 or json_end == 0:
print("未找到有效的JSON结构")
return None
json_content = content[json_start:json_end]
json_content = re.sub(r'[\x00-\x1f\x7f]', '', json_content) # 移除控制字符
try:
return json.loads(json_content)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
return None
def extract_posts_from_json(self, data):
"""从JSON数据中提取标题和链接"""
post_dict = {}
if not data:
return post_dict
try:
feed_list = data.get('page_data', {}).get('feed_list', [])
for feed_item in feed_list:
feed = feed_item.get('feed', {})
title = ""
thread_id = ""
# 遍历组件提取标题和线程ID
for component in feed.get('components', []):
if component.get('component') == 'feed_title':
title_data = component.get('feed_title', {}).get('data', [])
title = ''.join(item.get('text_info', {}).get('text', '') for item in title_data)
elif component.get('component') == 'feed_social':
thread_id = component.get('feed_social', {}).get('tid', '')
if title and thread_id:
post_dict[title] = f"https://tieba.baidu.com/p/{thread_id}"
except Exception as e:
print(f"提取数据时出错: {e}")
return post_dict
def save_to_csv(self, post_dict, csv_filename='combined_posts.csv'):
"""将提取的标题和链接保存到CSV文件"""
try:
with open(csv_filename, 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['标题', '链接'])
writer.writerows(post_dict.items())
print(f"数据已成功保存到 {csv_filename} 文件中!")
return True
except Exception as e:
print(f"保存CSV文件时出错: {e}")
return False
def is_json_response(self, content):
"""判断内容是否为JSON格式"""
return '{' in content and '}' in content and ('page_data' in content or 'feed_list' in content)
def parse_from_url(self, url, output_file='combined_posts.csv'):
"""从指定URL获取内容并解析"""
print(f"开始从URL解析百度贴吧数据: {url}")
content = self.fetch_page_content(url)
if not content:
print("无法获取页面内容,程序退出")
return False
# 根据内容类型选择解析方法
if self.is_json_response(content):
print("检测到JSON格式响应,使用JSON解析器")
data = self.clean_and_parse_json(content)
post_dict = self.extract_posts_from_json(data) if data else {}
else:
print("检测到HTML格式响应,使用HTML解析器")
post_dict = self.parse_html_content(content)
# 输出并保存结果
if post_dict:
print(f"\n成功提取到 {len(post_dict)} 条帖子信息:")
for i, (title, link) in enumerate(post_dict.items(), 1):
print(f"{i}. 标题: {title}, 链接: {link}")
return self.save_to_csv(post_dict, output_file)
else:
print("未能提取到任何帖子信息")
return False
def main():
parser = TiebaCombinedParser()
# 示例URL
url = "https://tieba.baidu.com/c/f/frs/wise?sign=db8c82337fef5483617e8b4fc8ae13bf&_client_type=2&_client_version=12.77.0&subapp_type=newwise&kw=%25E7%25A6%258F%25E5%25BB%25BA%25E8%2588%25B9%25E6%2594%25BF%25E4%25BA%25A4%25E9%2580%259A%25E5%25AD%25A6%25E9%2599%25A2&pn=1&sort_type=0&is_newfrs=1&is_newfeed=1&rn=30&rn_need=10&model=Nexus%205&scr_w=824&scr_h=799"
parser.parse_from_url(url)
if __name__ == "__main__":
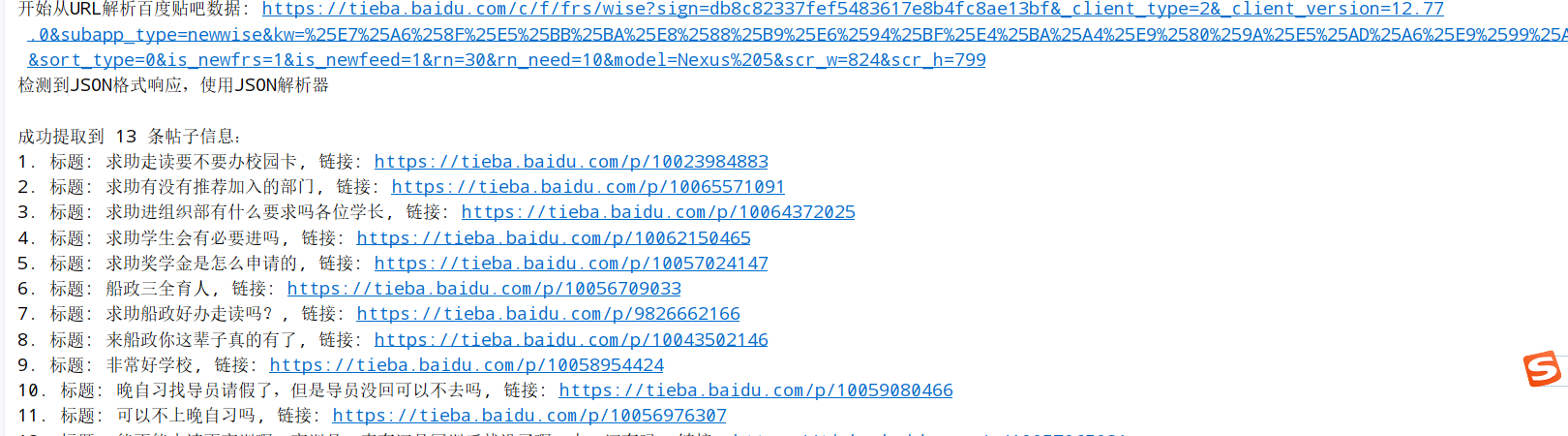
main()控制台输出示例如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号