

Pinecone向量数据库 - 详解
概述
Pinecone是一个提供托管服务的向量数据库(作为托管服务在AWS、GCP和Azure云平台上运行),用于在生产中大规模构建准确和高性能的AI应用程序;适用于需要快速上线并且不想花太多时间在数据库配置上的项目。
主要组成
组织、项目、索引、命名空间、以及数据记录等之间的相互关系:
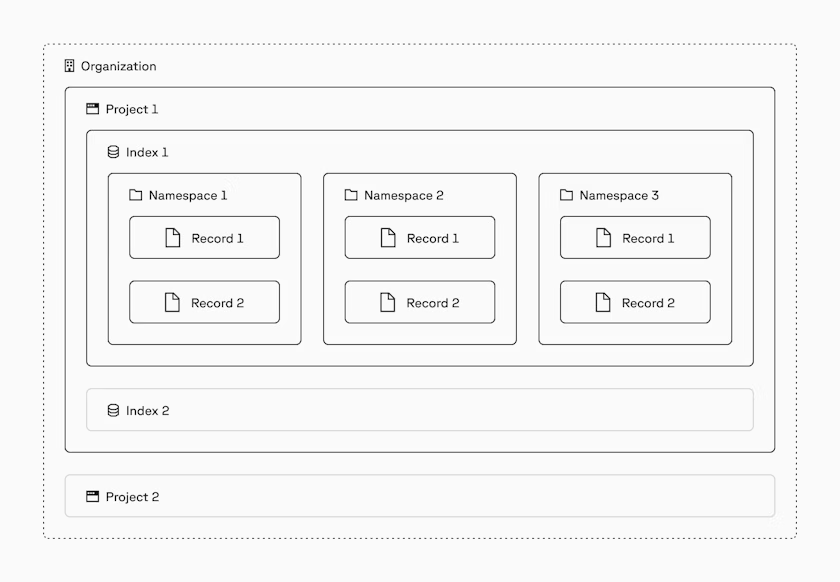
- 组织:使用相同计费的一个或者多个项目组。
- 项目:一个项目属于一个组织,并且包含一个或者多个索引。
- 命名空间:是密集索引和稀疏索引中的分区。
- 记录:存储数据的基本单位(每个记录会有一个唯一的记录ID)。
- 密集向量:是一系列代表数据含义和关系的数字,密集向量中的每个数字对应多维空间中的一个点(使用密集Embedding模型将数据转换为密集向量)。
- 稀疏向量:是具备高纬度,但只有一小部分值是非零,稀疏向量通常用于以捕获关键字信息的方式表示文档或查询。稀疏向量中的每个维度通常表示字典中的一个单词,非零值表示文档中这些单词的重要性(使用疏嵌入模型将数据转换为稀疏向量)。
应用
1、注册
如果是第一次使用Pinecone,需要在 app.pinecone.io 上进行注册并选择免费计划
1> 首先需要注册一个账号,选择合适的方式进行注册:
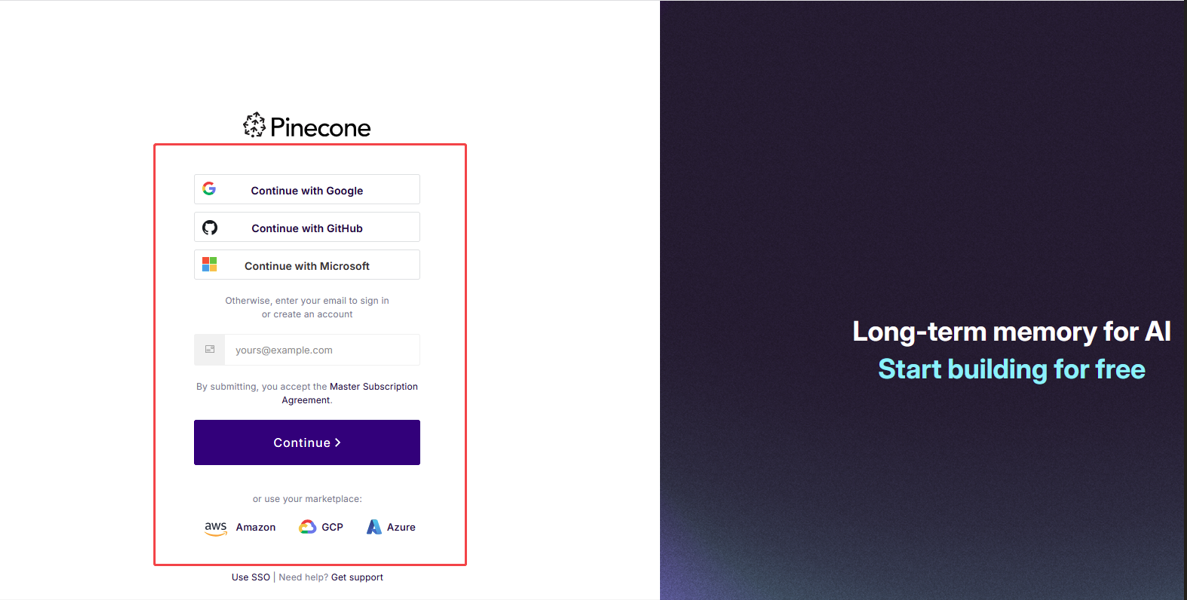
2> 注册登录之后会弹出以下选项框,选择合适的计划

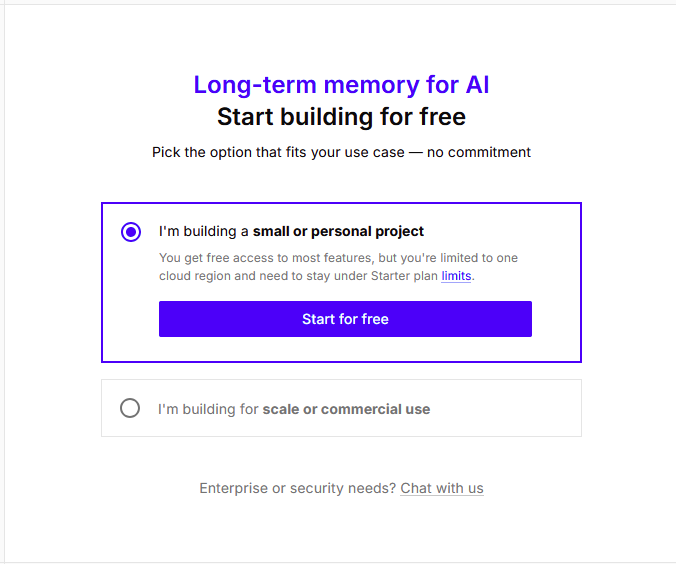
创建账号可以先选择跳过
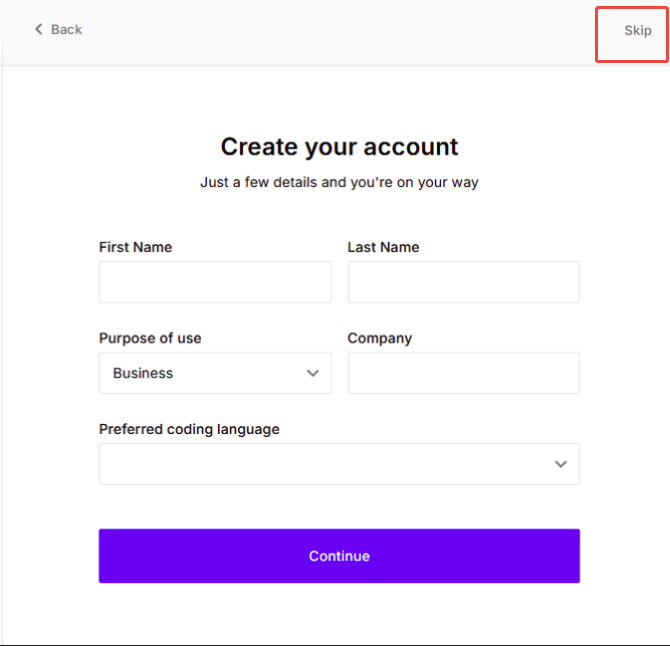
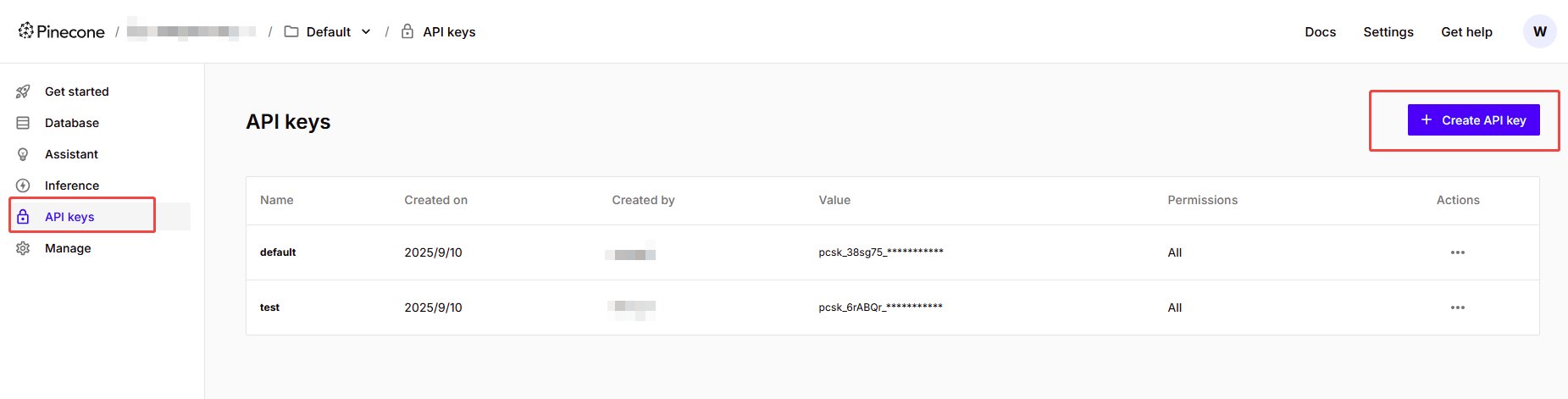
进入主页之后,会生成一个API key,后续编码时会用到该API key

使用过程中,如果忘记API key了,可以在这里重新创建
2、安装SDK
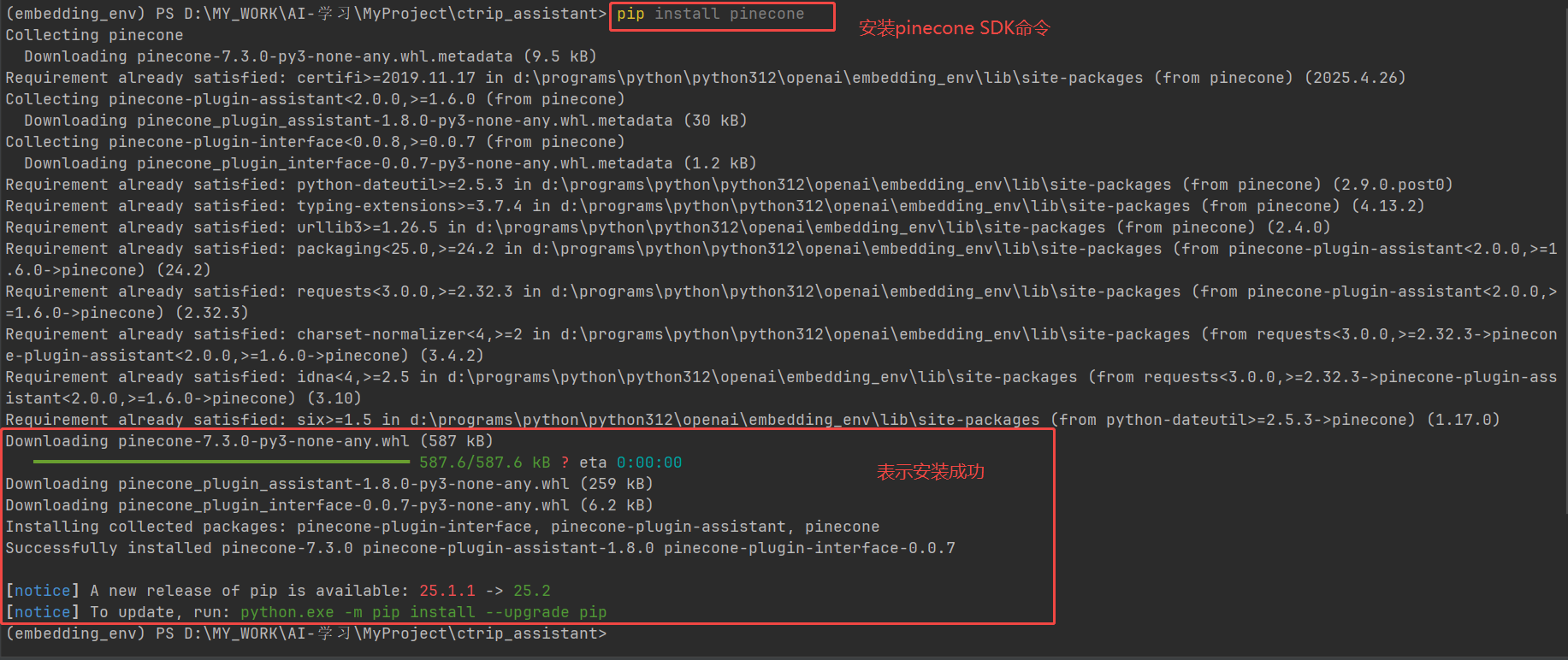
SDK支持Python、JavaScript、Java、Go和C#多种语言,具体安装方式如下:
# Python SDK安装
pip install pinecone
# JavaScript SDK安装
npm install @pinecone-database/pinecone
# Java SDK安装(Maven中配置)
# Maven
io.pinecone
pinecone-client
5.0.0
# Gradle
implementation "io.pinecone:pinecone-client:5.0.0"
# Go SDK安装
go get github.com/pinecone-io/go-pinecone/v4/pinecone
# c# SDK安装
# .NET Core CLI
dotnet add package Pinecone.Client
# NuGet CLI
nuget install Pinecone.Client本文中使用python进行使用说明,以下是安装pinecone的Python SDK:
3、代码示例
import time
# 导入 Pinecone 包
from pinecone import Pinecone
# 使用你注册时候生成的API key(或者重新生成)初始化Pinecone
pc = Pinecone(api_key="********-****-****-****-************")
# 创建一个与Pinecone托管的嵌入模型密集索引。使用Embedding模型,Pinecone会自动生成向量。
index_name = "quickstart-py" # 索引名称
if not pc.has_index(index_name):
pc.create_index_for_model(
name=index_name,
cloud="aws", # 托管的云
region="us-east-1", # 指定区域(暂时没找见国内的,暂时先用us做测试)
embed={
"model":"llama-text-embed-v2", # 指定Embedding模型
"field_map":{"text": "chunk_text"} # 指定数据集的名称
}
)
# 数据集
records = [
{ "_id": "rec1", "chunk_text": "The Eiffel Tower was completed in 1889 and stands in Paris, France.", "category": "history" },
{ "_id": "rec2", "chunk_text": "Photosynthesis allows plants to convert sunlight into energy.", "category": "science" },
{ "_id": "rec3", "chunk_text": "Albert Einstein developed the theory of relativity.", "category": "science" },
{ "_id": "rec4", "chunk_text": "The mitochondrion is often called the powerhouse of the cell.", "category": "biology" },
{ "_id": "rec5", "chunk_text": "Shakespeare wrote many famous plays, including Hamlet and Macbeth.", "category": "literature" },
]
# 目标索引
dense_index = pc.Index(index_name)
# 将数据集records更新到example-namespace命名空间(这里和其他向量数据的叫法有点区别,其他向量数据库叫集合)
dense_index.upsert_records("example-namespace", records)
# 在查询数据或更改的记录之前可能会有轻微的延迟,这里睡眠10秒
time.sleep(10)
# 查看索引的状态
stats = dense_index.describe_index_stats()
print(stats)
# 进行语义(相似性)搜索
# 需要搜索的信息
query = "Who proposed the theory of relativity"
# Search the dense index
results = dense_index.search(
namespace="example-namespace", # 执行搜索的名字空间
query={
"top_k": 3, # 返回最相似的3条记录
"inputs": {
'text': query # 需要进行相似性搜索的信息
}
}
)
# 输出搜索结果
for hit in results['result']['hits']:
# 格式化输出结果
print(f"id: {hit['_id']:<5} | score: {round(hit['_score'], 2):<5} | category: {hit['fields']['category']:<10} | text: {hit['fields']['chunk_text']:<50}")运行结果 :


 浙公网安备 33010602011771号
浙公网安备 33010602011771号