机器学习问题分类(监督学习、无监督学习、强化学习)
1.监督学习
监督学习(supervised learning)擅长在“给定输入特征”的情况下预测标签。 每个“特征-标签”对都称为一个样本(example)。
整个监督学习过程如图所示。

图 监督学习
1.1回归
回归(regression)是最简单的监督学习任务之一。当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。
生活中的许多问题都可归类为回归问题。 比如,预测用户对一部电影的评分可以被归类为一个回归问题。
1.2分类
虽然回归模型可以很好地解决“有多少”的问题,但是很多问题并非如此。 分类问题希望模型能够预测样本属于哪个类别(category,正式称为类(class))。 例如,手写数字可能有10类,标签被设置为数字0~9。 最简单的分类问题是只有两类,这被称之为二项分类(binomial classification)。
请注意,预测类别不一定是最终用于决策的类别。 举个例子现在,我们想要训练一个毒蘑菇检测分类器,根据照片预测蘑菇是否有毒。 假设这个分类器输出包含死帽蕈的概率是0.2。 换句话说,分类器80%确定图中的蘑菇不是死帽蕈。 尽管如此,我们也不会吃它,因为不值得冒20%的死亡风险。 换句话说,不确定风险的影响远远大于收益。 因此,我们需要将“预期风险”作为损失函数,即需要将结果的概率乘以与之相关的收益(或伤害)。 在这种情况下,食用蘑菇造成的损失为,而丢弃蘑菇的损失为<span class="math notranslate nohighlight">。 事实上,谨慎是有道理的。<a class="reference internal" href="https://zh.d2l.ai/chapter_introduction/index.html#fig-death-cap"><span class="std std-numref"><br />
1.3标记问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。 举个例子,人们在技术博客上贴的标签,比如“机器学习”“技术”“小工具”“编程语言”“Linux”“云计算”“AWS”。 一篇典型的文章可能会用5~10个标签,因为这些概念是相互关联的。 关于“云计算”的帖子可能会提到“AWS”,而关于“机器学习”的帖子也可能涉及“编程语言”。
1.4搜索
有时,我们不仅仅希望输出一个类别或一个实值。 在信息检索领域,我们希望对一组项目进行排序。搜索结果的排序也十分重要,学习算法需要输出有序的元素子集。 换句话说,如果要求我们输出字母表中的前5个字母,返回“A、B、C、D、E”和“C、A、B、E、D”是不同的。 即使结果集是相同的,集内的顺序有时却很重要。
该问题的一种可能的解决方案:首先为集合中的每个元素分配相应的相关性分数,然后检索评级最高的元素。
1.5推荐系统
推荐系统会为“给定用户和物品”的匹配性打分,这个“分数”可能是估计的评级或购买的概率。
尽管推荐系统具有巨大的应用价值,但单纯用它作为预测模型仍存在一些缺陷。 首先,我们的数据只包含“审查后的反馈”:用户更倾向于给他们感觉强烈的事物打分。 例如,在五分制电影评分中,会有许多五星级和一星级评分,但三星级却明显很少。 此外,推荐系统有可能形成反馈循环:推荐系统首先会优先推送一个购买量较大(可能被认为更好)的商品,然而目前用户的购买习惯往往是遵循推荐算法,但学习算法并不总是考虑到这一细节,进而更频繁地被推荐。 综上所述,关于如何处理审查、激励和反馈循环的许多问题,都是重要的开放性研究问题。
1.6序列学习
以上大多数问题都具有固定大小的输入和产生固定大小的输出。 例如,在预测房价的问题中,我们考虑从一组固定的特征:房屋面积、卧室数量、浴室数量、步行到市中心的时间; 图像分类问题中,输入为固定尺寸的图像,输出则为固定数量(有关每一个类别)的预测概率; 在这些情况下,模型只会将输入作为生成输出的“原料”,而不会“记住”输入的具体内容。
如果输入的样本之间没有任何关系,以上模型可能完美无缺。 但是如果输入是连续的,模型可能就需要拥有“记忆”功能。 比如,我们该如何处理视频片段呢? 在这种情况下,每个视频片段可能由不同数量的帧组成。 通过前一帧的图像,我们可能对后一帧中发生的事情更有把握。 语言也是如此,机器翻译的输入和输出都为文字序列。
2.无监督学习
到目前为止,所有的例子都与监督学习有关,即需要向模型提供巨大数据集:每个样本包含特征和相应标签值。 打趣一下,“监督学习”模型像一个打工仔,有一份极其专业的工作和一位极其平庸的老板。 老板站在身后,准确地告诉模型在每种情况下应该做什么,直到模型学会从情况到行动的映射。 取悦这位老板很容易,只需尽快识别出模式并模仿他们的行为即可。
相反,如果工作没有十分具体的目标,就需要“自发”地去学习了。 比如,老板可能会给我们一大堆数据,然后要求用它做一些数据科学研究,却没有对结果有要求。 这类数据中不含有“目标”的机器学习问题通常被为无监督学习(unsupervised learning), 本书后面的章节将讨论无监督学习技术。 那么无监督学习可以回答什么样的问题呢?来看看下面的例子。
-
聚类(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
-
主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?这可以用来描述实体及其关系,例如“罗马”  “意大利” <span class="math notranslate nohighlight"> “法国” <span class="math notranslate nohighlight"> “巴黎”。
-
因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
-
生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
3.与环境互动
有人一直心存疑虑:机器学习的输入(数据)来自哪里?机器学习的输出又将去往何方? 到目前为止,不管是监督学习还是无监督学习,我们都会预先获取大量数据,然后启动模型,不再与环境交互。 这里所有学习都是在算法与环境断开后进行的,被称为离线学习(offline learning)。 对于监督学习,从环境中收集数据的过程类似于 图1.3.6。

图1.3.6 从环境中为监督学习收集数据。
这种简单的离线学习有它的魅力。 好的一面是,我们可以孤立地进行模式识别,而不必分心于其他问题。 但缺点是,解决的问题相当有限。 这时我们可能会期望人工智能不仅能够做出预测,而且能够与真实环境互动。 与预测不同,“与真实环境互动”实际上会影响环境。 这里的人工智能是“智能代理”,而不仅是“预测模型”。 因此,我们必须考虑到它的行为可能会影响未来的观察结果。
4.强化学习
强化学习问题,这是一类明确考虑与环境交互的问题。 突破性的深度Q网络(Q-network)在雅达利游戏中仅使用视觉输入就击败了人类, 以及 AlphaGo 程序在棋盘游戏围棋中击败了世界冠军,是两个突出强化学习的例子。
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。 强化学习的过程在 图1.3.7 中进行了说明。 请注意,强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
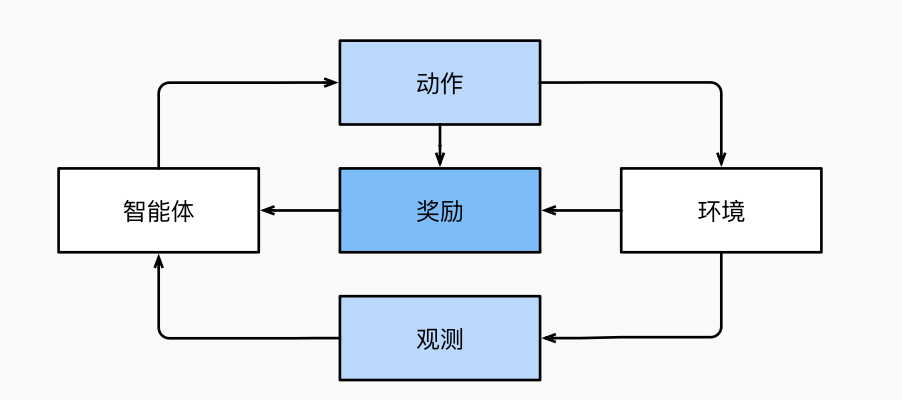
图1.3.7 强化学习和环境之间的相互作用
强化学习框架的通用性十分强大。 例如,我们可以将任何监督学习问题转化为强化学习问题。 假设我们有一个分类问题,可以创建一个强化学习智能体,每个分类对应一个“动作”。 然后,我们可以创建一个环境,该环境给予智能体的奖励。 这个奖励与原始监督学习问题的损失函数是一致的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号