爬取豆瓣电影评分top250数据分析
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
豆瓣电影TOP250数据分析
2.主题式网络爬虫爬取的内容与数据特征分析
分析豆瓣电影电影的相关类容
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
思路:网页内容的选取 对所选取网页进行html解析 ,单击鼠标右键查看网页源代码,找到关键内容的索引标签,对标签进行分析理解,提取关键字眼。导入第三方库,再将所爬取到的内容进行数据清洗.分析,绘制图形方程,以及可视化处理。
难点:对于数据的处理有较高的技术要求
二、主题页面的结构特征分析(15分)
1.主题页面的结构及特征分析
打开爬取网站https://movie.douban.com 下面内容得

导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
希望让人自由。
-
2

导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...
1993 / 中国大陆 中国香港 / 剧情 爱情 同性风华绝代。
-
3

导演: 罗伯特·泽米吉斯 Robert Zemeckis 主演: 汤姆·汉克斯 Tom Hanks / ...
1994 / 美国 / 剧情 爱情一部美国近现代史。
-
4

导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔莉·波特曼 ...
1994 / 法国 美国 / 剧情 动作 犯罪怪蜀黍和小萝莉不得不说的故事。
-
5

导演: 詹姆斯·卡梅隆 James Cameron 主演: 莱昂纳多·迪卡普里奥 Leonardo...
1997 / 美国 / 剧情 爱情 灾难失去的才是永恒的。
-
6

导演: 罗伯托·贝尼尼 Roberto Benigni 主演: 罗伯托·贝尼尼 Roberto Beni...
1997 / 意大利 / 剧情 喜剧 爱情 战争最美的谎言。
-
7

导演: 宫崎骏 Hayao Miyazaki 主演: 柊瑠美 Rumi Hîragi / 入野自由 Miy...
2001 / 日本 / 剧情 动画 奇幻最好的宫崎骏,最好的久石让。
-
8

导演: 史蒂文·斯皮尔伯格 Steven Spielberg 主演: 连姆·尼森 Liam Neeson...
1993 / 美国 / 剧情 历史 战争拯救一个人,就是拯救整个世界。
-
9

导演: 克里斯托弗·诺兰 Christopher Nolan 主演: 莱昂纳多·迪卡普里奥 Le...
2010 / 美国 英国 / 剧情 科幻 悬疑 冒险诺兰给了我们一场无法盗取的梦。
-
10

导演: 莱塞·霍尔斯道姆 Lasse Hallström 主演: 理查·基尔 Richard Ger...
2009 / 美国 英国 / 剧情永远都不能忘记你所爱的人。
# <span property="v:itemreviewed"> 肖申克的救赎 The Shawshank Redemption</span>
# <a href="/celebrity/1047973/" rel="v:directedBy"> 弗兰克·德拉邦特</a>
# <a href="/celebrity/1054521/" rel="v:starring"> 蒂姆·罗宾斯</a>
2.Htmls页面解析

三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集(20)

import requests
from bs4 import BeautifulSoup
import re
import pandas
from matplotlib import pyplot as plt
import numpy as np
import scipy as sp
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib
import seaborn as sns
from scipy.optimize import leastsq
headers = {
'Host':'movie.douban.com',
'Origin':'movie.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
}
base_url = 'https://movie.douban.com/top250?start={}&filter='
response = requests.get('https://movie.douban.com/top250?start=0&filter=', headers = headers, allow_redirects=False)
if response.status_code == 200:
# print(response.text)
pass
pattern1 = re.compile('<div.*?class="item">.*?<div.*?class="pic">.*?<a.*?href="(.*?)">', re.S) # 去掉所有换行符,并用正则表达式去匹配每一个页面的具体电影
urls = re.findall(pattern1, response.text)
directors = []# 导演名
names = []# 电影名称
stars = []# 主演人物
countrys = []# 电影的拍摄地
languages = []# 电影语言种类
typs = []# 电影类型
sorces = []# 评分
# <span property="v:itemreviewed"> 肖申克的救赎 The Shawshank Redemption</span>
# <a href="/celebrity/1047973/" rel="v:directedBy"> 弗兰克·德拉邦特</a>
# <a href="/celebrity/1054521/" rel="v:starring"> c蒂姆·罗宾斯</a>
def base_urls(base_url):
urls = []
# for i in range(0, 250, 25):
# true_url = base_url.format(i)
# print(true_url)
for i in range(0, 50, 25):
true_url = base_url.format(i)
response = requests.get(true_url, headers=headers, allow_redirects=False)
if response.status_code == 200:
# print(response.text)
pattern1 = re.compile('<div.*?class="item">.*?<div.*?class="pic">.*?<a.*?href="(.*?)">',re.S)
# 去掉所有换行符
url = re.findall(pattern1, response.text
for i in url:
urls.append(i)
return urls
def parse_url(urls):
for i in range(0, 50, 1):
res = requests.get(urls[i], headers = headers, allow_redirects=False)
if res.status_code == 200:
soup = BeautifulSoup(res.text, 'lxml')
# 爬取电影名称
name = soup.find('span', property="v:itemreviewed")
names.append(name.text)
# 爬取导演名
director = soup.find('a', rel="v:directedBy")
directors.append(director.text)
#爬取类型
typ =soup.find('span', property="v:genre")[1:]
typs.append(typ.text)
# 爬取明星
star_save = []
for star in soup.find_all('a', rel="v:starring"):
star_save.append(star.text)
stars.append(star_save)
# 爬取制片国家
#<span class="pl">制片国家/地区:</span> 美国<br>
country = soup.find('span', text='制片国家/地区:').next_sibling[1:]
countrys.append(country)
# 爬取影片语言
# <span class="pl">语言:</span>
language = soup.find('span', text='语言:').next_sibling[1:]
languages.append(language)
#爬取评分
sorce = soup.find('span', class_="rating_num")
sorces.append(sorce.text)
# print(directors)
# print(true_director)
# print(a)
if __name__ == '__main__':
base = base_urls(base_url)
parse_url(base)
print(countrys)
print(directors)
print(languages)
print(names)
print(typs)
print(sorces)
#
# 最后我们将数据写入到一个excel表格里
info ={'Filmname':names, 'Directors':directors, 'Country':countrys, 'Languages':languages, 'typs':typs, "sorce":sorces}
pdfile = pandas.DataFrame(info)
pdfile.to_excel('DoubanFilm.xlsx', sheet_name="豆瓣电影")

2.对数据进行清洗和处理(10)df = pd.DataFrame(pd.read_excel('DoubanFilm.xlsx'),columns=['Numbers','Filmname','Directors','Country','Languages','typs','score'])print(df.head())
# 读取excel文件
df.drop('Filmname', axis=1, inplace = True)
df.drop('Directors', axis=1, inplace = True)
df.drop('Languages', axis=1, inplace = True)
print(df.head())
# 删除无效行与列
print(df.isnull().sum())
print(df.isna().head())
# 统计缺失值
print(df.isna().head())
# 查找重复值
得到下面的数据

4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)(15分)
plt.rcParams['font.sans-serif']=['STSong']
# 显示中文
plt.rcParams['axes.unicode_minus']=False
# 用来正常显示负号
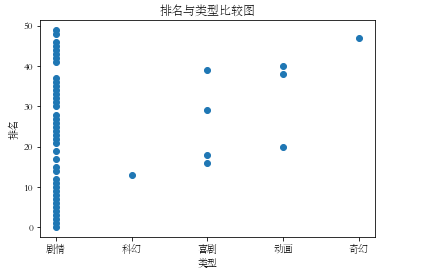
x = df.typs
y = df['Numbers'][:50]
plt.xlabel('类型')
plt.ylabel('排名')
plt.plot()
plt.scatter(x,y)
plt.title("排名与类型比较图")
plt.show()
#散点图
sns.lmplot(x='score',y='Numbers',data=df)
#线性图
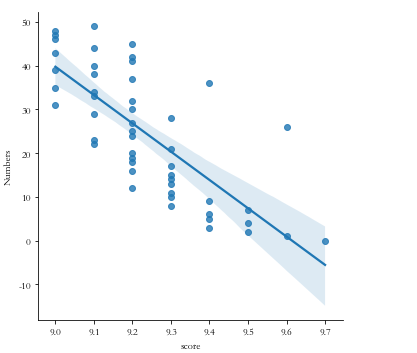
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)(10分)。
X = df.score
Y = df.Numbers
def func(params, x):
a, b, c = params
return a*x*x+b*x+c
def error(params,x,y):
return func(params,x)-y
def main(a,b,c):
p0 = [0,0,0]
Para=leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=",a,"b=",b,"c=",c)
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=a*x*x+b*x+c
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.legend()
plt.grid()
plt.show()
main()
#一元二次回归方程
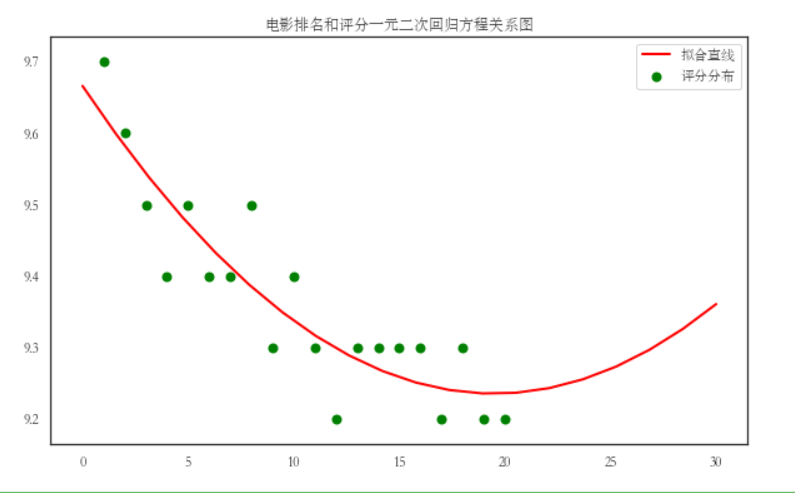
7.将以上各部分的代码汇总,附上完整程序代码
1 import requests
2 from bs4 import BeautifulSoup
3 import re
4 import pandas
5 from matplotlib import pyplot as plt
6 import numpy as np
7 import scipy as sp
8 import pandas as pd
9 from matplotlib import pyplot as plt
10 import matplotlib
11 import seaborn as sns
12 from scipy.optimize import leastsq
13
14 headers = {
15 'Host':'movie.douban.com',
16 'Origin':'movie.douban.com',
17 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36',
18 }
19 base_url = 'https://movie.douban.com/top250?start={}&filter='
25 response = requests.get('https://movie.douban.com/top250?start=0&filter=', headers = headers, allow_redirects=False)
26 if response.status_code == 200:
27 # print(response.text)
28 pass
29
30 pattern1 = re.compile('<div.*?class="item">.*?<div.*?class="pic">.*?<a.*?href="(.*?)">', re.S) # 去掉所有换行符,并用正则表达式去匹配每一个页面的具体电影
31 urls = re.findall(pattern1, response.text)
32
33 directors = [] # 导演名
34
35 names = [] # 电影名称
36
37 stars = [] # 主演人物
38
39 countrys = [] # 电影拍摄地
41 languages = [] # 电影语言种类
42
43 typs = [] # 电影类型
44
45 sorces = [] #评分
46
47 # <span property="v:itemreviewed">肖申克的救赎 The Shawshank Redemption</span>
48 # <a href="/celebrity/1047973/" rel="v:directedBy">弗兰克·德拉邦特</a>
49 # <a href="/celebrity/1054521/" rel="v:starring">蒂姆·罗宾斯</a>
50 def base_urls(base_url):
51 urls = []
52
53 # for i in range(0, 250, 25):
54 # true_url = base_url.format(i)
55 # print(true_url)
56 for i in range(0, 50, 25):
57 true_url = base_url.format(i)
58
59 response = requests.get(true_url, headers=headers, allow_redirects=False)
60 if response.status_code == 200:
61 # print(response.text)
62
63 pattern1 = re.compile('<div.*?class="item">.*?<div.*?class="pic">.*?<a.*?href="(.*?)">',re.S)
64 # 去掉所有换行符,并用正则表达式去匹配每一个页面的具体电影
65 url = re.findall(pattern1, response.text)
66 # 因为这里是用findall,他返回的是一个列表,如果我们直接append,会导致列表嵌套,故我们这里用个for循环提取出列表的元素再append进去
67
68 for i in url:
69 urls.append(i)
70 return urls
71
72 def parse_url(urls):
73
74 for i in range(0, 50, 1):
75 res = requests.get(urls[i], headers = headers, allow_redirects=False)
76 if res.status_code == 200:
77 soup = BeautifulSoup(res.text, 'lxml')
78 # 爬取电影名
79 name = soup.find('span', property="v:itemreviewed")
80 names.append(name.text)
81
82 # 爬取导演
83 director = soup.find('a', rel="v:directedBy")
84 directors.append(director.text)
85
86 #爬取类型
87 typ =soup.find('span', property="v:genre")[1:]
88 typs.append(typ.text)
89
90 # 爬取明星
91 star_save = []
92 for star in soup.find_all('a', rel="v:starring"):
93 star_save.append(star.text)
94 stars.append(star_save)
95
96
97 # 爬取制片国家
98 #<span class="pl">制片国家/地区:</span> 美国<br>
99 country = soup.find('span', text='制片国家/地区:').next_sibling[1:]
100 countrys.append(country)
101
102
103 # 爬取影片语言
104 # <span class="pl">语言:</span>
105 language = soup.find('span', text='语言:').next_sibling[1:]
106 languages.append(language)
107
108 #爬取评分
109 sorce = soup.find('span', class_="rating_num")
110 sorces.append(sorce.text)
111
112 # print(directors)
113 # print(true_director)
114 # print(a)
115 if __name__ == '__main__':
116 base = base_urls(base_url)
117 parse_url(base)
118 print(countrys)
119 print(directors)
120 print(languages)
121 print(names)
122 print(typs)
123 print(sorces)
124 125 # 最后我们将数据写入到一个excel表格里
126 info ={'Filmname':names, 'Directors':directors, 'Country':countrys, 'Languages':languages, 'typs':typs, "sorce":sorces}
127 pdfile = pandas.DataFrame(info)
128
129 pdfile.to_excel('DoubanFilm.xlsx', sheet_name="豆瓣电影")
130
131 #读取excel
132 df = pd.DataFrame(pd.read_excel('DoubanFilm.xlsx'),columns=['Numbers','Filmname','Directors','Country','Languages','typs','score'])
133 print(df.head())
134
135 # 删除无效行与列
136 df.drop('Filmname', axis=1, inplace = True)
137 df.drop('Directors', axis=1, inplace = True)
138 df.drop('Languages', axis=1, inplace = True)
139 print(df.head())
140
141 print(df.isnull().sum())
142 # 返回0,表示没有空值
143 print(df.isna().head())
144 # 统计缺失值
145 print(df.isna().head())
146 # 查找重复值
147 plt.rcParams['font.sans-serif']=['STSong']
148 # 显示中文
149 plt.rcParams['axes.unicode_minus']=False
150 # 用来正常显示负号
151
152 x = df.typs
153 y = df['Numbers'][:50]
154 plt.xlabel('类型')
155 plt.ylabel('排名')
156 plt.bar(x,y)
157 plt.title("排名与类型比较图")
158 plt.show()
159 #柱状图
160
161 x = df.typs
162 y = df['Numbers'][:50]
163 plt.xlabel('类型')
164 plt.ylabel('排名')
165 plt.plot()
166 plt.scatter(x,y)
167 plt.title("排名与类型比较图")
168 plt.show()
169 #散点图
170
171 sns.lmplot(x='score',y='Numbers',data=df)
172 #线性图
173
174 X = df.score
175 Y = df.Numbers
176 def func(params, x):
177 a, b, c = params
178 return a*x*x+b*x+c
179 def error(params,x,y):
180 return func(params,x)-y
181 def main(a,b,c):
182 p0 = [0,0,0]
183 Para=leastsq(error,p0,args=(X,Y))
184 a,b,c=Para[0]
185 print("a=",a,"b=",b,"c=",c)
186 plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
187 x=np.linspace(0,30,20)
188 y=a*x*x+b*x+c
189 plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
190 plt.title("电影排名和评分关系图")
191 plt.legend()
192 plt.grid()
193 plt.show()
194 main()
#一元二次回归方程
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对主题数据的分析与可视化可以更直观的了解数据
2.对本次程序设计任务完成的情况做一个简单的小结。
通过此次作业了解到了对于函数熟悉应用重要性以及
通过对代码不断的修改,对于python有进一步的认识
