
一、问题产生
雪崩效应:是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程
正常情况下的服务:
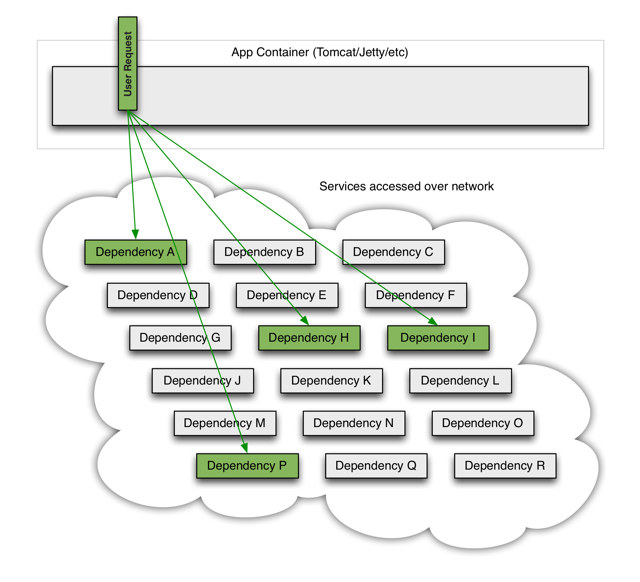
某一服务出现异常,拖垮整个服务链路,消耗整个线程队列,造成服务不可用,资源耗尽:
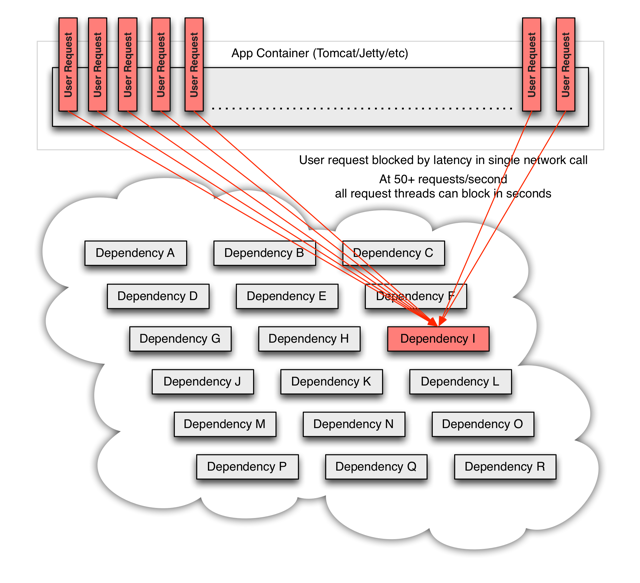
形成过程:
1)服务提供者不可用
a)硬件故障:硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问
b)程序Bug:
c) 缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用
d)用户大量请求:在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用
2)重试加大流量
a)用户重试:在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单
b)代码逻辑重试: 服务调用端的会存在大量服务异常后的重试逻辑
3)服务调用者不可用
a)同步等待造成的资源耗尽:当服务调用者使用同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
二、概念
- 服务熔断:
一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。很多时候刚开始可能只是系统出现了局部的、小规模的故障,然而由于种种原因,故障影响的范围越来越大,最终导致了全局性的后果。
适用场景:防止应用程序直接调用那些很可能会调用失败的远程服务或共享资源 - 服务降级:
当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
三、工作原理
Hystrix 是一个帮助解决分布式系统交互时超时处理和容错的类库, 它同样拥有保护系统的能力。Netflix的众多开源项目之一。
1. 隔离:
Hystrix隔离方式采用线程/信号的方式,通过隔离限制依赖的并发量和阻塞扩散
1)线程隔离
Hystrix在用户请求和服务之间加入了线程池。
Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。线程数是可以被设定的。
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
隔离前:

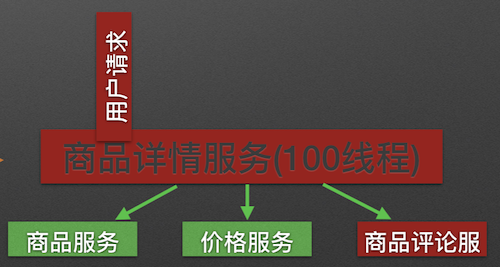
隔离后:

b)信号隔离:
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请, 如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销。信号量的大小可以动态调整, 线程池大小不可以。(参考文章2)
2. 熔断:
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断器:Circuit Breaker
熔断器是位于线程池之前的组件。用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。每个熔断器默认维护10个bucket ,每秒创建一个bucket ,每个blucket记录成功,失败,超时,拒绝的次数。当有新的bucket被创建时,最旧的bucket会被抛弃。
熔断器的状态机:
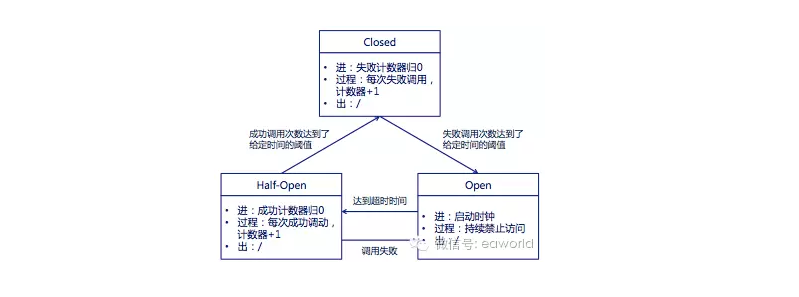
- Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
- Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
- Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
四、流程
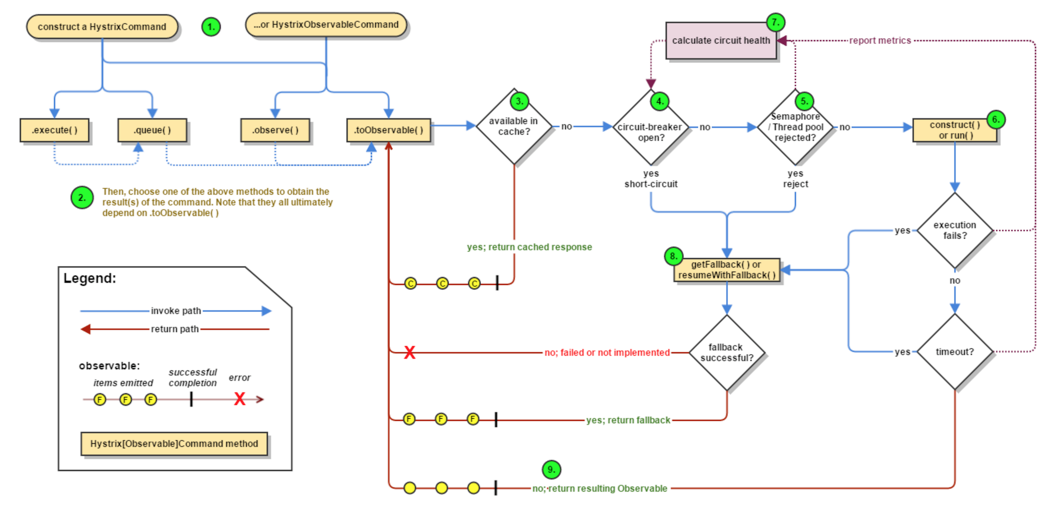
流程说明:1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中。2:执行execute()/queue做同步或异步调用。3:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤。4:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤。5:调用HystrixCommand的run方法。运行依赖逻辑5a:依赖逻辑调用超时,进入步骤8。6:判断逻辑是否调用成功6a:返回成功调用结果6b:调用出错,进入步骤8。7:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态。8:getFallback()降级逻辑。 以下四种情况将触发getFallback调用: (1):run()方法抛出非HystrixBadRequestException异常 (2):run()方法调用超时 (3):熔断器开启拦截调用 (4):线程池/队列/信号量是否跑满8a:没有实现getFallback的Command将直接抛出异常8b:fallback降级逻辑调用成功直接返回8c:降级逻辑调用失败抛出异常9:返回执行成功结果五、执行方式
同步执行:即一旦开始执行该命令,当前线程就得阻塞着直到该命令返回结果,然后才能继续执行下面的逻辑
异步执行:命令开始执行会返回一个Future<T>的对象,不阻塞后面的逻辑,开发者自己根据需要去获取结果。
响应式执行:命令开始执行会返回一个Observable<T> 对象,开发者可以给给Obeservable对象注册上Observer或者Action1对象,响应式地处理命令执行过程中的不同阶段。当调用HystrixCommand的observe()方法,或使用Observable的工厂方法(just(),from())即为响应式执行,这个功能的实现是基于Netflix的另一个开源项目RxJava(https://github.com/Netflix/RxJava)来的,更细节的用法可以参考:https://github.com/Netflix/Hystrix/wiki/How-To-Use#wiki-Reactive-Execution。
六、代码实现
jar包:
<dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystrix-core</artifactId> <version>1.4.21</version></dependency> |
|
参数
|
作用
|
备注
|
|---|---|---|
|
circuitBreaker.errorThresholdPercentage |
失败率达到多少百分比后熔断 |
默认值:50 主要根据依赖重要性进行调整 |
|
circuitBreaker.forceClosed |
是否强制关闭熔断 | 如果是强依赖,应该设置为true |
|
circuitBreaker.requestVolumeThreshold |
熔断触发的最小个数/10s | 默认值:20 |
|
circuitBreaker.sleepWindowInMilliseconds |
熔断多少秒后去尝试请求 | 默认值:5000 |
|
commandKey |
默认值:当前执行方法名 | |
|
coreSize |
线程池coreSize |
默认值:10 |
|
execution.isolation.semaphore.maxConcurrentRequests |
信号量最大并发度 | SEMAPHORE模式有效,默认值:10 |
|
execution.isolation.strategy |
隔离策略,有THREAD和SEMAPHORE |
默认使用THREAD模式,以下几种可以使用SEMAPHORE模式:
|
|
execution.isolation.thread.interruptOnTimeout |
是否打开超时线程中断 | THREAD模式有效 |
|
execution.isolation.thread.timeoutInMilliseconds
|
超时时间 |
默认值:1000 在THREAD模式下,达到超时时间,可以中断 在SEMAPHORE模式下,会等待执行完成后,再去判断是否超时 |
|
execution.timeout.enabled |
是否打开超时 | |
|
fallback.isolation.semaphore.maxConcurrentRequests |
fallback最大并发度 | 默认值:10 |
|
groupKey |
表示所属的group,一个group共用线程池 |
默认值:getClass().getSimpleName(); |
|
maxQueueSize |
请求等待队列 |
默认值:-1 如果使用正数,队列将从SynchronizeQueue改为LinkedBlockingQueue |
| hystrix.command.default.metrics.rollingStats.timeInMilliseconds | 设置统计的时间窗口值的,毫秒值 | circuit break 的打开会根据1个rolling window的统计来计算。若rolling window被设为10000毫秒,则rolling window会被分成n个buckets,每个bucket包含success,failure,timeout,rejection的次数的统计信息。默认10000 |
| hystrix.command.default.metrics.rollingStats.numBuckets | 设置一个rolling window被划分的数量 | |
| hystrix.command.default.metrics.healthSnapshot.intervalInMilliseconds | 记录health 快照(用来统计成功和错误绿)的间隔,默认500ms |
七、参考文章
官方文档:https://github.com/Netflix/Hystrix/wiki
同步异步反应执行三种方式示例:Hystrix使用&设置准则#2.使用
http://mvnrepository.com/artifact/com.netflix.hystrix/hystrix-javanica
