k8s环境集群环境搭建
K8s集群安装部署(CentOS系统)
一. 安装要求
在开始之前,部署Kubernetes集群机器需要满足以下几个条件:
1、一台或多台机器,操作系统 CentOS7.x-86_x64
2、硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多
3、集群中所有机器之间网络互通
4、可以访问外网,需要拉取镜像
5、禁止swap分区
6、有docker环境
二. 所有节点准备环境
1、【所有节点】关闭防火墙:
systemctl stop firewalld #暂停防火墙
systemctl disable firewalld #设置开机禁用防火墙
systemctl status firewalld #检查防火墙状态
2、【所有节点】关闭selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config #selinux为disabled
setenforce 0 #设置SELinux 成为permissive模式(许可模式)
3、【所有节点】关闭swap:
swapoff -a #将/etc/fstab文件中所有设置为swap的设备关闭,立即生效
vim /etc/fstab $ 永久
将 /dev/mapper/centos-swap swap swap default 0 0 这一行前面加个 # 号将其注释掉 #设置后开机后就不会开启swap功能
4、【所有节点】添加主机名与IP对应关系(记得设置主机名):
设置主机名:(此步可以按需求设置,对应host文件)
hostnamectl set-hostname 主机名字 #设置主机名
hostname #查看当前主机名
注意:设置完后需要reboot才能生效。
5.【所有节点】更改host文件
$ vi /etc/hosts
172.16.x.xx master
172.16.x.xx node1
172.16.x.xx node2
6.【所有节点】将桥接的IPv4流量传递到iptables的链:
有一些ipv4的流量不能走iptables链,linux内核的一个过滤器,每个流量都会经过他,然后再匹配是否可进入当前应用进程去处理,导致流量丢失
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
$ sysctl --system #手动加载所有的配置文件
7.【所有节点】添加阿里云YUM软件源
GFW原因访问国外资源比较慢,所以这里需要借助国内源来实现加速效果
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
三.安装必要组件
【所有节点】安装kubeadm,kubelet和kubectl
yum install -y kubeadm-1.20.5 kubelet-1.20.5 kubectl-1.20.5 #安装kubeadm、kubelet、kubectl
systemctl enable kubelet # 启动服务并设置开机自启动
四. 安装kubernetes Master
1、[ Master节点 ]执行部署Kubernetes Master
注意将apiserver-advertise-address的ip地址更改为本机ip
kubeadm init --kubernetes-version v1.20.5 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.233.0.0/16 --apiserver-advertise-address=192.168.4.39
回显结果要保存,后面node加入master需要用到
参数说明:
- kubernetes-version: 安装指定版本的 k8s 版本,该参数和 kubeadm 的版本有关,特定版本的 kubeadm 并不能安装所有版本的 k8s,最好还是 kubeadm 的版本和该参数指定的版本一致。
- image-repository: 该参数仅在高版本(具体哪个版本没仔细查,反正在 1.13.x 中是支持的)的 kubeadm 中支持,用来设置 kubeadm 拉取 k8s 各组件镜像的地址,默认拉取的地址是:k8s.gcr.io。众所周知 k8s.gcr.io 国内是无法访问的,所以在这里改为阿里云镜像仓库。
- pod-network-cidr: 设置 pod ip 的网段 ,网段之所以是 10.244.0.0/16,是因为后面安装 flannel 网络插件时,yaml 文件里面的 ip 段也是这个,两个保持一致,不然可能会使得 Node 间 Cluster IP 不通。这个参数必须得指定,如果这里不设置的话后面安装 flannel 网络插件时会报如下错误:
E0317 17:02:15.077598 1 main.go:289] Error registering network: failed to acquire lease: node "k8s-master" pod cidr not assigned
-
apiserver-advertise-address: API server 用来告知集群中其它成员的地址,这个参数也必须得设置,否则 api-server 容器启动不起来,该参数的值为 master 节点所在的本地 ip 地址。
kubeadm 以后将会在 /etc 路径下生成配置文件和证书文件
[root@k8s-master etc]# tree kubernetes/
kubernetes/
├── admin.conf
├── controller-manager.conf
├── kubelet.conf
├── manifests
│ ├── etcd.yaml
│ ├── kube-apiserver.yaml
│ ├── kube-controller-manager.yaml
│ └── kube-scheduler.yaml
├── pki
│ ├── apiserver.crt
│ ├── apiserver-etcd-client.crt
│ ├── apiserver-etcd-client.key
│ ├── apiserver.key
│ ├── apiserver-kubelet-client.crt
│ ├── apiserver-kubelet-client.key
│ ├── ca.crt
│ ├── ca.key
│ ├── etcd
│ │ ├── ca.crt
│ │ ├── ca.key
│ │ ├── healthcheck-client.crt
│ │ ├── healthcheck-client.key
│ │ ├── peer.crt
│ │ ├── peer.key
│ │ ├── server.crt
│ │ └── server.key
│ ├── front-proxy-ca.crt
│ ├── front-proxy-ca.key
│ ├── front-proxy-client.crt
│ ├── front-proxy-client.key
│ ├── sa.key
│ └── sa.pub
└── scheduler.conf。
2、[ Master节点 ]配置可以使用kubectl工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。
### 3、[ 所有节点 ]加入Kubernetes Node
> 在所有【Node】节点执行。 注意!!! 执行此操作前需要安装[calico网络插件](五.安装calico网络插件)
>
> 向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:这个在master init初始化时会有提示,更换为自己master的IP和token。
例如:
```shell
kubeadm join 192.168.x.x:6443 --token 8rzfx1.0mliir0mjure3cq0 \
--discovery-token-ca-cert-hash sha256:cf6496e029192677b6761569f8d6e1088287d27447598dd57cb01809829ecea2
节点加入kubernetes后检查node状态
$ kubectl get nodes
在调试 Kubernetes 集群时,最重要的手段就是用 kubectl describe 来查看这个节点(Node)对象的详细信息、状态和事件(Event),我们来试一下:
$ kubectl describe node master
...
Conditions:
...
Ready False ... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
通过 kubectl describe 指令的输出,我们可以看到 NodeNotReady 的原因在于,我们尚未部署任何网络插件。
五.安装calico网络插件
1.【master节点】下载 Calico 配置文件
curl https://docs.projectcalico.org/v3.9/manifests/calico-etcd.yaml -O
2.修改etcd配置
# 修改网络配置
POD_CIDR=`grep 'cluster-cidr' /etc/kubernetes/manifests/kube-controller-manager.yaml | awk -F= '{print $2}'`
sed -i -e "s?192.168.0.0/16?$POD_CIDR?g" calico-etcd.yaml
3.修改证书
sed -i 's/# \(etcd-.*\)/\1/' calico-etcd.yaml
etcd_key=$(cat /etc/kubernetes/pki/etcd/peer.key | base64 -w 0)
etcd_crt=$(cat /etc/kubernetes/pki/etcd/peer.crt | base64 -w 0)
etcd_ca=$(cat /etc/kubernetes/pki/etcd/ca.crt | base64 -w 0)
sed -i -e 's/\(etcd-key: \).*/\1'$etcd_key'/' \
-e 's/\(etcd-cert: \).*/\1'$etcd_crt'/' \
-e 's/\(etcd-ca: \).*/\1'$etcd_ca'/' calico-etcd.yaml
4.修改 etcd 地址
ETCD=$(grep 'advertise-client-urls' /etc/kubernetes/manifests/etcd.yaml | awk -F= '{print $2}')
sed -i -e 's/\(etcd_.*:\).*#/\1/' \
-e 's/replicas: 1/replicas: 2/' calico-etcd.yaml
5.指定探测网卡
注意:需要将interface值改为master 的网卡
sed '/autodetect/a\ - name: IP_AUTODETECTION_METHOD\n value: "interface=ens192"' -i calico-etcd.yaml
6.修改calico.yaml配置
echo $ETCD #查看etcd的地址
打开calico.yaml文件将data下etcd_endpoints值改为etcd地址
7.开始创建calico
kubectl apply -f calico-etcd.yaml
kubectl get pod/svc/deployment -n kube-system #查看calico相关的服务是否正常
通过 Taint/Toleration 调整 Master 执行 Pod 的策略
默认情况下 Master 节点是不允许运行用户 Pod 的。而 Kubernetes 做到这一点,依靠的是 Kubernetes 的 Taint/Toleration 机制。
它的原理非常简单:一旦某个节点被加上了一个 Taint,即被“打上了污点”,那么所有 Pod 就都不能在这个节点上运行,因为 Kubernetes 的 Pod 都有“洁癖”。
除非,有个别的 Pod 声明自己能“容忍”这个“污点”,即声明了 Toleration,它才可以在这个节点上运行。
为节点打上“污点”(Taint)的命令是:
kubectl taint nodes node1 foo=bar:NoSchedule
这时候该 node1 节点上就会增加一个键值对格式的 Taint,即:foo=bar:NoSchedule。其中值里面的 NoSchedule,意味着这个 Taint 只会在调度新 Pod 时产生作用,而不会影响已经在 node1 上运行的 Pod,哪怕它们没有 Toleration。
Pod声明 Toleration :
只要在 Pod 的.yaml 文件中的 spec 部分,加入 tolerations 字段即可:
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "foo"
operator: "Equal"
value: "bar"
effect: "NoSchedule"
这个 Toleration 的含义是,这个 Pod 能“容忍”所有键值对为 foo=bar 的 Taint( operator: “Equal”,“等于”操作)。
回到集群上,这时候通过kubectl describe检查一下Master 节点的 Taint 字段,就会有所发现了:
$ kubectl describe node master
Name: master
Roles: master
Taints: node-role.kubernetes.io/master:NoSchedule
可以看到,Master 节点默认被加上了node-role.kubernetes.io/master:NoSchedule这样一个“污点”,其中“键”是node-role.kubernetes.io/master,而没有提供“值”。
此时,你就需要像下面这样用“Exists”操作符(operator: “Exists”,“存在”即可)来说明,该 Pod 能够容忍所有以 foo 为键的 Taint,才能让这个 Pod 运行在该 Master 节点上:
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "foo"
operator: "Exists"
effect: "NoSchedule"
如果你就是想要一个单节点的 Kubernetes,删除这个 Taint 才是正确的选择:
kubectl taint nodes --all node-role.kubernetes.io/master-
如上所示,我们在“node-role.kubernetes.io/master”这个键后面加上了一个短横线“-”,这个格式就意味着移除所有以“node-role.kubernetes.io/master”为键的 Taint。
有了 kubeadm 这样的原生管理工具,Kubernetes 的部署已经被大大简化。更重要的是,像证书、授权、各个组件的配置等部署中最麻烦的操作,kubeadm 都已经帮你完成了。
接下来,我们再在这个 Kubernetes 集群上安装一些其他的辅助插件,比如 Dashboard 和存储插件。
部署 Dashboard 可视化插件
它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
部署完成之后,我们就可以查看 Dashboard 对应的 Pod 的状态了:
[19:22:05 root@lyp-master kubernetes]#kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kubernetes-dashboard dashboard-metrics-scraper-5b8896d7fc-gmkvw 1/1 Running 0 55s
kubernetes-dashboard kubernetes-dashboard-897c7599f-9h7sq 1/1 Running 0 56s
注意的是,由于 Dashboard 是一个 Web Server,很多人经常会在自己的公有云上无意地暴露 Dashboard 的端口,从而造成安全隐患。所以,1.7 版本之后的 Dashboard 项目部署完成后,默认只能通过 Proxy 的方式在本地访问。
执行
kubectl proxy
而如果你想从集群外访问这个 Dashboard 的话,就需要用到 Ingress
部署容器存储插件
Kubernetes 集群的最后一块拼图:容器持久化存储
- 无状态
如果你在某一台机器上启动的一个容器,显然无法看到其他机器上的容器在它们的数据卷里写入的文件。这是容器最典型的特征之一:无状态。
- 持久化
容器的持久化存储,就是用来保存容器存储状态的重要手段:存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论你在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。
常见可以为 Kubernetes 提供持久化存储能力储存项目
- Ceph
- GlusterFS
- NFS
储存插件项目Rook
Rook 项目是一个基于 Ceph 的 Kubernetes 存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对 Ceph 的简单封装,Rook 在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
使用rook部署Ceph储存后端
kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/common.yaml
kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml
kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/cluster.yaml
部署完成后,你就可以看到 Rook 项目会将自己的 Pod 放置在由它自己管理的两个 Namespace 当中:
kubectl get pods -n rook-ceph-system
NAME READY STATUS RESTARTS AGE
rook-ceph-agent-7cv62 1/1 Running 0 15s
rook-ceph-operator-78d498c68c-7fj72 1/1 Running 0 44s
rook-discover-2ctcv 1/1 Running 0 15s
kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-mon0-kxnzh 1/1 Running 0 13s
rook-ceph-mon1-7dn2t 1/1 Running 0 2s
一个基于 Rook 持久化存储集群就以容器的方式运行起来了,而接下来在 Kubernetes 项目上创建的所有 Pod 就能够通过 Persistent Volume(PV)和 Persistent Volume Claim(PVC)的方式,在容器里挂载由 Ceph 提供的数据卷了。
为什么要选择 Rook 项目?
Rook 项目的实现,就会发现它巧妙地依赖了 Kubernetes 提供的编排能力,合理的使用了很多诸如 Operator、CRD 等重要的扩展特性。这使得 Rook 项目,成为了目前社区中基于 Kubernetes API 构建的最完善也最成熟的容器存储插件。
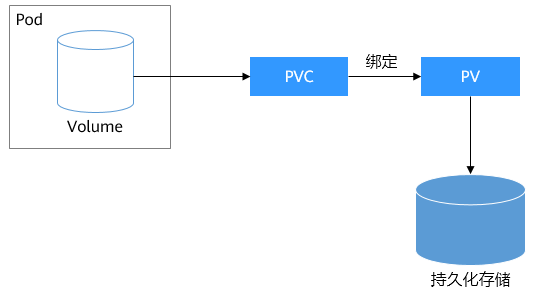
pv 与 pvc
PV全称叫做Persistent Volume,持久化存储卷。(主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置)
PVC是用来描述希望使用什么样的或者说是满足什么条件的存储,它的全称是Persistent Volume Claim,也就是持久化存储声明。(主要包括存储空间请求、访问模式、PV选择条件和存储类别等信息的设置)
PersistentVolumeClaims允许用户使用抽象存储资源,但是PersistentVolumes对于不同的问题,用户通常需要具有不同属性(例如性能)。群集管理员需要能够提供各种PersistentVolumes不同的方式,而不仅仅是大小和访问模式,而不会让用户了解这些卷的实现方式。对于这些需求,有StorageClass 资源。
StorageClass为管理员提供了一种描述他们提供的存储的“类”的方法。 不同的类可能映射到服务质量级别,或备份策略,或者由群集管理员确定的任意策略。 Kubernetes本身对于什么类别代表是不言而喻的。 这个概念有时在其他存储系统中称为“配置文件”。
pvc和pv是一一对应的。
生命周期
PV是群集中的资源。PVC是对这些资源的请求,并且还充当对资源的检查。PV和PVC之间的相互作用遵循以下生命周期:
Provisioning ( /prə'viʒəniŋ/)发布——-> Binding( /ˈbaɪndɪŋ/)绑定 ——–>Using( /ˈjuːzɪŋ/)使用——>Releasing( /rɪ'li:sɪŋ/)释放
——>Recycling( /ˌriːˈsaɪklɪŋ/)回收
-
供应准备Provisioning---通过集群外的存储系统或者云平台来提供存储持久化支持。
- - 静态提供Static:集群管理员创建多个PV。 它们携带可供集群用户使用的真实存储的详细信息。 它们存在于Kubernetes API中,可用于消费
- - 动态提供Dynamic:当管理员创建的静态PV都不匹配用户的PersistentVolumeClaim时,集群可能会尝试为PVC动态配置卷。 此配置基于StorageClasses:PVC必须请求一个类,并且管理员必须已创建并配置该类才能进行动态配置。 要求该类的声明有效地为自己禁用动态配置。
-
绑定Binding---用户创建pvc并指定需要的资源和访问模式。在找到可用pv之前,pvc会保持未绑定状态。
-
使用Using---用户可在pod中像volume一样使用pvc。
-
释放Releasing---用户删除pvc来回收存储资源,pv将变成“released”状态。由于还保留着之前的数据,这些数据需要根据不同的策略来处理,否则这些存储资源无法被其他pvc使用。
-
回收Recycling---pv
可以设置三种回收策略:保留(Retain),回收(Recycle)和删除(Delete)。
- - 保留策略:允许人工处理保留的数据。
- - 删除策略:将删除pv和外部关联的存储资源,需要插件支持。
- - 回收策略:将执行清除操作,之后可以被新的pvc使用,需要插件支持。
注:目前只有NFS和HostPath类型卷支持回收策略,AWS EBS,GCE PD,Azure Disk和Cinder支持删除(Delete)策略。
pv类型
- GCEPersistentDisk
- AWSElasticBlockStore
- AzureFile
- AzureDisk
- FC (Fibre Channel)
- Flexvolume
- Flocker
- NFS
- iSCSI
- RBD (Ceph Block Device)
- CephFS
- Cinder (OpenStack block storage)
- Glusterfs
- VsphereVolume
- Quobyte Volumes
- HostPath (Single node testing only – local storage is not supported in any way and WILL NOT WORK in a multi-node cluster)
- Portworx Volumes
- ScaleIO Volumes
- StorageOS
pv卷阶段状态
- Available – 资源尚未被claim使用
- Bound – 卷已经被绑定到claim了
- Released – claim被删除,卷处于释放状态,但未被集群回收。
- Failed – 卷自动回收失败
pv&pvc&StorageClass小总结:
- PVC和PV相当于面向对象的接口和实现
- 用户创建的Pod声明了PVC,K8S会找一个PV配对,如果没有PV,就去找对应的StorageClass,帮它创建一个PV,然后和PVC完成绑定
- 新创建的PV,要经过Master节点Attach为宿主机创建远程磁盘,再经过每个节点kubelet组件把Attach的远程磁盘Mount到宿主机目录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号