
MySQL对已存在的数据表增加分区
思路2:建新表–>备份–>删原表–>改名
①建新表
CREATE TABLE `t_send_message_send2` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `plan_id` bigint(20) DEFAULT NULL, `job_uuid` varchar(36) DEFAULT NULL, `send_port` varchar(16) DEFAULT NULL, `mobile` varchar(16) DEFAULT NULL, `content` varchar(200) DEFAULT NULL, `product_code` varchar(16) DEFAULT 'HELP', `fake` bit(1) DEFAULT b'0', `date_push` datetime NOT NULL, `activity_id` bigint(20) DEFAULT '0', PRIMARY KEY (`id`,`date_push`), KEY `mobile` (`mobile`), KEY `date_push` (`date_push`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE COLUMNS(date_push) (PARTITION p2016 VALUES LESS THAN ('2017-01-01') ENGINE = InnoDB, PARTITION p2017 VALUES LESS THAN ('2018-01-01') ENGINE = InnoDB, PARTITION p2018 VALUES LESS THAN ('2019-01-01') ENGINE = InnoDB, PARTITION p2019 VALUES LESS THAN ('2020-01-01') ENGINE = InnoDB, PARTITION p2020 VALUES LESS THAN ('2021-01-01') ENGINE = InnoDB);
这一步完成了建表、建索引、创建联合主键、创建分区。当然也可以跟思路1一样一步一步来:a、创建表;b、drop原主键,创建联合主键;c、创建分区。
②备份
备份的方式有两类:
a、在线备份
数据一直在数据库中不离线。
insert into t_send_message_send2 (select * from t_send_message_send);
b、离线备份
数据先导出到本地,再从本地导回数据库。
③删原表
drop table t_send_message_send;
注意:删原表前一定要确认数据备份完成,且完整。
备份之前可以先count下原表记录条数,备份后也count下新表记录条数,没法一条一条看数据,数下条数对不对还是必要的。如果实在下不去手,把原表改名也是可以的。
rename table t_send_message_send to t_send_message_send_bak;
④改名
rename table t_send_message_send2 to t_send_message_send;
这样思路2也完成了。实际上,第①③④步操作几乎是不耗时间的,最耗时的操作就是第②步备份。不管是在线备份还是离线备份,都非常耗时。具体耗时多久,咱下一篇博文揭晓。
附:
1、查询表分区情况
select partition_name part,partition_expression expr,partition_description descr,table_rows from information_schema.partitions where table_schema = schema() and table_name='t_send_message_send';
1
2、查询表分区数据
select * from t_send_message_send partition(p2020);
(21条消息) Mysql已有亿级数据大表按时间分区_ma_anjun的博客-CSDN博客
查看某表的分区状态
select partition_name, partition_description as val from information_schema.partitions
where table_name='表名';
查询指定分区的数据
查询p2分区的数据
SELECT * from bjop_user_base_info PARTITION(p2);
进行语句explain
explain select * from test.user where id=333;
可以看出id=333的数据落在了分配的p2分区内

java mysql 分区表_mysql分区表对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成。
实现分区的代码实际上是对一组底层表的句柄对象的封装。mysql在创建表时使用PARTITIONBY子句定义每个分区存放的数据。
在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就无须扫描所有分区——只需要查询包含需要数据的分区就可以了。
分区的一个主要目的是将数据按照一个较粗的粒度分在不同的表中,这样做可以将相关的数据放在一起,另外,如果想一次批量删除整个分区的数据也会变得很方便。
a),mysql 的分表是真正的分表,一张表分成很多表后,
每一个小表都是完正的一张表,都对应三个文件, 一个.MYD 数据文件,.MYI 索引文件,.frm 表结构文件。
[root@BlackGhost test]# ls |grep user
alluser.MRG
alluser.frm
user1.MYD 表1
user1.MYI 表2
user1.frm
user2.MYD
user2.MYI
user2.frm
简单说明一下,上面的分表呢是利用了 merge 存储引擎(分表的一种),alluser 是总表,下面有二个分表, user1,user2。他们二个都是独立的表,取数据的时候,我们可以通过总表来取。
这里总表是没有.MYD,.MYI 这二个文件的,也就是说,总表他不是一张表,没有数据,数据都放在分表里面。我们来看看.MRG 到底是 什么东西
[root@BlackGhost test]# cat alluser.MRG |more
user1
user2
#INSERT_METHOD=LAST
从上面我们可以看出,alluser.MRG 里面就存了一些分表的关系,以及插入数据的方式。可以把总表理解成 一个外壳,或者是联接池。
b),分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
[root@BlackGhost test]# ls |grep aa
aa#P#p1.MYD 表的块1
aa#P#p1.MYI 表的块1
aa#P#p3.MYD 表的块2
aa#P#p3.MYI 表的块2
aa.frm
aa.par
从上面我们可以看出,aa 这张表,分为二个区,p1 和 p3,本来是三个区,被我删了一个区。我们都知道一 张表对应三个文件.MYD,.MYI,.frm。
分区呢根据一定的规则把数据文件和索引文件进行了分割,还多出了一 个.par 文件,打开.par 文件后你可以看出他记录了,这张表的分区信息,根分表中的.MRG 有点像。
分区后, 还是一张,而不是多张表。
在下面的场景中,分区可以起到非常大的作用:
1.表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他均是历史数据。
2.分区表的数据更容易维护。例如想批量删除大量数据可以使用清除整个分区的方式。另外,还可以对一个独立分区进行优化、检查、修复等操作。
3.分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
4.可以使用分区表来避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3文件系统的inode锁竞争等。
5.如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果非常好。
分区表本身也有一些限制,下面是其中比较重要的几点:
1.一个表最多只能有1024个分区。
2.在mysql5.1中,分区表达式必须是整数,或者是返回整数的表达式。在mysql5.5中,某些场景中可以直接使用列进行分区。
3.如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
4.分区表中无法使用外键约束。
分区表上的操作按照下面的操作逻辑进行:
select查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。
insert操作
当写入一条记录时,分区层先打开并锁住所有的底层表,然后确定哪个分区接收这条记录,再将记录写入对应底层表。
delete操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应底层表进行删除操作。
update操作
当更新一条记录时,分区层先打开并锁住所有的底层表,mysql先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据在哪个分区,最后对底层进行写入操作,并对原数据所在的底层表进行删除操作。
虽然每个操作都有“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的。如果存储引擎能够自己实现行级锁,例如innoDb,则会在分区层释放对应表锁。这个加锁和解锁过程与普通InnoDB上的查询类似。
- mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,
- 一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,
- 在物理上将这一张表对应的三个文件,分割成许多个小块,这样呢,我们查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了。
- 如果表的数据太大,可能一个磁盘放不下,这个时候,我们可以把数据分配到不同的磁盘里面去
子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。这 也被称为复合分区(composite partitioning)。
create table employees (
id int not null primary key,
first_name varchar(30),
last_name varchar(30))
partition by range(id)(
partition p0 values less than (11),
partition p1 values less than (21),
partition p2 values less than (31),
partition p3 values less than (41)
);
insert into employees values(1,'Vincent','Chen');
insert into employees values(6,'Victor','Chen');
insert into employees values(11,'Grace','Li');
insert into employees values(16,'San','Zhang');
2)explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
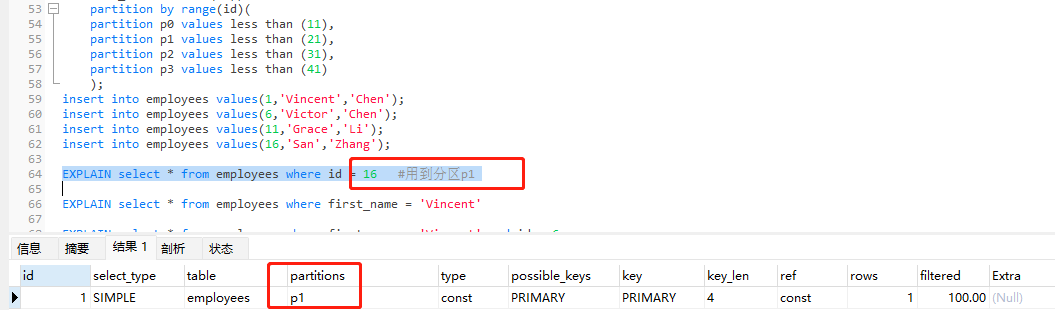
查询到这条数据,是从p1里面找到的。
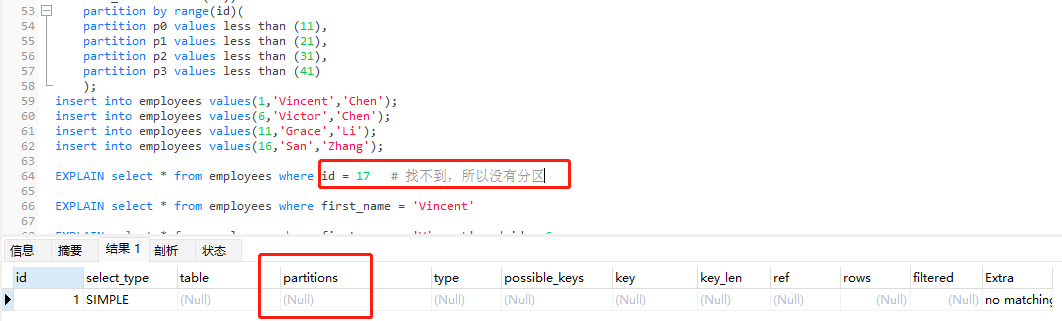
找不到,所以不是从哪个分区找到的。
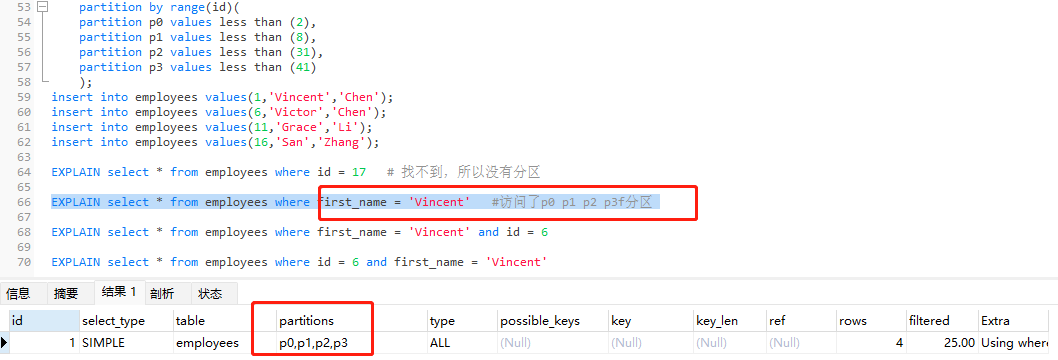
查询条件不是分区建立的条件,所以走所有分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号