第五节:哈希表详解(哈希函数、增删改查、扩容/缩容、质数容量优化)
一. 哈希表介绍
1. 什么是哈希表?
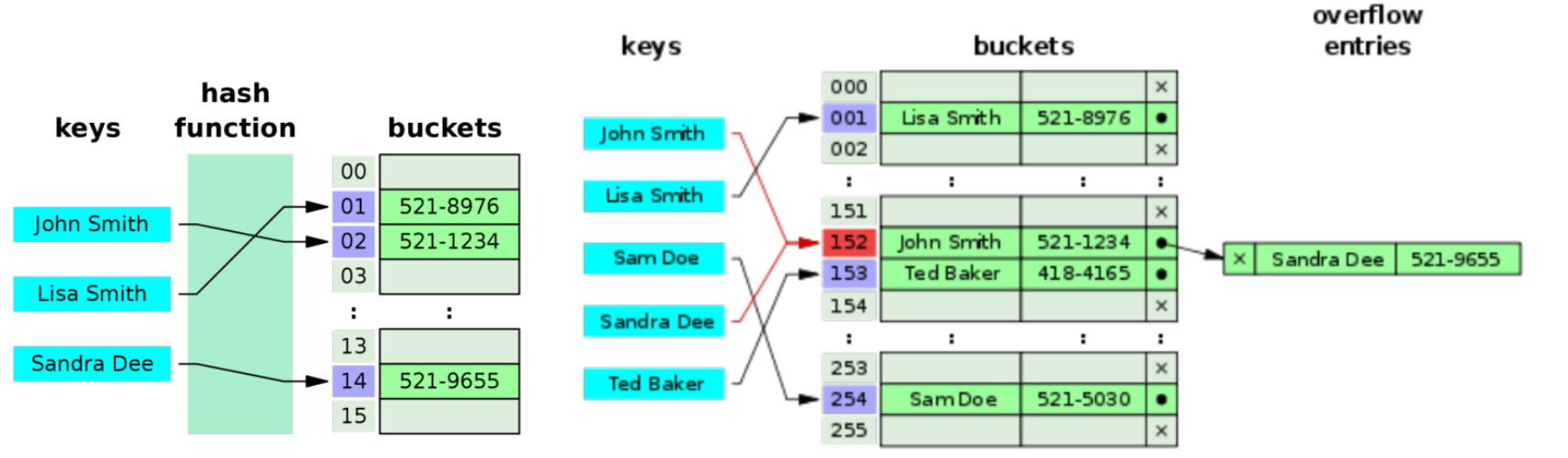
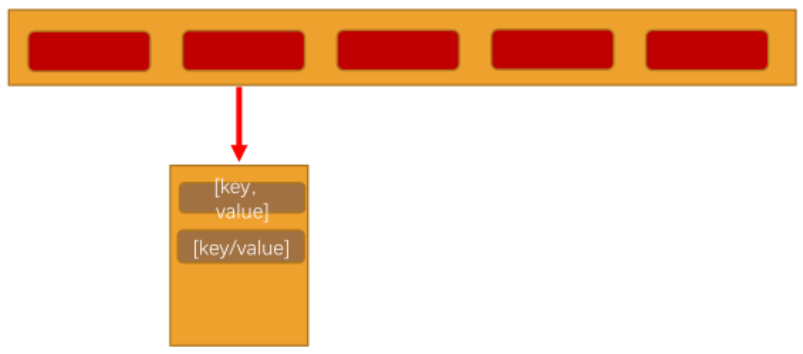
哈希表的结构: [ [[key,value],[key,value],[key,value]], [[key,value],[key,value]], [[key,value],[key,value]] ]
首先是一个大数组 [],大数组中包裹了多个bucket,每个bucket的结构为: [ [key,value], [key,value], [key,value] ] ,也是一个数组,数组里面的内容是 元组[key,value]
2. 对比数组
(1). 优势
它可以提供非常快速的插入-删除-查找操作;
无论多少数据,插入和删除值都接近常量的时间:即O(1)的时间复杂度。实际上,只需要几个机器指令即可完成;
哈希表的速度比树还要快,基本可以瞬间查找到想要的元素;
哈希表相对于树来说编码要容易很多;
(2). 弊端
哈希表中的数据是没有顺序的,所以不能以一种固定的方式(比如从小到大)来遍历其中的元素(没有特殊处理情况下)。
通常情况下,哈希表中的key是不允许重复的,不能放置相同的key,用于保存不同的元素。
3. 一些概念
哈希化:将大数字转化成数组范围内下标的过程,我们就称之为哈希化。
哈希函数:通常我们会将单词转成大数字,大数字在进行哈希化的代码实现放在一个函数中,这个函数我们称为哈希函数。
哈希表:最终将数据插入到的这个数组,对整个结构的封装,我们就称之为是一个哈希表。
4. 如何解决下标值重复问题?
(1). 链地址法
(2). 开放地址法
线性探测、 二次探测、 再哈希法
(了解即可)
二. 哈希函数和元组
1. 好的哈希函数应该具备哪些优点?
(1) 快速的计算
✓ 哈希表的优势就在于效率,所以快速获取到对应的hashCode非常重要。
✓ 我们需要通过快速的计算来获取到元素对应的hashCode
(2) 均匀的分布
✓ 哈希表中,无论是链地址法还是开放地址法,当多个元素映射到同一个位置的时候,都会影响效率。
✓ 所以,优秀的哈希函数应该尽可能将元素映射到不同的位置,让元素在哈希表中均匀的分布。
PS:设计技巧
使用常量的地方,尽量使用质数: A. 哈希表的长度。B. N次幂的底数(我们之前使用的是27)
为什么他们使用质数,会让哈希表分布更加均匀呢?
质数和其他数相乘的结果相比于其他数字更容易产生唯一性的结果,减少哈希冲突。
Java中的N次幂的底数选择的是31,是经过长期观察分布结果得出的;
2. 霍纳法则--快速计算

3. Java中的HashMap
Java中的哈希表采用的是链地址法。
(1). HashMap的初始长度是16,每次自动扩展(我们还没有聊到扩展的话题),长度必须是2的次幂。
这是为了服务于从Key映射到index的算法。60000000 % 100 = 数字。下标值
(2). HashMap中为了提高效率,采用了位运算的方式。
A HashMap中index的计算公式:index = HashCode(Key) & (Length - 1)
B 比如计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001
C 假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111
D 把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9
4. 自行封装hash函数
(1). 个人发现JavaScript中进行较大数据的位运算时会出问题,所以我的代码实现中还是使用了取模。另外,我这里为了方便代码之后向开放地址法中迁移,容量还是选择使用质数。
(2). 这里采用霍纳法则的模式计算hashcode,charCodeAt 返回字符串第n个字符的 Unicode 编码
遍历计算hashcode的公式: hashcode=31*hashcode + str.charCodeAt(i)
(3). 取模求索引:index=hashcode % maxLength (这里hashcode是面临计算后的总值)
/**
* 自定义Hash函数
* @param str 需要求索引的字符串
* @param maxLength 哈希表的最大长度
* @returns 索引值
*/
function hashFunc(str: string, maxLength: number): number {
//1. 计算hashcode值
let hashcode = 0;
const length = str.length;
for (let i = 0; i < length; i++) {
// 霍纳法则计算hashcode,这里采用31作为底数
// charCodeAt 返回字符串第n个字符的 Unicode 编码
hashcode = hashcode * 31 + str.charCodeAt(i);
}
//2. 计算索引值
let index = hashcode % maxLength;
return index;
}5. 元组复习
(1). tuple和数组有什么区别呢?
A. 首先,数组中通常建议存放相同类型的元素,不同类型的元素是不推荐放在数组中。(可以放在对象或者元组中)
B. 其次,元组中每个元素都有自己特性的类型,根据索引值获取到的值可以确定对应的类型;
// 1. 数组的弊端
{
const info1: any[] = ["ypf", 18, 1.21];
console.log(info1[0].length);
console.log(info1[1].length); //只有string类型才能length,number不能,但是这里不会报错,只有运行的时候才能知道,这就是弊端
}
// 2. 使用元组
{
const info2: [string, number, number] = ["ypf", 18, 1.21];
console.log(info2[0].length);
// console.log(info2[1].length); //直接报错
}(2). 剖析 const storage : [string, number][][] = [] 是个什么样的结构?
{
//3.1 array1是个数组类型,数组中元素都是string类型,具体的结构[str1,str2,str3]
let array1: string[] = [];
//3.2 array2是个数组类型,数组中元素都是元组[string,number],具体结构[[str1,num1],[str2,num2],[str3,num3]]
let array2: [string, number][] = [];
/*
3.3 array3是个数组类型,数组中元素都是 [[str1,num1],[str2,num2],[str3,num3]]
所以具体结构为:[ [[str1,num1],[str2,num2]], [[str3,num3],[str4,num4],[str5,num5]], [[str6,num6]] ]
*/
let array3: [string, number][][] = [];
}
三. 哈希表封装
1. 封装的方法有
hashFunc(str,maxLength): 自定义hash函数,求索引
put(key,value): 插入 或 修改
get(key): 根据key获取对应的value
delete(key): 根据key删除数据
resize(newLength):扩容 或 缩容
A. count/maxLength>0.75 进行扩容 (服务于插入)
B. count/maxLength<0.25 进行缩容,同时还要保证 maxLength大于默认值7 (服务于删除)
ps: 关于缩容,这里个人思路,缩容后的maxLength必须 >= 默认值7,否则没别要缩容
2. 基本属性和自定义哈希函数
storage作为我们的数组,数组中存放相关的元素。
maxLength:用于标记数组中最多可以存放多少个元素。
count:表示当前已经存在了多少数据。
class HashTable<T = any> {
//0. hash表的属性
/*
创建一个数组,用来存放链地址法中的链
具体格式: [ [[key,value],[key,value],[key,value]], [[key,value],[key,value]], [[key,value],[key,value]]]
特别注意:每个bucket中 [[key,value],[key,value],[key,value]]
*/
storage: [string, T][][] = [];
// 数组的最大长度 (可以扩容或缩容),默认长度为7
maxLength: number = 7; //正常为private属性,为了测试暂时去掉
//已经存放的元素的个数
private count: number = 0;
/**
* 1. 自定义Hash函数
* @param str 需要求索引的字符串
* @param maxLength 哈希表的最大长度
* @returns 索引值
*/
private hashFunc(str: string, maxLength: number): number {
//1. 计算hashcode值
let hashcode = 0;
const length = str.length;
for (let i = 0; i < length; i++) {
hashcode = 31 * hashcode + str.charCodeAt(i);
}
//2. 求索引
let index = hashcode % maxLength;
//3. 返回索引
return index;
}
}3. 扩容和缩容
(1). 为什么要扩容?
目前,我们是将所有的数据项放在长度为7的数组中的。 因为我们使用的是链地址法,loadFactor可以大于1,所以这个哈希表可以无限制的插入新数据。
但是,随着数据量的增多,每一个index对应的bucket会越来越长,也就造成效率的降低。
所以,在合适的情况对数组进行扩容,比如扩容两倍。
(2). 扩容/缩容的条件?
A. count/maxLength>0.75 进行扩容 (服务于插入)
B. count/maxLength<0.25 进行缩容,同时还要保证 maxLength大于默认值7 (服务于删除)
(3). 如何扩容或缩容?
扩容可以简单的将容量增大两倍 【质数的优化问题,详见最后】
但是这种情况下,所有的数据项一定要同时进行修改(重新调用哈希函数,来获取到不同的位置)
/**
* 2. 扩容或缩容
* @param newLength 扩容或缩容后数组的最大长度
*/
private resize(newLength: number): void {
//1.修改数组的最大长度
this.maxLength = newLength;
//2. 置空哈希表中原先的属性storage、count
let oldStorage = this.storage;
this.storage = [];
this.count = 0;
//3.遍历oldStorage进行重新插入
oldStorage.forEach(bucket => {
if (!bucket) {
return;
}
for (let i = 0; i < bucket.length; i++) {
const tuple = bucket[i];
const tupleKey = tuple[0];
const tupleValue = tuple[1];
this.put(tupleKey, tupleValue);
}
});
}
4. 插入或修改
(1). 说明
哈希表的插入和修改操作是同一个函数:
因为,当使用者传入一个<Key,Value>时, 如果原来不存该key,那么就是插入操作。如果已经存在该key,那么就是修改操作。
PS:插入后,要判断是否需要扩容。
(2). 实操
/**
* 3. 插入 或 修改
* @param key 插入的key
* @param value 插入的value
*/
put(key: string, value: T): void {
//1. 对key进行哈希化,求index索引
let index = this.hashFunc(key, this.maxLength);
//2. 根据index索引拿到bucket桶(数组)
let bucket = this.storage[index];
//3. bucket桶为空需赋值空数组 //等价 if(bucket===null)
if (!bucket) {
bucket = [];
this.storage[index] = bucket;
}
//4. 判断进行修改操作
let isUpdate = false;
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
let tupleKey = tuple[0];
if (key === tupleKey) {
tuple[1] = value;
isUpdate = true;
break; //直接跳出for循环
}
}
//5. 判断进行插入操作 //等价 if(!isUpdate)
if (isUpdate == false) {
bucket.push([key, value]); //存入这个bucket桶中
this.count++;
//判断是否需要扩容
let loadFactor = this.count / this.maxLength;
if (loadFactor > 0.75) {
this.resize(this.maxLength * 2);
}
}
}5. 查找
(1). 说明
先定位到bucket,如果bucket存在,然后再遍历bucket进行查找
(2). 实操
/**
* 4. 根据key获取对应的value
* @param key key-value中的key
* @returns 返回value值 或者 undefined
*/
get(key: string): T | undefined {
//1.对key进行hash化, 求索引
let index = this.hashFunc(key, this.maxLength);
//2. 根据索引求桶bucket(数组)
let bucket = this.storage[index];
if (!bucket) return undefined;
//3. 遍历桶中内容,获取对应的value值
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
let tupleKey = tuple[0];
if (tupleKey === key) {
return tuple[1];
}
}
//4. 桶中没有内容,直接返回undefined
return undefined;
}6. 删除
(1). 说明
先查找,找到的话通过splice函数进行删除即可。 删除后要判断是否需要缩容。
(2). 实操
/**
* 5. 根据key删除对应[key,value]
* @param key 标记key
* @returns 返回删除的value 或 undefined
*/
delete(key: string): T | undefined {
//1.对key进行hash化, 求索引
let index = this.hashFunc(key, this.maxLength);
//2. 根据索引求桶bucket(数组)
let bucket = this.storage[index];
if (!bucket) return undefined;
//3. 遍历查找元素并删除
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
let tupleKey = tuple[0];
if (tupleKey === key) {
bucket.splice(i, 1); //删除该[key,value]值
this.count--;
//判断是否需要缩容
let loadFactor = this.count / this.maxLength;
let newLength = Math.floor(this.maxLength / 2);
if (loadFactor < 0.25 && newLength >= 7) {
this.resize(newLength);
}
return tuple[1]; //返回删除的值
}
}
return undefined;
}7. 测试
代码如下:
查看代码
import HashTable from "./03-哈希表HashTable封装";
let hashTable = new HashTable();
// 1. 插入
{
hashTable.put("aaa", 100);
hashTable.put("aaa", 200);
hashTable.put("bbb", 300);
hashTable.put("ccc", 400);
hashTable.put("abc", 111);
hashTable.put("cba", 222);
console.log(hashTable.storage);
console.log("maxLength:", hashTable.maxLength); //7
console.log("--------------------------------------------");
hashTable.put("nba", 333);
hashTable.put("mba", 444);
console.log(hashTable.storage); //打印出来不一定正好是14,因为【13】这个位置可能没有值
console.log("maxLength:", hashTable.maxLength); //14
}
//2. 获取
// {
// console.log("------------------测试获取--------------------------");
// console.log(hashTable.get("aaa"));
// console.log(hashTable.get("mba"));
// }
// 3. 删除
{
console.log("------------------测试删除--------------------------");
console.log(hashTable.delete("aaa"));
console.log(hashTable.delete("mba"));
console.log(hashTable.delete("bbb"));
console.log(hashTable.delete("ccc"));
console.log(hashTable.delete("cba"));
console.log(hashTable.storage);
console.log(hashTable.get("aaa"));
console.log(hashTable.get("mba"));
console.log("maxLength:", hashTable.maxLength);
}
四. 面试题
1. 判断一个数是否为质数?
(1). 什么是质数?
大于1的自然数,并且只能被1和本身整除,那么他就是质数。(1不是质数)
/**
* 判断数字是否为质数
* @param num 需要被判断的数
* @returns 质数返回true;非质数返回false
*/
function isPrime(num: number): boolean {
//边界判断
if (num <= 1) return false;
//遍历
for (let i = 2; i < num; i++) {
let yushu = num % i;
if (yushu === 0) return false;
}
return true;
}(2). 优化过程
对于每个数n,其实并不需要从2判断到n-1
一个数若可以进行因数分解,那么分解时得到的两个数一定是一个小于等于sqrt(n),一个大于等于sqrt(n)。
注意: sqrt是square root的缩写,表示平方根;
比如16可以被分别。那么是2*8,2小于sqrt(16),也就是4,8大于4。而4*4都是等于sqrt(n),所以其实我们遍历到等于sqrt(n)即可
/**
* 判断数字是否为质数(优化后)
* @param num 需要被判断的数
* @returns 质数返回true;非质数返回false
*/
function isPrime2(num: number): boolean {
//边界判断
if (num <= 1) return false;
//求平法根
let temp = Math.sqrt(num);
//遍历
for (let i = 2; i <= temp; i++) {
if (num % i === 0) return false;
}
return true;
}
五. 扩容/缩容优化
1. 说明
(1). 我们希望扩容/缩容后的maxLength是质数, 所以需要增加两个方法,isPrime 和 getNextPrime,对传入的newLength进行处理
(2). 对插入 和 删除方法中, 扩容和缩容的容量进行质数处理
/**
* 6. 判断数字是否为质数(优化后)
* @param num 需要被判断的数
* @returns 质数返回true;非质数返回false
*/
isPrise(num: number): boolean {
//边界判断
if (num <= 1) return false;
//求平法根
let temp = Math.sqrt(num);
//遍历
for (let i = 2; i <= temp; i++) {
if (num % i === 0) return false;
}
return true;
}
/**
* 7. 获取质数
* @param num 传入需要判断的数
* @returns 如果传入的数不是质数,返回下一个;是则返回本身
*/
getNextPrime(num: number): number {
let newPrise = num;
while (!this.isPrise(newPrise)) {
newPrise++;
}
return newPrise;
}2. 实操
(1). 插入方法优化
/**
* 3. 插入 或 修改
* @param key 插入的key
* @param value 插入的value
*/
put(key: string, value: T): void {
//1. 对key进行哈希化,求index索引
let index = this.hashFunc(key, this.maxLength);
//2. 根据index索引拿到bucket桶(数组)
let bucket = this.storage[index];
//3. bucket桶为空需赋值空数组 //等价 if(bucket===null)
if (!bucket) {
bucket = [];
this.storage[index] = bucket;
}
//4. 判断进行修改操作
let isUpdate = false;
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
let tupleKey = tuple[0];
if (key === tupleKey) {
tuple[1] = value;
isUpdate = true;
break; //直接跳出for循环
}
}
//5. 判断进行插入操作 //等价 if(!isUpdate)
if (isUpdate == false) {
bucket.push([key, value]); //存入这个bucket桶中
this.count++;
//判断是否需要扩容
let loadFactor = this.count / this.maxLength;
if (loadFactor > 0.75) {
this.resize(this.getNextPrime(this.maxLength * 2));
}
}
}(2). 删除方法优化
/**
* 5. 根据key删除对应[key,value]
* @param key 标记key
* @returns 返回删除的value 或 undefined
*/
delete(key: string): T | undefined {
//1.对key进行hash化, 求索引
let index = this.hashFunc(key, this.maxLength);
//2. 根据索引求桶bucket(数组)
let bucket = this.storage[index];
if (!bucket) return undefined;
//3. 遍历查找元素并删除
for (let i = 0; i < bucket.length; i++) {
let tuple = bucket[i];
let tupleKey = tuple[0];
if (tupleKey === key) {
bucket.splice(i, 1); //删除该[key,value]值
this.count--;
//判断是否需要缩容
let loadFactor = this.count / this.maxLength;
let newLength = this.getNextPrime(Math.floor(this.maxLength / 2));
if (loadFactor < 0.25 && newLength >= 7) {
this.resize(newLength);
}
return tuple[1]; //返回删除的值
}
}
return undefined;
}(3). 测试
// 1. 插入
{
hashTable.put("aaa", 100);
hashTable.put("aaa", 200);
hashTable.put("bbb", 300);
hashTable.put("ccc", 400);
hashTable.put("abc", 111);
hashTable.put("cba", 222);
console.log(hashTable.storage);
console.log("maxLength:", hashTable.maxLength); //7
console.log("--------------------------------------------");
hashTable.put("nba", 333);
hashTable.put("mba", 444);
console.log(hashTable.storage);
console.log("maxLength:", hashTable.maxLength); //17 (14,15,16 都不是质数)
}
// 3. 删除
{
console.log("------------------测试删除--------------------------");
console.log(hashTable.delete("aaa"));
console.log(hashTable.delete("mba"));
console.log(hashTable.delete("bbb"));
console.log(hashTable.delete("ccc"));
console.log(hashTable.delete("cba"));
console.log(hashTable.storage);
console.log(hashTable.get("aaa"));
console.log(hashTable.get("mba"));
console.log("maxLength:", hashTable.maxLength); //11 (8,9,10都不是质数)
}
!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号