
脱机手写中文文本行识别系统——软件设计方案
通过高级软件工程课,我学习到了软件工程分析的方法。本文将对工程实践使用软件工程方法进行分析,进行软件系统分析和设计,最终形成软件系统概念原型。
我的工程实践选题是基于深度学习的脱机手写中文文本行识别系统。脱机手写中文文本行识别是指,将手写体的中文纸质文档通过扫描或拍照的方式转化为数字图像,并进一步对该图像中的中文文本行进行识别。目前,随着以 CNN 为代表的一系列深度学习模型的出现, 手写单字符中文识别问题已基本上得到了很好解决。但相对单个汉字识别而言, 含序列信息的脱机手写中文文本行的识别率急剧下降,仍然是此领域还未解决的难点问题之一。 本项目的技术难点在于手写中文字符的样式多变,中文字符种类繁多,再加上近似字等问题给识别网络的设计带来了挑战,同时定位模块的定位准确度也影响着识别模块的识别精度,因此想高效准确地定位识别出手写文本行信息还需要综合考虑多方面因素,深入分析遇到的问题,最终才能实现预定的项目效果。
参考资料:课堂PPT
(一)课题内容
本选题拟实现一个基于深度学习的脱机手写中文文本行识别系统。具体包括:
(1)通过收集/合成更多类别的汉字及不同的书写风格、结合相关数据增强技术来丰富训练集,以提高当前模型结构的泛化能力。
(2)设计和实现至少一个文本行识别模型。
(3)在训练集上进行参数优化,完成模型的训练。
(4)结合后处理的纠错技术,以提高模型的最终的推理精度。
(5)在测试集上,完成对整个系统的评测。
(6)系统部署。
(二)项目设计方案
1. 软件的体系结构
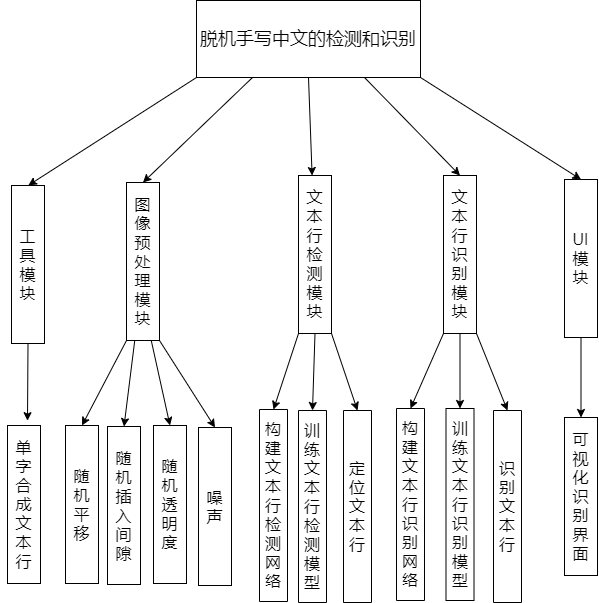
通过需求分析,可以设计一个实用的脱机手写中文文本行检测和识别系统,本文开发的自然场景文本识别的系统具有五个关键的模块,它们是工具类模块,图像预处理模块,文本行检测模块,文本识别模块。系统体系结构如图
2. 系统的功能模块
工具类模块的主要功能是在训练文本行识别模型前扩充文本行训练集。预处理模块的主要功能是进行数据增强。能够更好的模拟自然场景下的手写中文文本,可以使模型的抗干扰能力增强,同时可以使得模型避免过拟合。文本行检测模块的功能性需求是能够较准确的检测出一页中的文本行,并且能够快速准确的将每行文本用矩形区域框出来。文本行识别模块的功能性需求是能够较准确的识别自然场景中文本的信息,文本行识别是对文本行检测中提取的矩形区域中的文本进行识别。UI模块主要功能是为用户提供使用此系统的个性化界面。
工具类模块
(1)单字合成文本行:为扩充文本行训练集,随机选择指定个数单字,将单字拼接成指定长度的文本行,并生成对应文本行标签, 如图所示

工具类模块的输入输出流
图像预处理模块
(1) 随机平移:将文本行中的每个汉字上下平移随机范围的长度。
(2) 随机插入间隙:将文本行的每个汉字之间随机插入一段随机大小范围的间隙。
(3) 随机透明度:将文本行的每个汉字随机设置一定范围内的透明度。
(4) 噪声:对文本行加入噪声。
如图所示:

图图像预处理模块的输入输出流
文本行检测模块
(1)构建文本行检测网络:选择恰当的神经网络模型,设置适宜的输入参数、模型的超参数以及损失函数,用于文本行的检测。
(2)训练文本行检测模型:将训练集经过预处理后输入到文本行检测网络中进行训练,不断进行迭代以降低模型的损失值,提高精确度。
(3)定位文本行:将文本行待定位的图片输入到已经训练好的模型中,经过后处理得到文本行已定位的图片(即每行用矩形框框出的图片)。
如图所示:

文本行检测模块的输入输出流
文本行识别模块
(1) 构建文本行识别网络:选择恰当的神经网络模型,设置适宜的输入参数、模型的超参数以及损失函数,用于文本行的识别。
(2) 训练文本行识别模型:将训练集经过预处理后输入到文本行识别网络中进行训练,不断进行迭代以降低模型的损失值,提高精确度。
(3) 识别文本行:将已定位好文本行的图片输入到已经训练好的文本行识别模型中,经过后处理得到文本行图片对应的文本信息。
如图所示:

文本行识别模块的输入输出流
UI模块
(1)可视化识别界面:实现人机交互功能,用户可以选择浏览手写中文图片,然后生成模型识别出来的对应的文本信息并显示在屏幕上。
3. 接口API
(1) 工具类-图像预处理类接口
接口说明:将单字符图像拼接成文本行图像,一种扩大数据集的手段;
接口参数:待拼接的图片个数,图片所在文件夹地址,图片格式,合成后的图片存放地址;
返回结果:保存新图;
(2) 接口:数据增强-文本定位接口
接口说明:进行数据增强,包括模糊、噪声、平移、拉伸等操作;
接口参数:待增强的图片的路径,增强强度;
返回结果:增强后的图片;
(3) 接口:文本定位-文本识别接口
接口说明:定位出图片上的文本行
接口参数:待定位图片的路径
返回结果:定位后图片的路径
(4) 接口:文本识别-文本显示接口
接口说明:识别出文本行图片上的文字信息
接口参数:定位文本行后图片的路径
返回结果:识别出的文字生成的文本的路径
(5) GUI接口
接口说明:初始化系统界面配置,弹出欢迎界面;
接口参数:sys.argv;
返回结果:None;
三、软件系统概念原型的不同视图
1. 分解视图
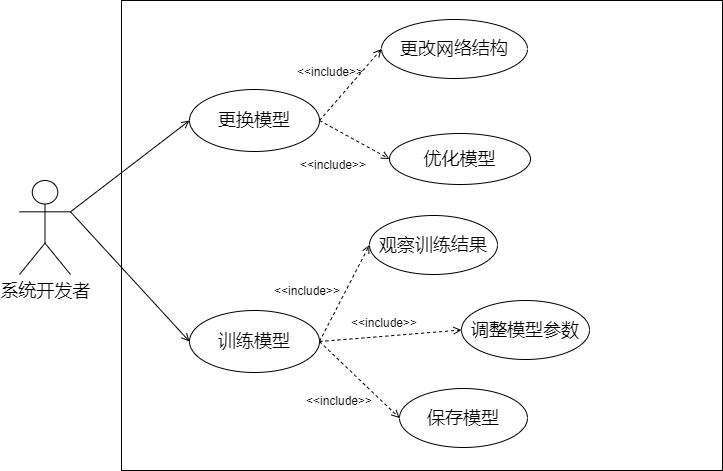
(1) 首先画出系统开发者后台管理子系统的分解视图:
(2) 然后画出客户使用识别子系统的分解视图:

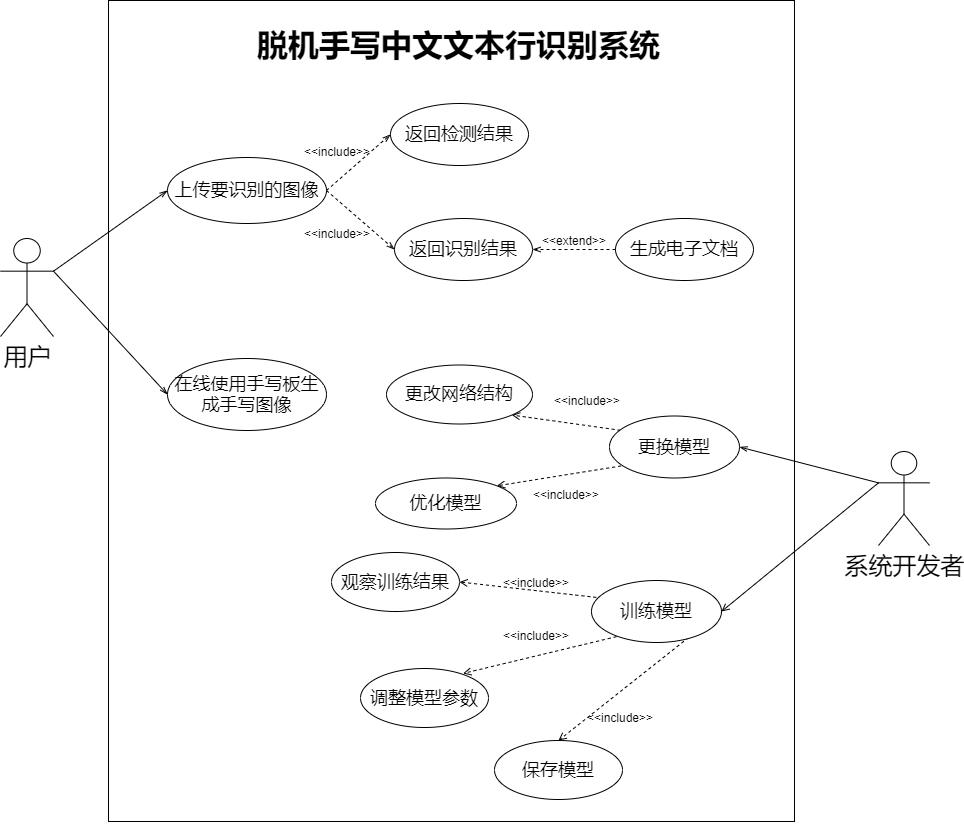
(3) 最终得到整个系统的分解视图:
2. 执行视图
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
a. 业务流程分析
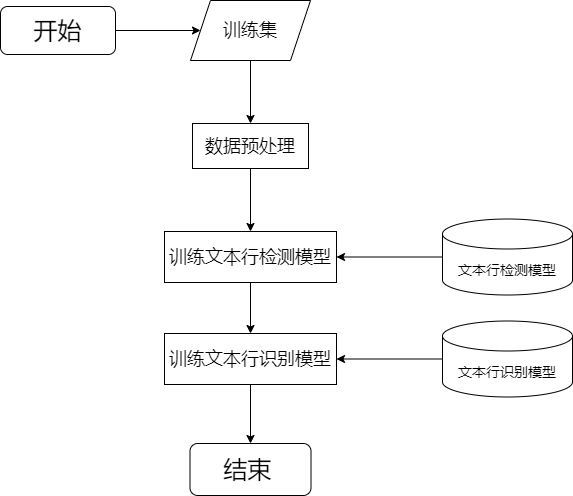
系统训练阶段大致分为以下几个步骤:
① 对训练集数据预处理;
② 训练文本行检测模型;
③ 训练文本行识别模型;
④ 结束;
管理员训练流程:
用户使用系统的业务流程分为以下几个步骤:
① 进入系统首页;
② 上传一批图片;
③ 系统对这批图片进行预处理、检测并识别;
④ 用户得到识别后的结果;
⑤ 退出系统;
用户使用系统的业务流程:

3. 实现视图
实现视图是描述软件架构与源文件之间的映射关系。典型的实现视图就可以由软件项目的源文件目录树来呈现。
本项目的目录树如图所示:
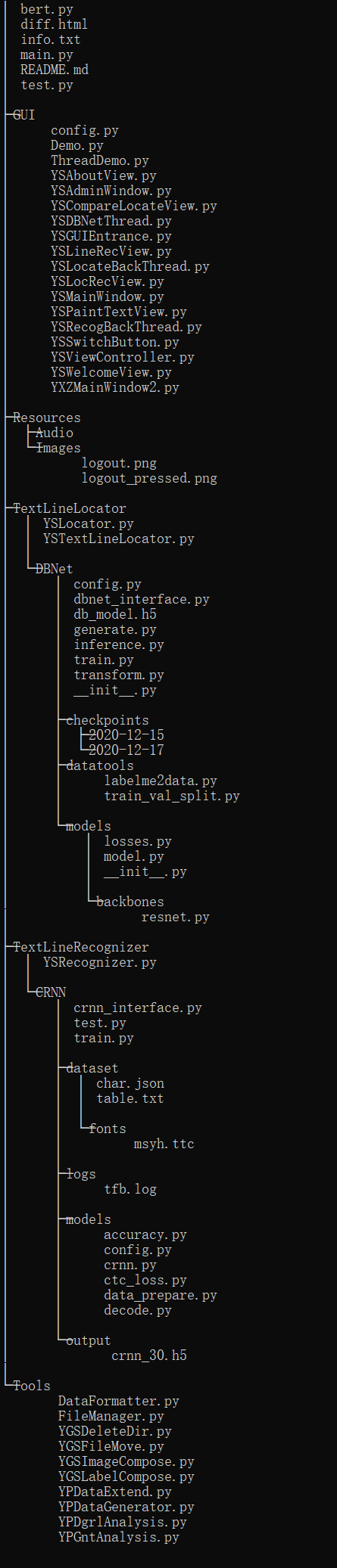
四、数据建模
根据上述的用例建模和业务领域建模,可以得到各个类的数据模型:
- 用户
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 主键、自增 |
| 2 | user_name | String | 用户名 | |
| 3 | account_num | String | 账号 | |
| 4 | password | String | 密码 | |
| 5 | phone_num | String | 电话号码 | 要求11位 |
| 6 | others | String | 其他信息 | |
| 7 | user_class | int | 用户类别 | 两类:客户和管理员 |
- 客户
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 外键 |
| 2 | user_class | int | 用户类别 |
- 管理员
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 外键 |
| 2 | user_class | int | 用户类别 |
- 文件类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | file_ID | String | 文件ID | 主键、自增 |
| 2 | file_format | String | 文件格式 | |
| 3 | subfile_num | String | 子文件数目 | |
| 4 | subfile_name_list | List | 子文件名列表 | |
| 5 | file_class | int | 文件类别 | 分为图片和标签 |
- 图片类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | pic_ID | String | 图片ID | 指一批图片而不是一张;主键、自增 |
- 标签类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | label_ID | String | 标签ID | 是与上述图片对应的一批标签;主键、自增 |
- 工具类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | tool_ID | String | 工具ID | 为不同的用户打开不同的功能权限 |
| 2 | user_ID | String | 用户ID | 外键 |
五、系统运行环境和技术选型说明
1) 开发环境及技术路线:
本项目拟采用的开发环境为:
1. 操作系统: Windows10, MacOS 10.11
2. 集成开发环境IDE: Pycharm
3. 编程语言: Python 3.6 4. 深度学习框架: TensorFlow 2.3.0 5. 依赖库: OpenCV 3.4.2, PyQT 5.9.2
本项目使用的技术路线为:
1. 图像预处理部分: 使用OpenCV对输入图像进行归一化处理
2. 文本行定位部分: 使用形态学方法定位, 备选(使用DBNet或EAST等深度学习网络定位)
3. 文本行识别部分: 使用CRNN模型识别文字
4. GUI部分: 使用PyQT5进行GUI设计
六、概念原型的核心工作机制
-
概念原型是一种虚拟的、理想化的软件产品形式。

根据上面的用例建模和数据建模可以从两方面总结系统的概念原型:
(1) 从用户角度:用户可以上传本地的一批中文手写图像,点击按钮后,系统会使用文本行检测模型对文本行进行定位,最后对这些图片进行识别。识别完成后会在界面上向客户展示识别结果。
(2) 从管理员角度:管理员可以更改模型以及微调模型。
七、总结与展望
本项目预期实现文本行定位和检测系统,以及一个能够识别手写中文文本行并达到预定准确度的模型。本文对这个项目进行了概要设计,在分析与设计的过程中,既加深了软件工程理论知识也提升了项目实践能力。同时认识到做好概要设计对于软件工程的重要性,为日后继续学习奠定了基础。
