
脱机手写中文文本行识别系统——需求分析与概念模型
通过高级软件工程课,我学习到了软件工程分析的方法。本文将对工程实践使用软件工程方法进行分析。
我的工程实践选题是基于深度学习的脱机手写中文文本行识别系统。脱机手写中文文本行识别是指,将手写体的中文纸质文档通过扫描或拍照的方式转化为数字图像,并进一步对该图像中的中文文本行进行识别。目前,随着以 CNN 为代表的一系列深度学习模型的出现, 手写单字符中文识别问题已基本上得到了很好解决。但相对单个汉字识别而言, 含序列信息的脱机手写中文文本行的识别率急剧下降,仍然是此领域还未解决的难点问题之一。
参考资料:课堂PPT
(一)课题内容
本选题拟实现一个基于深度学习的脱机手写中文文本行识别系统。具体包括:
(1)通过收集/合成更多类别的汉字及不同的书写风格、结合相关数据增强技术来丰富训练集,以提高当前模型结构的泛化能力。
(2)设计和实现至少一个文本行识别模型。
(3)在训练集上进行参数优化,完成模型的训练。
(4)结合后处理的纠错技术,以提高模型的最终的推理精度。
(5)在测试集上,完成对整个系统的评测。
(6)系统部署。
(二)系统需求分析
(1) 功能性需求分析:
a. 业务流程分析
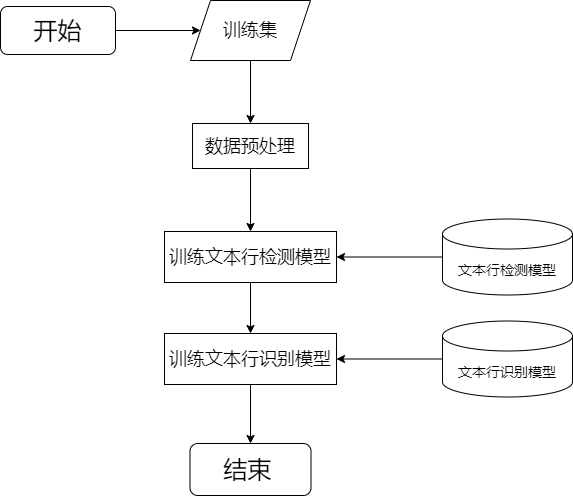
系统训练阶段大致分为以下几个步骤:
① 对训练集数据预处理;
② 训练文本行检测模型;
③ 训练文本行识别模型;
④ 结束;
系统训练流程:
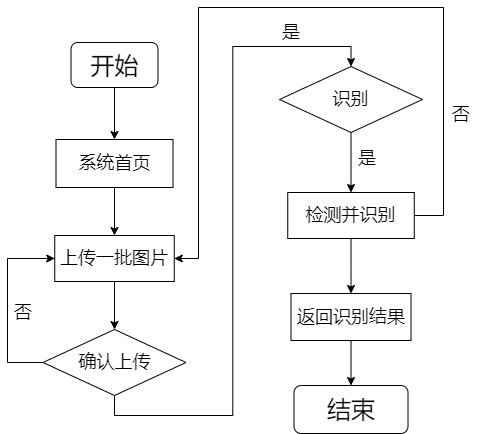
用户使用系统的业务流程分为以下几个步骤:
① 进入系统首页;
② 上传一批图片;
③ 系统对这批图片进行预处理、检测并识别;
④ 用户得到识别后的结果;
⑤ 退出系统;
用户使用系统的业务流程:
b. 用例分析:
整体用例图:
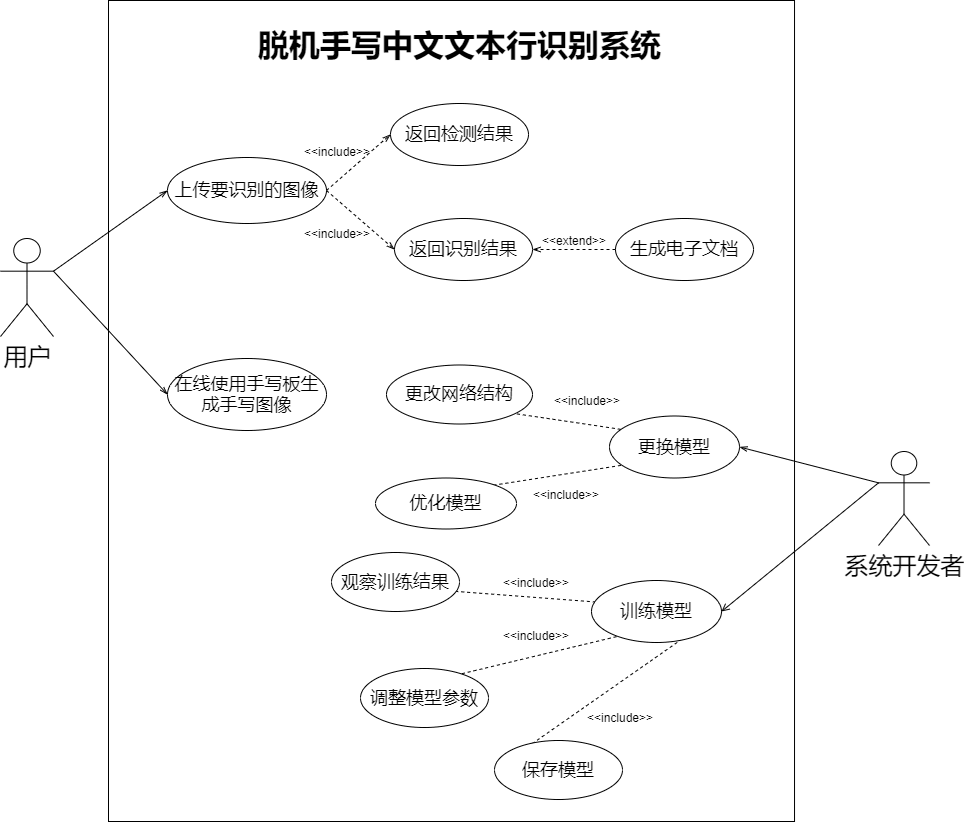
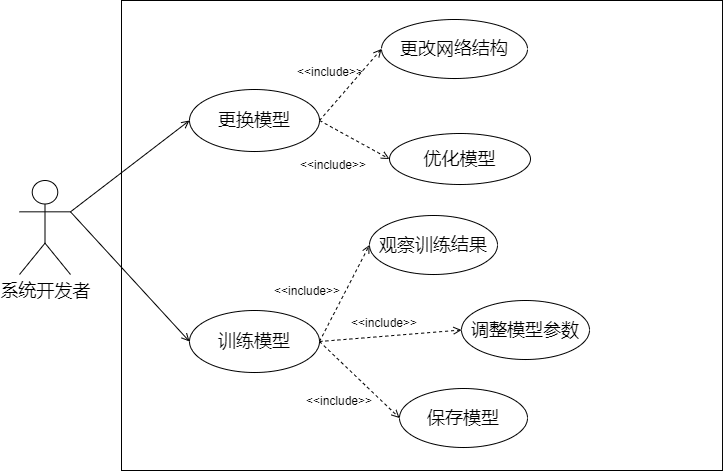
系统开发者的用例分析表和图:
|
Use Case1:更换模型; TUCBW:开发者通过接口将之前的模型文件替换为优化后的模型文件; TUCEW:系统可以正常运行; |
|
Use Case2:训练模型; TUCBW:开发者将大量中文手写数字图像喂给搭建好的网络模型; TUCEW:生成一个精度达到标准的模型文件; |
用户的用例分析表和图
|
Use Case1:上传手写中文数字图像,得到识别结果; TUCBW:用户上传一批手写中文的数字图像; TUCEW:系统框出图像中的所有文本行并显示识别结果; |
|
Use Case2:在线生成手写图片; TUCBW:用户在系统中打开手写板功能,写下随意一段文本; TUCEW:客户点击确定,系统返回识别结果; |

(2) 非功能性需求分析
① 可扩展性:系统需要提供良好的可扩展性,保持各接口之间参数的一致性,可以直接通过函数的传入参数调节训练模型的各个参数。
② 健壮性:大规模数据对模型的训练需要很长时间才能得到结果,然而经常会由于某些原因导致程序崩溃,从而需要重新进行训练。所以本系统需要定期存储训练的中间参数,当程序崩溃时可以恢复到最近的备份点,继续进行训练。
③ 识别准确率:识别准确率是衡量项目开发成败的关键因素。我们要求,在测试集上,模型的识别准确率不应低于85%。
④ 响应时间:响应时间同样也是提高用户体验的关键因素,我们要求对每张图片的检测识别时间不超过1s。
(三)业务领域建模
(1)业务领域建模的步骤
- 第一步,收集应用业务领域的信息。聚焦在功能需求层面,也考虑其他类型的需求和资料;
- 第二步,头脑风暴。列出重要的应用业务领域概念,给出这些概念的属性,以及这些概念之间的关系;
- 第三步,给这些应用业务领域概念分类。分别列出哪些是类、属性和属性值、以及列出类之间的继承关系、聚合关系和关联关系。
- 第四步,将结果用 UML 类图画出来。
(2)画出业务类图
① 用户类 ② 客户类(继承自用户类)③ 管理员类(继承自用户类)④ 文件类⑤ 图片类⑥ 标签类⑦ 工具类:
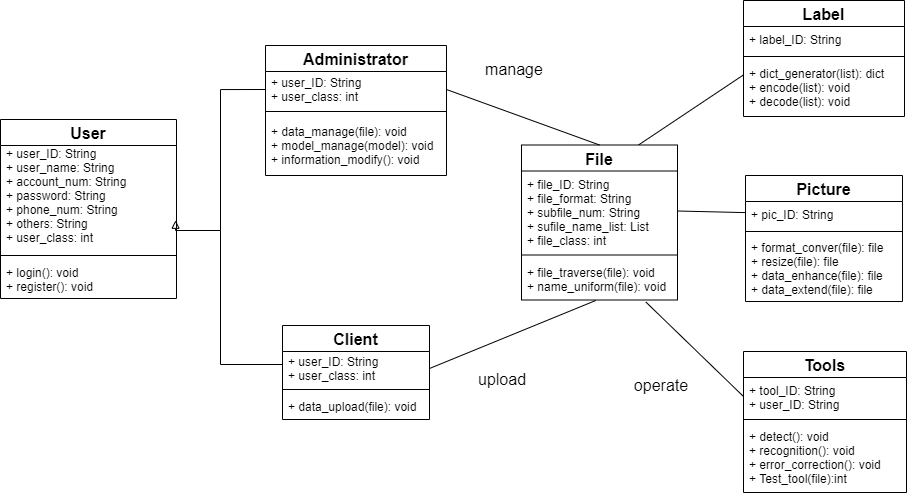
(四)数据建模
根据上述的用例建模和业务领域建模,可以得到各个类的数据模型:
- 用户
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 主键、自增 |
| 2 | user_name | String | 用户名 | |
| 3 | account_num | String | 账号 | |
| 4 | password | String | 密码 | |
| 5 | phone_num | String | 电话号码 | 要求11位 |
| 6 | others | String | 其他信息 | |
| 7 | user_class | int | 用户类别 | 两类:客户和管理员 |
- 客户
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 外键 |
| 2 | user_class | int | 用户类别 |
- 管理员
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | user_ID | String | 用户ID | 外键 |
| 2 | user_class | int | 用户类别 |
- 文件类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | file_ID | String | 文件ID | 主键、自增 |
| 2 | file_format | String | 文件格式 | |
| 3 | subfile_num | String | 子文件数目 | |
| 4 | subfile_name_list | List | 子文件名列表 | |
| 5 | file_class | int | 文件类别 | 分为图片和标签 |
- 图片类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | pic_ID | String | 图片ID | 指一批图片而不是一张;主键、自增 |
- 标签类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | label_ID | String | 标签ID | 是与上述图片对应的一批标签;主键、自增 |
- 工具类
| 序号 | 字段 | 字段类型 | 字段描述 | 备注 |
| 1 | tool_ID | String | 工具ID | 为不同的用户打开不同的功能权限 |
| 2 | user_ID | String | 用户ID | 外键 |
(五)总结概念原型
概念原型是一种虚拟的、理想化的软件产品形式。

根据上面的用例建模和数据建模可以从两方面总结系统的概念原型:
(1) 从用户角度:用户可以上传本地的一批中文手写图像,点击按钮后,系统会使用文本行检测模型对文本行进行定位,最后对这些图片进行识别。识别完成后会在界面上向客户展示识别结果。
(2) 从管理员角度:管理员可以更改模型以及微调模型。
(六)总结与展望
本项目预期实现文本行定位和检测系统,以及一个能够识别手写中文文本行并达到预定准确度的模型。本文对这个项目进行了需求分析以及概要设计,在分析与设计的过程中,既加深了软件工程理论知识也提升了项目实践能力。同时认识到做好需求分析对于软件工程的重要性,为日后继续学习奠定了基础。
