


1.事故起因是是报表开发人员在运行大报表的过程主备namenode同时出现下线挂死。

此时可以看出CM管理工具还未告警fsimage延迟的问题(一般正常情况下,fsimage的延迟CM应该会进行告警行为)
2.刚开始以为是普通namenode压力过大进行namenode重启,但是还是起不来,发现大量namenode元数据延迟,加载缓慢,加载一般会重新宕机。
3.对宕机原因进行分析后发现,namenode在同步JN的过程中,会出现reuqest exception,此时意识到JN备用节点功能应该出问题了。
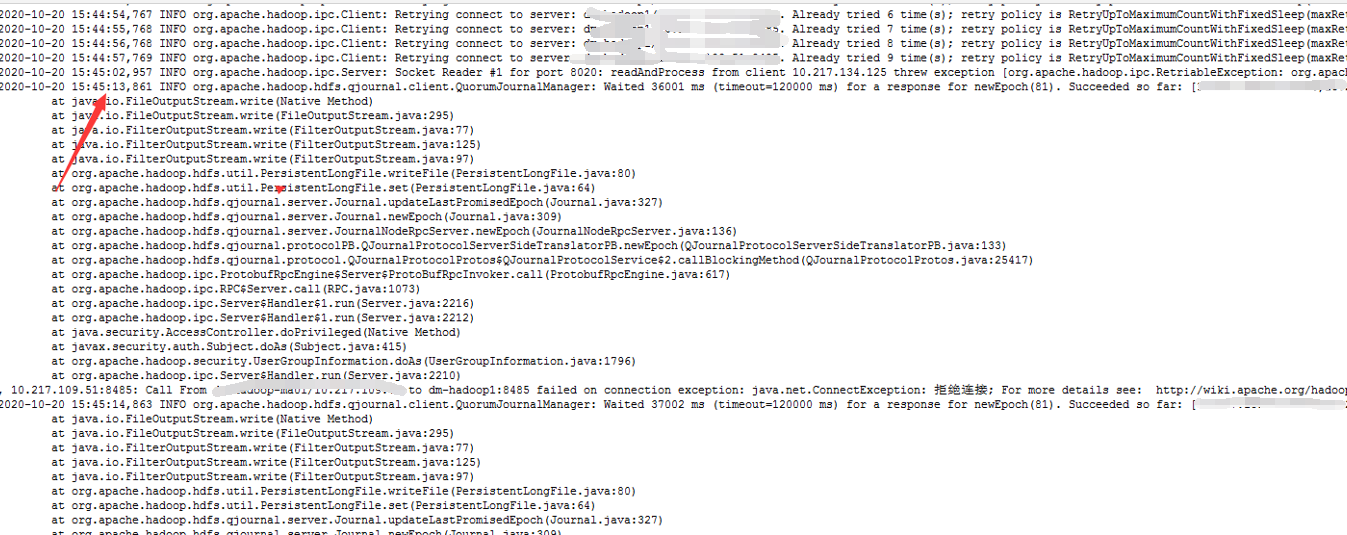
4.于是进行JN群的检查,发现集群的JN功能节点一共5个,挂了四个,都是因为磁盘空间不足。于是紧急进行空间清理,把写edit log的磁盘下的log文件清理了几十G的空间出来腾出来给JN支撑它正常起服务。(此时启动了三个在正常运转),重启namenode节点,3个JN功能生效。集群开始正常工作
5.此时发现了namenode的fsimage主备都在7月23号(当前自然日是10月20号),namenode开始加载JN的备份edit log进行回放,加载速度大概20S一个(这里不知道为什么那么慢,我们CDH版本是5.10,在CDH6测试加载速度是很快的,可能版本不同效率也不同),edit log一共达到5万多个,预计加载完需要10--15天之间(实际上加载速度取决当天editlog产生数量的大小,而查询edit log的加载进度可以查询namenode log加载产生的esgment id,然后去JN节点的edit log查询对应的edit文件产生的时间,就是加载的进度,例子ID不对应随便找的,大概查询方法是如此)
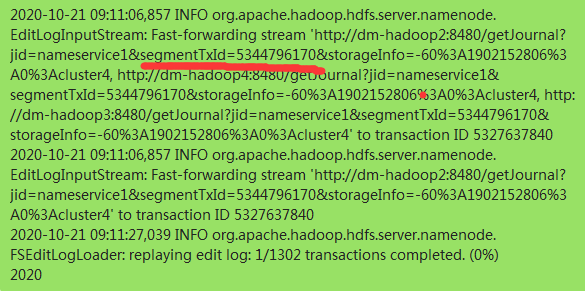

6.由于namenode属于hdfs元数据,是大数据支撑的核心单元,一旦起不来会导致整个集群业务不能工作。寻求了多方帮助可靠方案就两个,一个就是删除edit log此时数据会从7月23号开始加载(次方案弊端很大,也就是7月23号后的数据都会丢失,产生大量的垃圾数据在集群无法识别和清理),一个就是只能等待。个人也是人为此刻等待比较靠谱,因为namenode去同步editlog是一个有顺序的单机串行行为,加载会比较慢,而且我也试过在测试环境进行人为干预,大多以format namenode告终,于是也是强烈建议团队人员进行等待,不要人为干预。
7.进行重新搭建一套临时集群,进行重要日报的运行(旧集群还是采用了等待自动的方式),当时还是比较担心fsimage相隔比较旧能不能正常恢复
8.修复
9.等待12天主节点开始恢复,fsimage告警开始正常工作,此时延迟了5亿多个事务(恢复过程千万要记得监控号不够磁盘的JN机器,当时不断删log想办法释放集群空间,来维持JN的正常运转)
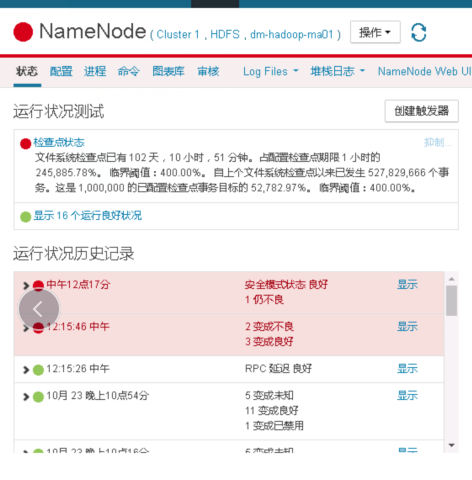
10.主节点恢复集群开始工作
11.备用节点恢复checkpoint机制开始运转

 浙公网安备 33010602011771号
浙公网安备 33010602011771号