
引言
很多分类器在数学解释时都是以二分类为例,其数学推导不适用于多分类,模型本身也只能用于二分类,如SVM,Adaboost ,
但是现实中很多问题是多分类的,那这些模型还能用吗
二分类 to 多分类
更改数学原理
改变这些模型的原理,重新推导数学公式,然后代码实现。
这种方法一般不可取,难度大,而且很麻烦
一对多法
也叫一对其余法
假设有N个类,每次把一个类作为正例,其他类作为反例,训练一个二分类器,然后再拿一个类作为正例,其他类作为反例,再训练一个二分类器,依次训练N个分类器,组成多分类器。
如何进行预测呢?
假设有5个类,来个新样本,
放入第一个二分类器(假设2为正例),看看是不是2类,如果是,记下一个{2},如果不是,记下一个{1 3 4 5} ,
然后放入下个二分类器(假设1为正例),看看是不是1类,如果是,记下一个{1},否则,记下{2 3 4 5},
依次...
最后统计记下的结果,被分为每个类别的次数,取max
这个过程用如下图表示

左图
1. 每条直线就是一个二分类器,每次都把一个类和其他类分开
2. 三叉线为多分类器,实际上这条线是不存在的
3. 直线之间不可能平行,那必然相交,这意味着什么呢?
// 来看紫色的点
// 在三角和其他类的分类器中,被分为三角;在方形与其他类的分类器中,被分为方形;在圆圈与其他类的分类器中,被分为{三角 方形}
// 此时 三角和方形 2:2 打平,那到底紫色点属于哪一类?只能随便挑
// 这就是说存在一些模棱两可的分类区域
右图
紫色区域就是模棱两可的分类区域
一对一法
与一对多法思路类似,方法不同
假设有N个类,每次从中取2个类,训练一个二分类器,总共需要 CN2=N*(N-1)/2个分类器,组成多分类器。
那如何预测呢?
假设有5个类,来个新样本,
放入第一个分类器(1and2),若是1,记为{1},否则记为{2};
放入第二个分类器(1and3),若是1,记为{1},否则记为{3};
依次...
最后统计结果,被分到每个类的次数,取max
这种方法会不会产生一对多法的阴影呢?也会,如下图
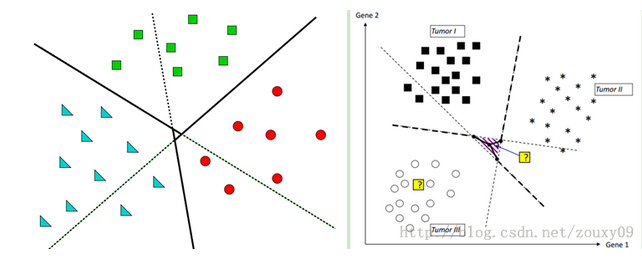
从图上看出阴影部分小很多。
所以一对一法的准确率要高于一对多法,但其分类器个数较多, N*(N-1)/2-2,训练速度慢
多对多法
分为两个步骤
1. 编码:对N个类别进行M次不同的划分,然后训练M个二分类器。
2. 解码:M个二分类器分别对样本进行预测,得到M长的编码向量。
把编码向量与每个类别对应的向量进行比较,如计算距离,取距离最近的作为目标类别。
这里的类别划分通过编码矩阵指定,编码矩阵主要有,二元码(每个类别分别指定正类反类),三元码(正,反,停用)
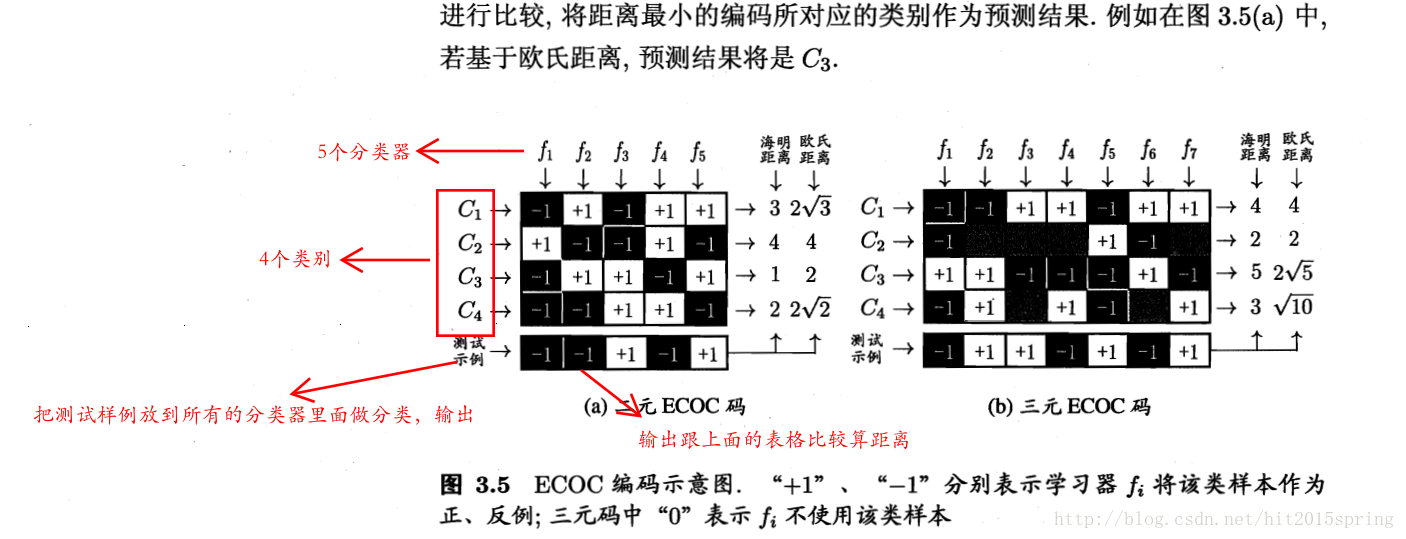
计算距离时,可以灵活计算,如每个分类器 的编码与预测编码相减,取绝对值,如上图,相同时相减为0,不同时相减取绝对值为2,和C1类别相比有3个分类器结果不同,最后计算距离为3,
当然也可以不同为1,同为0,最后选出的结果也是一样的
一般来说编码越长,意味着分类器越多,计算量也越大,但不一定效果越好
层次分类法
如层次支持向量机 H-SVMs
首先将所有类别分为2类,训练一个二分类器,然后将每个子类分为2类,训练二分类器,依次,直到所有类分开。
1, 2, 3, 4,5, 6, 7
1, 2, 3, | 4, 5, 6, 7
1, || 2, 3 | 4, 5 ||| 6, 7
2||||3 4|||||5 6||||||7
这种方法的预测可以依次送入二分类器,得到一个确切的类即可停止。
参考资料:
http://www.cnblogs.com/litthorse/p/9332370.html
https://blog.csdn.net/hit2015spring/article/details/72902927


 浙公网安备 33010602011771号
浙公网安备 33010602011771号