
使用scrapy框架
说明,
之前使用的pyspider框架的,安装的各种问题都已解决,当初还在云服务器做了镜像,配置的python36+pyspider。因为想加全局代理,还修改了fetcher的代码。对调度的任务先后也在index_page里逐一添加到队列的,但仍对顺序执行掌控不好。
故来scapy看看。
发现还挺灵活的。
1。安装pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/ 就能顺利安装好。cmd中 scrapy 即可以验证是否成功。
2。创建项目只cd 到目标,scarpy startproject tutorial即可以创建 tutorial 项目 ,按这里:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
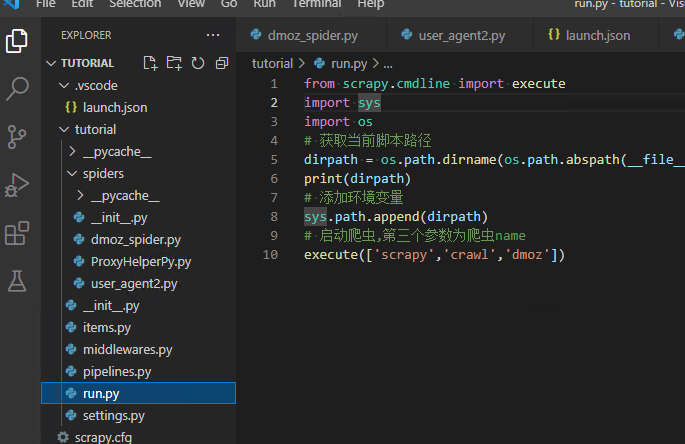
3。然后添加在tutorial / spiders 目录下第一个爬虫文件,dmoz_spider.py文件


import scrapy from pyquery import PyQuery as pq import random from tutorial.spiders.ProxyHelperPy import ProxyHelperClass class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "https://www.baidu.com", ] def start_requests(self): urls = [ "https://www.baidu.com", ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): doc=pq(response.body) items=doc('#u1 a').items() for i in items: print(i.text()) # print(doc('#u1 a'))
4。默认的xpath 不看了,还是用的熟悉的pyquery.
from pyquery import PyQuery as pq
然后 parse 里
doc=pq(response.body) 就可以用了。
5。vscode添加 run.py 用于ctrl + atl +n 运行scrapy 项目,不然还cmd 启动:scrapy crawl dmoz
6。调试添加launch.json,需要后动:关键是红色的
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: Module", "type": "python", "request": "launch", "module": "scrapy", "cwd": "${workspaceRoot}/tutorial", "args": [ "crawl", "dmoz" ] } ] }
7。proxy控制
import scrapy from pyquery import PyQuery as pq import random from tutorial.spiders.ProxyHelperPy import ProxyHelperClass class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] # start_urls = [ # "https://www.baidu.com", # ] proxyObj=None def start_requests(self): urls = [ "https://www.baidu.com", ] if self.proxyObj==None: self.proxyObj=ProxyHelperClass() for url in urls: proxy=self.get_proxy() if proxy!='': yield scrapy.Request(url=url, callback=self.parse, meta={'proxy': proxy}) else: yield scrapy.Request(url=url, callback=self.parse) def get_proxy(self): proxies='' try: print(self.proxyObj==None) ret=self.proxyObj.get_proxy_ip() if ret=='error': print('获取代理ip失败') ip = '{}:{}'.format(ret[0],ret[1]) print(ret, ip) proxies = 'http://'+ip print(proxies) except Exception as e: print('ip获取失败---------------') print(e) return proxies def parse(self, response): doc=pq(response.body) items=doc('#u1 a').items() for i in items: print(i.text()) # print(doc('#u1 a'))
8。那些控制台消息,robots.txt配置,
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号