K8S -二进制部署
K8S
操作系统初始化配置


#没有规则





#修改主机名
#关闭防火墙 systemctl stop firewalld systemctl disable firewalld iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X #关闭selinux setenforce 0 sed -i 's/enforcing/disabled/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #根据规划设置主机名 hostnamectl set-hostname master01 hostnamectl set-hostname node01 hostnamectl set-hostname node02


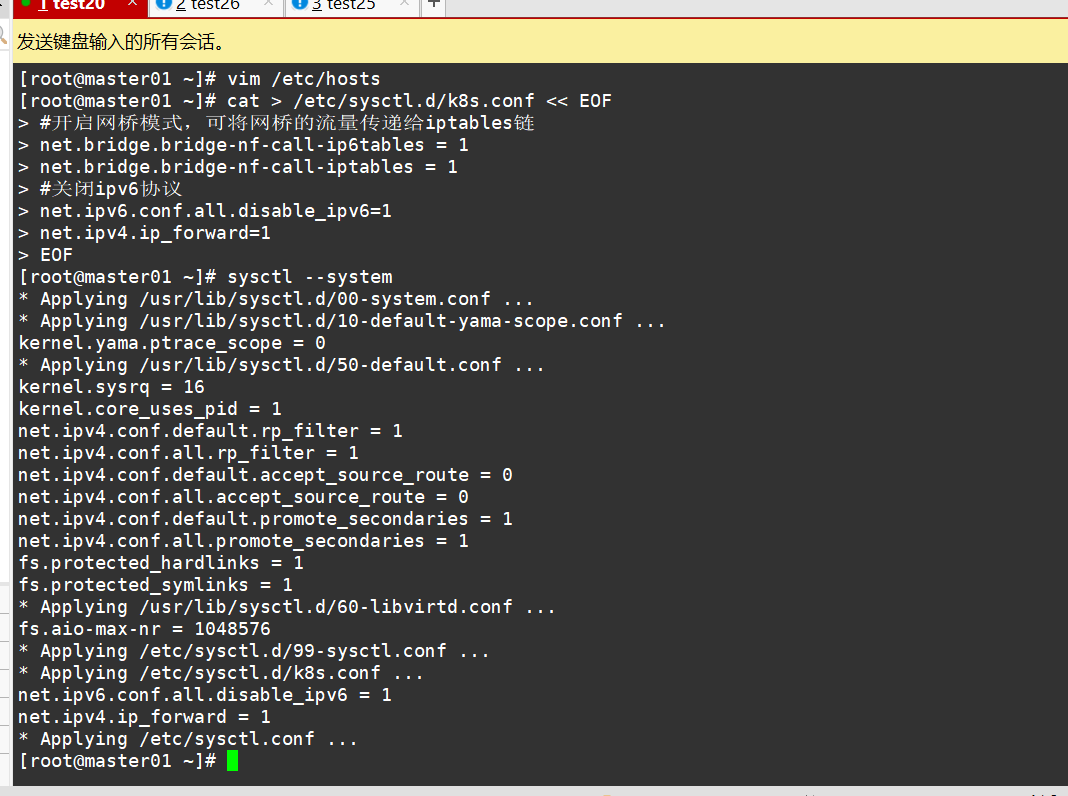
#调整内核参数
#调整内核参数 cat > /etc/sysctl.d/k8s.conf << EOF #开启网桥模式,可将网桥的流量传递给iptables链 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 #关闭ipv6协议 net.ipv6.conf.all.disable_ipv6=1 net.ipv4.ip_forward=1 EOF
#查看ntpdate有无安装



#做个计划任务,每三十分钟做个时间同步
*/30 * * * * /usr/sbin/ntpdate ntp.aliyun.com &> /dev/null
部署 docker引擎
在所有node节点上部署docker引擎

yum install -y yum-utils device-mapper-persistent-data lvm2

yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
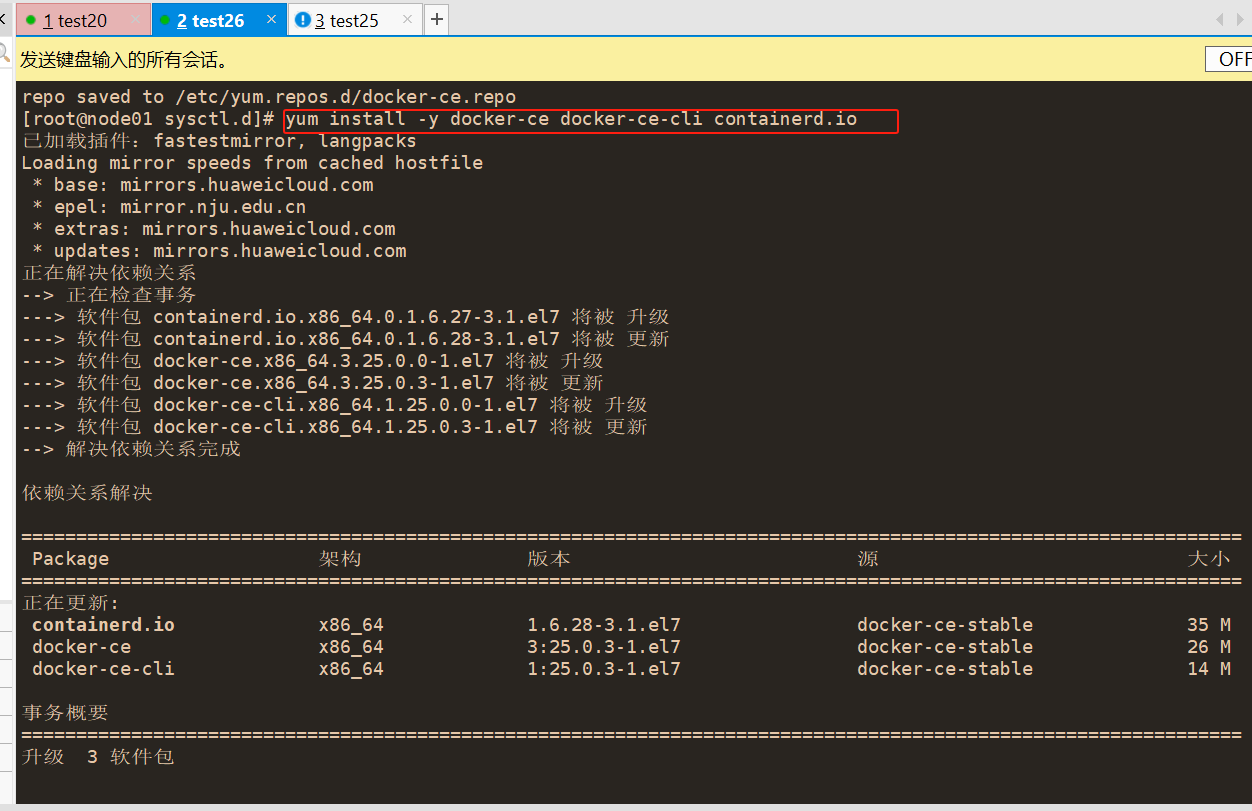
yum install -y docker-ce docker-ce-cli containerd.io

#启动docker服务


#将docker管理服务改为和K8S一致
{ "registry-mirrors": ["https://6ijb8ubo.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "500m", "max-file": "3" } }



#cgroup driver 已改为systemd
部署 etcd 集群
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。 etcd 作为服务发现系统,有以下的特点: 简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单 安全:支持SSL证书验证 快速:单实例支持每秒2k+读操作 可靠:采用raft算法,实现分布式系统数据的可用性和一致性 etcd 目前默认使用2379端口提供HTTP API服务, 2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。 etcd 在生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。 ---------- 准备签发证书环境 ---------- CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。 CFSSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。 CFSSL 使用配置文件生成证书,因此自签之前,需要生成它识别的 json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。 CFSSL 用来为 etcd 提供 TLS 证书,它支持签三种类型的证书: 1、client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如 kube-apiserver 访问 etcd; 2、server 证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如 etcd 对外提供服务; 3、peer 证书,相互之间连接时使用的证书,如 etcd 节点之间进行验证和通信。 这里全部都使用同一套证书认证。

#准备cfssl证书工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo cfssl:证书签发的工具命令 cfssljson:将 cfssl 生成的证书(json格式)变为文件承载式证书 cfssl-certinfo:验证证书的信息 cfssl-certinfo -cert <证书名称> #查看证书的信息
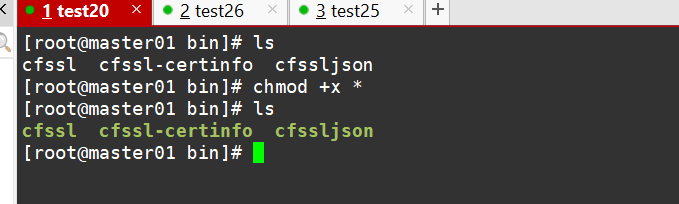
#给三个工具执行权限
#检查版本

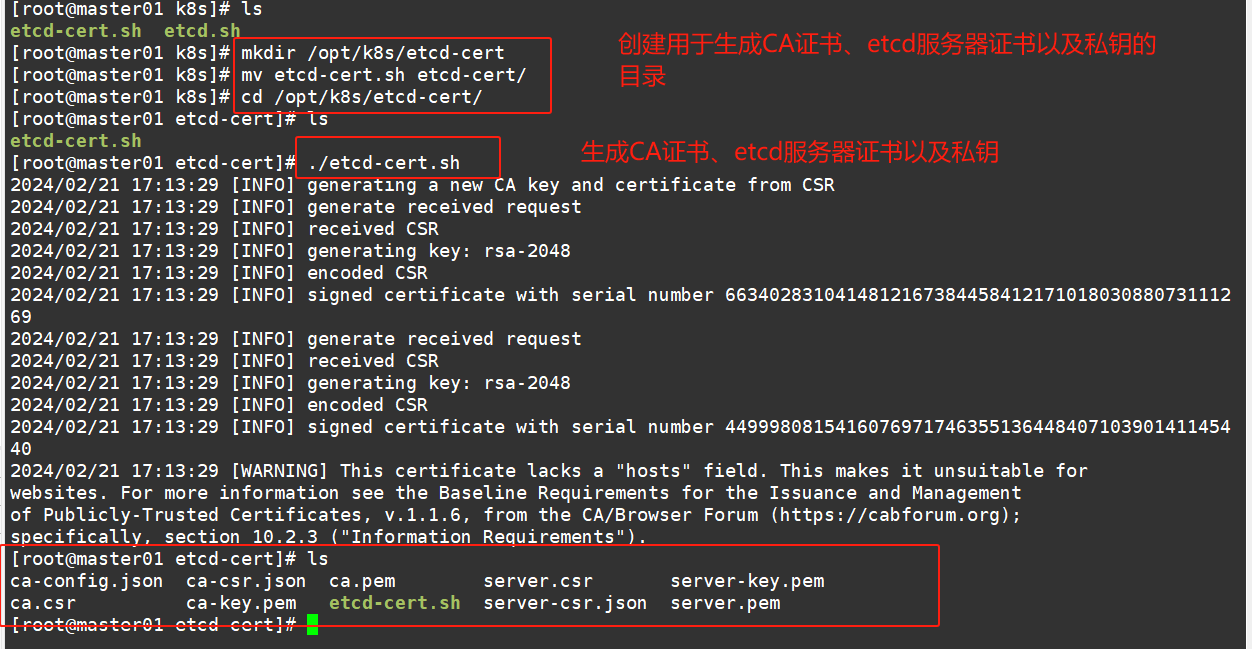
#创建K8S安装目录
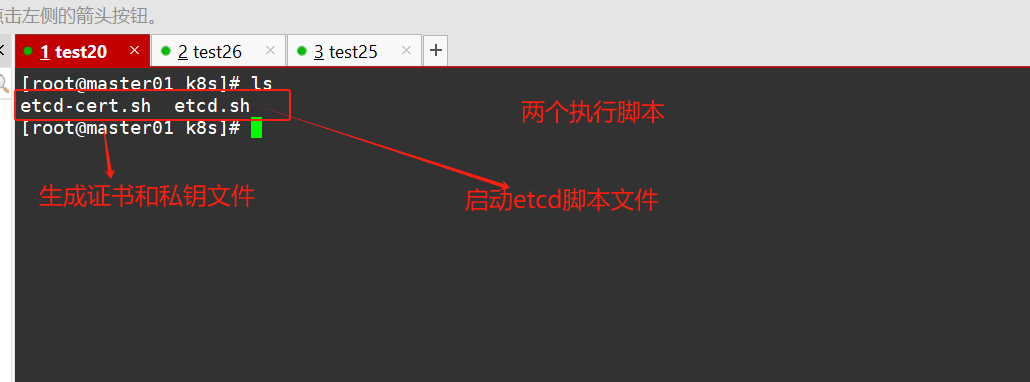

#!/bin/bash #配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书 cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "www": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF #ca-config.json:可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数; #后续在签名证书时会使用某个 profile;此实例只有一个 www 模板。 #expiry:指定了证书的有效期,87600h 为10年,如果用默认值一年的话,证书到期后集群会立即宕掉 #signing:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE; #key encipherment:表示使用非对称密钥加密,如 RSA 加密; #server auth:表示client可以用该 CA 对 server 提供的证书进行验证; #client auth:表示server可以用该 CA 对 client 提供的证书进行验证; #注意标点符号,最后一个字段一般是没有逗号的。 #----------------------- #生成CA证书和私钥(根证书和私钥) #特别说明: cfssl和openssl有一些区别,openssl需要先生成私钥,然后用私钥生成请求文件,最后生成签名的证书和私钥等 ,但是cfssl可以直接得到请求文件。 cat > ca-csr.json <<EOF { "CN": "etcd", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing" } ] } EOF #CN:Common Name,浏览器使用该字段验证网站或机构是否合法,一般写的是域名 #key:指定了加密算法,一般使用rsa(size:2048) #C:Country,国家 #ST:State,州,省 #L:Locality,地区,城市 #O: Organization Name,组织名称,公司名称 #OU: Organization Unit Name,组织单位名称,公司部门 cfssl gencert -initca ca-csr.json | cfssljson -bare ca #生成的文件: #ca-key.pem:根证书私钥 #ca.pem:根证书 #ca.csr:根证书签发请求文件 #cfssl gencert -initca <CSRJSON>:使用 CSRJSON 文件生成新的证书和私钥。如果不添加管道符号,会直接把所有证书内容 输出到屏幕。 #注意:CSRJSON 文件用的是相对路径,所以 cfssl 的时候需要 csr 文件的路径下执行,也可以指定为绝对路径。 #cfssljson 将 cfssl 生成的证书(json格式)变为文件承载式证书,-bare 用于命名生成的证书文件。 #----------------------- #生成 etcd 服务器证书和私钥 cat > server-csr.json <<EOF { "CN": "etcd", "hosts": [ "192.168.19.20", "192.168.19.26", "192.168.19.25" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing" } ] } EOF #hosts:将所有 etcd 集群节点添加到 host 列表,需要指定所有 etcd 集群的节点 ip 或主机名不能使用网段,新增 etcd >服务器需要重新签发证书。 cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server #生成的文件: #server.csr:服务器的证书请求文件 #server-key.pem:服务器的私钥 #server.pem:服务器的数字签名证书 #-config:引用证书生成策略文件 ca-config.json #-profile:指定证书生成策略文件中的的使用场景,比如 ca-config.json 中的 www

#!/bin/bash #example: ./etcd.sh etcd01 192.168.19.20 etcd02=https://192.168.19.26:2380,etcd03=https://192.168.19.25:2380 #创建etcd配置文件/opt/etcd/cfg/etcd ETCD_NAME=$1 ETCD_IP=$2 ETCD_CLUSTER=$3 WORK_DIR=/opt/etcd cat > $WORK_DIR/cfg/etcd <<EOF #[Member] ETCD_NAME="${ETCD_NAME}" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://${ETCD_IP}:2380" ETCD_LISTEN_CLIENT_URLS="https://${ETCD_IP}:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://${ETCD_IP}:2380" ETCD_ADVERTISE_CLIENT_URLS="https://${ETCD_IP}:2379" ETCD_INITIAL_CLUSTER="etcd01=https://${ETCD_IP}:2380,${ETCD_CLUSTER}" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF #Member:成员配置 #ETCD_NAME:节点名称,集群中唯一。成员名字,集群中必须具备唯一性,如etcd01 #ETCD_DATA_DIR:数据目录。指定节点的数据存储目录,这些数据包括节点ID,集群ID,集群初始化配置,Snapshot文件,若>未指定-wal-dir,还会存储WAL文件;如果不指定会用缺省目录 #ETCD_LISTEN_PEER_URLS:集群通信监听地址。用于监听其他member发送信息的地址。ip为全0代表监听本机所有接口 #ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址。用于监听etcd客户发送信息的地址。ip为全0代表监听本机所有接口 #Clustering:集群配置 #ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址。其他member使用,其他member通过该地址与本member交互信息。一定要 保证从其他member能可访问该地址。静态配置方式下,该参数的value一定要同时在--initial-cluster参数中存在 #ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址。etcd客户端使用,客户端通过该地址与本member交互信息。一定要保证从客 户侧能可访问该地址 #ETCD_INITIAL_CLUSTER:集群节点地址。本member使用。描述集群中所有节点的信息,本member根据此信息去联系其他member #ETCD_INITIAL_CLUSTER_TOKEN:集群Token。用于区分不同集群。本地如有多个集群要设为不同 #ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群。 #创建etcd.service服务管理文件 cat > /usr/lib/systemd/system/etcd.service <<EOF [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=${WORK_DIR}/cfg/etcd ExecStart=${WORK_DIR}/bin/etcd \ --cert-file=${WORK_DIR}/ssl/server.pem \ --key-file=${WORK_DIR}/ssl/server-key.pem \ --trusted-ca-file=${WORK_DIR}/ssl/ca.pem \ --peer-cert-file=${WORK_DIR}/ssl/server.pem \ --peer-key-file=${WORK_DIR}/ssl/server-key.pem \ --peer-trusted-ca-file=${WORK_DIR}/ssl/ca.pem \ --logger=zap \ --enable-v2 Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF #--enable-v2:开启 etcd v2 API 接口。当前 flannel 版本不支持 etcd v3 通信 #--logger=zap:使用 zap 日志框架。zap.Logger 是go语言中相对日志库中性能最高的 #--peer开头的配置项用于指定集群内部TLS相关证书(peer 证书),这里全部都使用同一套证书认证 #不带--peer开头的的参数是指定 etcd 服务器TLS相关证书(server 证书),这里全部都使用同一套证书认证 systemctl daemon-reload systemctl enable etcd systemctl restart etcd
#两个脚本执行权限

#上传etcd-v3.4.9-linux-amd64
etcd就是etcd 服务的启动命令,后面可跟各种启动参数
etcdctl主要为etcd 服务提供了命令行操作

#创建用于存放 etcd 配置文件,命令文件,证书的目录


#启动etcd
./etcd.sh etcd01 192.168.19.20 etcd02=https://192.168.19.26:2380,etcd03=https://192.168.19.25:2380
#进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况



#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp /usr/lib/systemd/system/etcd.service root@192.168.19.26:/usr/lib/systemd/system/ scp /usr/lib/systemd/system/etcd.service root@192.168.19.25:/usr/lib/systemd/system/





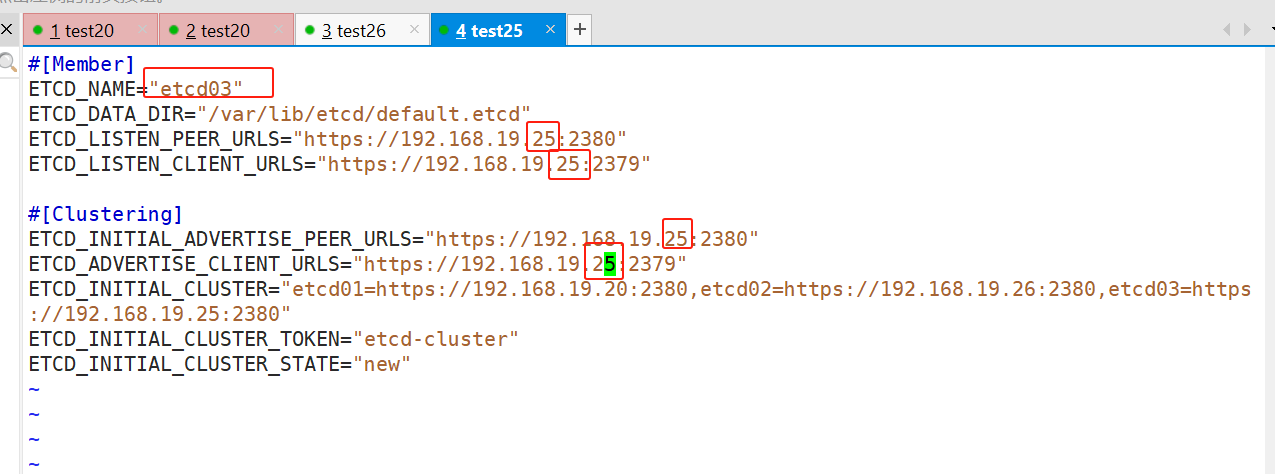
#[Member] ETCD_NAME="etcd03" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.19.25:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.19.25:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.19.25:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.19.25:2379" ETCD_INITIAL_CLUSTER="etcd01=https://192.168.19.20:2380,etcd02=https://192.168.19.26:2380,etcd03=https://192.168.19.25:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"


ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.19.20:2379,https://192.168.19.26:2379,https://192.168.19.25:2379" endpoint health --write-out=table
--cert-file:识别HTTPS端使用SSL证书文件
--key-file:使用此SSL密钥文件标识HTTPS客户端
--ca-file:使用此CA证书验证启用https的服务器的证书
--endpoints:集群中以逗号分隔的机器地址列表
cluster-health:检查etcd集群的运行状况

ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.19.20:2379,https://192.168.19.26:2379,https://192.168.19.25:2379" --write-out=table member list
部署 Master 组件
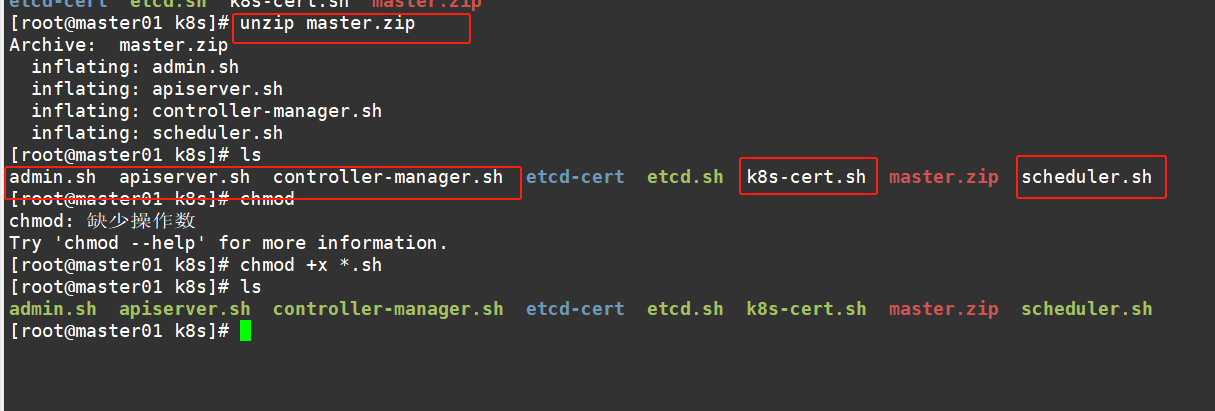
#传 master.zip 和 k8s-cert.sh 到 /opt/k8s 目录中,解压 master.zip 压缩包

#!/bin/bash mkdir /root/.kube KUBE_CONFIG="/root/.kube/config" KUBE_APISERVER="https://192.168.19.20:6443" #切换到k8s证书目录操作 cd /opt/k8s/k8s-cert/ #配置kubernetes集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=${KUBE_CONFIG} #配置客户端认证参数 kubectl config set-credentials admin \ --client-certificate=./admin.pem \ --client-key=./admin-key.pem \ --embed-certs=true \ --kubeconfig=${KUBE_CONFIG} #设置设置一个环境项,配置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=admin \ --kubeconfig=${KUBE_CONFIG} #设置默认环境上下文 kubectl config use-context default --kubeconfig=${KUBE_CONFIG} #生成的 kubeconfig 被保存到 /root/.kube/config 文件 ######################################################### #集群参数 @ @#!/bin/bash mkdir /root/.kube KUBE_CONFIG="/root/.kube/config" KUBE_APISERVER="https://192.168.19.20:6443" #切换到k8s证书目录操作 cd /opt/k8s/k8s-cert/ #配置kubernetes集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=${KUBE_CONFIG} #配置客户端认证参数 kubectl config set-credentials admin \ --client-certificate=./admin.pem \ --client-key=./admin-key.pem \ --embed-certs=true \ --kubeconfig=${KUBE_CONFIG} #设置设置一个环境项,配置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=admin \ --kubeconfig=${KUBE_CONFIG} #设置默认环境上下文 kubectl config use-context default --kubeconfig=${KUBE_CONFIG} #生成的 kubeconfig 被保存到 /root/.kube/config 文件 #########################################################
#集群参数
#本段设置了所需要访问的集群的信息。使用set-cluster设置了需要访问的集群,如上为kubernetes,这只是个名称,实际为--server指向的apiserver;--certificate-authority设置了该集群的公钥;--embed-certs为true表示将--certificate-authority证书写入到kubeconfig中;--server则表示该集群的kube-apiserver地址
#用户参数
#本段主要设置用户的相关信息,主要是用户证书。如上的用户名为admin,证书为:/opt/kubernetes/ssl/admin.pem,私钥为
:/opt/kubernetes/ssl/admin-key.pem。注意客户端的证书首先要经过集群CA的签署,否则不会被集群认可。此处使用的是ca认证方式,也可以使用token认证,如kubelet的 TLS Boostrap 机制下的 bootstrapping 使用的就是token认证方式。上述kubectl使用的是ca认证,不需要token字段
#上下文参数
#集群参数和用户参数可以同时设置多对,在上下文参数中将集群参数和用户参数关联起来。上面的上下文名称为default,集>群为kubenetes,用户为admin,表示使用admin的用户凭证来访问kubenetes集群的default命名空间,也可以增加--namspace来
指定访问的命名空间。
#最后使用 kubectl config use-context default 来使用名为 default 的环境项来作为配置。 如果配置了多个环境项,可以
通过切换不同的环境项名字来访问到不同的集群环境。
#########################################################
@

#!/bin/bash #example: apiserver.sh 192.168.19.20 https://192.168.19.20:2379,https://192.168.19.26:2379,https://192.168.19.25:2379 #创建 kube-apiserver 启动参数配置文件 MASTER_ADDRESS=$1 ETCD_SERVERS=$2 cat >/opt/kubernetes/cfg/kube-apiserver <<EOF KUBE_APISERVER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --etcd-servers=${ETCD_SERVERS} \\ --bind-address=${MASTER_ADDRESS} \\ --secure-port=6443 \\ --advertise-address=${MASTER_ADDRESS} \\ --allow-privileged=true \\ --service-cluster-ip-range=10.0.0.0/24 \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\ --authorization-mode=RBAC,Node \\ --enable-bootstrap-token-auth=true \\ --token-auth-file=/opt/kubernetes/cfg/token.csv \\ --service-node-port-range=30000-50000 \\ --kubelet-client-certificate=/opt/kubernetes/ssl/apiserver.pem \\ --kubelet-client-key=/opt/kubernetes/ssl/apiserver-key.pem \\ --tls-cert-file=/opt/kubernetes/ssl/apiserver.pem \\ --tls-private-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\ --client-ca-file=/opt/kubernetes/ssl/ca.pem \\ --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --service-account-issuer=api \\ --service-account-signing-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\ --etcd-cafile=/opt/etcd/ssl/ca.pem \\ --etcd-certfile=/opt/etcd/ssl/server.pem \\ --etcd-keyfile=/opt/etcd/ssl/server-key.pem \\ --requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \\ --proxy-client-cert-file=/opt/kubernetes/ssl/apiserver.pem \\ --proxy-client-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\ --requestheader-allowed-names=kubernetes \\ --requestheader-extra-headers-prefix=X-Remote-Extra- \\ --requestheader-group-headers=X-Remote-Group \\ --requestheader-username-headers=X-Remote-User \\ --enable-aggregator-routing=true \\ --audit-log-maxage=30 \\ --audit-log-maxbackup=3 \\ --audit-log-maxsize=100 \\ --audit-log-path=/opt/kubernetes/logs/k8s-audit.log" EOF #--logtostderr=true:启用日志。输出日志到标准错误控制台,不输出到文件 #--v=4:日志等级。指定输出日志的级别,v=4为调试级别详细输出 #--etcd-servers:etcd集群地址。指定etcd服务器列表(格式://ip:port),逗号分隔 #--bind-address:监听地址。指定 HTTPS 安全接口的监听地址,默认值0.0.0.0 #--secure-port:https安全端口。指定 HTTPS 安全接口的监听端口,默认值6443 #--advertise-address:集群通告地址。通过该 ip 地址向集群其他节点公布 api server 的信息,必须能够被其他节点访问 #--allow-privileged=true:启用授权。允许拥有系统特权的容器运行,默认值false #--service-cluster-ip-range:Service虚拟IP地址段。指定 Service Cluster IP 地址段 #--enable-admission-plugins:准入控制模块。kuberneres集群的准入控制机制,各控制模块以插件的形式依次生效,集群时 必须包含ServiceAccount,运行在认证(Authentication)、授权(Authorization)之后,Admission Control是权限认证链>上的最后一环, 对请求API资源对象进行修改和校验 #--authorization-mode:认证授权,启用RBAC授权和节点自管理。在安全端口使用RBAC,Node授权模式,未通过授权的请求拒>绝,默认值AlwaysAllow。RBAC是用户通过角色与权限进行关联的模式;Node模式(节点授权)是一种特殊用途的授权模式,专 门授权由kubelet发出的API请求,在进行认证时,先通过用户名、用户分组验证是否是集群中的Node节点,只有是Node节点的>请求才能使用Node模式授权 #--enable-bootstrap-token-auth:启用TLS bootstrap机制。在apiserver上启用Bootstrap Token 认证 #--token-auth-file=/opt/kubernetes/cfg/token.csv:指定bootstrap token认证文件路径 #--service-node-port-range:指定 Service NodePort 的端口范围,默认值30000-32767 #–-kubelet-client-xxx:apiserver访问kubelet客户端证书 #--tls-xxx-file:apiserver https证书 #1.20版本必须加的参数:–-service-account-issuer,–-service-account-signing-key-file #--etcd-xxxfile:连接Etcd集群证书 #–-audit-log-xxx:审计日志 #启动聚合层相关配置:–requestheader-client-ca-file,–proxy-client-cert-file,–proxy-client-key-file,–requestheader-allowed-names,–requestheader-extra-headers-prefix,–requestheader-group-headers,–requestheader-username-headers,–enable-aggregator-routing #创建 kube-apiserver.service 服务管理文件 cat >/usr/lib/systemd/system/kube-apiserver.service <<EOF [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-apiserver ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable kube-apiserver systemctl restart kube-apiserver

#!/bin/bash ##创建 kube-controller-manager 启动参数配置文件 MASTER_ADDRESS=$1 cat >/opt/kubernetes/cfg/kube-controller-manager <<EOF KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --leader-elect=true \\ --kubeconfig=/opt/kubernetes/cfg/kube-controller-manager.kubeconfig \\ --bind-address=127.0.0.1 \\ --allocate-node-cidrs=true \\ --cluster-cidr=10.244.0.0/16 \\ --service-cluster-ip-range=10.0.0.0/24 \\ --cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\ --cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --root-ca-file=/opt/kubernetes/ssl/ca.pem \\ --service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\ --cluster-signing-duration=87600h0m0s" EOF #??leader-elect:当该组件启动多个时,自动选举(HA) #-?kubeconfig:连接 apiserver 用的配置文件,用于识别 k8s 集群 #--cluster-cidr=10.244.0.0/16:pod资源的网段,需与pod网络插件的值设置一致。通常,Flannel网络插件的默认为10.244.0.0/16,Calico插件的默认值为192.168.0.0/16 #--cluster-signing-cert-file/?-cluster-signing-key-file:自动为kubelet颁发证书的CA,与apiserver保持一致。指定签 名的CA机构根证书,用来签名为 TLS BootStrapping 创建的证书和私钥 #--root-ca-file:指定根CA证书文件路径,用来对 kube-apiserver 证书进行校验,指定该参数后,才会在 Pod 容器的 ServiceAccount 中放置该 CA 证书文件 #--experimental-cluster-signing-duration:设置为 TLS BootStrapping 签署的证书有效时间为10年,默认为1年 ##生成kube-controller-manager证书 #切换到k8s证书目录操作 cd /opt/k8s/k8s-cert/ #创建证书请求文件 cat > kube-controller-manager-csr.json << EOF { "CN": "system:kube-controller-manager", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:masters", "OU": "System" } ] } EOF #生成证书和私钥 cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager #生成kubeconfig配置文件 KUBE_CONFIG="/opt/kubernetes/cfg/kube-controller-manager.kubeconfig" KUBE_APISERVER="https://192.168.19.20:6443" #配置kubernetes集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=${KUBE_CONFIG} #配置客户端认证参数 kubectl config set-credentials kube-controller-manager \ --client-certificate=./kube-controller-manager.pem \ --client-key=./kube-controller-manager-key.pem \ --embed-certs=true \ --kubeconfig=${KUBE_CONFIG} #设置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=kube-controller-manager \ --kubeconfig=${KUBE_CONFIG} #设置默认上下文 kubectl config use-context default --kubeconfig=${KUBE_CONFIG} ##创建 kube-controller-manager.service 服务管理文件 cat >/usr/lib/systemd/system/kube-controller-manager.service <<EOF [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-controller-manager ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable kube-controller-manager systemctl restart kube-controller-manager

#!/bin/bash #配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书 cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "87600h" }, "profiles": { "kubernetes": { "expiry": "87600h", "usages": [ "signing", "key encipherment", "server auth", "client auth" ] } } } } EOF #生成CA证书和私钥(根证书和私钥) cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "ST": "Beijing", "O": "k8s", "OU": "System" } ] } EOF cfssl gencert -initca ca-csr.json | cfssljson -bare ca - #----------------------- #生成 apiserver 的证书和私钥(apiserver和其它k8s组件通信使用) #hosts中将所有可能作为 apiserver 的 ip 添加进去,后面 keepalived 使用的 VIP 也要加入 cat > apiserver-csr.json <<EOF { "CN": "kubernetes", "hosts": [ "10.0.0.1", "127.0.0.1", "192.168.19.20", #master01 "192.168.19.21", #master02 "192.168.19.100", #vip,后面 keepalived 使用 "192.168.19.27", #load balancer01(master) "192.168.19.28", #load balancer02(backup) "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare apiserver #----------------------- #生成 kubectl 连接集群的证书和私钥(kubectl 和 apiserver 通信使用) cat > admin-csr.json <<EOF { "CN": "admin", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:masters", "OU": "System" } ] } EOF cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin #----------------------- #生成 kube-proxy 的证书和私钥(kube-proxy 和 apiserver 通信使用) cat > kube-proxy-csr.json <<EOF { "CN": "system:kube-proxy", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy

#!/bin/bash ##创建 kube-scheduler 启动参数配置文件 MASTER_ADDRESS=$1 cat >/opt/kubernetes/cfg/kube-scheduler <<EOF KUBE_SCHEDULER_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --leader-elect=true \\ --kubeconfig=/opt/kubernetes/cfg/kube-scheduler.kubeconfig \\ --bind-address=127.0.0.1" EOF #-?kubeconfig:连接 apiserver 用的配置文件,用于识别 k8s 集群 #--leader-elect=true:当该组件启动多个时,自动启动 leader 选举 #k8s 中 Controller-Manager 和 Scheduler 的选主逻辑:k8s 中的 etcd 是整个集群所有状态信息的存储,涉及数据的读写>和多个 etcd 之间数据的同步,对数据的一致性要求严格,所以使用较复杂的 raft 算法来选择用于提交数据的主节点。而 apiserver 作为集群入口,本身是无状态的 web 服务器,多个 apiserver 服务之间直接负载请求并不需要做选主。Controller-Manager 和 Scheduler 作为任务类型的组件,比如 controller-manager 内置的 k8s 各种资源对象的控制器实时的 watch apiserver 获取对象最新的变化事件做期望状态和实际状态调整,scheduler watch 未绑定节点的 pod 做节点选择, 显然多个>这些任务同时工作是完全没有必要的,所以 controller-manager 和 scheduler 也是需要选主的,但是选主逻辑和 etcd 不一 样的,这里只需要保证从多个 controller-manager 和 scheduler 之间选出一个 leader 进入工作状态即可,而无需考虑它们 之间的数据一致和同步。 ##生成kube-scheduler证书 #切换到k8s证书目录操作 cd /opt/k8s/k8s-cert/ #创建证书请求文件 cat > kube-scheduler-csr.json << EOF { "CN": "system:kube-scheduler", "hosts": [], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "BeiJing", "ST": "BeiJing", "O": "system:masters", "OU": "System" } ] } EOF #生成证书和私钥 cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler #生成kubeconfig配置文件 KUBE_CONFIG="/opt/kubernetes/cfg/kube-scheduler.kubeconfig" KUBE_APISERVER="https://192.168.19.20:6443" #配置kubernetes集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=/opt/kubernetes/ssl/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=${KUBE_CONFIG} #配置客户端认证参数 kubectl config set-credentials kube-scheduler \ --client-certificate=./kube-scheduler.pem \ --client-key=./kube-scheduler-key.pem \ --embed-certs=true \ --kubeconfig=${KUBE_CONFIG} #设置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=kube-scheduler \ --kubeconfig=${KUBE_CONFIG} #设置默认上下文 kubectl config use-context default --kubeconfig=${KUBE_CONFIG} ##创建 kube-scheduler.service 服务管理文件 cat >/usr/lib/systemd/system/kube-scheduler.service <<EOF [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-scheduler ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable kube-scheduler systemctl restart kube-scheduler
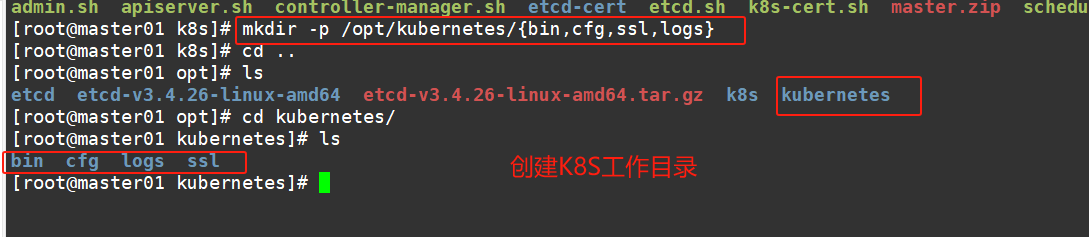





#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包

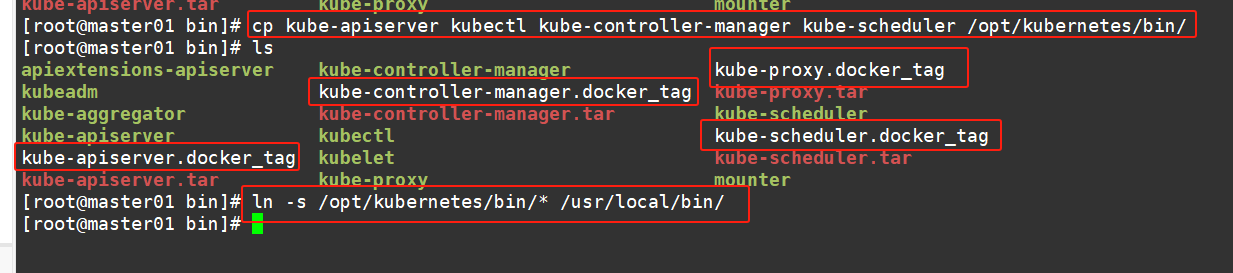
#复制master组件的关键命令文件到 kubernetes工作目录的 bin 子目录中

#创建 bootstrap token 认证文件,apiserver 启动时会调用,然后就相当于在集群内创建了一个这个用户,接下来就可以用 RBAC 给他授权
#!/bin/bash #获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格 BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
cat > /opt/kubernetes/cfg/token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOF

#生成 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成



#二进制文件、token、证书都准备好后,开启 apiserver 服务
./apiserver.sh 192.168.19.20 https://192.168.19.20:2379,https://192.168.19.26:2379,https://192.168.19.25:2379

#检查进程是否启动成功

#安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证

#启动 scheduler 服务


#启动 controller-manager 服务


#生成kubectl连接集群的kubeconfig文件

#绑定默认cluster-admin管理员集群角色,授权kubectl访问集群
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
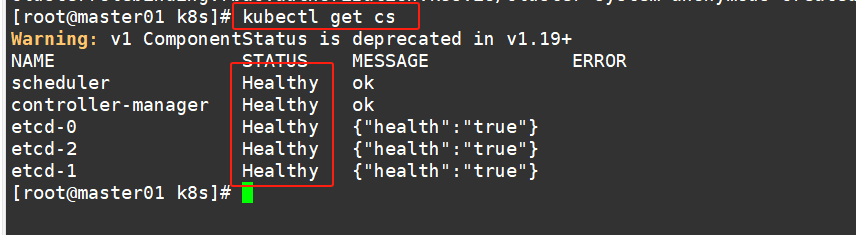
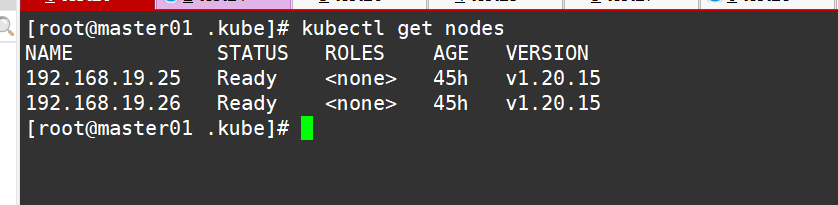
#通过kubectl工具查看当前集群组件状态

#查看版本信息
部署 Worker Node 组件

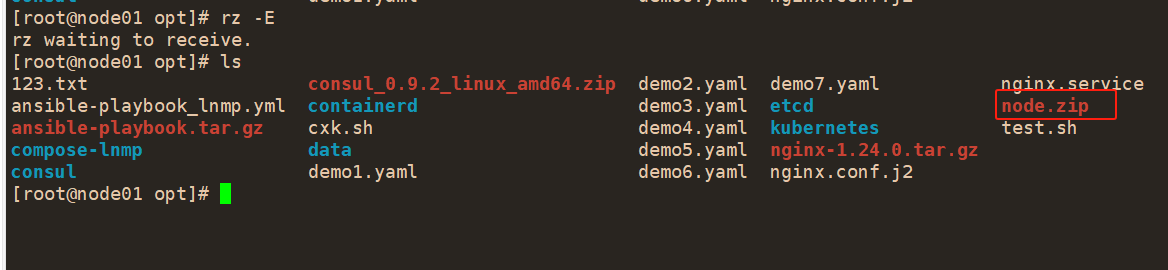
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh


#!/bin/bash NODE_ADDRESS=$1 DNS_SERVER_IP=${2:-"10.0.0.2"} #创建 kubelet 启动参数配置文件 cat >/opt/kubernetes/cfg/kubelet <<EOF KUBELET_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --hostname-override=${NODE_ADDRESS} \\ --network-plugin=cni \\ --kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\ --bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\ --config=/opt/kubernetes/cfg/kubelet.config \\ --cert-dir=/opt/kubernetes/ssl \\ --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause-amd64:3.2" EOF #--hostname-override:指定kubelet节点在集群中显示的主机名或IP地址,默认使用主机hostname;kube-proxy和kubelet的>此项参数设置必须完全一致 #--network-plugin:启用CNI #--kubeconfig:指定kubelet.kubeconfig文件位置,当前为空路径,会自动生成,用于如何连接到apiserver,里面含有kubelet证书,master授权完成后会在node节点上生成 kubelet.kubeconfig 文件 #--bootstrap-kubeconfig:指定连接 apiserver 的 bootstrap.kubeconfig 文件 #--config:指定kubelet配置文件的路径,启动kubelet时将从此文件加载其配置 #--cert-dir:指定master颁发的kubelet证书生成目录 #--pod-infra-container-image:指定Pod基础容器(Pause容器)的镜像。Pod启动的时候都会启动一个这样的容器,每个pod>里容器之间的相互通信需要Pause的支持,启动Pause需要Pause基础镜像 #---------------------- #创建kubelet配置文件(该文件实际上就是一个yml文件,语法非常严格,不能出现tab键,冒号后面必须要有空格,每行结尾>也不能有空格) cat >/opt/kubernetes/cfg/kubelet.config <<EOF kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 address: ${NODE_ADDRESS} port: 10250 readOnlyPort: 10255 cgroupDriver: systemd clusterDNS: - ${DNS_SERVER_IP} clusterDomain: cluster.local failSwapOn: false authentication: anonymous: enabled: true EOF #PS:当命令行参数与此配置文件(kubelet.config)有相同的值时,就会覆盖配置文件中的该值。 #---------------------- #创建 kubelet.service 服务管理文件 cat >/usr/lib/systemd/system/kubelet.service <<EOF [Unit] Description=Kubernetes Kubelet After=docker.service Requires=docker.service [Service] EnvironmentFile=/opt/kubernetes/cfg/kubelet ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS Restart=on-failure KillMode=process [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable kubelet systemctl restart kubelet

#!/bin/bash NODE_ADDRESS=$1 #创建 kube-proxy 启动参数配置文件 cat >/opt/kubernetes/cfg/kube-proxy <<EOF KUBE_PROXY_OPTS="--logtostderr=false \\ --v=2 \\ --log-dir=/opt/kubernetes/logs \\ --hostname-override=${NODE_ADDRESS} \\ --cluster-cidr=10.244.0.0/16 \\ --proxy-mode=ipvs \\ --kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig" EOF #--hostnameOverride: 参数值必须与 kubelet 的值一致,否则 kube-proxy 启动后会找不到该 Node,从而不会创建任何 ipvs 规则 #--cluster-cidr:指定 Pod 网络使用的聚合网段,Pod 使用的网段和 apiserver 中指定的 service 的 cluster ip 网段不>是同一个网段。 kube-proxy 根据 --cluster-cidr 判断集群内部和外部流量,指定 --cluster-cidr 选项后 kube-proxy 才>会对访问 Service IP 的请求做 SNAT,即来自非 Pod 网络的流量被当成外部流量,访问 Service 时需要做 SNAT。 #--kubeconfig: 指定连接 apiserver 的 kubeconfig 文件 #--proxy-mode:指定流量调度模式为ipvs模式,可添加--ipvs-scheduler选项指定ipvs调度算法(rr|lc|dh|sh|sed|nq) #rr: round-robin,轮询。 #lc: least connection,最小连接数。 #dh: destination hashing,目的地址哈希。 #sh: source hashing ,原地址哈希。 #sed: shortest expected delay,最短期望延时。 #nq: never queue ,永不排队。 #---------------------- #创建 kube-proxy.service 服务管理文件 cat >/usr/lib/systemd/system/kube-proxy.service <<EOF [Unit] Description=Kubernetes Proxy After=network.target [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF systemctl daemon-reload systemctl enable kube-proxy systemctl restart kube-proxy

#执行权限


#上传kubeconfig.sh文件到/opt/k8s/kubeconfig目录中,生成kubelet初次加入集群引导kubeconfig文件和kube-proxy.kubeconfig文件
#kubeconfig 文件包含集群参数(CA 证书、API Server 地址),客户端参数(上面生成的证书和私钥),集群 context 上下文参数(集群名称、用户名)。Kubenetes 组件(如 kubelet、kube-proxy)通过启动时指定不同的 kubeconfig 文件可以切换到不同的集群,连接到 apiserver。
#!/bin/bash #example: kubeconfig 192.168.19.20 /opt/k8s/k8s-cert/ #创建bootstrap.kubeconfig文件 #该文件中内置了 token.csv 中用户的 Token,以及 apiserver CA 证书;kubelet 首次启动会加载此文件,使用 apiserver CA 证书建立与 apiserver 的 TLS 通讯,使用其中的用户 Token 作为身份标识向 apiserver 发起 CSR 请求 BOOTSTRAP_TOKEN=$(awk -F ',' '{print $1}' /opt/kubernetes/cfg/token.csv) APISERVER=$1 SSL_DIR=$2 export KUBE_APISERVER="https://$APISERVER:6443" # 设置集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=$SSL_DIR/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=bootstrap.kubeconfig #--embed-certs=true:表示将ca.pem证书写入到生成的bootstrap.kubeconfig文件中 # 设置客户端认证参数,kubelet 使用 bootstrap token 认证 kubectl config set-credentials kubelet-bootstrap \ --token=${BOOTSTRAP_TOKEN} \ --kubeconfig=bootstrap.kubeconfig # 设置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=kubelet-bootstrap \ --kubeconfig=bootstrap.kubeconfig # 使用上下文参数生成 bootstrap.kubeconfig 文件 kubectl config use-context default --kubeconfig=bootstrap.kubeconfig #---------------------- #创建kube-proxy.kubeconfig文件 # 设置集群参数 kubectl config set-cluster kubernetes \ --certificate-authority=$SSL_DIR/ca.pem \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=kube-proxy.kubeconfig # 设置客户端认证参数,kube-proxy 使用 TLS 证书认证 kubectl config set-credentials kube-proxy \ --client-certificate=$SSL_DIR/kube-proxy.pem \ --client-key=$SSL_DIR/kube-proxy-key.pem \ --embed-certs=true \ --kubeconfig=kube-proxy.kubeconfig # 设置上下文参数 kubectl config set-context default \ --cluster=kubernetes \ --user=kube-proxy \ --kubeconfig=kube-proxy.kubeconfig # 使用上下文参数生成 kube-proxy.kubeconfig 文件 kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig


./kubeconfig.sh 192.168.19.20 /opt/k8s/k8s-cert/


#把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 拷贝到 node 节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.19.26:/opt/kubernetes/cfg/ scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.19.25:/opt/kubernetes/cfg/

#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
----------------------------------------------------------------------------------------- kubelet 采用 TLS Bootstrapping 机制,自动完成到 kube-apiserver 的注册,在 node 节点量较大或者后期自动扩容时非常有用。 Master apiserver 启用 TLS 认证后,node 节点 kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与 apiserver 通信,当 node 节点很多时,签署证书是一件很繁琐的事情。因此 Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书,kubelet 会以一个低权限用户自动向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。 kubelet 首次启动通过加载 bootstrap.kubeconfig 中的用户 Token 和 apiserver CA 证书发起首次 CSR 请求,这个 Token 被预先内置在 apiserver 节点的 token.csv 中,其身份为 kubelet-bootstrap 用户和 system:kubelet-bootstrap 用户组;想要首次 CSR 请求能成功(即不会被 apiserver 401 拒绝),则需要先创建一个 ClusterRoleBinding,将 kubelet-bootstrap 用户和 system:node-bootstrapper 内置 ClusterRole 绑定(通过 kubectl get clusterroles 可查询),使其能够发起 CSR 认证请求。 TLS bootstrapping 时的证书实际是由 kube-controller-manager 组件来签署的,也就是说证书有效期是 kube-controller-manager 组件控制的;kube-controller-manager 组件提供了一个 --experimental-cluster-signing-duration 参数来设置签署的证书有效时间;默认为 8760h0m0s,将其改为 87600h0m0s,即 10 年后再进行 TLS bootstrapping 签署证书即可。 也就是说 kubelet 首次访问 API Server 时,是使用 token 做认证,通过后,Controller Manager 会为 kubelet 生成一个证书,以后的访问都是用证书做认证了。
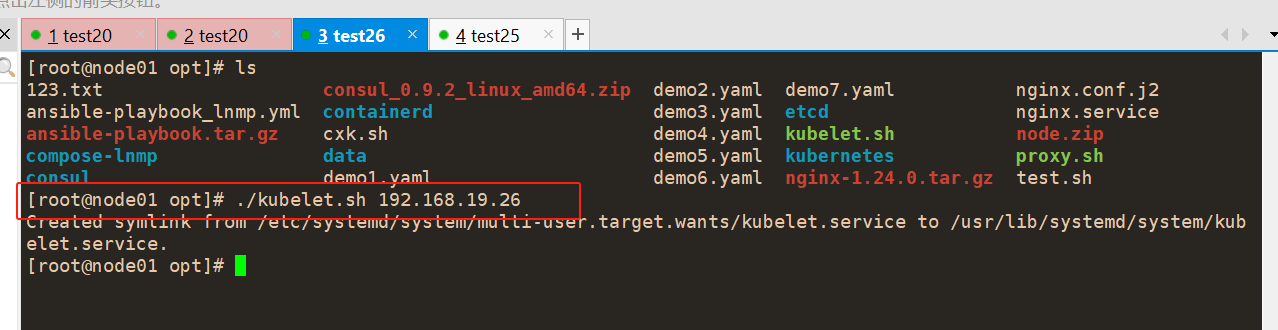
#启动 kubelet 服务


在 master01 节点上操作,通过 CSR 请求
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
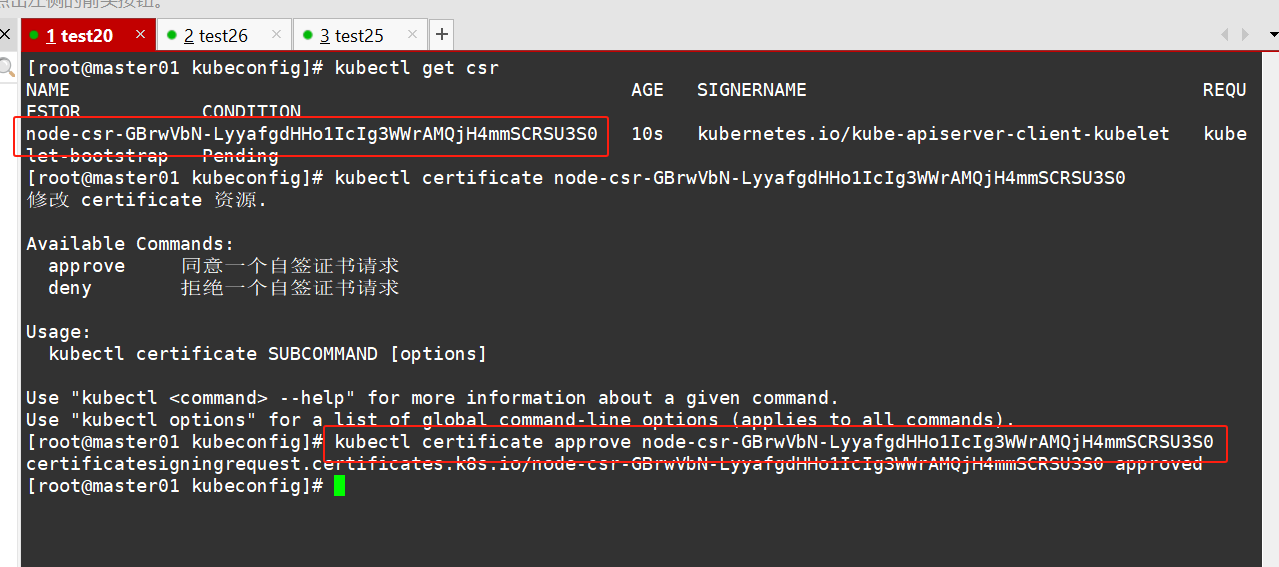
#通过 CSR 请求
kubectl certificate approve node-csr-GBrwVbN-LyyafgdHHo1IcIg3WWrAMQjH4mmSCRSU3S0

#Approved,Issued 表示已授权 CSR 请求并签发证书

#.pm证书已有

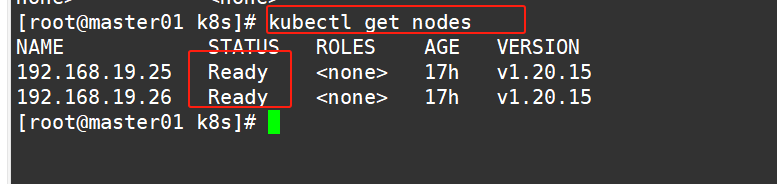
#查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done

#启动proxy服务
#25node节点服务器加载ipvs模块

#自动签发证书命令
kubectl create clusterrolebinding node-autoapprove-bootstrap --clusterrole=system:certificates.k8s.io:certificatesigningrequests:nodeclient --user=kubelet-bootstrap
kubectl create clusterrolebinding node-autoappove-certificate-rotation --clusterrole=system:certificates.k8s.io:certificatesigningrequests:selfnodeclient --user=kubelet-bootstrap




#notready原因: 网络插件为安装
部署 CNI 网络组件
部署 flannel
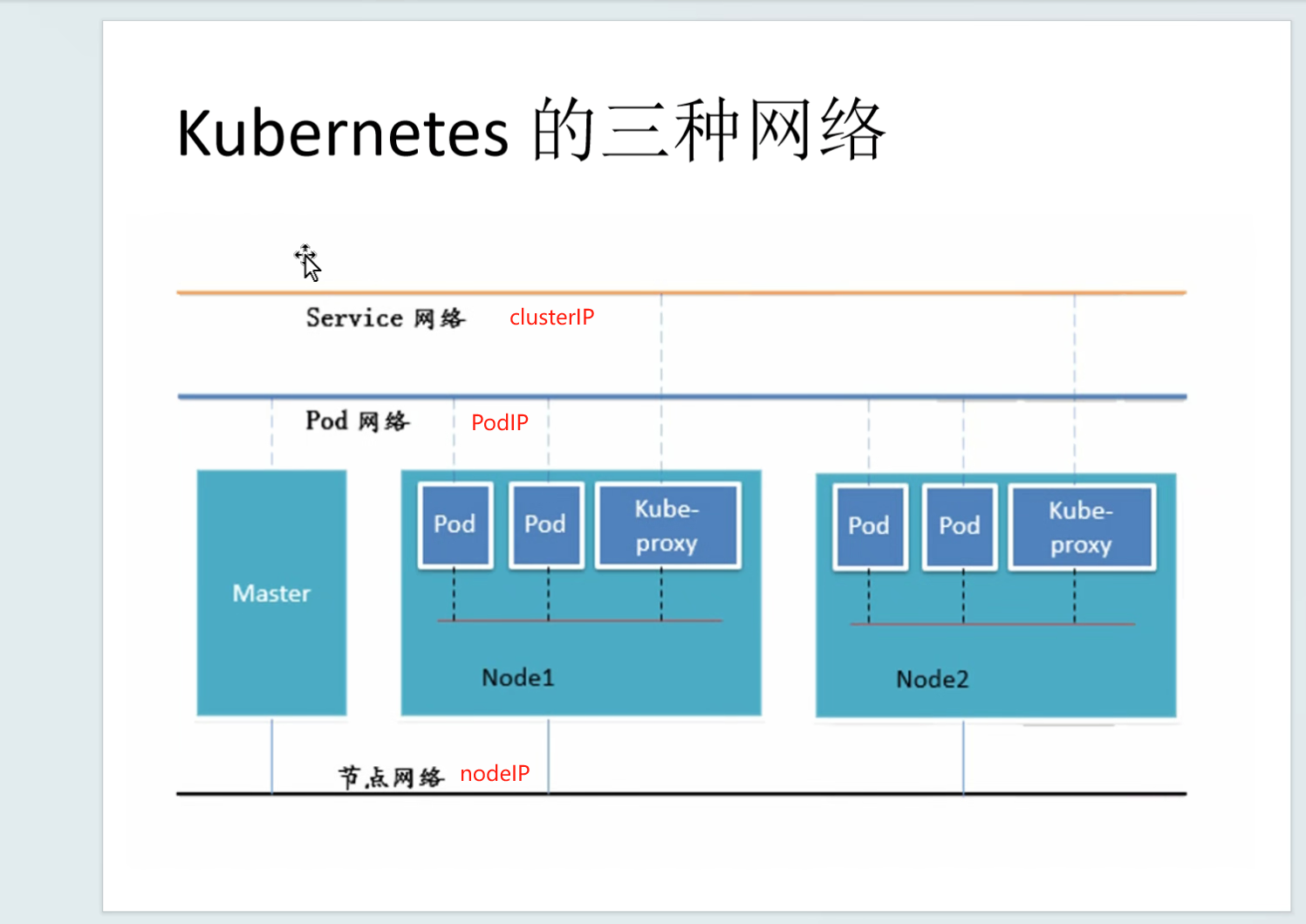
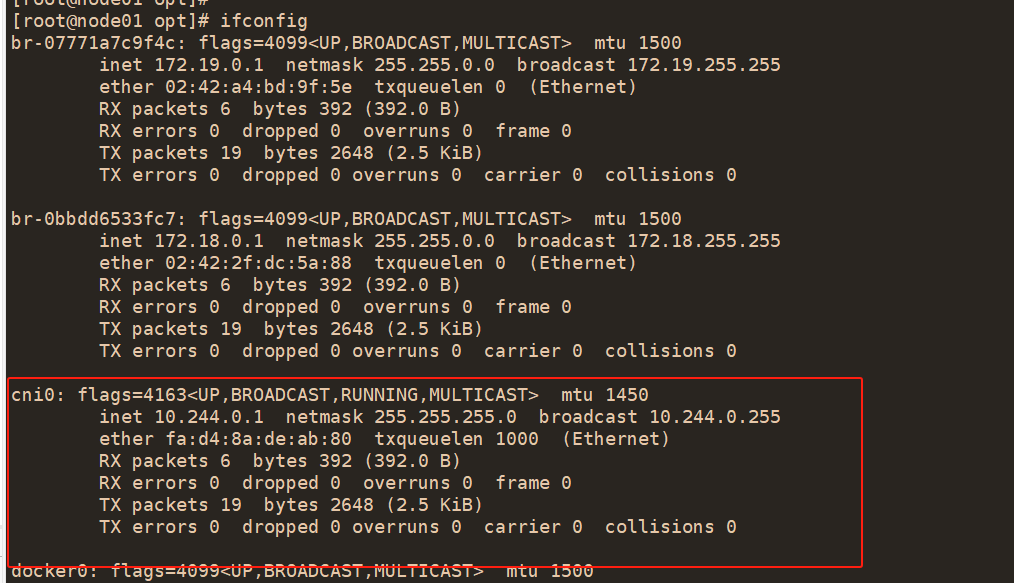
K8S 中 Pod 网络通信: ●Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。 ●同一个 Node 内 Pod 之间的通信 每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0 网桥,网段相同,所以它们之间可以直接通信。 ●不同 Node 上 Pod 之间的通信 Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的通信只能通过宿主机的物理网卡进行。 要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。因此要满足两个条件:Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。 Overlay Network: 叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)。 VXLAN: Virturl Extensible LAN(虚拟可扩展局域网) 将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。 Flannel: Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。 Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,目前支持 udp、vxlan、 host-GW 3种数据转发方式。 #Flannel udp 模式的工作原理: 数据从 node01 上 Pod 的源容器中发出后,经由所在主机的 docker0 虚拟网卡转发到 flannel.1 虚拟网卡,flanneld 服务监听在 flannel.1 虚拟网卡的另外一端。 Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 node01 的 flanneld 服务将原本的数据内容封装到 UDP 中后根据自己的路由表通过物理网卡投递给目的节点 node02 的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel.1 虚拟网卡,之后被转发到目的主机的 docker0 虚拟网卡,最后就像本机容器通信一样由 docker0 转发到目标容器。 #ETCD 之 Flannel 提供说明: 存储管理Flannel可分配的IP地址段资源 监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表 由于 udp 模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的 vxlan 模式差。 #vxlan 模式: vxlan 是一种overlay(虚拟隧道通信)技术,通过三层网络搭建虚拟的二层网络,跟 udp 模式具体实现不太一样: (1)udp模式是在用户态实现的,数据会先经过tun网卡,到应用程序,应用程序再做隧道封装,再进一次内核协议栈,而vxlan是在内核当中实现的,只经过一次协议栈,在协议栈内就把vxlan包组装好 (2)udp模式的tun网卡是三层转发,使用tun是在物理网络之上构建三层网络,属于ip in udp,vxlan模式是二层实现, overlay是二层帧,属于mac in udp (3)vxlan由于采用mac in udp的方式,所以实现起来会涉及mac地址学习,arp广播等二层知识,udp模式主要关注路由 #Flannel vxlan 模式的工作原理: vxlan在内核当中实现,当数据包使用vxlan设备发送数据时,会打上vlxan的头部信息,在发送出去,对端解包,flannel.1网卡把原始报文发送到目的服务器。
Kubernetes三种网络
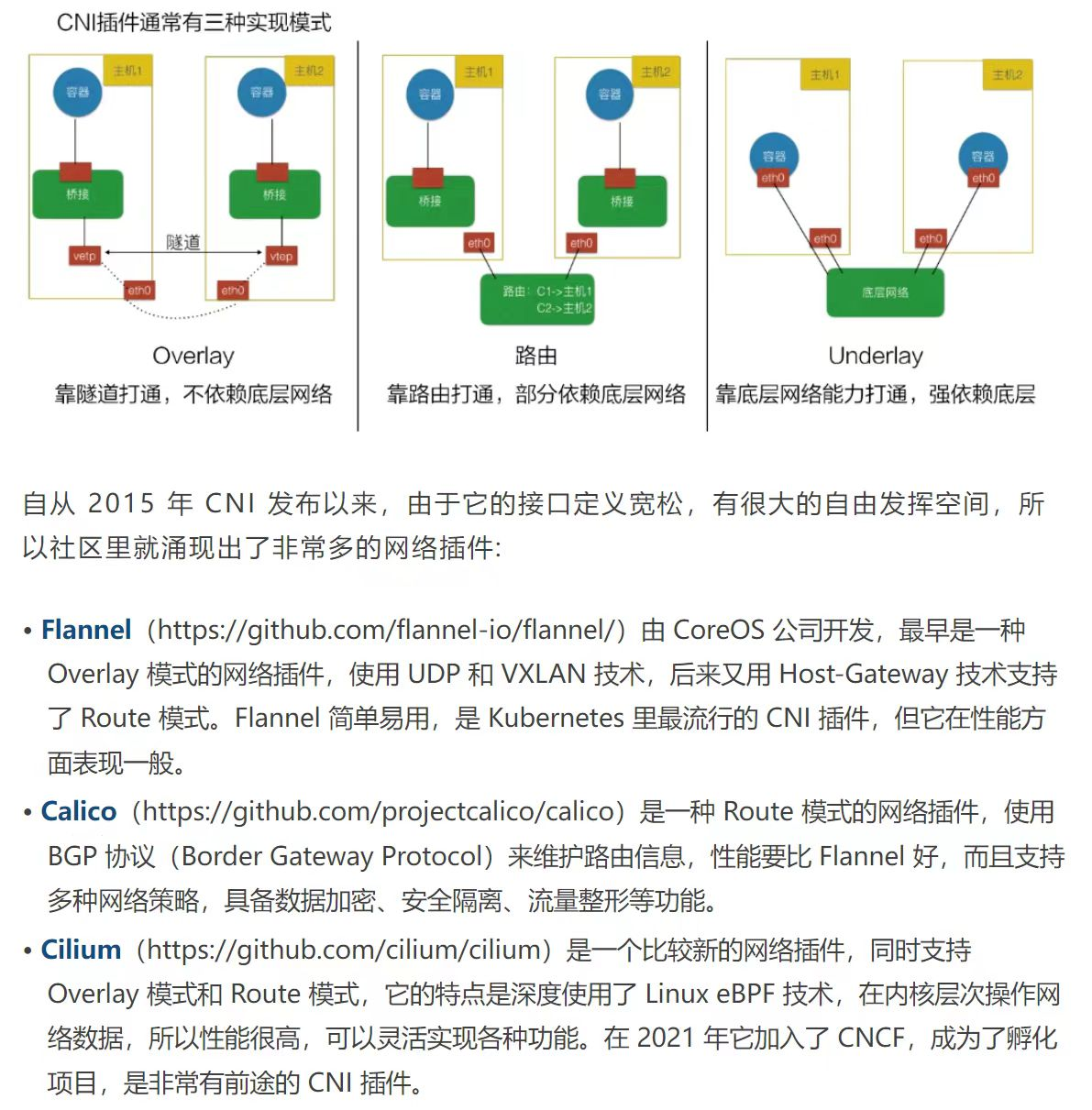
#vxlan与vlan区别: #vxlan支持更多的二层网络 vlan使用12位bit表示vlanlD,因此最多支持2^12=4094个vlan vxlan使用的ID使用24位bit,最多可以支持224个 (2^24个) #已有的网络路径利用效率更高 vlan使用spanning tree protocol避免环路,会将一半的网络路径阻塞 vxlan的数据包封装成UDP通过网络层传输,可以使用所有的网络路径 #防止物理交换机Mac表耗尽 van需要在交换机的Mac表中记录Mac物理地址 vxlan采用隧道机制,Mac物理地址不需记录在交换机
#相比VLAN技术,VXLAN技术具有以下的优势:
24位长度的VNI字段值可以支持更多数量的虚拟网络,解决了VLAN数目上限为4094的局限性的问题。
VXLAN技术通过隧道技术在物理的三层网络中虚拟二层网络,处于VXLAN网络的终端无法察觉到VXLAN的通信过程,这样也就使得逻辑网络拓扑和物理网络拓扑实现了一定程度的解耦,网络拓扑的配置对于物理设备的配置的依赖程度有所降低,配置更灵活更方便。
VLAN技术仅仅解决了二层网络广播域分割的问题,而VXLAN技术还具有多租户支持的特性,通过VXLAN分割,各个租户可以独立组网、通信,地址分配方面和多个租户之间地址冲突的问题也得到了解决。
1) VxLAN: 而VxLAN有两种工作方式: a.VxLAN: 这是原生的VxLAN,即直接封装VxLAN首部,UDP首部,IP,MAC首部这种的。b. DirectRouting: 这种是混合自适应的方式,即它会自动判断,若当前是相同二层网络(即:不垮路由器,二层广播可直达),则直接使用Host-GW方式工作,若发现目标是需要跨网段(即:跨路由器)则自动转变为使用VxLAN的方式。 2) host-GW: 这种方式是宿主机内Pod通过虚拟网桥互联,然后将宿主机的物理网卡作为网关,当需要访问其它Node上的Pod时,只需要将报文发给宿主机的物理网卡,由宿主机通过查询本地路由表,来做路由转发,实现跨主机的Pod通信,这种模式带来的问题时,当k8s集群非常大时,会导致宿主机上的路由表变得非常巨大,而且这种方式,要求所有Node必须在同一个二层网络中,否则将无法转发路由,这也很容易理解,因为如果Node之间是跨路由的,那中间的路由器就必须知道Pod网络的存在,它才能实现路由转发,但实际上,宿主机是无法将Pod网络通告给中间的路由器,因此它也就无法转发理由。 3)UDP:这种方式性能最差的方式,这源于早期flannel刚出现时,Linux内核还不支持VLAN,即没有VLAN核心模块因此flanne采用了这种方式,来实现隧道封装,其效率可想而知,因此也给很多人一种印象,flannel的性能很差,其实说的是这种工作模式,若flannel工作在host-GW模式下,其效率是非常高的,因为几乎没有网络开销。

#flannel 的三种模式 UDP 出现最早的模式,但是性能最差,基于flanneld应用程序实现数据包的封装、解封装 VXLAN flannel的默认模式,也是推荐使用的模式,性能比UDP模式更好,基于内核实现数据帧的封装和解封装,而且配置简单使用方便 HOST-GW 性能最好的模式,但是配置复杂,且不能跨网段。 #flannel的UDP模式工作原理 1)原始数据报文从源主机的Pod容器发出到CNI0网桥接口,再由CNI0转发到flannel0虚拟接口 2)flanneld服务进程会监听flannel0接口接受到的数据,flanneld进程会将㡳数据包封装到UDP报文里 3)flanneld进程会根据在EDCT中维护的路由表查到目标Pod所在的nodeIP,并在UDP报文外封装nodeIP头部、MAC头部,再通过物理网卡发送到目标node节点 4)UDP报文会通过82 85号 端口送到目标node节点flanneld进程进行解封装,再根据本地路由器通过flannel0接口发送到CNI0网桥,再由CNI0发送到目标Pod容器
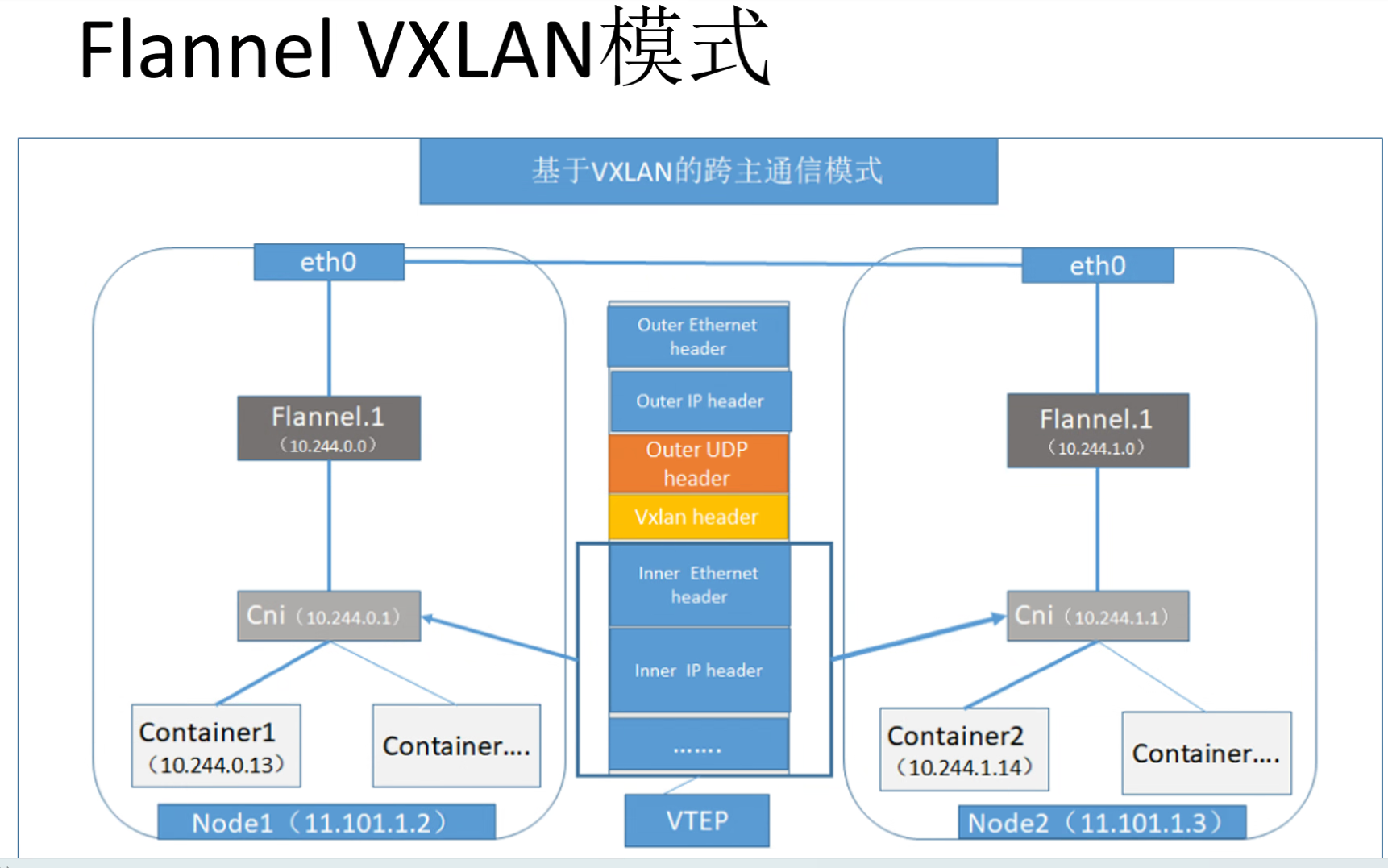
#flannel的VLAN模式工作原理 1)原始数据帧从源主机的Pod容器发出到CNI0网桥接口,再由CNI0转发到flannel.1虚拟接口 2)flannel.1接口接收到数据帧后田间VXLAN头部,并在内核将原始数据帧封装到UDP报文里 3)根据etcd中维护的路由表查到目标Pod所在的nodeIP,并在UDP报文外封装nodeIP头部、mac头部,再通过物理网卡发送到目标node节点 4)UDP报文通过8472端口送达到目标node节点的flannel.1接口并在内核进行解封装,再根据本地路由器发送到CNI0网桥,再由CNI0发送到目标Pod容器

#上传并解压flannel包
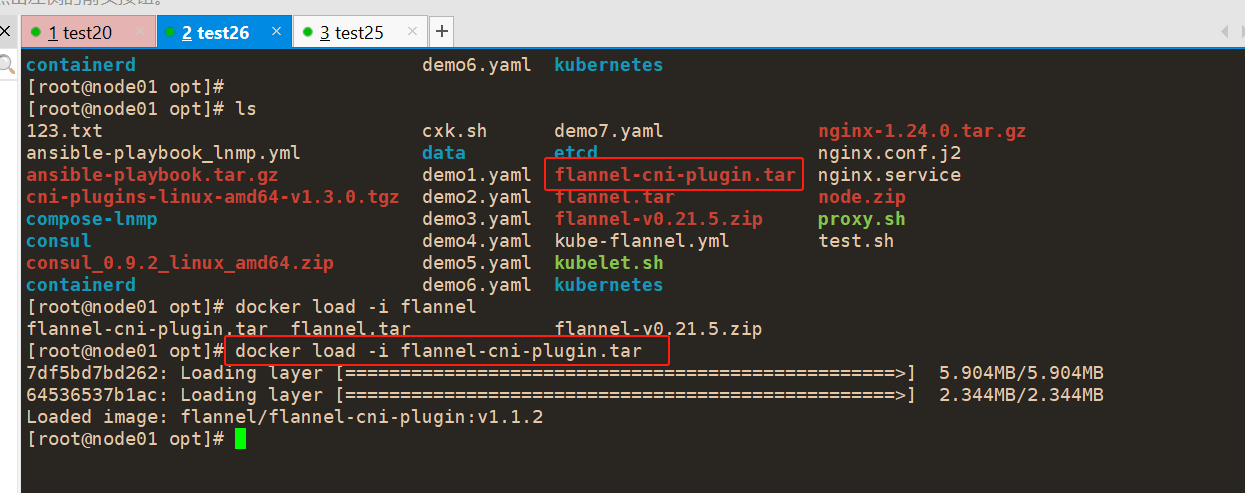

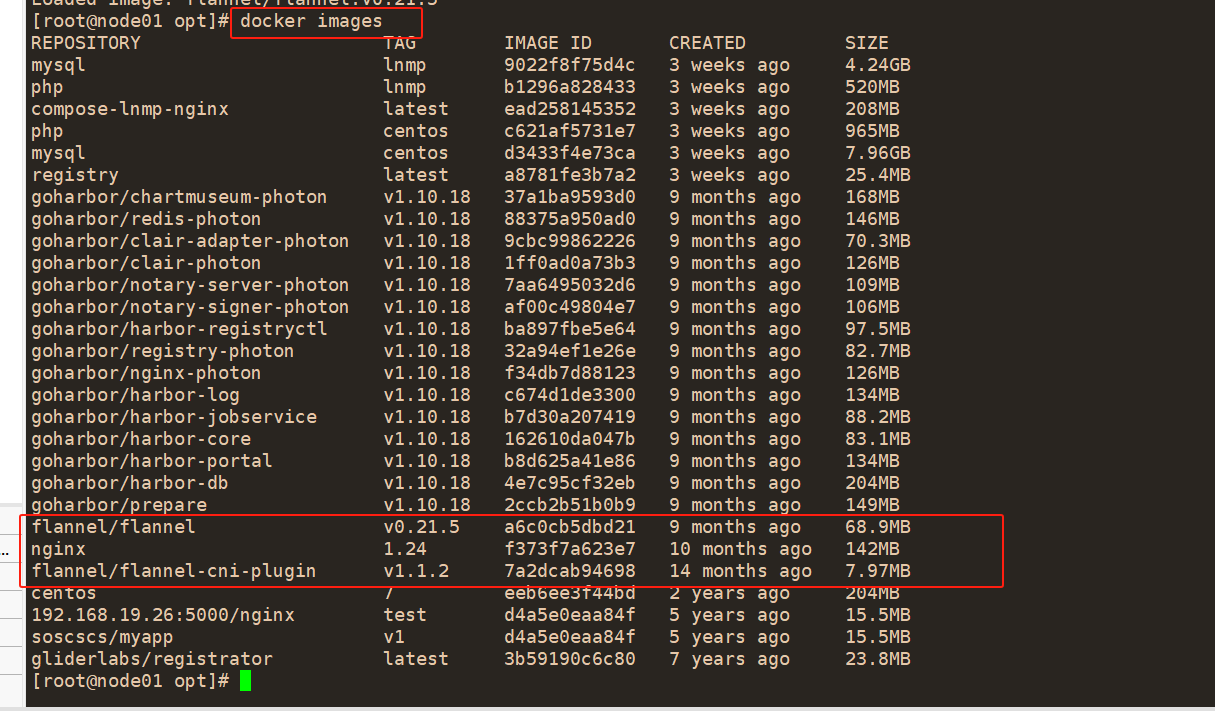
#导入镜像




#开启proxy
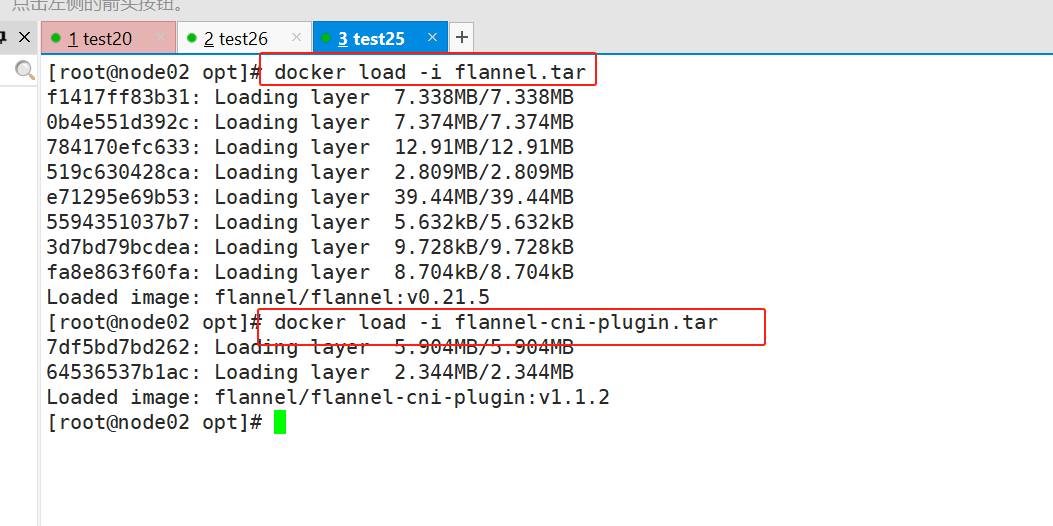
#导入镜像




apiVersion: v1 kind: Namespace metadata: labels: k8s-app: flannel pod-security.kubernetes.io/enforce: privileged name: kube-flannel --- apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: flannel name: flannel namespace: kube-flannel --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: flannel name: flannel rules: - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - get - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch - apiGroups: - networking.k8s.io resources: - clustercidrs verbs: - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: flannel name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-flannel --- apiVersion: v1 data: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } kind: ConfigMap metadata: labels: app: flannel k8s-app: flannel tier: node name: kube-flannel-cfg namespace: kube-flannel --- apiVersion: apps/v1 kind: DaemonSet metadata: labels: app: flannel k8s-app: flannel tier: node name: kube-flannel-ds namespace: kube-flannel spec: selector: matchLabels: app: flannel k8s-app: flannel template: metadata: labels: app: flannel k8s-app: flannel tier: node spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux containers: - args: - --ip-masq - --kube-subnet-mgr command: - /opt/bin/flanneld env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: EVENT_QUEUE_DEPTH value: "5000" image: docker.io/flannel/flannel:v0.21.5 name: kube-flannel resources: requests: cpu: 100m memory: 50Mi securityContext: capabilities: add: - NET_ADMIN - NET_RAW privileged: false volumeMounts: - mountPath: /run/flannel name: run - mountPath: /etc/kube-flannel/ name: flannel-cfg - mountPath: /run/xtables.lock name: xtables-lock hostNetwork: true initContainers: - args: - -f - /flannel - /opt/cni/bin/flannel command: - cp image: docker.io/flannel/flannel-cni-plugin:v1.1.2 name: install-cni-plugin volumeMounts: - mountPath: /opt/cni/bin name: cni-plugin - args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist command: - cp image: docker.io/flannel/flannel:v0.21.5 name: install-cni volumeMounts: - mountPath: /etc/cni/net.d name: cni - mountPath: /etc/kube-flannel/ name: flannel-cfg priorityClassName: system-node-critical serviceAccountName: flannel tolerations: - effect: NoSchedule operator: Exists volumes: - hostPath: path: /run/flannel name: run - hostPath: path: /opt/cni/bin name: cni-plugin - hostPath: path: /etc/cni/net.d name: cni - configMap: name: kube-flannel-cfg name: flannel-cfg - hostPath: path: /run/xtables.lock type: FileOrCreate name: xtables-lock



#都为running时 插件部署完成






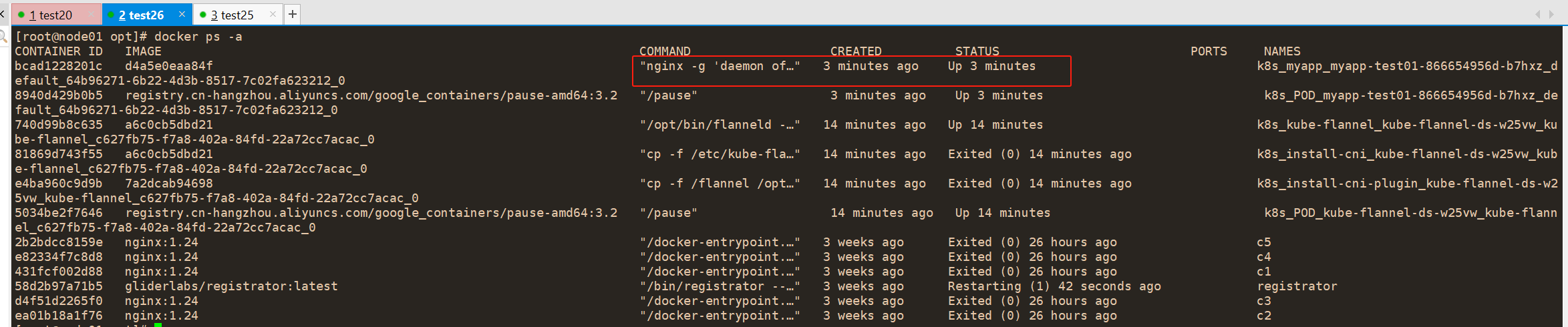


#进入容器

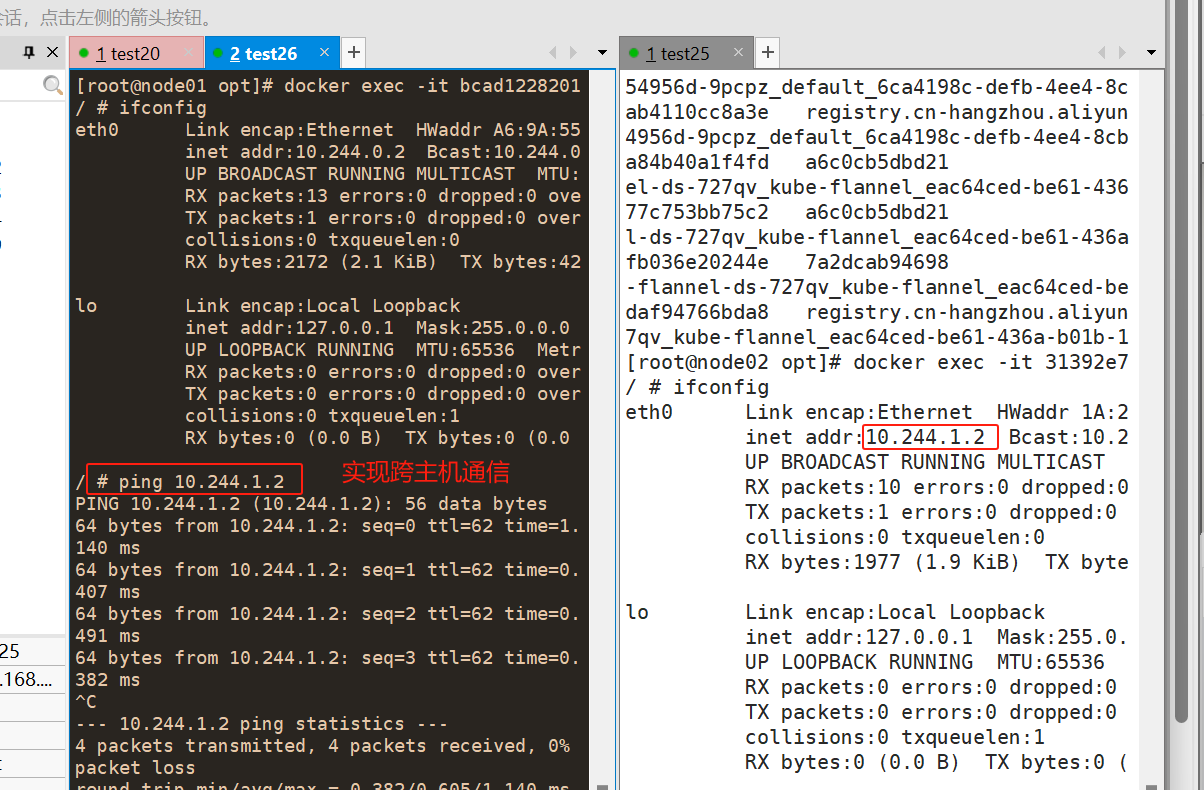


#查看标签

kubectl expose deployment myapp-test01 --port=80 --target-port=80
#创建service资源

#查看资源
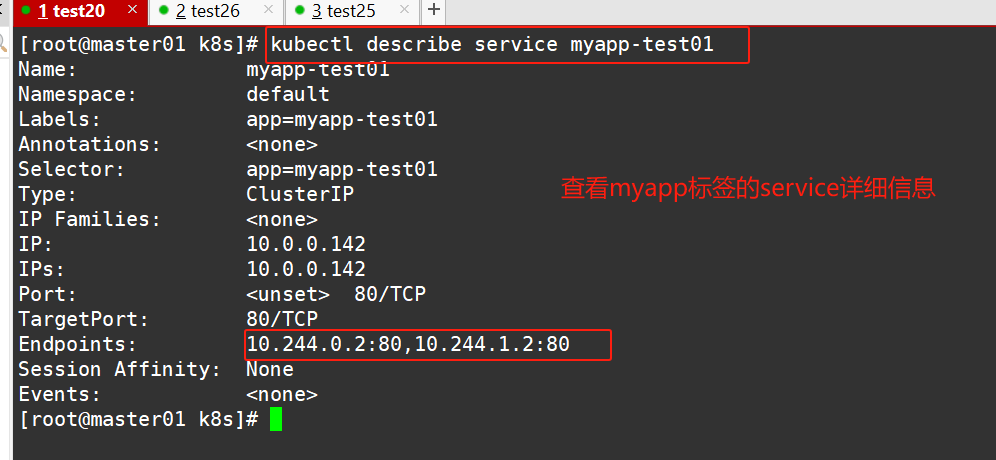


#验证两个相互通信
calico 的 IPIP模式的工作原理

1)原始数据包从源主机的Pod容器发出到tunl0接口,再被内核的IPIP 驱动封装到node节点网络的IP报文里 2)根据felix维护的路由规则,通过物理网卡发送到目标node节点 3)IP数据包到达目标node节点后tunl0,再通过内核的IPIP驱动解封装得到原始数据包,再根据本地路由器通过 veth pair 设备送达到目标Pod容器
calico的BGP模式的工作原理
#calico的BGP模式的工作原理 (本质就是通过路由规则来实现Pod之间的通信) 每个Pod容器都有一个veth pair 设备,一端接入容器,另一端接入宿主机网络空间,并设置一条路由规则 这些路由规则都是由felix 维护配置的,由 BIRD 组件基于 BGP 动态路由协议分发路由信息 如何进行数据包转发? 1)原始数据包从源主机的Pod容器发出,通过 veth pair 设备送达到宿主机网络空间 2)根据Felix维护的路由规则,通过物理网卡发送到目标node节点 3)目标node节点接受到数据包后,根据本地路由规则通过 veth pair 设备送达到目标Pod容器
flannel 与 calico区别
#flannel 与 calico区别 flannel: UDP VXLAN HOST-GW 默认网段: 10.244.0.0/16 通常会采用VXLAN模式,用的是叠加网络,IP隧道方式传输数据,对性能有一定的影响 flannel 产品成熟,依赖性较少,易于安装,功能简单,配置方便,利于管理,但是不具备复杂的网络策略规则配置能力 calico: IPIP BGP 混合模式(CrossSubnet) 默认网段: 192.168.0.0/16 使用IPIP模式可以实现跨子网传输,但是传输过程中需要额外的封包和解包过程,对性能有一定的影响 使用BGP模式 会把node节点看作成路由器,通过Felix、BIRD组件来维护和分发路由规则,可实现通过BGP路由协议实现路由转发,传输过程中不需要额外的封包和解包过程,因此性能较好,但是只能在同一个网段里使用,无法跨子网传输 calico 不使用CNI0网桥,而通过路由规则把数据包直接发送到目标主机,所以性能较高;而且还具有更丰富的网络策略配置管理能力,功能更全面,但是维护起来较为复杂 # 所以对于较小规模且网络要求简单K8S集群,可以采用flannel作为CNI网络插件,对于集群规模较大且要求更多的网络策略配置时,可以考虑采用性能更好,功能更全面的calico或者cilium
部署 CoreDNS
CoreDNS 是K8S默认的内部DNS功能实现,为K8S集群内的Pod提供DNS解析服务
根据service 的资源名称 解析出对应的clusterIP
根据statefulset 控制器 创建的Pod资源名称 解析出对应的PodIP

#在node01,node02节点上上传镜像包
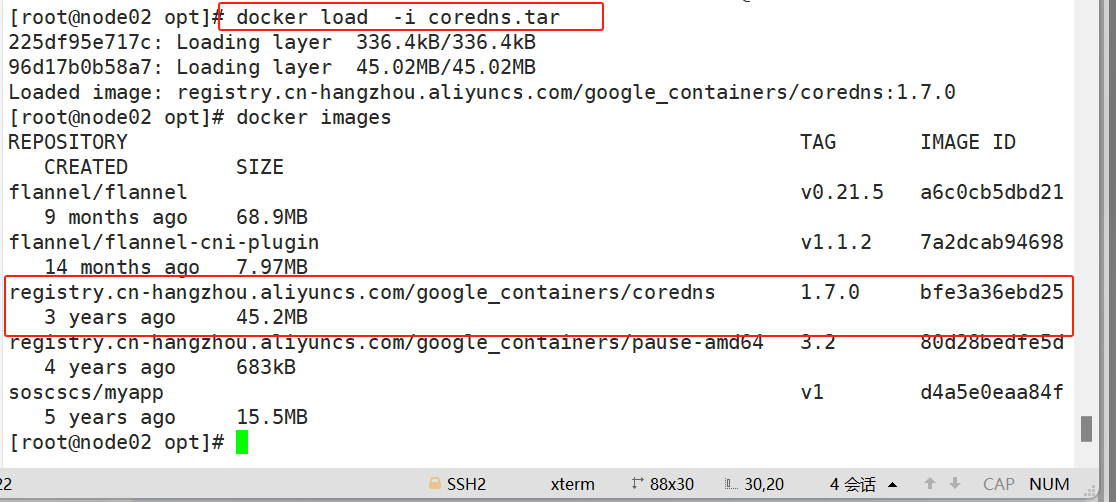

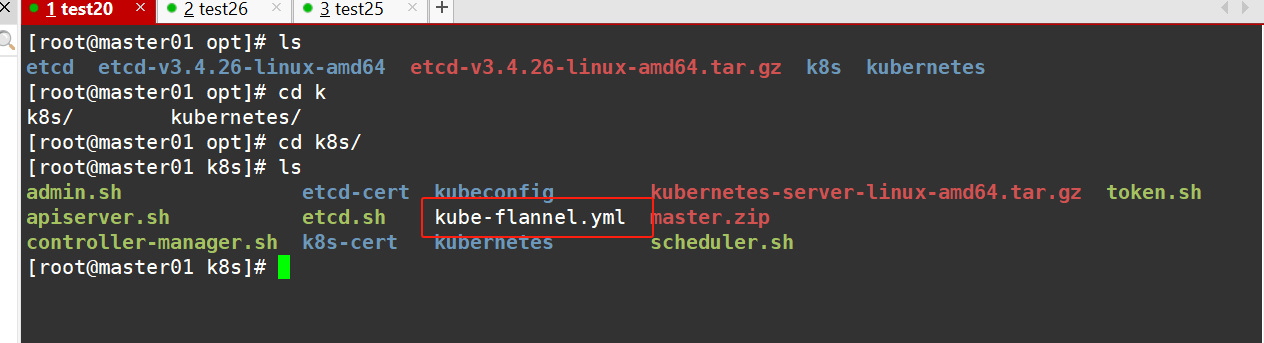
#在master服务器上上传coredns.yaml 文件
# __MACHINE_GENERATED_WARNING__ apiVersion: v1 kind: ServiceAccount metadata: name: coredns namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: kubernetes.io/bootstrapping: rbac-defaults addonmanager.kubernetes.io/mode: Reconcile name: system:coredns rules: - apiGroups: - "" resources: - endpoints - services - pods - namespaces verbs: - list - watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
securityContext:
seccompProfile:
type: RuntimeDefault
priorityClassName: system-cluster-critical
serviceAccountName: coredns
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values: ["kube-dns"]
topologyKey: kubernetes.io/hostname
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
nodeSelector:
kubernetes.io/os: linux
containers:
- name: coredns
image: registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /ready
port: 8181
scheme: HTTP
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.0.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
- name: metrics
port: 9153
protocol: TCP
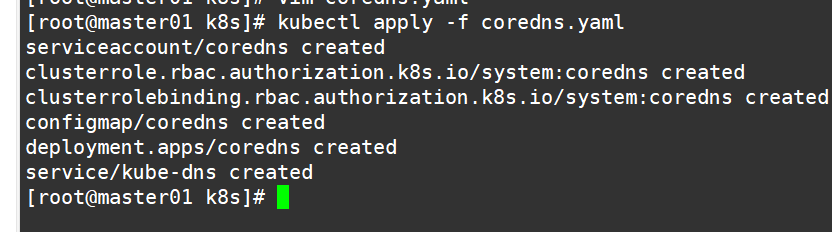
#部署 CoreDNS

kubectl get pods -n kube-system


#解析IP

#可以ping标签

kubectl create service clusterip svc-cxk --tcp=8080:80
部署多master (master02)




#两个master和node的hosts都加上新加入的masterIP与主机名
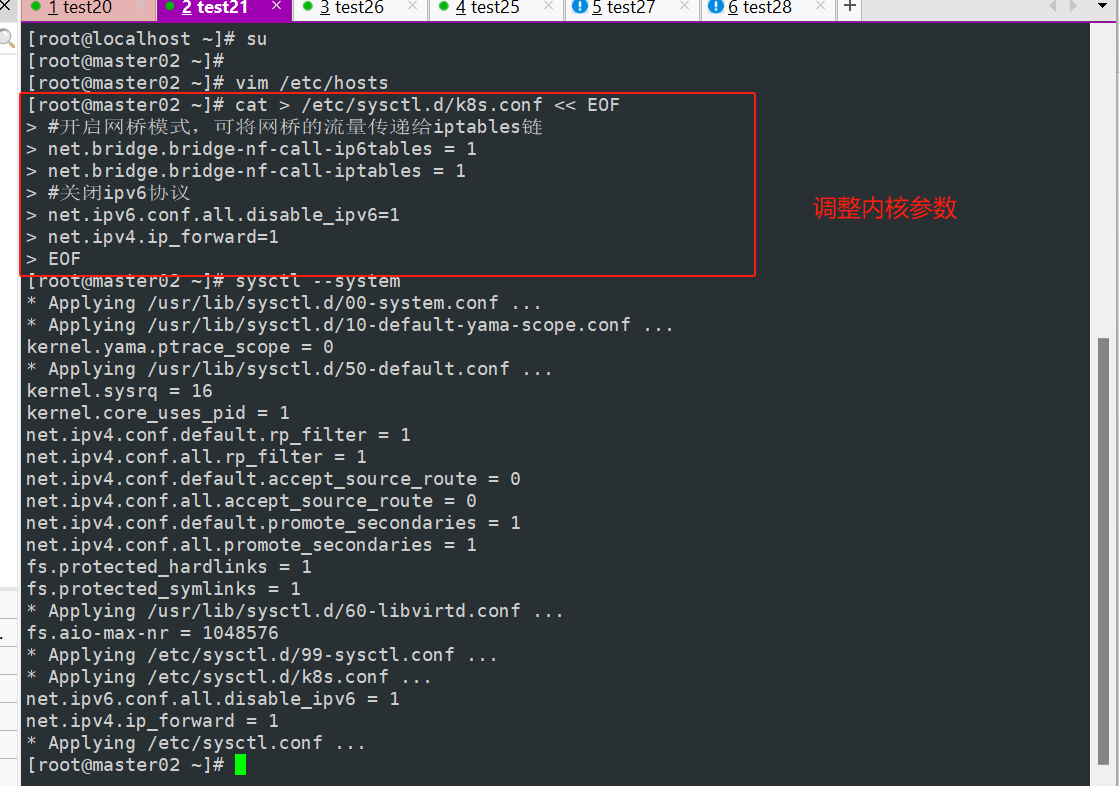
cat > /etc/sysctl.d/k8s.conf << EOF #开启网桥模式,可将网桥的流量传递给iptables链 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 #关闭ipv6协议 net.ipv6.conf.all.disable_ipv6=1 net.ipv4.ip_forward=1 EOF
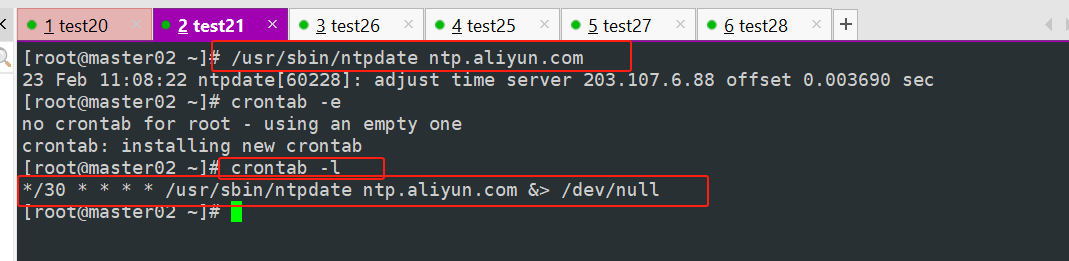

#时间同步,并且做计划任务


#将这几个配置文件都导给master02








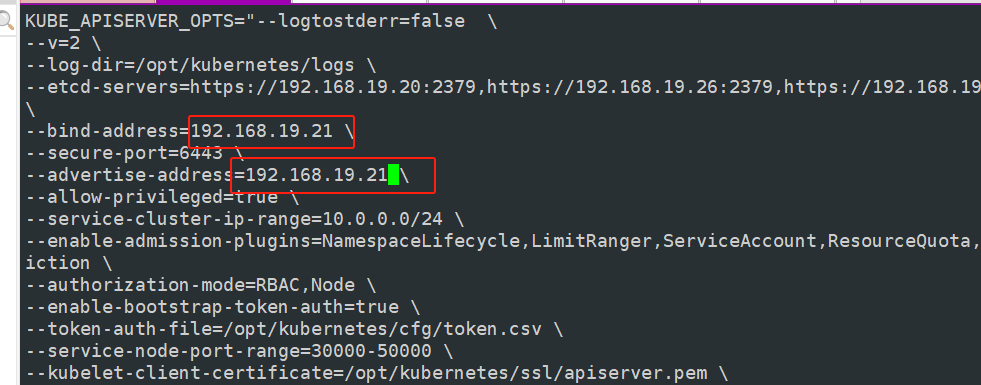

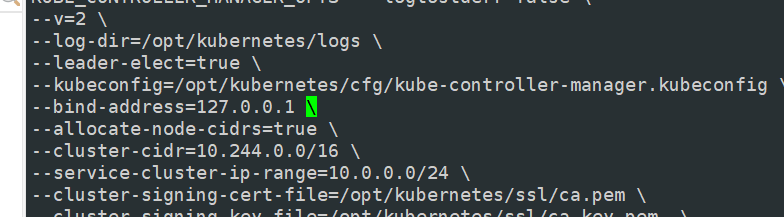


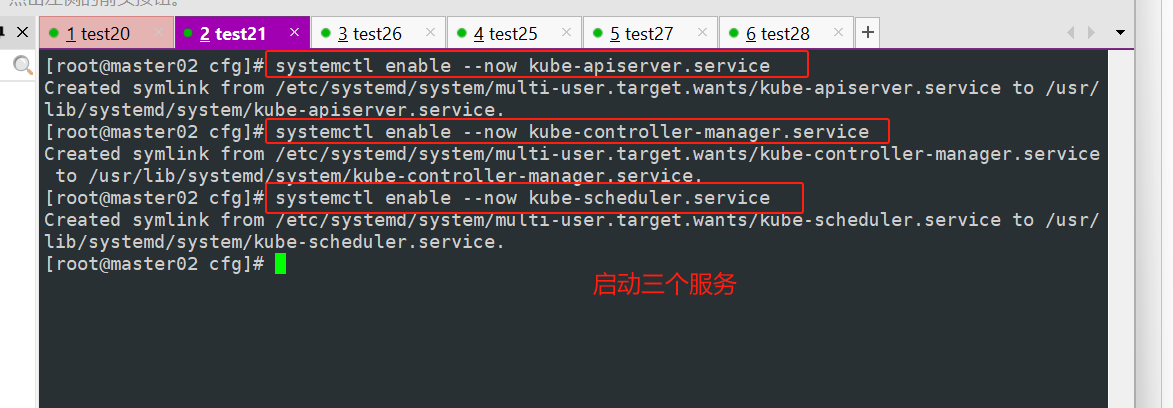
systemctl enable --now kube-apiserver.service systemctl enable --now kube-controller-manager.service systemctl enable --now kube-scheduler.service



部署负载均衡


初始换
nginx



#配置nginx的官方在线yum源,配置本地nginx的yum源
#安装nginx,用nginx来做负载均衡
cat > /etc/yum.repos.d/nginx.repo << 'EOF' [nginx] name=nginx repo baseurl=http://nginx.org/packages/centos/7/$basearch/ gpgcheck=0 EOF

#开启nginx

#保证要有stream模块


#做四层代理转发
stream { 14 upstream k8s-apiserver { 15 server 192.168.19.20:6443; 16 server 192.168.19.21:6443; 17 } 18 server { 19 listen 6443; 20 proxy_pass k8s-apiserver; 21 } 22 }

#检查语法

#重启nginx

Keepalived



#编写脚本,如nginx关闭,则会自动关闭keepalived
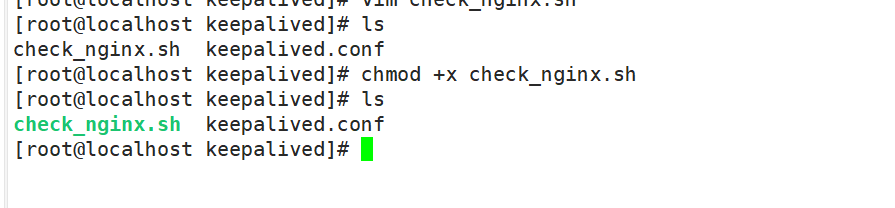
#给脚本执行权限

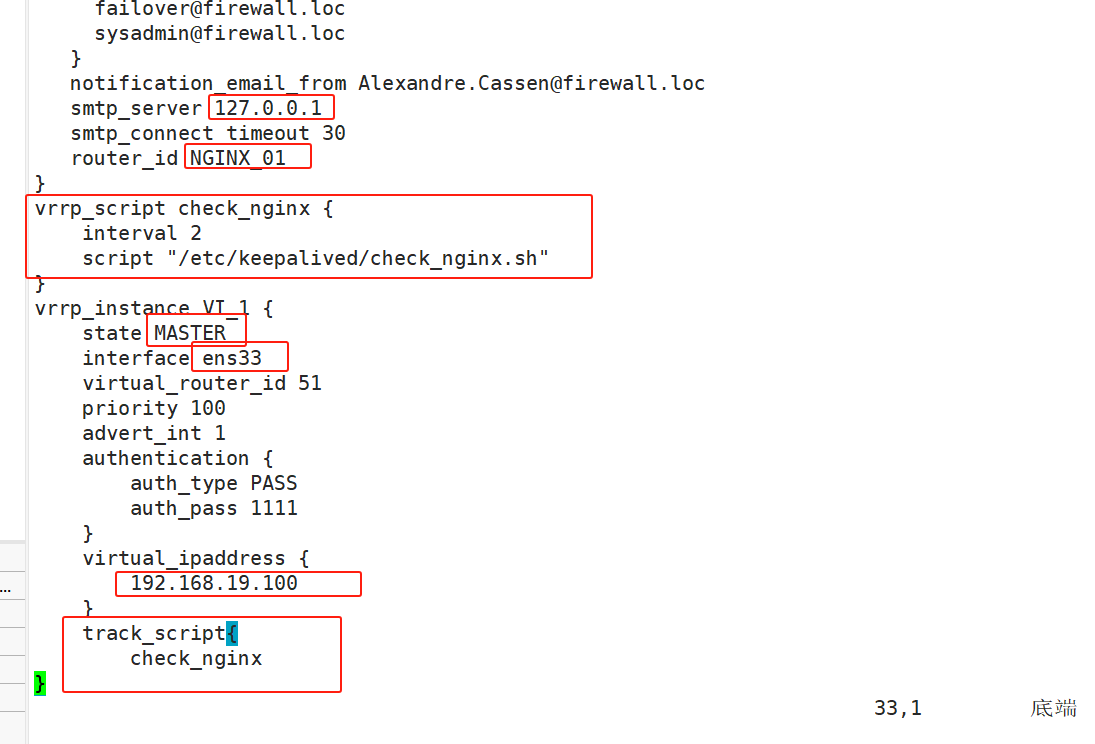
notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_01 } vrrp_script check_nginx { interval 2 script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.19.100 } track_script { check_nginx }


#开启keepalived

#虚拟IP以生成

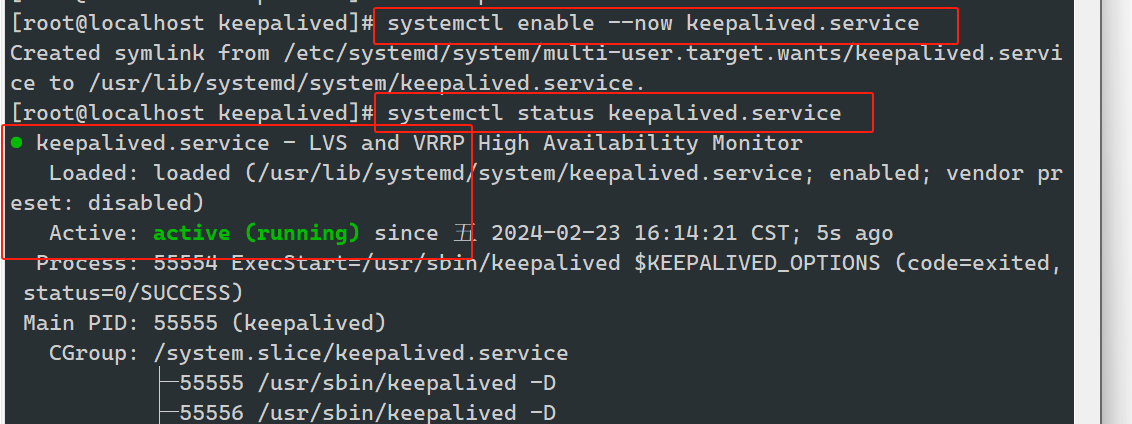
#启动keepalived
测试故障转移

#关闭nginx keepalived也会关闭

#vip飘走了
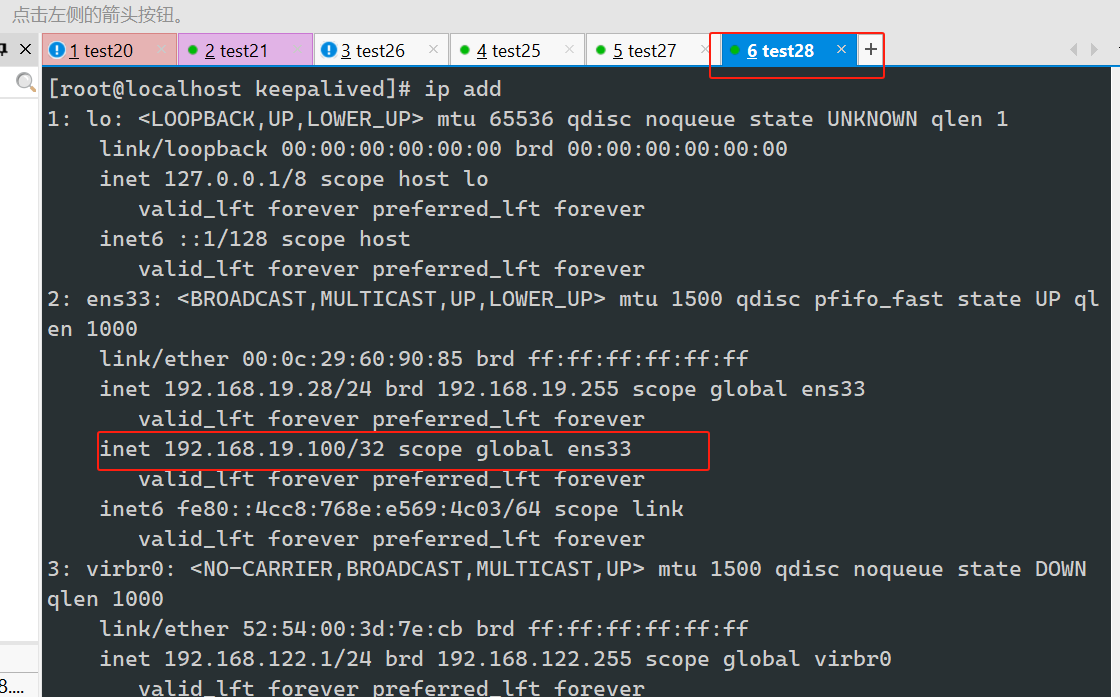
#VIP漂移到备服务器上

#再启动nginx和keepalived,有先后顺序明显启动nginx再启动keepalived
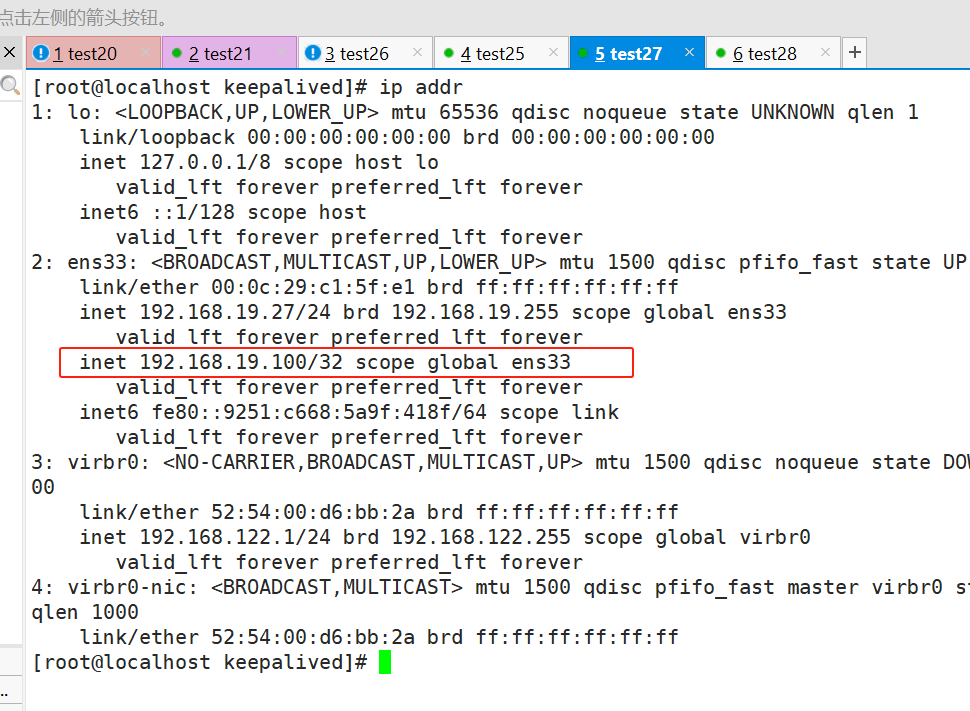
#VIP又飘回来了

#修改所有node节点以.kubeconfig结尾的配置文件,将IP修改为VIP的IP




#重启这两服务



#IP改为虚拟VIP

#查看健康状态







部署 Dashboard
仪表板是基于Web的Kubernetes用户界面。您可以使用仪表板将容器化应用程序部署到Kubernetes集群,对容器化应用程序进行故障排除,并管理集群本身及其伴随资源。您可以使用仪表板来概述群集上运行的应用程序,以及创建或修改单个Kubernetes资源(例如部署,作业,守护进程等)。例如,您可以使用部署向导扩展部署,启动滚动更新,重新启动Pod或部署新应用程序。仪表板还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。

kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: ports: - port: 443 targetPort: 8443 nodePort: 30001 #添加 type: NodePort #添加 selector: k8s-app: kubernetes-dashboard


#创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkNTNmppMGNaX2RGN3BLQlFlUUNkUmFEX1FKV2VIZHc1SkVNN2FCNnlJUzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tdG5iZnQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiMTc3ZmUyZjctNjIxNS00ZTNiLWE5MjItZWQxNzlmZmIxODFkIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.LZZ2_1gOIJHTHQzpEwr2cIehBieoQ3yxtZtfgX9n9e7v2glsY_aaEq4gMK9bJjUQ08FSek7hpC2-zxFmhqT__Ybqd8ls2V80RErkO8qbiqixQn6Qq9-JfubuIaqB9VmPNmL9DWx0eXJX8mj5uMM_vS3DeHY29UvEwryq5xe-DVyZJLpBBe_aONNXJqNzohPhTqilm37zTjECSeznHV_RkGev2LoTmhdFGfLRe6K1xdHgt-aHCRsh3CiRusGb8KeoyxyNFLBC2_Zd2NuwtZN-oWryfvO2ZAZrZsxRkhWJ03ajSimZYaFZIgJibO_J3DdvGRKB54gM96I1ASXAj2tmBw


#访问node节点的IP加上30001端口

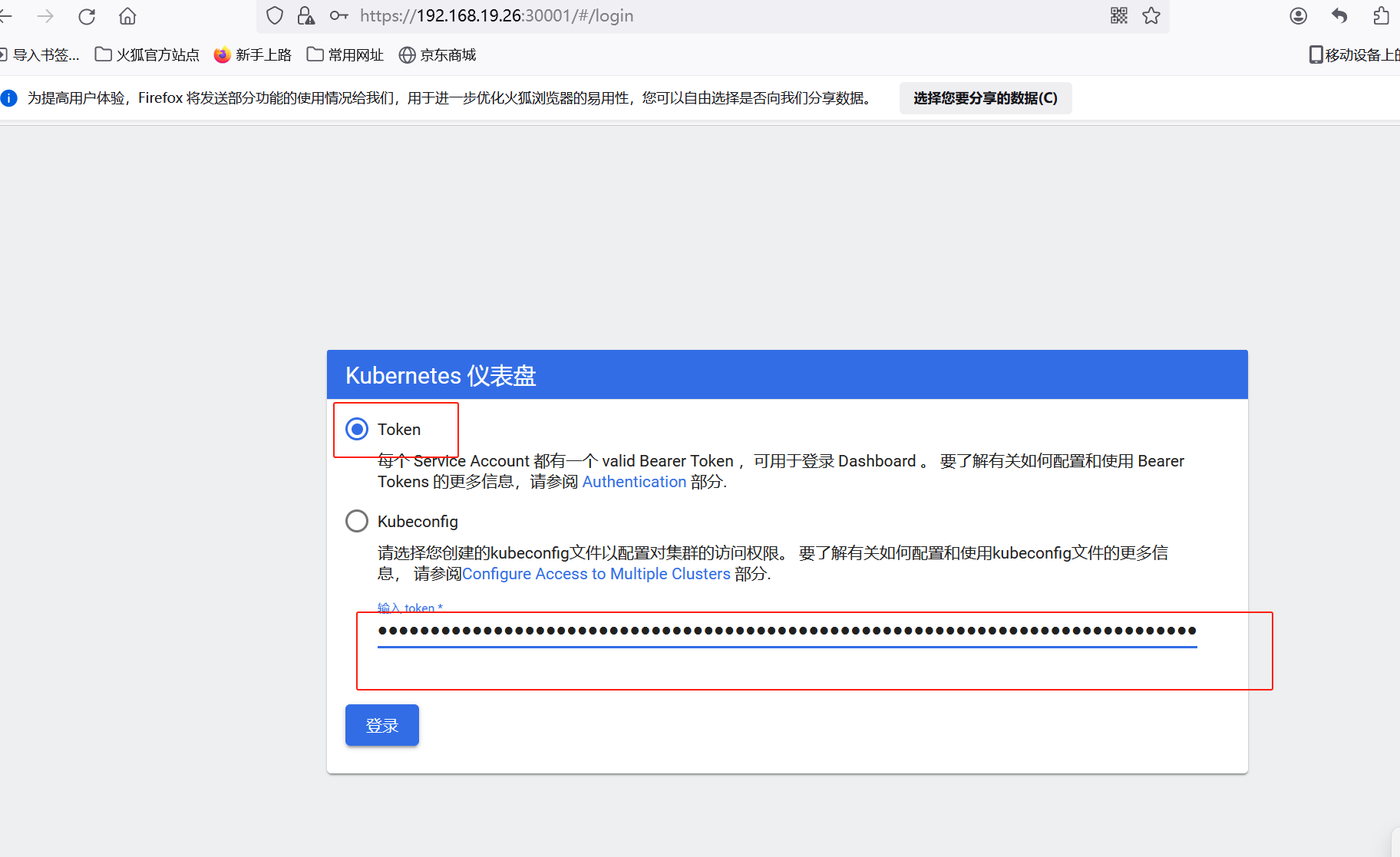
eyJhbGciOiJSUzI1NiIsImtpZCI6IkNTNmppMGNaX2RGN3BLQlFlUUNkUmFEX1FKV2VIZHc1SkVNN2FCNnlJUzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tdG5iZnQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiMTc3ZmUyZjctNjIxNS00ZTNiLWE5MjItZWQxNzlmZmIxODFkIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.LZZ2_1gOIJHTHQzpEwr2cIehBieoQ3yxtZtfgX9n9e7v2glsY_aaEq4gMK9bJjUQ08FSek7hpC2-zxFmhqT__Ybqd8ls2V80RErkO8qbiqixQn6Qq9-JfubuIaqB9VmPNmL9DWx0eXJX8mj5uMM_vS3DeHY29UvEwryq5xe-DVyZJLpBBe_aONNXJqNzohPhTqilm37zTjECSeznHV_RkGev2LoTmhdFGfLRe6K1xdHgt-aHCRsh3CiRusGb8KeoyxyNFLBC2_Zd2NuwtZN-oWryfvO2ZAZrZsxRkhWJ03ajSimZYaFZIgJibO_J3DdvGRKB54gM96I1ASXAj2tmBw


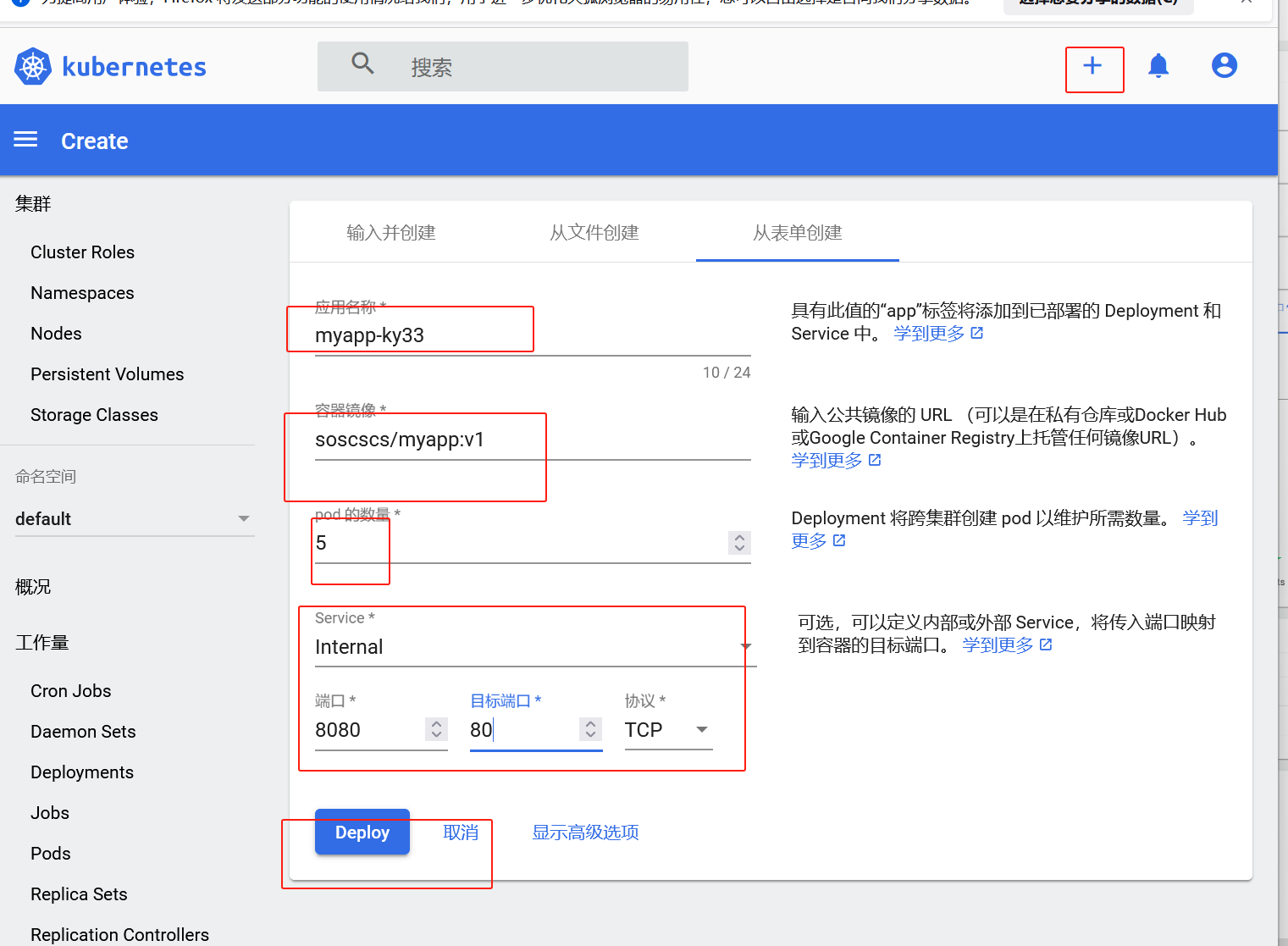
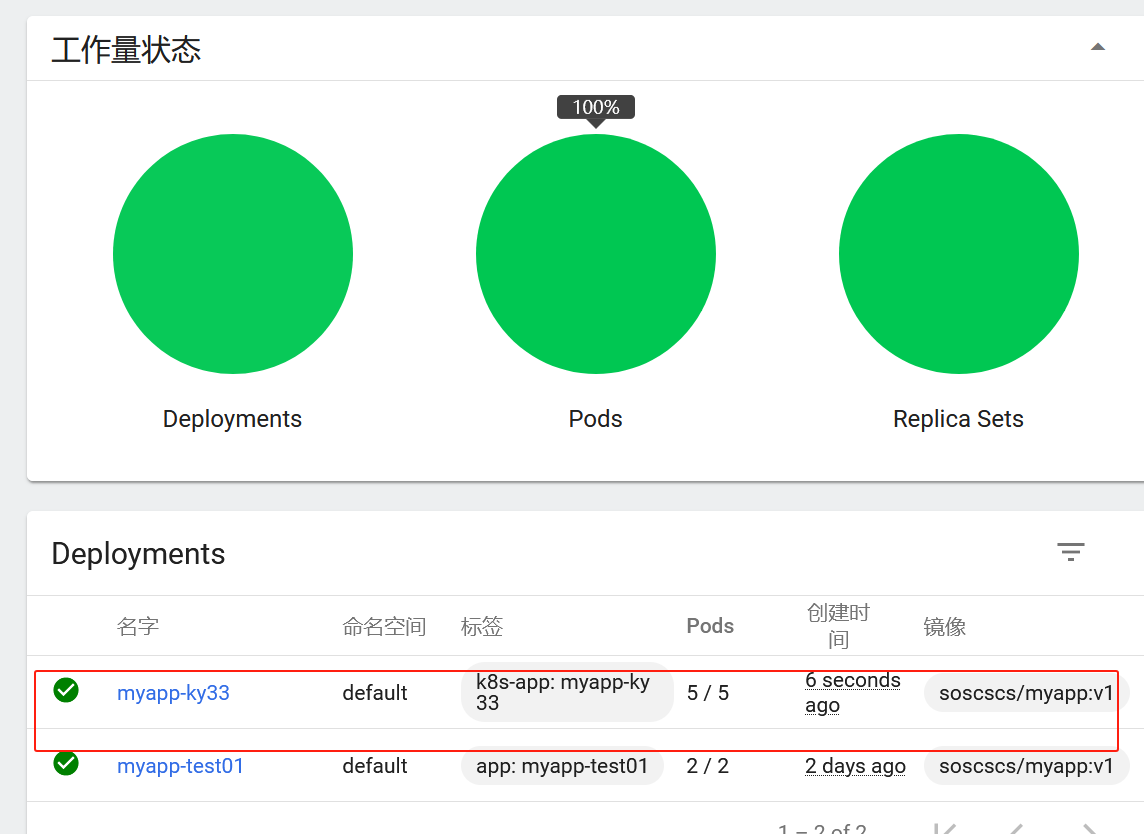
#如需创建





#删除
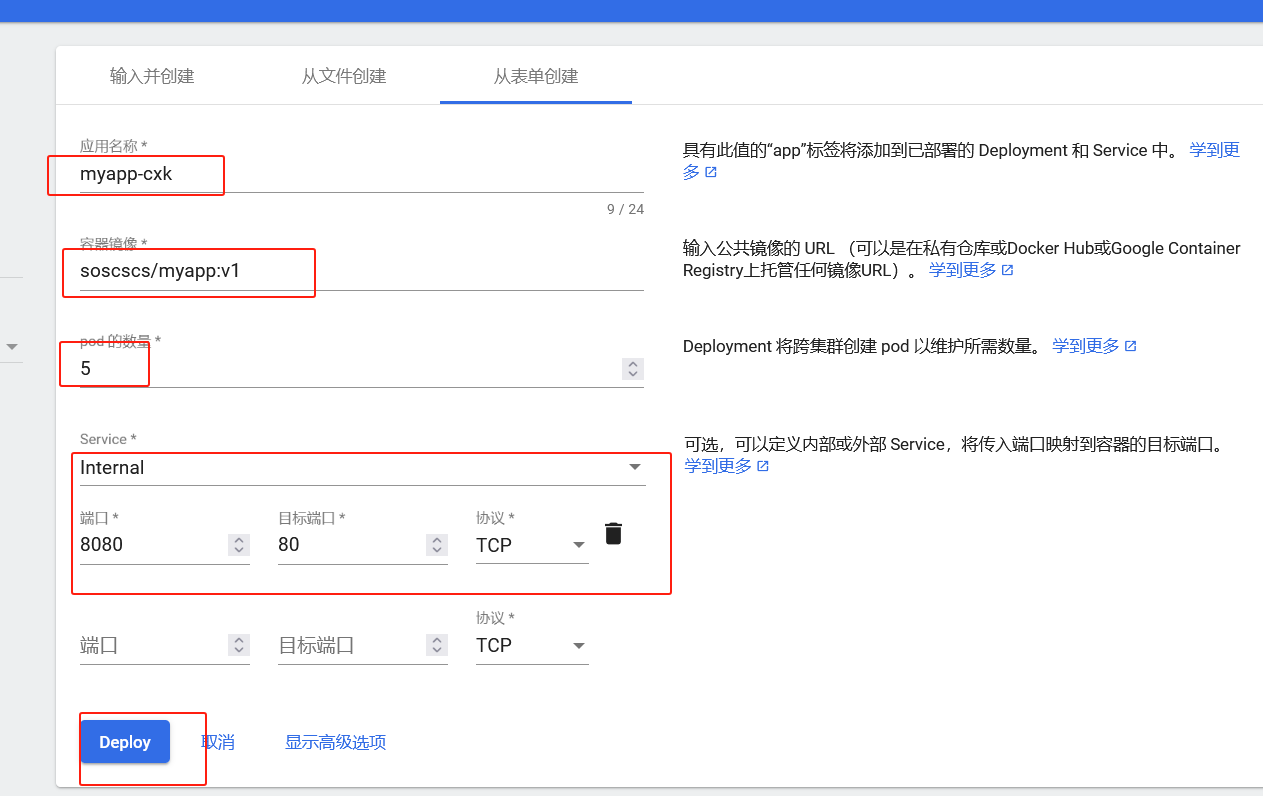
#在创建个应用名称为cxk的


总结
K8S有 matser和worker node 两类节点 master节点(负责K8S集群 的管理和资源调度等运维工作) 有 apiserver、controller-manager、scheduler、etcd组件 apiserver: 是所有服务请求的统一访问入口 controller-manager:控制器管理器,负责管理K8S各种资源对象的控制器,并通过apiserver监控整个K8S集群的资源状态,并确保资源始终处于预期的工作状态 scheduler: 资源调度器,负责pod资源的调度,通过调度算法(预选/优选策略)为要部署的Pod选择最合适的node节点 etcd: K8S集群的数据库,是一种键值队存储结构的分布式数据库,负责存储K8S集群所有的重要信息,仅apiserver拥有访问和读写权限 woker node节点 (负责运行工作负载,及容器应用),组件有(kubelet、kube-proxy、容器引擎(docker、containerd等)) kubelet: 接受apiserver发来的请求,创建管理Pod和容器,跟容器引擎交互实现对容器的生命周期的管理;收集nodo节点的资源信息和Pod的运行状态发送给apiserver kube-proxy: 作为service资源的载体,实现对Pod的网络代理,负责维护Pod集群的网络规则和四层代理工作 容器引擎: 运行管理容器 #K8S资源对象 Pod: 是K8S能够创建和管理的最小单位。 一个Pod里可以包含一个或多个应用容器,同一个Pod里的容器之间共享网络,存储等资源 Pod控制器: deployment: 部署无状态应用(没有实时数据需要存储);同时也要负责管理replicaset(维持Pod副本数始终符合预期状态)和Pod(容器化的应用程序) Statefulset: 部署有状态应用(有实时数据需要存储); Daemonset: 在所有node节点上都部署同一种的Pod Job; 一次性的部署短期任务的Pod(执行完任务后会自动退出的容器应用) Cronjob: 周期性的部署短期任务的Pod(执行完任务后会自动退出的容器应用) Label: 标签,将一个或多个键值对标识关联到某个资源对象,用于资源对象的分组查询和筛选 label selector: 标签选择器,用于查询和筛选拥有相关标签的资源对象 annotation: 注释,用做于资源对象的注释信息或在一些特殊的资源对象里用做于设置额外的功能特性 Service: 在K8S集群内部为通过标签选择器相关联的一组Pod提供一个统一的访问入口(clusterIP),只支持四层代理转发 service通过标签选择器关联Pod的标签,从而自动发现相关Pod的端点(PodIP:Pod端口) Ingress: 作为K8S集群外部的访问入口,可定义ingress规则,根据用户请求域名或url请求路径转发给指定的service,支持七层代理转发 ingress通过配置规则将不同的域名或url路径关联不同的service资源 name: 资源名称 namespace: 命名空间,用于隔离资源名称的。在同一个命名空间种,同类型的资源对象的名称是唯一 的 #K8S配置信息 apiversion: 指定资源对象在K8S种使用的api接口版本 kind: 指定资源对象的类型 metadata: 指定资源对象的元数据信息,比如name指定资源名称、namespace指定命名空间、annotation指定注释、label指定标签 spec: 指定资源对象的资源配置清单(配置属性),比如副本数、镜像、网络模式、存储卷、label selector标签选择器 status: 自动生成资源对象在当前的运行状态信息 #K8S二进制搭建 1)部署EDCT 使用cfssl工具签发证书和私钥文件 解压etcd软件包,获取二进制文件 etcd、etcdctl 准备etcd集群配置文件 启动etcd进程服务,将所有节点加入节点到etcd集群中 -- etcd的操作 -- #查看etcd集群健康状态 ETCDCTL_API=3 /opt/etcd/bin/etcdctl -endpoints="nttps://IP1:2379,https://IP2:2379,https://IP3:2379"--cacert=cai证书 -cert=客广端证书 --key=客户端私钥 -wtable endpoint health #查看etcd集群状态信息 BTICDCTL API=3 /opt/etcd/bin/etcdctl -endpoints="htps:/iP1:2379,htps:/IP2:2379,htps://Ip3:2379"--cacert=CA证书 -cert=客户端证书--key=客户端私钥 -wtable endpoint status #查看etcd集群成员列表 ETCDCTL API=3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379,https://IP2:2379,https://IP3:2379" --cacert=cai证书 -cert=客户端证书 --key=客户端私钥 -wtable member list #向etcd插入键值 ETCDCTL API3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379"--cacert=CA证书 --cert=客户端证书 --key=客户端私钥 put <KEY> '<VALUE>'' #查看键的值 TCDCTL API3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379"--cacert=CA证书 --cert=客户端证书 --key=客户端私钥 get <KEY> #删除键 TCDCTL API3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379"--cacert=CA证书 --cert=客户端证书 --key=客户端私钥 del <KEY> #备份etcd数据库 TCDCTL API3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379"--cacert=CA证书 --cert=客户端证书 --key=客户端私钥 snapshot save 备份文件路径 #恢复etcd数据库 TCDCTL API3 /opt/etcd/bin/etcdctl --endpoints="https://IP1:2379"--cacert=CA证书 --cert=客户端证书 --key=客户端私钥 snapshot restore 备份文件路径 2)部署master组件 使用cffsl工具签发证书和私钥文件 下载K8S软件包,获取相关的二进制文件kube-apiserver、kube-controller-manager、kube-scheduler 准备apiserver启动时要调用的bootstrap-token认证文件(token.csv) 准备kube-apiserver、kube-controller-manager、kube-scheduler 的进程服务启动参数配置文件 准备kube-controller-manager、kube-scheduler kubectl 的 kubeconfig集群引导配置文件(用于连接和验证 kube-apiserver) 依次启动 kube-apiserver、kube-controller-manager、kube-scheduler 的进程服务 执行kubectl get cs 命令查看master组件健康状态 3)部署node组件 获取二进制文件 kubelet kube-proxy 准备kubelet kube-proxy 使用的 kubeconfig集群引导配置文件 bootstrap.kubeconfig (kubelet首次访问apiserver使用的认证文件) kube-proxy.kubeconfig 准备kubelet kube-proxy 的进程服务启动参数配置文件 启动kubelet 进程服务,向apiserver 发起CSR请求自动签发证书,master 通过 CSR 请求后 kubelet 方可获取到证书 加载ipvs模块 启动kube-proxy 进程服务 执行kubectl get nodes 命令 查看node节点的状态 4)部署多master高可用 复制master组件的相关证书、私钥文件、启动参数配置文件、kubeconfig集群配置文件、二进制文件和etcd的证书以及私钥文件 修改apiserver kube-controller-manager、kube-scheduler 启动参数配置文件 里的监控地址和通过地址,再依次重启服务进程 部署nginx/haproxy 负载均衡器和keepalived 高可用 修改kubelete kube-proxy kubectl 的kubeconfig集群引导配置文件里的server参数都指向keepalived的viIP地址,再重启kubelete kube-proxy 服务进程 修改其他master节点上的kube-controller-manager、kube-scheduler 的kubeconfig集群引导配置文件里的server参数都指向 各自本机的 apiserver 地址,再重启服务进程 #K8S的三种接口 CRI 容器运行时接口 docker containerd podman cri-o CNI 容器网络接口 flannel calico cilium CSI 容器存储接口 nfs ceph qfs oss s3 minio #K8S的三种网络 节点网络 nodeIP (物理网卡的IP实现节点间的通信) Pod网络 podIP Pod与Pod之间可通过Pod的IP相互通信 service网络 clusterIP 在K8S集群内可通过service资源的clusterIP 集群的网络代理(负载均衡)转发 #Vlan和Vxlan区别 1)vxlan支持更多的二层网络,最多可支持2^24个; VLAN最多支持2^12个(4096-2) 2)作用不同:VLAN主要用于在交换机上逻辑划分广播域,还可以配合STP协议生成树协议阻塞路径端口,避免产生环路和广播风暴 VXLAN 可将数据帧封装成UDP报文再通过网路层传输给其他网络,实现虚拟大二层网络的通信 3)VXLAN防止物理交换机Mac表耗尽,VLAN需要在交换机的MAC表中记录MAC物理地址,VXLAN采用隧道机制,MAC物理地址不需要记录在交换机 #flannel 的三种模式 UDP 出现最早的模式,但是性能最差,基于flanneld应用程序实现数据包的封装、解封装 VXLAN flannel的默认模式,也是推荐使用的模式,性能比UDP模式更好,基于内核实现数据帧的封装和解封装,而且配置简单使用方便 HOST-GW 性能最好的模式,但是配置复杂,且不能跨网段。 #flannel的UDP模式工作原理 1)原始数据报文从源主机的Pod容器发出到CNI0网桥接口,再由CNI0转发到flannel0虚拟接口 2)flanneld服务进程会监听flannel0接口接受到的数据,flanneld进程会将㡳数据包封装到UDP报文里 3)flanneld进程会根据在EDCT中维护的路由表查到目标Pod所在的nodeIP,并在UDP报文外封装nodeIP头部、MAC头部,再通过物理网卡发送到目标node节点 4)UDP报文会通过82 85号 端口送到目标node节点flanneld进程进行解封装,再根据本地路由器通过flannel0接口发送到CNI0网桥,再由CNI0发送到目标Pod容器 #flannel的VLAN模式工作原理 1)原始数据帧从源主机的Pod容器发出到CNI0网桥接口,再由CNI0转发到flannel.1虚拟接口 2)flannel.1接口接收到数据帧后田间VXLAN头部,并在内核将原始数据帧封装到UDP报文里 3)根据etcd中维护的路由表查到目标Pod所在的nodeIP,并在UDP报文外封装nodeIP头部、mac头部,再通过物理网卡发送到目标node节点 4)UDP报文通过8472端口送达到目标node节点的flannel.1接口并在内核进行解封装,再根据本地路由规则发送到CNI0网桥,再由CNI0发送到目标Pod容器 #calico的IPIP工作原理 1)原始数据包从源主机的Pod容器发出到tunl0接口,再被内核的IPIP 驱动封装到node节点网络的IP报文里 2)根据felix维护的路由规则,通过物理网卡发送到目标node节点 3)IP数据包到达目标node节点后tunl0,再通过内核的IPIP驱动解封装得到原始数据包,再根据本地路由规则通过 veth pair 设备送达到目标Pod容器 #calico的BGP模式的工作原理 (本质就是通过路由规则来实现Pod之间的通信) 每个Pod容器都有一个veth pair 设备,一端接入容器,另一端接入宿主机网络空间,并设置一条路由规则 这些路由规则都是由felix 维护配置的,由 BIRD 组件基于 BGP 动态路由协议分发路由信息 如何进行数据包转发? 1)原始数据包从源主机的Pod容器发出,通过 veth pair 设备送达到宿主机网络空间 2)根据Felix维护的路由规则,通过物理网卡发送到目标node节点 3)目标node节点接受到数据包后,根据本地路由规则通过 veth pair 设备送达到目标Pod容器 #flannel 与 calico区别 flannel: UDP VXLAN HOST-GW 默认网段: 10.244.0.0/16 通常会采用VXLAN模式,用的是叠加网络,IP隧道方式传输数据,对性能有一定的影响 flannel 产品成熟,依赖性较少,易于安装,功能简单,配置方便,利于管理,但是不具备复杂的网络策略规则配置能力 calico: IPIP BGP 混合模式(CrossSubnet) 默认网段: 192.168.0.0/16 使用IPIP模式可以实现跨子网传输,但是传输过程中需要额外的封包和解包过程,对性能有一定的影响 使用BGP模式 会把node节点看作成路由器,通过Felix、BIRD组件来维护和分发路由规则,可实现通过BGP路由协议实现路由转发,传输过程中不需要额外的封包和解包过程,因此性能较好,但是只能在同一个网段里使用,无法跨子网传输 calico 不使用CNI0网桥,而通过路由规则把数据包直接发送到目标主机,所以性能较高;而且还具有更丰富的网络策略配置管理能力,功能更全面,但是维护起来较为复杂 # 所以对于较小规模且网络要求简单K8S集群,可以采用flannel作为CNI网络插件,对于集群规模较大且要求更多的网络策略配置时,可以考虑采用性能更好,功能更全面的calico或者cilium #CoreDNS CoreDNS 是K8S默认的内部DNS功能实现,为K8S集群内的Pod提供DNS解析服务 根据service 的资源名称 解析出对应的clusterIP 根据statefulset 控制器 创建的Pod资源名称 解析出对应的PodIP

 浙公网安备 33010602011771号
浙公网安备 33010602011771号