
|NO.Z.00085|——————————|BigDataEnd|——|Hadoop&Spark.V01|——|Spark.v01|Spark 原理 源码|作业执行原理&任务调度概述|
一、作业执行原理
### --- 任务调度概述
~~~ 再次简要回顾 Spark 中的几个重要概念:
~~~ Job 是以 Action 方法为界,遇到一个 Action 方法则触发一个 Job
~~~ Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle)为界,遇到 Shuffle 做一次划分。### --- Stage有两个具体子类:
~~~ ShuffleMapStage,是其他 Stage 的输入
~~~ ShuffleMapStage 内部的转换操作(map、filter等)会组成pipeline,连在一起计算
~~~ 产生 map 输出文件(Shuffle 过程中输出的文件)
~~~ ResultStage。一个job中只有一个ResultStage,最后一个 Stage 即为 ResultStage
~~~ Task 是 Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个 task### --- SparkContext中的三大组件:
~~~ DAGScheduler(class) 负责 Stage 的调度
~~~ TaskScheduler(trait,仅有一个实现 TaskSchedulerImpl) 负责 Task 的调度
~~~ SchedulerBackend 有多种实现,分别对应不同的资源管理器~~~ # sparkcontext三大组件:
SchedulerBackend(org.apache.spark.scheduler)
CoarseGrainedSchedulerBackend(org.apache.spark.scheduler.cluster)
StandaloneSchedulerBackend(org.apache.spark.scheduler.cluster)
LocalSchedulerBackend(org.apache.spark.scheduler.local)~~~ Spark 的任务调度可分为:Stage 级调度(高层调度)、Task级调度(底层调度)。
~~~ 总体调度流程如下图所示: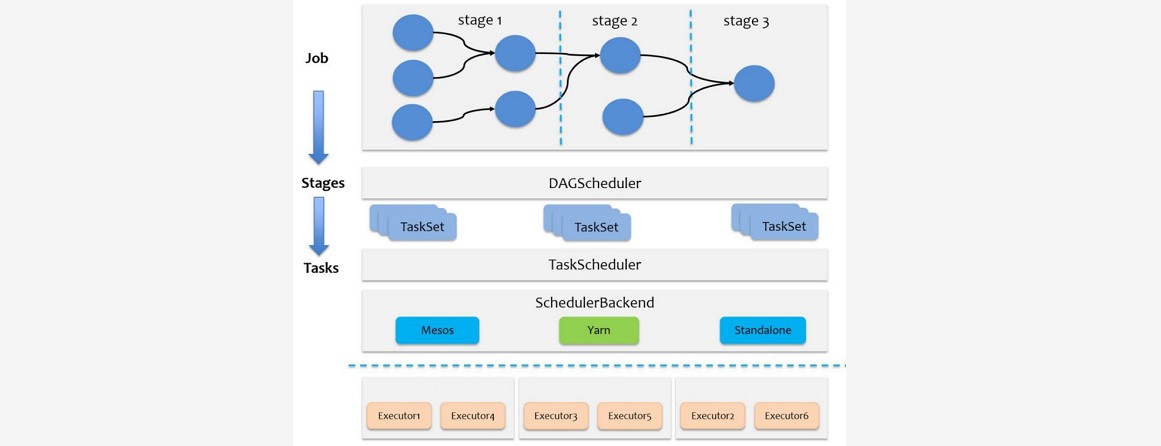
Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号