
|NO.Z.00083|——————————|BigDataEnd|——|Hadoop&Spark.V09|——|Spark.v09|Spark 原理 源码|Spark Context&三大组件启动流程|
一、三大组件启动流程
### --- 三大组件启动流程
~~~ DAGScheduler(高层调度器,class):
~~~ 负责将 DAG 拆分成不同Stage的具有依赖关系(包含RDD的依赖关系)的多批任务,
~~~ 然后提交给TaskScheduler进行具体处理
~~~ TaskScheduler(底层调度器,trait,只有一种实现TaskSchedulerImpl):
~~~ 负责实际每个具体Task的物理调度执行
~~~ SchedulerBackend(trait):
~~~ 有多种实现,分别对应不同的资源管理器
~~~ 在Standalone模式下,其实现为:StandaloneSchedulerBackend二、三大组件启动流程结构
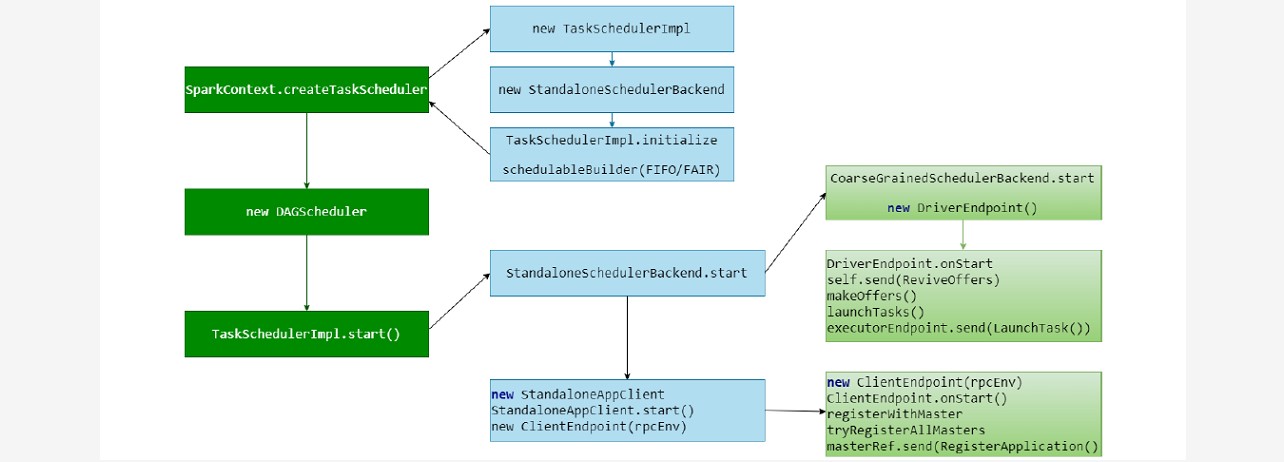
三、完整流程
### --- 完整流程
~~~ # 源码提取流程:SparkContext.scala
~~~ # 492行~501行
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()### --- 创建SchedulerBackend、TaskScheduler
~~~ 根据传入的不同参数,启动不同的 SchedulerBackend, TaskScheduler(都是trait)
~~~ TaskScheduler的实现只有一个,但是不同模式传入的参数不同
~~~ SchedulerBackend的实现有多个
~~~ 在Standalone模式下,创建的分别是:StandaloneSchedulerBackend、TaskSchedulerImpl
~~~ 创建TaskSchedulerImpl后,构建了任务调度池 FIFOSchedulableBuilder / FairSchedulableBuilder~~~ # 源码提取流程:SparkContext.scala
~~~ # 2716行~2759行
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures
// local[N, M] means exactly N threads with M failures
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)### --- 创建 DAGScheduler
### --- 执行 TaskScheduler.start
~~~ TaskSchedulerImpl.start~~~ # 源码提取说明:TaskSchedulerImpl.scala
~~~ # 182行~193行
override def start() {
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}### --- CoarseGrainedSchedulerBackend.start
~~~ StandaloneSchedulerBackend.start => CoarseGrainedSchedulerBackend.start
~~~ CoarseGrainedSchedulerBackend.start 启动中最重要的事情是:创建并注册 driverEndpoint
~~~ 在DriverEndpoint.onStart 方法中创建定时调度任务,
~~~ 定时发送 ReviveOffers 消息;最终调用 makeOffers()方法处理该消息
~~~ DriverEndpoint 代表Driver管理App的计算资源(即Executor)
~~~ makeOffers方法,将集群的资源以Offer的方式发给上层的TaskSchedulerImpl~~~ # 源码提取说明:CoarseGrainedSchedulerBackend.scala
~~~ # 383行~398行
override def start() {
val properties = new ArrayBuffer[(String, String)]
for ((key, value) <- scheduler.sc.conf.getAll) {
if (key.startsWith("spark.")) {
properties += ((key, value))
}
}
// TODO (prashant) send conf instead of properties
driverEndpoint = createDriverEndpointRef(properties)
}
protected def createDriverEndpointRef(
properties: ArrayBuffer[(String, String)]): RpcEndpointRef = {
rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint(properties))
}### --- DriverEndpoint 在 CoarseGrainedSchedulerBackend 中定义:
~~~ # 源码提取说明:CoarseGrainedSchedulerBackend.scala
~~~ # 101行~118行
class DriverEndpoint(override val rpcEnv: RpcEnv, sparkProperties: Seq[(String, String)])
extends ThreadSafeRpcEndpoint with Logging {
// Executors that have been lost, but for which we don't yet know the real exit reason.
protected val executorsPendingLossReason = new HashSet[String]
protected val addressToExecutorId = new HashMap[RpcAddress, String]
override def onStart() {
// Periodically revive offers to allow delay scheduling to work
val reviveIntervalMs = conf.getTimeAsMs("spark.scheduler.revive.interval", "1s")
reviveThread.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
Option(self).foreach(_.send(ReviveOffers))
}
}, 0, reviveIntervalMs, TimeUnit.MILLISECONDS)
}### --- 在 onStart 方法中创建定时调度任务,定时发送 ReviveOffers 消息;
~~~ 最终调用 makeOffers() 方法处理该消息;
~~~ makeOffers方法,将集群的资源以Offer的方式发给上层的TaskSchedulerImpl。
~~~ TaskSchedulerImpl调用scheduler.resourceOffers获得要被执行的Seq[TaskDescription],
~~~ 然后将得到的Seq[TaskDescription]交给CoarseGrainedSchedulerBackend分发到各个executor上执行~~~ # 源码提取说明:CoarseGrainedSchedulerBackend.scala
~~~ # 263行~281行
// Make fake resource offers on just one executor
private def makeOffers(executorId: String) {
// Make sure no executor is killed while some task is launching on it
val taskDescs = withLock {
// Filter out executors under killing
if (executorIsAlive(executorId)) {
val executorData = executorDataMap(executorId)
val workOffers = IndexedSeq(
new WorkerOffer(executorId, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort)))
scheduler.resourceOffers(workOffers)
} else {
Seq.empty
}
}
if (!taskDescs.isEmpty) {
launchTasks(taskDescs)
}
}~~~ # 源码提取说明:CoarseGrainedSchedulerBackend.scala
~~~ # 289行~312行
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))### --- 创建 StandaloneAppClient
~~~ 执行start(),在其中创建 ClientEndpoint
~~~ ClientEndpoint执行onstart方法
~~~ ClientEndpoint 代表应用程序向 Master 注册 【RegisterApplication】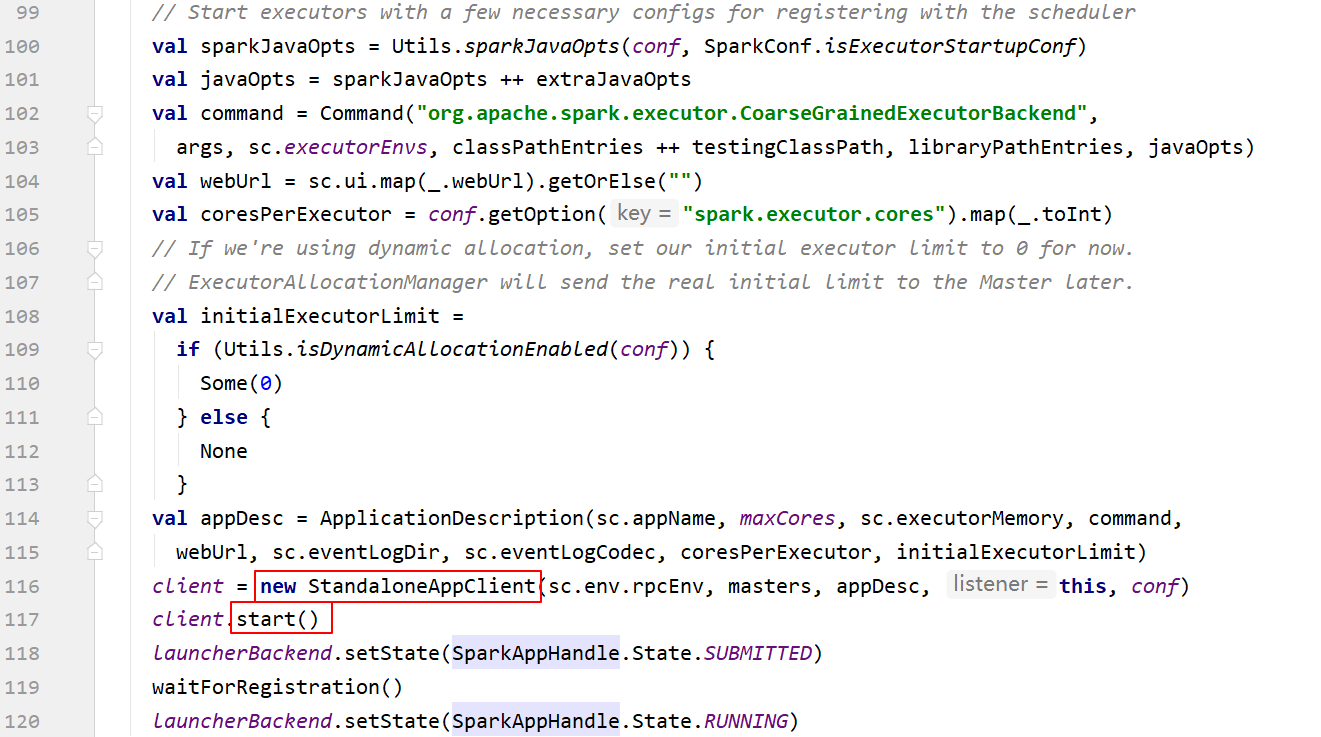
~~~ # 源码提取说明:
~~~ # 274行~277行
def start() {
// Just launch an rpcEndpoint; it will call back into the listener.
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}~~~ # 源码提取说明:
~~~ # 44行~66行
private[spark] class StandaloneAppClient(
rpcEnv: RpcEnv,
masterUrls: Array[String],
appDescription: ApplicationDescription,
listener: StandaloneAppClientListener,
conf: SparkConf)
extends Logging {
private val masterRpcAddresses = masterUrls.map(RpcAddress.fromSparkURL(_))
private val REGISTRATION_TIMEOUT_SECONDS = 20
private val REGISTRATION_RETRIES = 3
private val endpoint = new AtomicReference[RpcEndpointRef]
private val appId = new AtomicReference[String]
private val registered = new AtomicBoolean(false)
private class ClientEndpoint(override val rpcEnv: RpcEnv) extends ThreadSafeRpcEndpoint
with Logging {
private var master: Option[RpcEndpointRef] = None
// To avoid calling listener.disconnected() multiple times
private var alreadyDisconnected = false~~~ # 源码提取说明:
~~~ # 84行~93行
override def onStart(): Unit = {
try {
registerWithMaster(1)
} catch {
case e: Exception =>
logWarning("Failed to connect to master", e)
markDisconnected()
stop()
}
}~~~ # 源码提取说明:
~~~ # 123行~138行
private def registerWithMaster(nthRetry: Int) {
registerMasterFutures.set(tryRegisterAllMasters())
registrationRetryTimer.set(registrationRetryThread.schedule(new Runnable {
override def run(): Unit = {
if (registered.get) {
registerMasterFutures.get.foreach(_.cancel(true))
registerMasterThreadPool.shutdownNow()
} else if (nthRetry >= REGISTRATION_RETRIES) {
markDead("All masters are unresponsive! Giving up.")
} else {
registerMasterFutures.get.foreach(_.cancel(true))
registerWithMaster(nthRetry + 1)
}
}
}, REGISTRATION_TIMEOUT_SECONDS, TimeUnit.SECONDS))
}~~~ # 源码提取说明:
~~~ # 98行~114行
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {
if (registered.get) {
return
}
logInfo("Connecting to master " + masterAddress.toSparkURL + "...")
val masterRef = rpcEnv.setupEndpointRef(masterAddress, Master.ENDPOINT_NAME)
masterRef.send(RegisterApplication(appDescription, self))
} catch {
case ie: InterruptedException => // Cancelled
case NonFatal(e) => logWarning(s"Failed to connect to master $masterAddress", e)
}
})
}
}### --- Master处理注册信息
~~~ # 源码提取说明:Master.scala
~~~ # 267行~279行
case RegisterApplication(description, driver) =>
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}~~~ # 源码提取说明:Master.scala
~~~ # 155号~165行
override def receive: PartialFunction[Any, Unit] = {
case RegisteredApplication(appId_, masterRef) =>
// FIXME How to handle the following cases?
// 1. A master receives multiple registrations and sends back multiple
// RegisteredApplications due to an unstable network.
// 2. Receive multiple RegisteredApplication from different masters because the master is
// changing.
appId.set(appId_)
registered.set(true)
master = Some(masterRef)
listener.connected(appId.get)Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号