
|NO.Z.00038|——————————|BigDataEnd|——|Hadoop&Redis.V06|——|Redis.v06|高可用|集群介绍|
一、集群与分区
### --- 集群与分区
~~~ 分区是将数据分布在多个Redis实例(Redis主机)上,以至于每个实例只包含一部分数据。### --- 分区的意义
~~~ # 性能的提升
~~~ 单机Redis的网络I/O能力和计算资源是有限的,将请求分散到多台机器,
~~~ 充分利用多台机器的计算能力可网络带宽,有助于提高Redis总体的服务能力。
~~~ # 存储能力的横向扩展
~~~ 即使Redis的服务能力能够满足应用需求,但是随着存储数据的增加,
~~~ 单台机器受限于机器本身的存储容量,将数据分散到多台机器上存储使得Redis服务可以横向扩展。二、分区的方式
### --- 分区的方式
~~~ 根据分区键(id)进行分区:### --- 范围分区
~~~ 根据id数字的范围比如1--10000、100001--20000.....90001-100000,
~~~ 每个范围分到不同的Redis实例中| id范围 | Redis实例 |
| 1-10000 | Redis01 |
| 100001-20000 | Redis02 |
| ...... | ...... |
| 90001-100000 | Redis10 |
~~~ # 好处:
~~~ 实现简单,方便迁移和扩展
~~~ # 缺陷:
~~~ 热点数据分布不均,性能损失
~~~ 非数字型key,比如uuid无法使用(可采用雪花算法替代)
~~~ 分布式环境 主键 雪花算法
~~~ 是数字
~~~ 能排序### --- hash分区
~~~ # 利用简单的hash算法即可:
~~~ Redis实例=hash(key)%N
~~~ key:要进行分区的键,比如user_id
~~~ N:Redis实例个数(Redis主机)
~~~ # 好处:
~~~ 支持任何类型的key
~~~ 热点分布较均匀,性能较好
~~~ # 缺陷:
~~~ 迁移复杂,需要重新计算,扩展较差(利用一致性hash环)三、client端分区
### --- client端分区
### --- 部署方案
~~~ 对于一个给定的key,客户端直接选择正确的节点来进行读写。
~~~ 许多Redis客户端都实现了客户端分区(JedisPool),也可以自行编程实现。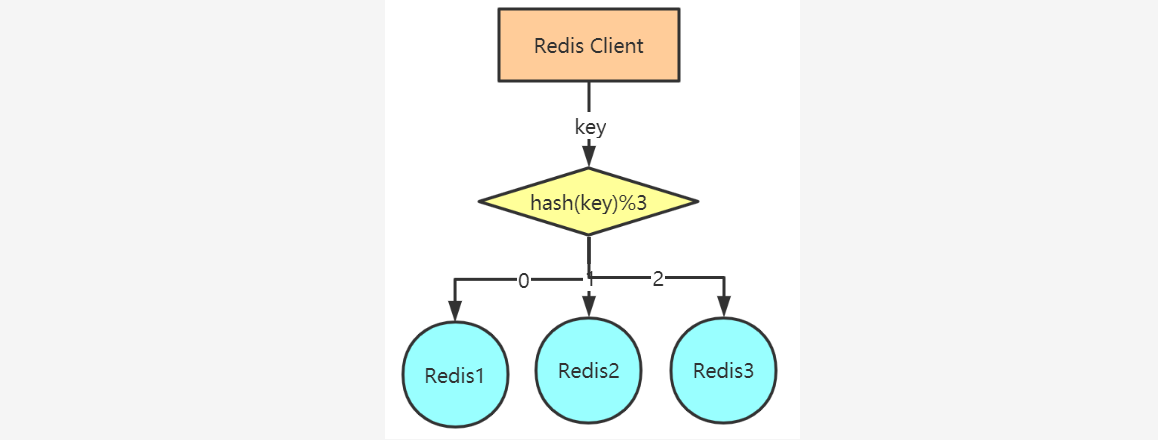
四、客户端选择算法
### --- Hash
~~~ hash
~~~ 普通hash
~~~ hash(key)%N
~~~ hash:可以采用hash算法,比如CRC32、CRC16等
~~~ N:是Redis主机个数### --- 比如:
~~~ user_id : u001
~~~ hash(u001) : 1844213068
~~~ Redis实例=1844213068%3
~~~ 余数为2,所以选择Redis3。Walter Savage Landor:strove with none,for none was worth my strife.Nature I loved and, next to Nature, Art:I warm'd both hands before the fire of life.It sinks, and I am ready to depart
——W.S.Landor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号